seata面试题
1、请介绍一下你对 SEATA 的理解以及你对分布式事务的看法
SEATA 是一个开源的分布式事务解决方案,它旨在解决分布式系统中的数据一致性问题。我理解的分布式事务是指涉及多个服务或数据库的操作,需要保证这些操作要么全部成功,要么全部失败,以确保数据的一致性。在传统的单体应用中,可以使用本地事务来实现这一目标,但在分布式系统中,跨多个服务或数据库的事务操作需要额外的处理来确保一致性,而 SEATA 就提供了这样的解决方案。
2、SEATA 的核心组件有哪些?你能分别描述一下它们的作用吗?
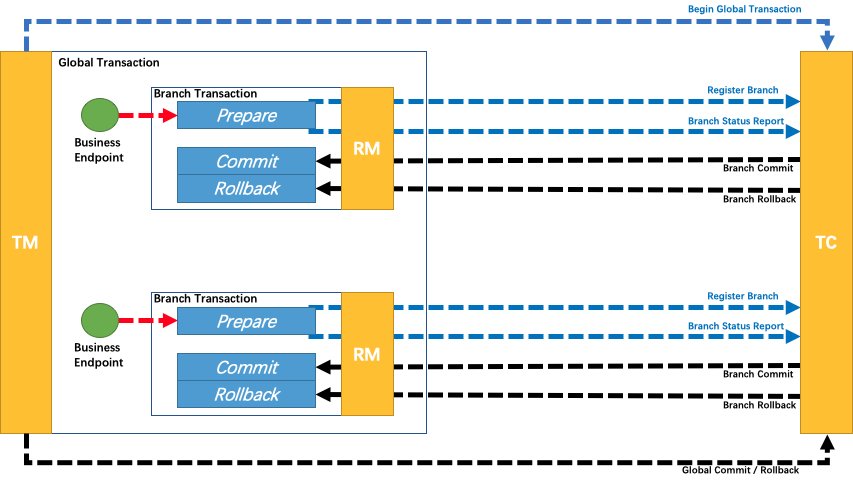
(1)事务协调器(TC):事务协调器负责全局事务的协调和控制
(2)事务日志存储(AT、TC):事务日志存储用于存储全局事务的日志信息
(3)分支事务(Branch):分支事务用于执行分布式事务的实际操作
(4)资源管理器(RM):资源管理器负责管理本地事务和资源
(5)锁定器(Lock):锁定器用于在并发访问情况下确保数据的一致性
3、SEATA 是如何保证分布式事务的一致性的
SEATA 通过两阶段提交(2PC)和补偿事务机制来保证分布式事务的一致性。在 2PC 中,事务协调器会先向所有的分支事务发送准备命令,等待它们的响应,然后根据响应情况决定是否提交或回滚全局事务。而在补偿事务机制中,如果某个分支事务执行失败,事务协调器会向其发送补偿命令,以回滚或修复之前的操作,从而保证全局事务的一致性
4、SEATA 支持哪些事务模式?请分别介绍它们的特点和适用场景
SEATA 支持 AT、TCC 和 SAGA 、XA四种事务模式。
AT(ATomic Mode)模式
AT是最常用的模式,它利用数据库的本地事务来实现全局事务的一致性,适用于各种简单的业务场景;
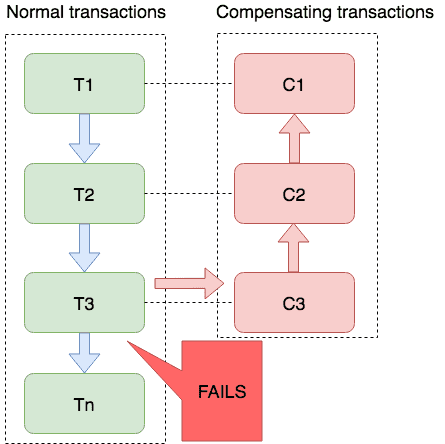
TCC(Try-Confirm-Cancel)模式
TCC则通过 Try 阶段尝试执行业务操作、Confirm 阶段确认执行操作以及 Cancel 阶段取消执行操作来实现分布式事务的一致性,适用于对数据一致性要求较高的场景;
优点:
TCC 完全不依赖底层数据库,能够实现跨数据库、跨应用资源管理,可以提供给业务方更细粒度的控制。
缺点:
CC 是一种侵入式的分布式事务解决方案,需要业务系统自行实现 Try,Confirm,Cancel 三个操作,对业务系统有着非常大的入侵性,设计相对复杂。
待解决的方案
(1)幂等控制:原服务与补偿服务都需要保证幂等性, 由于网络可能超时, 可以设置重试策略,重试发生时要通过幂等控制避免业务数据重复更新
(2)空补偿:原服务未执行,补偿服务执行了
出现原因:
(1)原服务超时(丢包)
(2)Saga事务触发回滚
(3)未收到原服务请求,先收到补偿请求
所以服务设计时需要允许空补偿, 即没有找到要补偿的业务主键时返回补偿成功并将原业务主键记录下来
(3)防悬挂控制:
悬挂:补偿服务比原服务先执行
出现原因:
(1)原服务超时(拥堵)
(2)Saga事务回滚,触发回滚
(3)拥堵的原服务到达
所以要检查当前业务主键是否已经在空补偿记录下来的业务主键中存在,如果存在则要拒绝服务的执行
SAGA 模式
通过一系列的局部事务来实现全局事务,适用于长时间运行的业务流程
适用场景:
- 业务流程长、业务流程多
- 参与者包含其它公司或遗留系统服务,无法提供 TCC 模式要求的三个接口
优势: - 阶段提交本地事务,无锁,高性能
- 事件驱动架构,参与者可异步执行,高吞吐
- 补偿服务易于实现
缺点: - 不保证隔离性
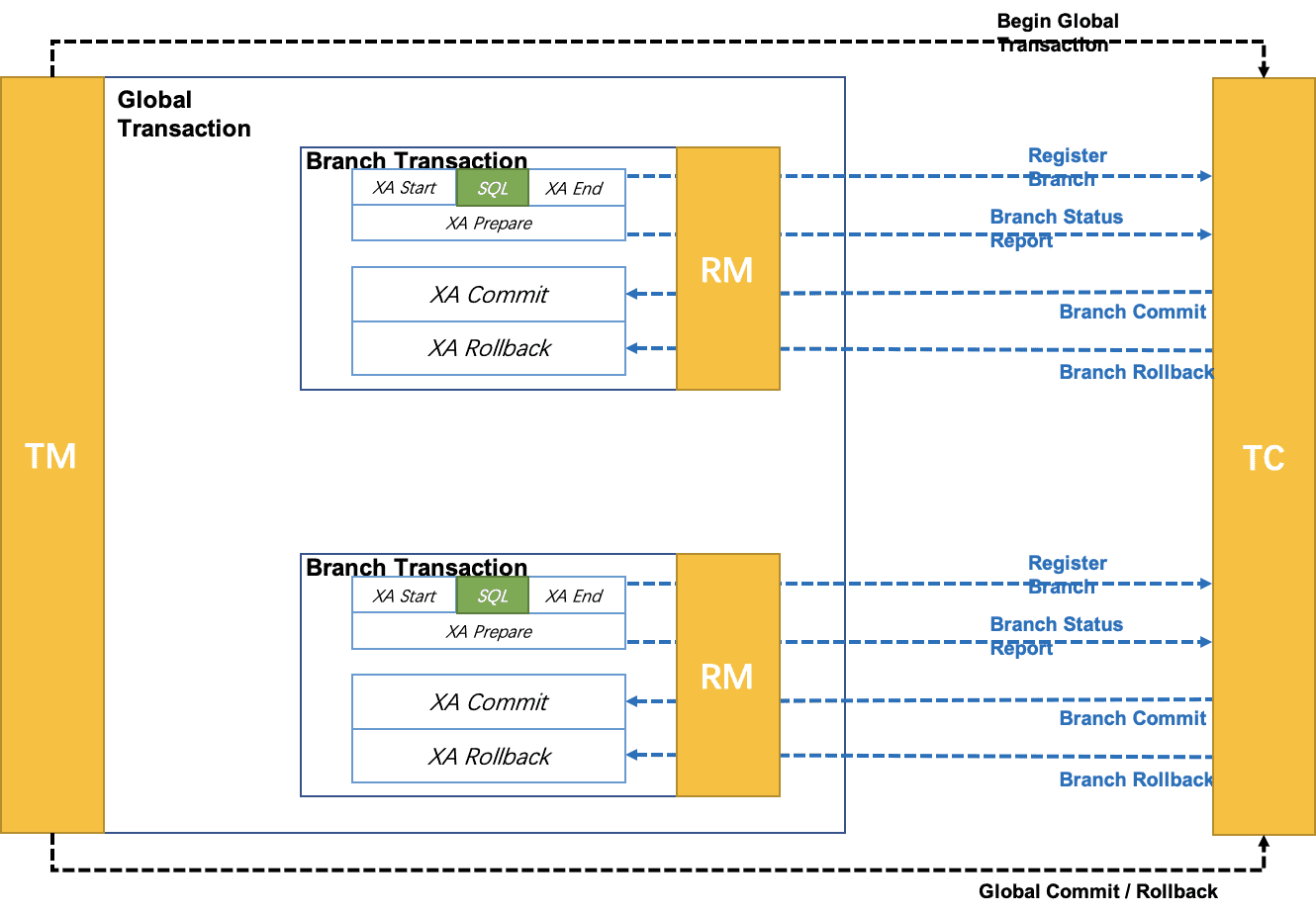
XA 模式
从1.2版本开始支持的事务模式。XA 规范 是 X/Open 组织定义的分布式事务处理(DTP,Distributed Transaction Processing)标准。Seata XA 模式是利用事务资源(数据库、消息服务等)对 XA 协议的支持,以 XA 协议的机制来管理分支事务的一种事务模式。
优势
1、业务无侵入:和 AT 一样,XA 模式将是业务无侵入的,不给应用设计和开发带来额外负担。
2、数据库的支持广泛:XA协议普遍被主流数据支持,不需要额外的适配
缺点
XA prepare后,分支事务进入阻塞,必须等到XA commit或XA rollback前必须阻塞等待。事务资源长时间得不到释放,锁定周期长,而且应用层无法进行干预,性能差。
适用场景
适用于想要迁移到 Seata 平台基于 XA 协议的老应用,使用 XA 模式将更平滑,还有 AT 模式未适配的数据库应用
整体机制
- 执行阶段:
可回滚:业务 SQL 操作放在 XA 分支中进行,由资源对 XA 协议的支持来保证 可回滚
持久化:XA 分支完成后,执行 XA prepare,同样,由资源对 XA 协议的支持来保证 持久化 (即,之后任何意外都不会造成无法回滚的情况) - 完成阶段:
分支提交:执行 XA 分支的 commit
分支回滚:执行 XA 分支的 rollback
5、在使用 SEATA 进行分布式事务时,如何配置和启动事务协调器(TC)和事务日志存储(AT、TC)
配置和启动事务协调器和事务日志存储是 SEATA 的关键步骤之一。通常情况下,可以通过修改 SEATA 的配置文件来配置事务协调器和事务日志存储的相关参数,然后通过命令行或启动脚本来启动它们。另外,可以使用 SEATA 提供的 Docker 镜像来快速部署事务协调器和事务日志存储。
6、在一个微服务架构中,如果某个服务出现故障,SEATA 是如何处理分布式事务的恢复
当某个服务出现故障时,SEATA 会利用其事务日志存储的机制来实现分布式事务的恢复。具体来说,SEATA 会根据事务日志中记录的信息来进行事务的回滚或者补偿,以确保全局事务的一致性。同时,SEATA 还支持基于恢复策略的配置,可以根据实际情况来调整事务恢复的行为。
7、SEATA 的适用范围有哪些限制?在什么情况下不建议使用 SEATA
SEATA 适用于大多数的分布式事务场景,但也存在一些限制。首先,由于 SEATA 是基于数据库本地事务的,因此不适用于涉及跨多个数据库类型的场景。其次,由于 SEATA 使用了 2PC 和补偿事务机制,可能会带来一定的性能损耗,因此不适合对性能要求极高的场景。此外,SEATA 还需要侵入业务代码,因此在已有业务系统较为复杂的情况下,引入 SEATA 可能会增加改造成本。
8、SEATA 与其他分布式事务解决方案相比有什么优势和劣势?
SEATA 的优势在于它提供了简单易用的分布式事务解决方案,支持多种事务模式,并且具有较好的水平扩展性和高可用性。另外,SEATA 还提供了丰富的监控和管理功能,方便用户对分布式事务进行管理和调优。然而,SEATA 也存在一些劣势,比如性能较低、侵入性较强以及对数据库类型的限制等
9、使用 SEATA 过程中,可能会遇到的性能瓶颈是什么?如何优化?
在使用 SEATA 过程中,可能会遇到的性能瓶颈主要包括网络延迟、事务协调器的压力以及数据库的性能瓶颈等。为了优化性能,可以采取以下措施:首先,尽量减少事务的范围,降低事务的并发度;其次,合理配置事务日志存储和资源管理器,提高其性能和可用性;另外,可以使用分布式缓存来减轻数据库的压力,从而提高整体性能。
10、如何在项目中集成 SEATA?是否有示例或最佳实践可以参考?
在项目中集成 SEATA 主要包括修改配置文件、引入依赖、修改业务代码等步骤。首先,需要修改 SEATA 的配置文件,配置事务协调器和事务日志存储的地址和参数等信息;然后,引入 SEATA 的依赖到项目中,并根据需要修改业务代码,以便支持分布式事务。此外,SEATA 官方文档中也提供了详细的集成示例和最佳实践

 浙公网安备 33010602011771号
浙公网安备 33010602011771号