Python3列表、元组、字典、集合的方法
一、列表
温馨提示:对图片点右键——在新标签页中打开图片:

1、count()
定义:统计指定元素在列表中出现的次数并返回这个数。若指定的元素不存在则返回:0。
格式:[列表].count(“指定元素”)
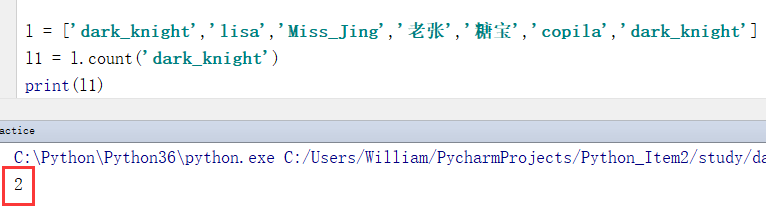
例:统计指定元素的个数
l = ['dark_knight','lisa','Miss_Jing','老张','糖宝','copila','dark_knight']
l1 = l.count('dark_knight')
print(l1)
输出结果:
2
图示:
例2:统计这一个不存在的元素
l = ['dark_knight','lisa','Miss_Jing','老张','糖宝','copila','dark_knight']
l1 = l.count('x') # 指定一个不存在的元素
print(l1)
输出结果:
0
图示:

2、index()
定义:查找并返回指定元素的索引位置,若指定的元素不存在则会抛出异常,可以指定范围查找。
格式:[列表].index("指定元素",指定范围)
例1:查找指定元素的索引位置
l = ['dark_knight','lisa','Miss_Jing','老张','糖宝','copila','dark_knight']
l1 = l.index('dark_knight')
print(l1)
输出结果:
0
图示:

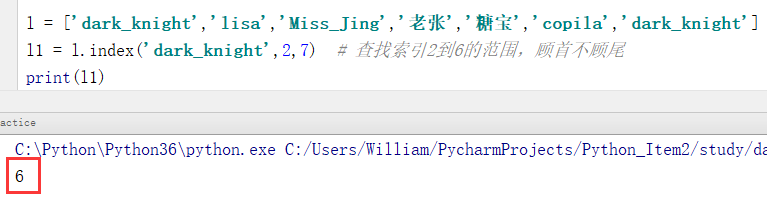
例2:指定范围查找指定元素的索引位置,范围查找顾首不顾尾
l = ['dark_knight','lisa','Miss_Jing','老张','糖宝','copila','dark_knight']
l1 = l.index('dark_knight',2,7) # 查找索引2到6的范围,顾首不顾尾
print(l1)
输出结果:
6
图示:
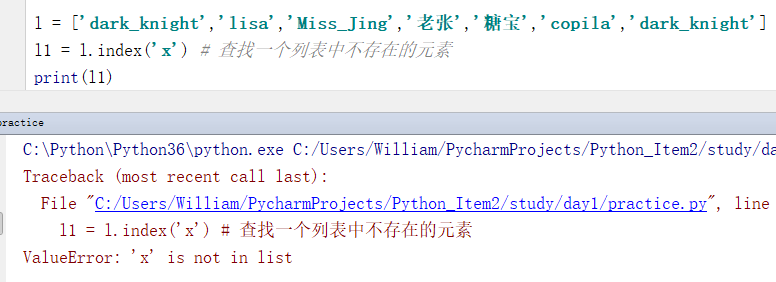
例3:查找一个列表中不存在的元素则会抛出异常
l = ['dark_knight','lisa','Miss_Jing','老张','糖宝','copila','dark_knight']
l1 = l.index('x') # 查找一个列表中不存在的元素
print(l1)
输出结果:
ValueError: 'x' is not in list
图示:
3、pop()
定义:移除列表中一个指定元素。括号中必须写被移除元素的索引位置,并返回这个被移除的元素,括号中不写则默认移除列表中最后一个元素
格式:[列表].pop(指定元素的索引位置)
例1:默认移除列表中的最后一个元素
l = ['dark_knight','lisa','Miss_Jing','老张','糖宝','copila','dark_knight'] l1 = l.pop() # 默认移除列表中的最后一个元素 print(l1) # 返回这个被移除的元素 print(l) # 查看原列表
输出结果:
dark_knight
['dark_knight', 'lisa', 'Miss_Jing', '老张', '糖宝', 'copila']
图示:

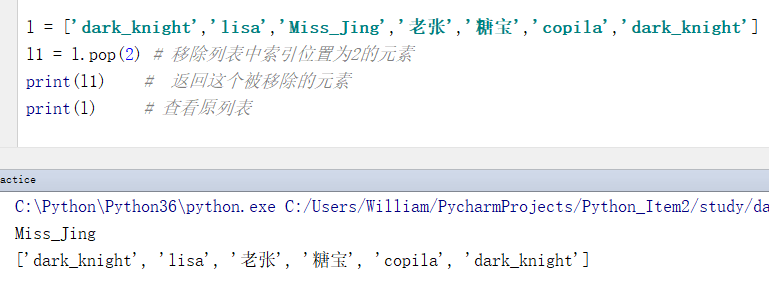
例2:移除指定的元素
l = ['dark_knight','lisa','Miss_Jing','老张','糖宝','copila','dark_knight'] l1 = l.pop(2) # 移除列表中索引位置为2的元素 print(l1) # 返回这个被移除的元素 print(l) # 查看原列表
输出结果:
Miss_Jing
['dark_knight', 'lisa', '老张', '糖宝', 'copila', 'dark_knight']
图示:
例3:删除一个超出列表元素索引的元素则会抛出异常
l = ['dark_knight','lisa','Miss_Jing','老张','糖宝','copila','dark_knight'] l1 = l.pop(10) # 移除列表中索引位置为10的元素,但列表中的元素没有索引位置为10的元素 print(l1) # 返回这个被移除的元素 print(l) # 查看原列表
输出结果:
IndexError: pop index out of range
图示:

4、remove()
定义:移除列表中一个指定的元素,返回值为None,括号中必须指定元素名,否则抛出异常。移除一个不存在列表中的元素也会抛出异常。
格式:[列表].remove(“指定的元素名”)
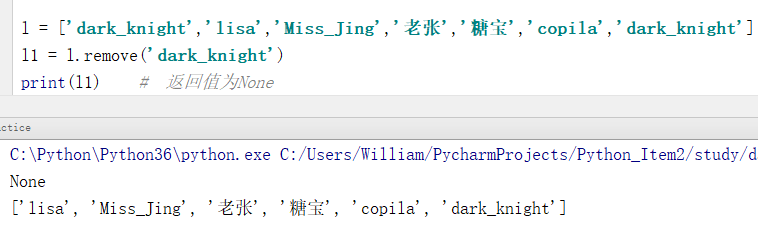
例1:移除指定元素
l = ['dark_knight','lisa','Miss_Jing','老张','糖宝','copila','dark_knight']
l1 = l.remove('dark_knight')
print(l1) # 返回值为None
print(l) # 打印原列表
输出结果:
None
['lisa', 'Miss_Jing', '老张', '糖宝', 'copila', 'dark_knight']
图示:
例2:移除一 个不存在列表的元素则会抛出异常。
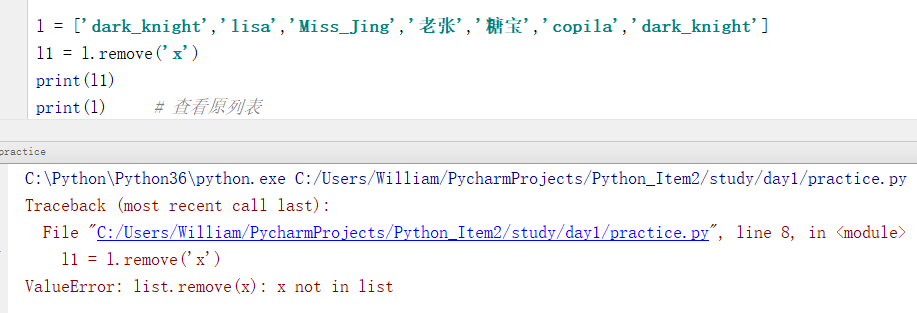
l = ['dark_knight','lisa','Miss_Jing','老张','糖宝','copila','dark_knight']
l1 = l.remove('x')
print(l1)
print(l) # 查看原列表
输出结果:
ValueError: list.remove(x): x not in list
图示:
5、insert()
定义:将要插入的元素插入至列表中指定的索引位置处,返回值为None。
格式:[列表].insert(指定的索引位置,"要插入的元素")
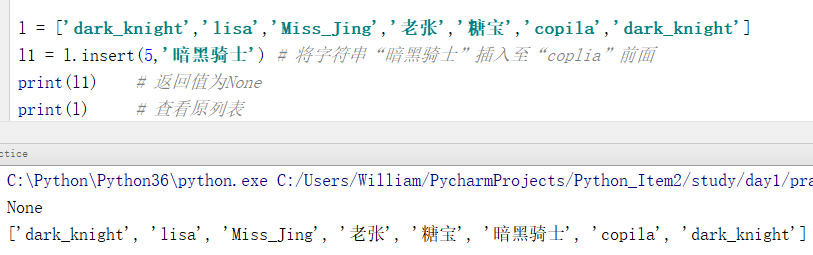
例1:将要插入的元素插入至列表中指定的索引位置处
l = ['dark_knight','lisa','Miss_Jing','老张','糖宝','copila','dark_knight'] l1 = l.insert(5,'暗黑骑士') # 将字符串“暗黑骑士”插入至“coplia”前面 print(l1) # 返回值为None print(l) # 查看原列表
输出结果:
None
['dark_knight', 'lisa', 'Miss_Jing', '老张', '糖宝', '暗黑骑士', 'copila', 'dark_knight']
图示:
例2:将要插入的元素插入至列表中指定的索引位置处。
l = ['dark_knight','lisa','Miss_Jing','老张','糖宝','copila','dark_knight'] l1 = l.insert(20,'暗黑骑士') # 将字符串“暗黑骑士”插入索引位置为20的地方 print(l1) # 返回值为None print(l) # 查看原列表
输出结果:
None
['dark_knight', 'lisa', 'Miss_Jing', '老张', '糖宝', 'copila', 'dark_knight', '暗黑骑士']
图示:

6、append()
定义:在列表中的末尾处添加指定的元素,返回值为None。
格式:[列表].append(“指定元素”)
例:在列表的末尾处添加指定的元素
l = ['dark_knight','lisa','Miss_Jing','老张','糖宝','copila','dark_knight']
l1 = l.append('暗黑骑士')
print(l1) # 返回值为None
print(l) # 查看原列表
输出结果:
None
['dark_knight', 'lisa', 'Miss_Jing', '老张', '糖宝', 'copila', 'dark_knight', '暗黑骑士']
图示:

7、clear()
定义:清空列表中所有的元素,返回值为None
格式:[列表].clear()
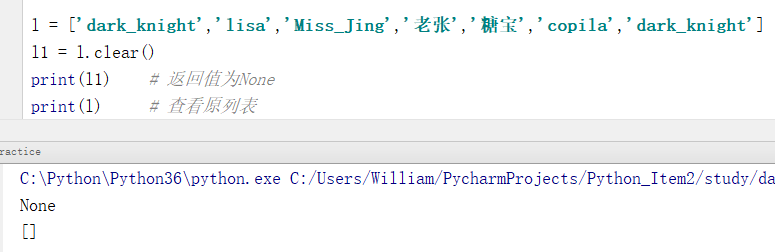
例:清空列表中所有的元素
l = ['dark_knight','lisa','Miss_Jing','老张','糖宝','copila','dark_knight'] l1 = l.clear() print(l1) # 返回值为None print(l) # 查看原列表
输出结果:
None
[]
图示:
8、copy()
定义:拷贝列表,并返回一个浅拷贝后的新列表
格式:[列表].copy()
例:拷贝一个列表
l = ['dark_knight','lisa','Miss_Jing','老张','糖宝','copila','dark_knight'] l1 = l.copy() print(l1) # 得到复制后的新列表 print(l) # 查看原列表
输出结果:
['dark_knight', 'lisa', 'Miss_Jing', '老张', '糖宝', 'copila', 'dark_knight']
['dark_knight', 'lisa', 'Miss_Jing', '老张', '糖宝', 'copila', 'dark_knight']
图示:

9、extend()
定义:扩展列表。在原列表中末尾处追加一个序列,该序列中的所有元素都会被添加至原列表末尾。返回值为None
格式:[列表].extend(一个序列)
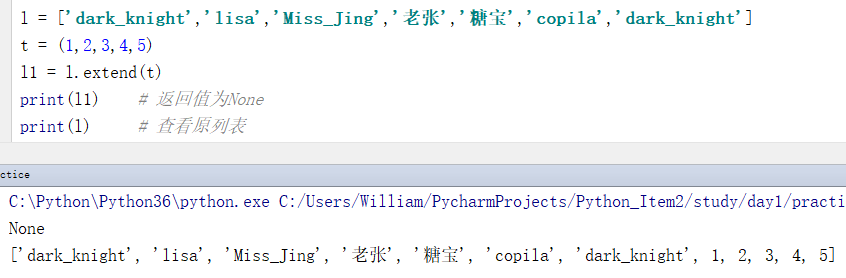
例:扩展列表
l = ['dark_knight','lisa','Miss_Jing','老张','糖宝','copila','dark_knight'] t = (1,2,3,4,5) l1 = l.extend(t) print(l1) # 得到复制后的新列表 print(l) # 查看原列表
输出结果:
None
['dark_knight', 'lisa', 'Miss_Jing', '老张', '糖宝', 'copila', 'dark_knight', 1, 2, 3, 4, 5]
图示:
10、reverse()
定义:反向列表中的元素,返回值为None。
格式:[列表].reverse()
例:反向列表中的元素
l = ['dark_knight','lisa','Miss_Jing','老张','糖宝','copila','dark_knight'] l1 = l.reverse() print(l1) # 返回值为None print(l) # 查看原列表
输出结果:
None
['dark_knight', 'copila', '糖宝', '老张', 'Miss_Jing', 'lisa', 'dark_knight']
图示:

11、sort()
定义:对列表进行排序,返回值为None。
有两个可选参数:key和reversekey。
key在使用时必须提供一个排序过程总调用的函数,默认key = None;
reverse实现升降序排序,需要提供布尔值,默认reverse = False
格式:[列表].sort(key = 过程总调用函数,reverse = 布尔值)
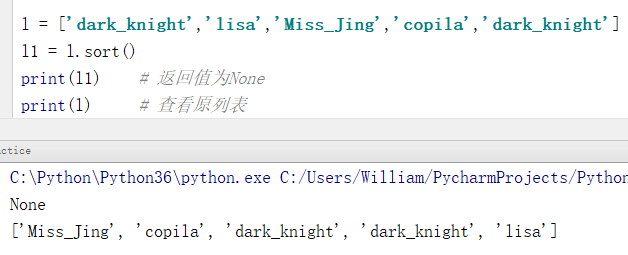
例1:将每个元素的首字母以“a-z”的顺序进行排序
l = ['dark_knight','lisa','Miss_Jing','copila','dark_knight'] l1 = l.sort() # 相当于:l1 = l.sort(key = None,reverse = False) print(l1) # 返回值为None print(l) # 查看原列表
输出结果:
None
['Miss_Jing', 'copila', 'dark_knight', 'dark_knight', 'lisa']
图示:
例2:将每个元素以“0-9”的顺序进行排序.
l = [5,3,2,7,4,1,6] l1 = l.sort() # 数字按0-9的升序排序。相当于l1 = l.sort(key = None,reverse = False) print(l1) # 返回值为None print(l) # 查看原列表
输出结果:
None
[1, 2, 3, 4, 5, 6, 7]
例3:列表中若既有数字又有字符串则不能用sort方法进行排序,否则报错。
l = ['dark_knight','lisa','Miss_Jing','copila',8,7,6] l1 = l.sort() print(l1) # 返回值为None print(l) # 查看原列表
输出结果:
TypeError: '<' not supported between instances of 'int' and 'str'
图示:

例4:将每个字符串元素按长度从短到长的方式进行排序
l = ['hahahahaha','hahaha','hahahaha','ha'] l1 = l.sort(key = len) # 相当于l1 = l.sort(key = len,reverse = False) print(l1) # 返回值为None print(l) # 查看原列表
输出结果:
None
['ha', 'hahaha', 'hahahaha', 'hahahahaha']
图示:

例5:将每个字符串元素按长度从长到短的方式进行排序
l = ['hahahahaha','hahaha','hahahaha','ha'] l1 = l.sort(key = len,reverse=True) print(l1) # 返回值为None print(l) # 查看原列表
输出结果:
None
['hahahahaha', 'hahahaha', 'hahaha', 'ha']
图示:

二、元组
1、count()
定义:统计指定元素在元组中出现的次数并返回这个数。若指定的元素不存在则返回:0。
格式:(元组).count(“指定的元素”)
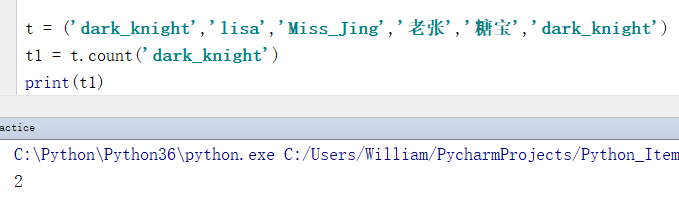
例1:统计指定元素在元组中出现的次数
t = ('dark_knight','lisa','Miss_Jing','老张','糖宝','dark_knight')
t1 = t.count('dark_knight')
print(t1)
输出结果:
2
图示:
例2:统计一个不存在元组的中的元素
t = ('dark_knight','lisa','Miss_Jing','老张','糖宝','dark_knight')
t1 = t.count('x')
print(t1)
输出结果:
0
图示:

2、index()
定义:查找并返回指定元素的索引位置,若指定的元素不存在则会抛出异常,可以指定范围查找。
格式:(元组).index(“指定元素”,指定范围)
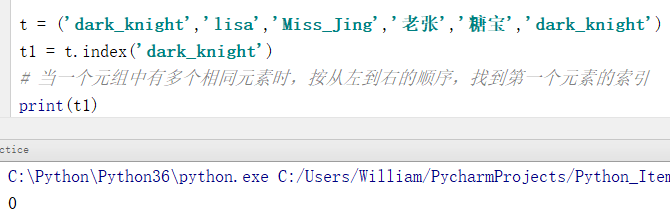
例1:当有多个相同的元素时,按从左到右的顺序,找到第一个元素的索引位置
t = ('dark_knight','lisa','Miss_Jing','老张','糖宝','dark_knight')
t1 = t.index('dark_knight')
# 当一个元组中有多个相同的元素时,按从左到右的顺序,找到第一个元素的索引位置
print(t1)
输出结果:
0
图示:
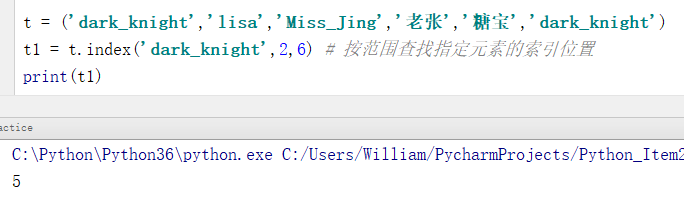
例2:按范围查找指定元素的索引位置
t = ('dark_knight','lisa','Miss_Jing','老张','糖宝','dark_knight')
t1 = t.index('dark_knight',2,6) # 按范围查找指定元素的索引位置
print(t1)
输出结果:
5
图示:
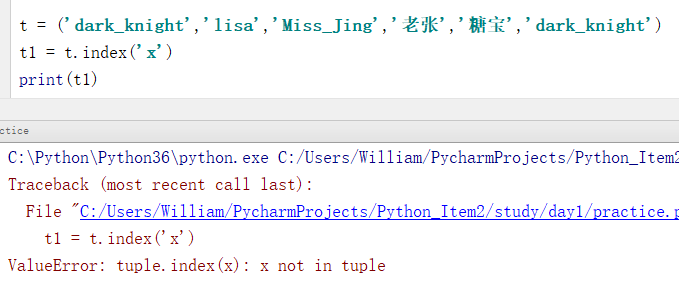
例3:查找一个元组中不存在的元素则会抛出异常
t = ('dark_knight','lisa','Miss_Jing','老张','糖宝','dark_knight')
t1 = t.index('x')
print(t1)
输出结果:
ValueError: tuple.index(x): x not in tuple
图示:
三、字典 
1、keys()
定义:返回字典里的所有的键
格式:{字典}.keys()
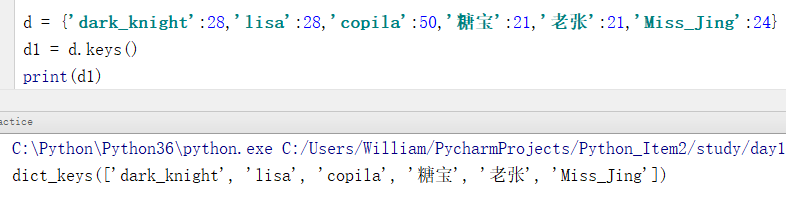
例:取出字典中所有的键
d = {'dark_knight':28,'lisa':28,'copila':50,'糖宝':21,'老张':21,'Miss_Jing':24}
d1 = d.keys()
print(d1)
输出结果:
dict_keys(['dark_knight', 'lisa', 'copila', '糖宝', '老张', 'Miss_Jing'])
图示:
2、values()
定义:返回字典里的所有的值
格式:{字典}.values()
例:返回字典里的所有的值
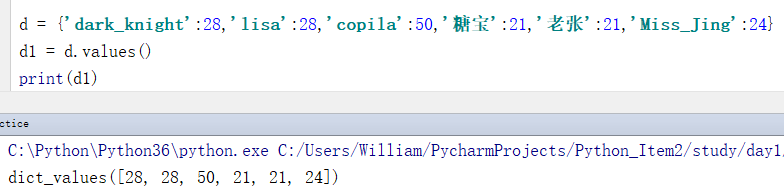
d = {'dark_knight':28,'lisa':28,'copila':50,'糖宝':21,'老张':21,'Miss_Jing':24}
d1 = d.values()
print(d1)
输出结果:
dict_values([28, 28, 50, 21, 21, 24])
图示:
3、copy()
定义:拷贝字典,并返回一个浅拷贝后的新字典。
格式:{字典}.copy()
例:拷贝字典
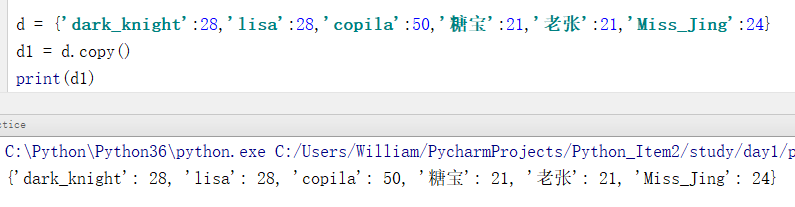
d = {'dark_knight':28,'lisa':28,'copila':50,'糖宝':21,'老张':21,'Miss_Jing':24}
d1 = d.copy()
print(d1)
输出结果:
{'dark_knight': 28, 'lisa': 28, 'copila': 50, '糖宝': 21, '老张': 21, 'Miss_Jing': 24}
图示:
4、clear()
定义:清空字典中所有的元素,返回值为None
格式:{字典}.clear()
例:清空字典中所有的元素
d = {'dark_knight':28,'lisa':28,'copila':50,'糖宝':21,'老张':21,'Miss_Jing':24}
d1 = d.clear()
print(d1) # 返回值
print(d)
输出结果:
None
{}
图示:

5、pop()
定义:删除指定键值。返回被删除指定键值的值。
格式:{字典}.pop(指定的键)
例:指定删除一对键值。
d = {'dark_knight':28,'lisa':28,'copila':50,'糖宝':21,'老张':21,'Miss_Jing':24}
d1 = d.pop('copila')
print(d1) # 返回值
print(d)
输出结果:
50
{'dark_knight': 28, 'lisa': 28, '糖宝': 21, '老张': 21, 'Miss_Jing': 24}
图示:

6、get()
定义:返回指定键的值。若指定的键不存在则返回None
格式:{字典}.get(指定的键)
例1:返回指定键的值
d = {'dark_knight':28,'lisa':28,'copila':50,'糖宝':21,'老张':21,'Miss_Jing':24}
d1 = d.get('copila')
print(d1)
输出结果:
50
图示:

例2:指定的键不在字典中
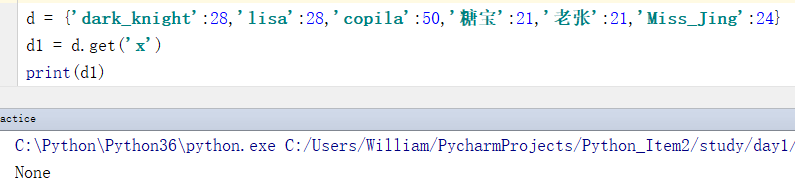
d = {'dark_knight':28,'lisa':28,'copila':50,'糖宝':21,'老张':21,'Miss_Jing':24}
d1 = d.get('x')
print(d1)
输出结果:
None
图示:
7、items()
定义:返回可遍历的(键、值)元组数组
格式:{字典}.items()
例:返回可遍历的(键、值)元组数组
d = {'dark_knight':28,'lisa':28,'copila':50,'糖宝':21,'老张':21,'Miss_Jing':24}
d1 = d.items()
print(d1)
输出结果:
dict_items([('dark_knight', 28), ('lisa', 28), ('copila', 50), ('糖宝', 21), ('老张', 21), ('Miss_Jing', 24)])
图示:

8、update()
定义:扩展字典,返回值为None
格式:{字典1}.update({字典2})
例:扩展字典
d = {'dark_knight':28,'lisa':28,'copila':50,'糖宝':21,'老张':21,'Miss_Jing':24}
d1 = {'x':1,'y':2}
d2 = d.update(d1)
print(d2) # 返回值为None
print(d) # 查看原字典
输出结果:
None
{'dark_knight': 28, 'lisa': 28, 'copila': 50, '糖宝': 21, '老张': 21, 'Miss_Jing': 24, 'x': 1, 'y': 2}
图示:

9、popitem()
定义:随机删除字典中的一对键和值,并返回被删除的键和值。(一般删除字典末尾的键和值)
格式:{字典}.popitem()
例:随机删除字典中的一对键和值。
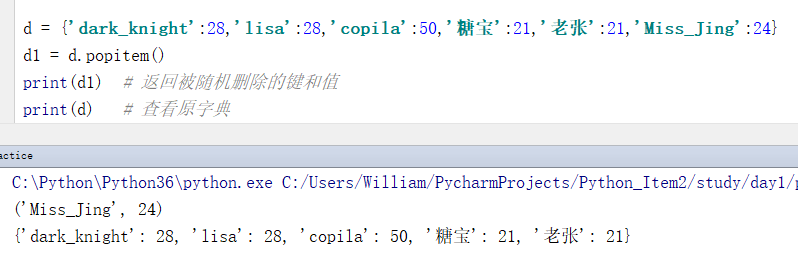
d = {'dark_knight':28,'lisa':28,'copila':50,'糖宝':21,'老张':21,'Miss_Jing':24}
d1 = d.popitem()
print(d1) # 返回被随机删除的键和值
print(d) # 查看原字典
输出结果:
('Miss_Jing', 24) # 这个结果是随机删除,有变化的
{'dark_knight': 28, 'lisa': 28, 'copila': 50, '糖宝': 21, '老张': 21}
图示:
10、fromkeys()
定义:创建并返回一个新字典,有两个参数:seq和value。
seq是必选参数,表示要传入的序列。
value是可选参数,表示要传入新字典中的值。(若不指定值则生成的新字典所有的值都为None)
格式:{字典}.fromkeys(要传入的序列,指定新字典的值)
例:创建一个新字典
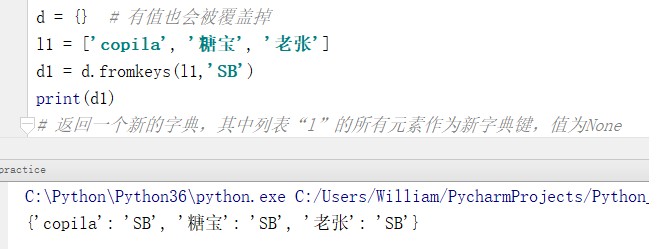
d = {} # 有值也会被覆盖
l1 = ['copila', '糖宝', '老张']
d1 = d.fromkeys(l1,'SB')
print(d1)
# 返回一个新的字典,其中列表“l”的所有元素作为新字典键,值为None
输出结果:
{'copila': 'SB', '糖宝': 'SB', '老张': 'SB'}
图示:
11、setdefault()
定义:与get()方法类似。当指定的键存在时则返回它对应的的值;当指定的键不存在时于字典中时,返回值为None,则将这个键加入到字典里,对应一个空值。
格式:{字典}.setdefault(指定的键)
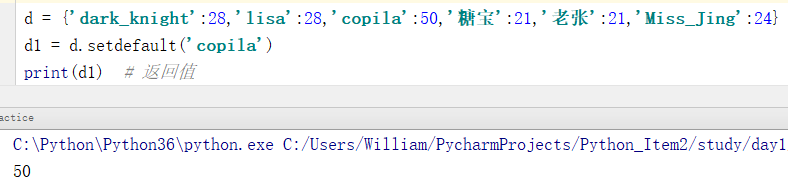
例1:当指定的键存在字典中时返回这个键的值
d = {'dark_knight':28,'lisa':28,'copila':50,'糖宝':21,'老张':21,'Miss_Jing':24}
d1 = d.setdefault('copila')
print(d1) # 返回值
输出结果:
50
图示:
例2:当指定的键不存在字典中时则将这个键添加到字典中,并对应一个空值。
d = {'dark_knight':28,'lisa':28,'copila':50,'糖宝':21,'老张':21,'Miss_Jing':24}
d1 = d.setdefault('x')
print(d1) # 返回值
print(d) # 查看原字典
输出结果:
None
{'dark_knight': 28, 'lisa': 28, 'copila': 50, '糖宝': 21, '老张': 21, 'Miss_Jing': 24, 'x': None}
图示:

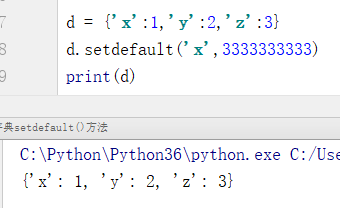
例3:若指定的键存在则不会修改值
d = {'x':1,'y':2,'z':3}
d.setdefault('x',3333333333)
print(d)
输出结果:
{'x': 1, 'y': 2, 'z': 3}
图示:
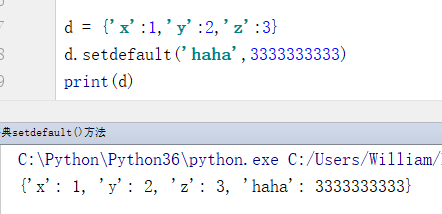
例4:若指定的键不存在则会添加键和值
d = {'x':1,'y':2,'z':3}
d.setdefault('haha',3333333333)
print(d)
输出结果:
{'x': 1, 'y': 2, 'z': 3, 'haha': 3333333333}
图示:
四、集合
1、update()
定义:扩展集合。返回值为None
格式:{集合}.update({被扩展的集合})
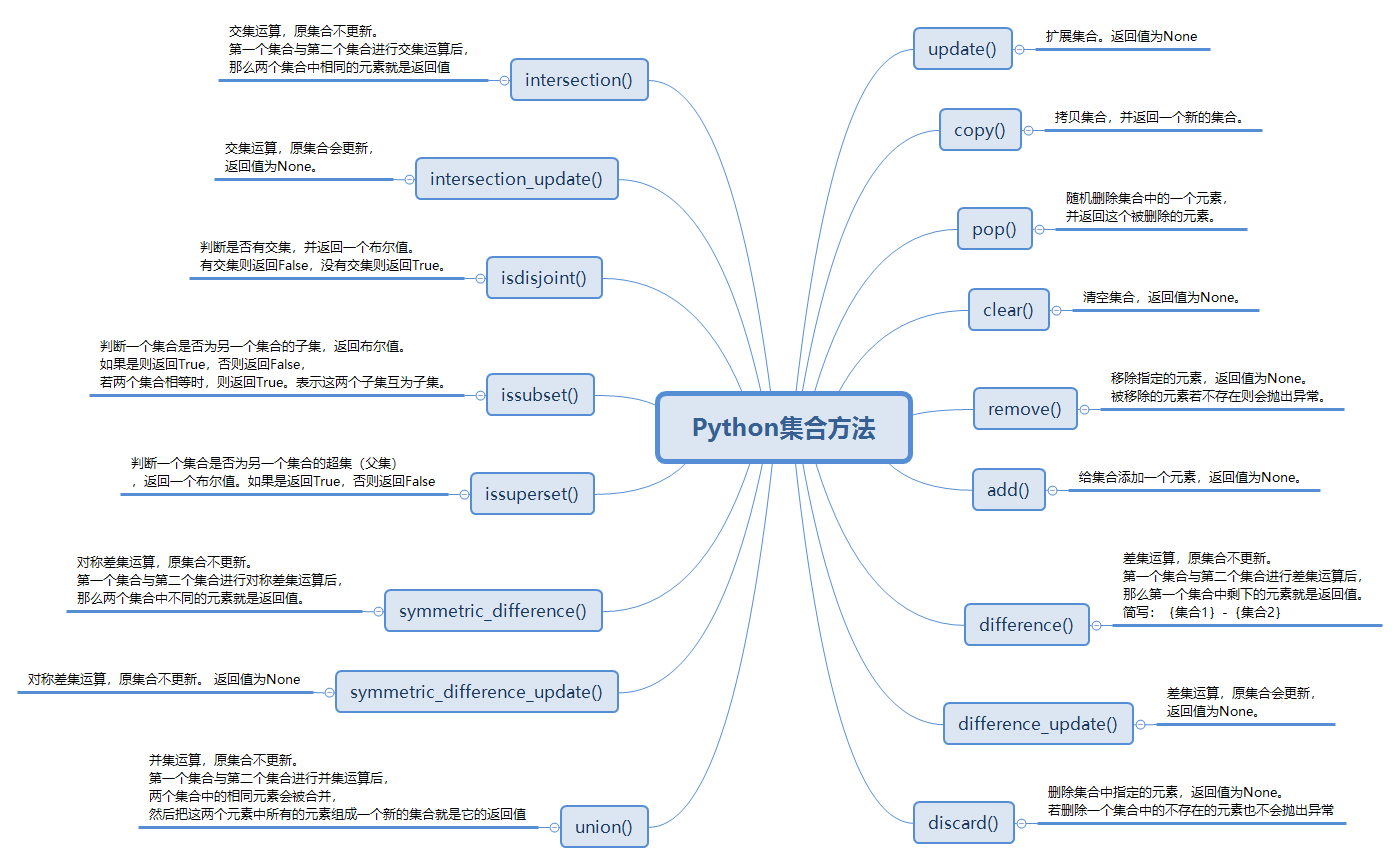
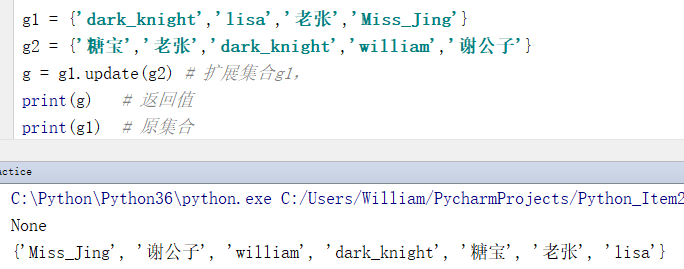
例:扩展集合g1,两个集合中相同的元素将被合并
g1 = {'dark_knight','lisa','老张','Miss_Jing'}
g2 = {'糖宝','老张','dark_knight','william','谢公子'}
g = g1.update(g2) # 扩展集合g1,
print(g) # 返回值
print(g1) # 原集合
输出结果:
None
{'Miss_Jing', '谢公子', 'william', 'dark_knight', '糖宝', '老张', 'lisa'}
图示1:
图示2:
2、copy()
定义:拷贝集合,并返回一个新的集合。
格式:{集合}.copy()
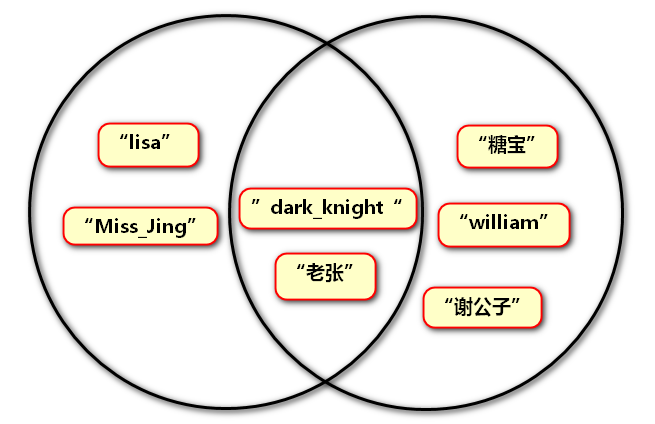
例1:拷贝集合
g = {'dark_knight','lisa','老张','Miss_Jing'}
g1 = g.copy()
print(g1) # 返回值,得到拷贝后的新集合
print(g) # 原集合
输出结果:
{'老张', 'lisa', 'dark_knight', 'Miss_Jing'}
{'老张', 'lisa', 'dark_knight', 'Miss_Jing'}
图示:
3、pop()
定义:随机删除集合中的一个元素,并返回这个被删除的元素。
格式:{集合}.pop()
例:随机删除集合中的一个元素。
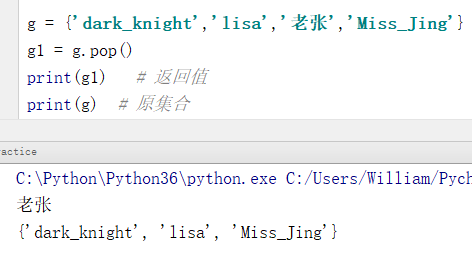
g = {'dark_knight','lisa','老张','Miss_Jing'}
g1 = g.pop()
print(g1) # 返回值
print(g) # 原集合
输出结果:
老张
{'dark_knight', 'lisa', 'Miss_Jing'}
图示:
4、clear()
定义:清空集合,返回值为None。
格式:{集合}.clear()
例:清空集合
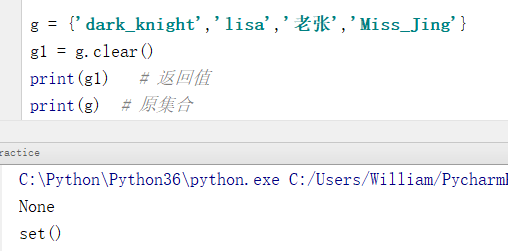
g = {'dark_knight','lisa','老张','Miss_Jing'}
g1 = g.clear()
print(g1) # 返回值
print(g) # 原集合
输出结果:
None
set()
图示:

5、remove()
定义:移除指定的元素,返回值为None。被移除的元素若不存在则会抛出异常。
格式:{集合}.remove(指定的元素)
例1:移除指定的元素
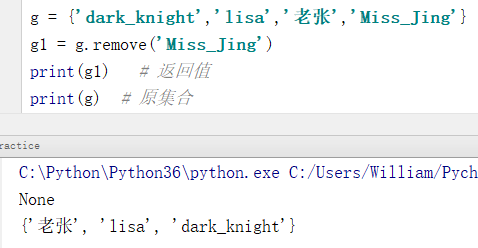
g = {'dark_knight','lisa','老张','Miss_Jing'}
g1 = g.remove('Miss_Jing')
print(g1) # 返回值
print(g) # 原集合
输出结果:
None
{'老张', 'lisa', 'dark_knight'}
图示:
6、add()
定义:给集合添加一个元素,返回值为None。
格式:{集合}.add(元素)
例:给集合添加一个元素
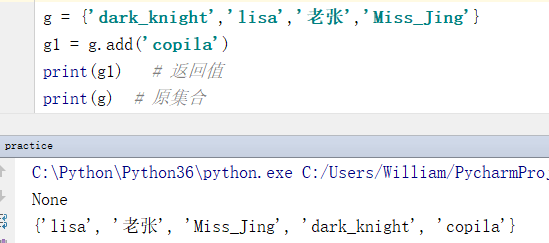
g = {'dark_knight','lisa','老张','Miss_Jing'}
g1 = g.add('copila')
print(g1) # 返回值
print(g) # 原集合
输出结果:
None
{'lisa', '老张', 'Miss_Jing', 'dark_knight', 'copila'}
图示:
7、difference()
定义:差集运算,原集合不更新。第一个集合与第二个集合进行差集运算后,那么第一个集合中剩下的元素就是返回值。
格式:{集合1}.difference({集合2})
简写:{集合1} - {集合2}
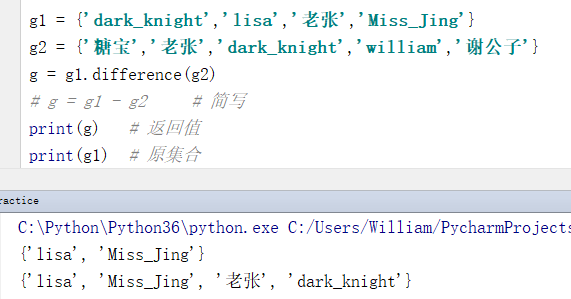
例:集合1对集合2进行差集运算时,返回值则为集合1中与集合2不相同的元素。
g1 = {'dark_knight','lisa','老张','Miss_Jing'}
g2 = {'糖宝','老张','dark_knight','william','谢公子'}
g = g1.difference(g2)
# g = g1 - g2 # 简写
print(g) # 返回值
print(g1) # 原集合
输出结果:
{'lisa', 'Miss_Jing'}
{'lisa', 'Miss_Jing', '老张', 'dark_knight'}
图示1:
差集图示:

8、difference_update()
定义:差集运算,原集合会更新,返回值为None。
格式: {集合1}.difference_update({集合2})
例:差集运算,原集合会更新
g1 = {'dark_knight','lisa','老张','Miss_Jing'}
g2 = {'糖宝','老张','dark_knight','william','谢公子'}
g = g1.difference_update(g2)
print(g) # 返回值
print(g1) # 原集合
输出结果:
None
{'lisa', 'Miss_Jing'
图示:

9、discard()
定义:删除集合中指定的元素,返回值为None。若删除一个集合中的不存在的元素也不会抛出异常
格式:{集合}.discard(指定元素)
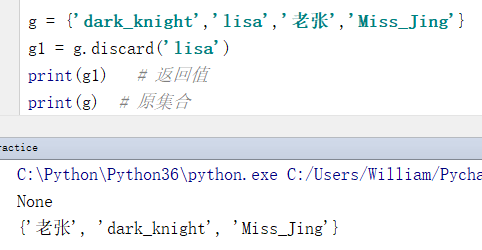
例1:删除一个指定的元素。
g = {'dark_knight','lisa','老张','Miss_Jing'}
g1 = g.discard('lisa')
print(g1) # 返回值
print(g) # 原集合
输出结果:
None
{'老张', 'dark_knight', 'Miss_Jing'}
图示:
例2:删除一个集合中不存在的元素
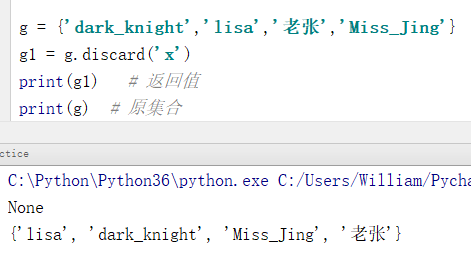
g = {'dark_knight','lisa','老张','Miss_Jing'}
g1 = g.discard('x') # 删除一个集合中不存在的元素
print(g1) # 返回值
print(g) # 原集合
输出结果:
None
{'lisa', 'dark_knight', 'Miss_Jing', '老张'}
图示:
10、intersection()
定义:交集运算,原集合不更新。第一个集合与第二个集合进行交集运算后,那么两个集合中相同的元素就是返回值
格式:{集合1}.intersection({集合2})
简写:{集合1}&{集合2}
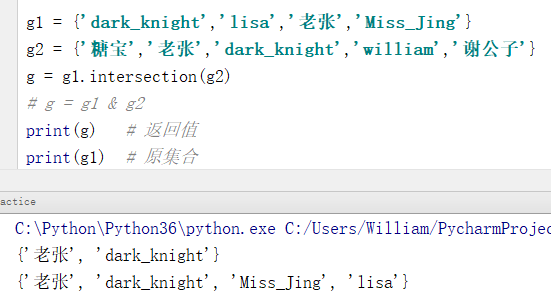
例:交集运算
g1 = {'dark_knight','lisa','老张','Miss_Jing'}
g2 = {'糖宝','老张','dark_knight','william','谢公子'}
g = g1.intersection(g2)
# g = g1 & g2
print(g) # 返回值
print(g1) # 原集合
输出结果:
{'老张', 'dark_knight'}
{'老张', 'dark_knight', 'Miss_Jing', 'lisa'}
图示:
交集图示:

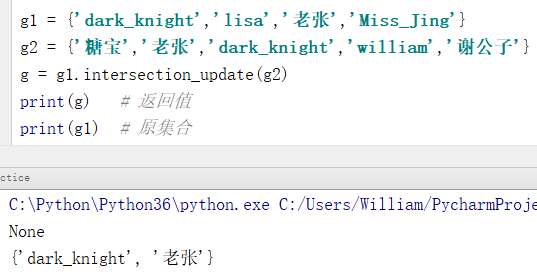
11、intersection_update()
定义:交集运算,原集合会更新,返回值为None。
格式: {集合1}.intersection_update({集合2})
例:交集运算,原集合会更新
g1 = {'dark_knight','lisa','老张','Miss_Jing'}
g2 = {'糖宝','老张','dark_knight','william','谢公子'}
g = g1.intersection_update(g2)
print(g) # 返回值
print(g1) # 原集合
输出结果:
None
{'dark_knight', '老张'}
图示:
12、isdisjoint()
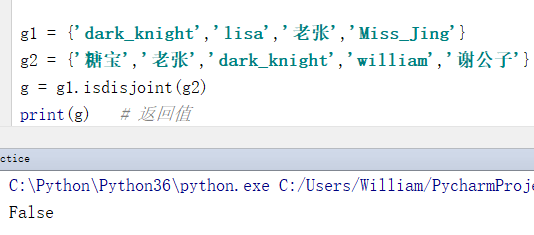
定义:判断是否有交集,并返回一个布尔值。有交集则返回False,没有交集则返回True。
格式:{集合1}.isdisjoint({集合2})
例1:两个集合有交集时返回False
g1 = {'dark_knight','lisa','老张','Miss_Jing'}
g2 = {'糖宝','老张','dark_knight','william','谢公子'}
g = g1.isdisjoint(g2)
print(g) # 返回值
输出结果:
False
图示:
例2:两个集合之间没有交集时返回True
g1 = {'dark_knight','lisa','老张','Miss_Jing'}
g2 = {'xxx','yyy','zzz'}
g = g1.isdisjoint(g2)
print(g) # 返回值
输出结果:
True
图示:

13、issubset()
定义:判断一个集合是否为另一个集合的子集,返回布尔值。如果是则返回True,否则返回False,若两个集合相等时,则返回True。表示这两个集合互为子集。
格式:{集合1}.issubset({集合2})
例1:判断是否为子集
g1 = {'dark_knight','pudding'}
g2 = {'dark_knight','lisa','knight','pudding'}
g = g1.issubset(g2) # g1是g2的子集,所以返回True
print(g)
输出结果:
True
图示:

例2:相同的集合互为子集,也返回True。
g1 = {'dark_knight','lisa','knight','pudding'}
g2 = {'dark_knight','lisa','knight','pudding'}
g = g1.issubset(g2) # g1和g2互为子集,所以返回True
print(g)
输出结果:
True
图示:

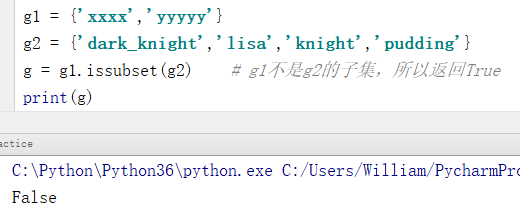
例3: 若不是子集则返回False。
g1 = {'xxxx','yyyyy'}
g2 = {'dark_knight','lisa','knight','pudding'}
g = g1.issubset(g2) # g1不是g2的子集,所以返回False
print(g)
输出结果:
False
图示:
14、issuperset()
定义:判断一个集合是否为另一个集合的超集(父集),返回一个布尔值。如果是返回True,否则返回False
格式:{集合1}.issuperset({集合2})
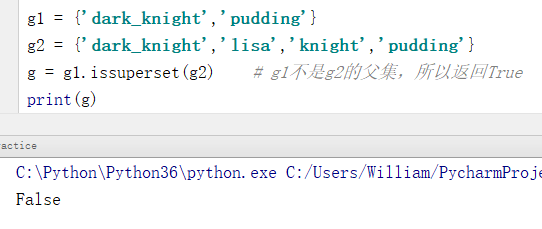
例1:判断是否为父集
g1 = {'dark_knight','pudding'}
g2 = {'dark_knight','lisa','knight','pudding'}
g = g1.issuperset(g2) # g1不是g2的父集,所以返回True
print(g)
输出结果:
False
图示:
例2:判断是否为父集
g1 = {'dark_knight','lisa','knight','pudding'}
g2 = {'dark_knight','pudding'}
g = g1.issuperset(g2) # g1是g2的父集,所以返回True
print(g)
输出结果:
True
图示:

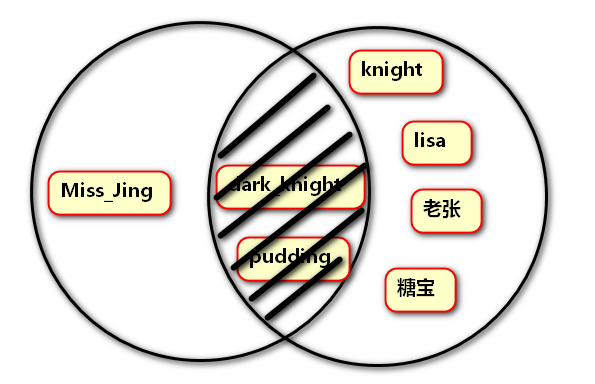
15、symmetric_difference()
定义:对称差集运算,原集合不更新。第一个集合与第二个集合进行对称差集运算后,那么两个集合中不同的元素就是返回值。
格式:{集合1}.symmetric_difference({集合2})
简写:{集合1}^{集合2}
例:对称差集运算
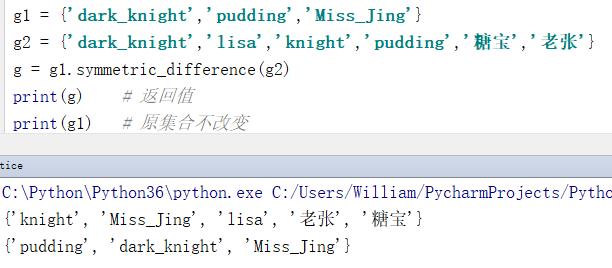
g1 = {'dark_knight','pudding','Miss_Jing'}
g2 = {'dark_knight','lisa','knight','pudding','糖宝','老张'}
g = g1.symmetric_difference(g2)
print(g) # 返回值,得到两个集合中的不相同元的素
print(g1) # 原集合不改变
输出结果:
{'knight', 'Miss_Jing', 'lisa', '老张', '糖宝'}
{'pudding', 'dark_knight', 'Miss_Jing'}
图示:
对称差集图示:
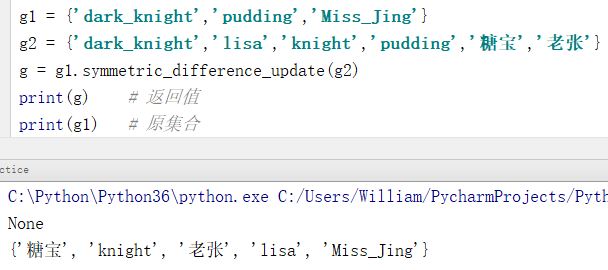
16、symmetric_difference_update()
定义:对称差集运算,原集合更新。返回值为None。
格式:{集合1}.sysmmetric_difference_update({集合2})
例:对称差集运算,原集合会更新。
g1 = {'dark_knight','pudding','Miss_Jing'}
g2 = {'dark_knight','lisa','knight','pudding','糖宝','老张'}
g = g1.symmetric_difference_update(g2)
print(g) # 返回值
print(g1) # 原集合
输出结果:
None
{'糖宝', 'knight', '老张', 'lisa', 'Miss_Jing'}
图示:
17、union()
定义:并集运算,原集合不更新,。第一个集合与第二个集合进行并集运算后,两个集合中的相同元素会被合并,然后把这两个元素中所有的元素组成一个新的集合就是它的返回值
格式:{集合1}.union({集合2})
简写:{集合1}|{集合2}
例:并集运算,原集合不更新
g1 = {'dark_knight','pudding','Miss_Jing'}
g2 = {'dark_knight','lisa','knight','pudding','糖宝','老张'}
g = g1.union(g2)
print(g) # 返回值
print(g1) # 原集合不会被改变
输出结果:
{'dark_knight', 'pudding', 'lisa', '糖宝', 'knight', '老张', 'Miss_Jing'}
{'dark_knight', 'pudding', 'Miss_Jing'}
图示:

并集运算图示:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号