
数据科学技术与应用
根据不同的身体指标可以预测患心脏病的风险等级(Risk)。heart-disease.xlsx记录了测试者的年龄(Age)、性别(Sex)、胸痛类型(Cp)、血压(Trestbps)、胆固醇(Chol)等13种身体指标(具体说明见“数据集说明”文件),以及患心脏病的风险等级。风险等级分为五种:无风险(no)、低风险(low)、中风险(medium)、高风险(high)、极高风险(very high)。
请根据数据集(heart-disease.xlsx)文件格式,正确获取数据样本进行预处理,统计分析,建立分类模型;尝试多种算法,比较分类的性能。
具体要求如下:
1)从文件中读出所需的数据,根据分析需求将所需的数据保存到DataFrame中。
2)数据清洗。判断数据集中是否有缺失数据,并采取以下方式处理:
若‘Thal’有缺失则使用同列前一行数据填充;
若‘Ca’有缺失则使用同列中出现最多的数据填充;
若‘Age’有缺失则删掉该行数据。
3)统计各类‘Risk’的数量,并列出每类‘Risk’的名字。
4)使用散点图矩阵分析‘Risk’类型与‘Age’、‘Trestbps’特征间的相关性,并计算他们之间的相关系数。
5)数据预处理,将数据中非数值型的数据转换为数值类型。
6)选择合适的数据列作为特征和分类标签形成数据集用于训练分类模型,并将数据集分为训练集和测试集。
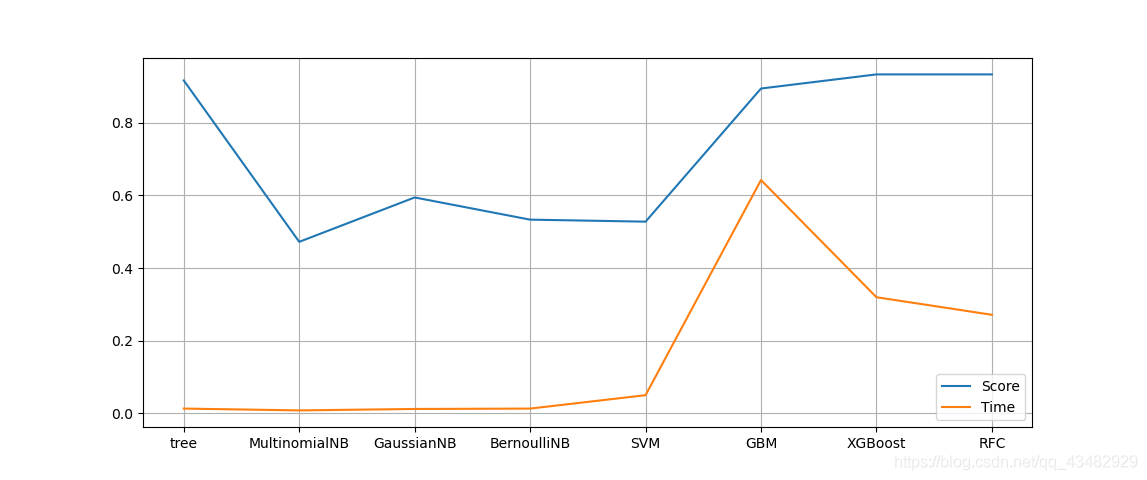
7)在训练集上建立分类模型,在测试集上测试模型预测的准确性。 在已学习的分类方法(决策树、随机森林、SVM、神经网络等)中试用两种算法建立模型。
8)根据第 7) 步的运行结果,说明两种算法在‘Risk’分类数据上的性能。请将结果用文字描述在程序文件给出的注释行中。
import pandas,numpy,datetime,xgboost import matplotlib.pyplot as plt from sklearn import model_selection,preprocessing,metrics,tree,naive_bayes,svm from sklearn.ensemble import RandomForestClassifier,GradientBoostingClassifier from keras.models import Sequential from keras.layers import Dense,Activation from keras.utils import np_utils #1 #请根据 heart-disease.xlsx 保存位置适当调整代码 filepath='data/heart-disease.xlsx' data=pandas.read_excel(filepath,'data',index_col=None,header=0) #2 data['Thal'].fillna(method='ffill',inplace=True) data['Ca'].fillna(data['Ca'].mode().values[0],inplace=True) data.drop(data[data['Age'].isnull()].index,inplace=True) #3 group_3=data.groupby(['Risk']).aggregate({'Risk':pandas.value_counts}) print(group_3) #4 data_4=data[['Risk','Age','Trestbps']].copy() data_4.loc[data_4['Risk']=='very_high','Risk']=5 data_4.loc[data_4['Risk']=='high ','Risk']=4 data_4.loc[data_4['Risk']=='medium ','Risk']=3 data_4.loc[data_4['Risk']=='low ','Risk']=2 data_4.loc[data_4['Risk']=='no','Risk']=1 data_4['Risk']=data_4['Risk'].astype(int) #print(data_4.dtypes) corr_4=data_4.corr() print(corr_4) pandas.plotting.scatter_matrix(data_4,diagonal='kde') plt.show() #5 data_5=data.copy() data_5.loc[data_5['Risk']=='very_high','Risk']=5 data_5.loc[data_5['Risk']=='high ','Risk']=4 data_5.loc[data_5['Risk']=='medium ','Risk']=3 data_5.loc[data_5['Risk']=='low ','Risk']=2 data_5.loc[data_5['Risk']=='no','Risk']=1 data_5['Risk']=data_5['Risk'].astype(int) data_5.loc[data_5['Sex']=='male','Sex']=1 data_5.loc[data_5['Sex']=='female','Sex']=2 data_5['Sex']=data_5['Sex'].astype(int) print(data_5.isnull().any()) #6-8 x=data_5.drop(['Risk'],axis=1).values.astype(float) #x=preprocessing.scale(x) y=data_5['Risk'].values.astype(int) x_train,x_test,y_train,y_test=model_selection.train_test_split(x,y,test_size=0.2,random_state=1) #tree print('Tree') start_time=datetime.datetime.now() clf_tree=tree.DecisionTreeClassifier() clf_tree.fit(x_train,y_train) pre_y_train_tree=clf_tree.predict(x_train) pre_y_test_tree=clf_tree.predict(x_test) print('train_tree') print(clf_tree.score(x_train,y_train)) print(metrics.classification_report(y_train,pre_y_train_tree)) print(metrics.confusion_matrix(y_train,pre_y_train_tree)) print('test_tree') tree_score=clf_tree.score(x_test,y_test) print(tree_score) print(metrics.classification_report(y_test,pre_y_test_tree)) print(metrics.confusion_matrix(y_test,pre_y_test_tree)) end_time = datetime.datetime.now() time_tree=end_time-start_time print("time:",time_tree) #naive_bayes.MultinomialNB print('MultinomialNB') start_time=datetime.datetime.now() clf_MultinomialNB=naive_bayes.MultinomialNB() clf_MultinomialNB.fit(x_train,y_train) pre_y_train_MultinomialNB=clf_MultinomialNB.predict(x_train) pre_y_test_MultinomialNB=clf_MultinomialNB.predict(x_test) print('train_MultinomialNB') print(clf_MultinomialNB.score(x_train,y_train)) print(metrics.classification_report(y_train,pre_y_train_MultinomialNB)) print(metrics.confusion_matrix(y_train,pre_y_train_MultinomialNB)) print('test_MultinomialNB') MultinomialNB_score=clf_MultinomialNB.score(x_test,y_test) print(MultinomialNB_score) print(metrics.classification_report(y_test,pre_y_test_MultinomialNB)) print(metrics.confusion_matrix(y_test,pre_y_test_MultinomialNB)) end_time=datetime.datetime.now() time_MultinomialNB=end_time-start_time print("time:",time_MultinomialNB) #naive_bayes.GaussianNB print('GaussianNB') start_time=datetime.datetime.now() clf_GaussianNB=naive_bayes.GaussianNB() clf_GaussianNB.fit(x_train,y_train) pre_y_train_GaussianNB=clf_GaussianNB.predict(x_train) pre_y_test_GaussianNB=clf_GaussianNB.predict(x_test) print('train_GaussianNB') print(clf_GaussianNB.score(x_train,y_train)) print(metrics.classification_report(y_train,pre_y_train_GaussianNB)) print(metrics.confusion_matrix(y_train,pre_y_train_GaussianNB)) print('test_GaussianNB') GaussianNB_score=clf_GaussianNB.score(x_test,y_test) print(GaussianNB_score) print(metrics.classification_report(y_test,pre_y_test_GaussianNB)) print(metrics.confusion_matrix(y_test,pre_y_test_GaussianNB)) end_time=datetime.datetime.now() time_GaussianNB=end_time-start_time print("time:",time_GaussianNB) #naive_bayes.BernoulliNB print('BernoulliNB') start_time=datetime.datetime.now() clf_BernoulliNB=naive_bayes.BernoulliNB() clf_BernoulliNB.fit(x_train,y_train) pre_y_train_BernoulliNB=clf_BernoulliNB.predict(x_train) pre_y_test_BernoulliNB=clf_BernoulliNB.predict(x_test) print('train_BernoulliNB') print(clf_BernoulliNB.score(x_train,y_train)) print(metrics.classification_report(y_train,pre_y_train_BernoulliNB)) print(metrics.confusion_matrix(y_train,pre_y_train_BernoulliNB)) print('test_BernoulliNB') BernoulliNB_score=clf_BernoulliNB.score(x_test,y_test) print(BernoulliNB_score) print(metrics.classification_report(y_test,pre_y_test_BernoulliNB)) print(metrics.confusion_matrix(y_test,pre_y_test_BernoulliNB)) end_time=datetime.datetime.now() time_BernoulliNB=end_time-start_time print("time:",time_BernoulliNB) #SVM print('SVM') start_time=datetime.datetime.now() clf_SVM=svm.SVC() clf_SVM.fit(x_train,y_train) pre_y_train_SVM=clf_SVM.predict(x_train) pre_y_test_SVM=clf_SVM.predict(x_test) print('train_SVM') print(clf_SVM.score(x_train,y_train)) print(metrics.classification_report(y_train,pre_y_train_SVM)) print(metrics.confusion_matrix(y_train,pre_y_train_SVM)) print('test_SVM') SVM_score=clf_SVM.score(x_test,y_test) print(SVM_score) print(metrics.classification_report(y_test,pre_y_test_SVM)) print(metrics.confusion_matrix(y_test,pre_y_test_SVM)) end_time=datetime.datetime.now() time_SVM=end_time-start_time print("time:",time_SVM) #GBM print('GBM') start_time=datetime.datetime.now() clf_GBM=GradientBoostingClassifier() clf_GBM.fit(x_train,y_train) pre_y_train_GBM=clf_GBM.predict(x_train) pre_y_test_GBM=clf_GBM.predict(x_test) print('train_GBM') print(clf_GBM.score(x_train,y_train)) print(metrics.classification_report(y_train,pre_y_train_GBM)) print(metrics.confusion_matrix(y_train,pre_y_train_GBM)) print('test_GBM') GBM_score=clf_GBM.score(x_test,y_test) print(GBM_score) print(metrics.classification_report(y_test,pre_y_test_GBM)) print(metrics.confusion_matrix(y_test,pre_y_test_GBM)) end_time=datetime.datetime.now() time_GBM=end_time-start_time print("time:",time_GBM) #XGBoost print('XGBoost') start_time=datetime.datetime.now() clf_XGBoost=xgboost.XGBClassifier() clf_XGBoost.fit(x_train,y_train) pre_y_train_XGBoost=clf_XGBoost.predict(x_train) pre_y_test_XGBoost=clf_XGBoost.predict(x_test) print('train_XGBoost') print(clf_XGBoost.score(x_train,y_train)) print(metrics.classification_report(y_train,pre_y_train_XGBoost)) print(metrics.confusion_matrix(y_train,pre_y_train_XGBoost)) print('test_XGBoost') XGBoost_score=clf_XGBoost.score(x_test,y_test) print(XGBoost_score) print(metrics.classification_report(y_test,pre_y_test_XGBoost)) print(metrics.confusion_matrix(y_test,pre_y_test_XGBoost)) end_time=datetime.datetime.now() time_XGBoost=end_time-start_time print("time:",time_XGBoost) #RandomForestClassifier print('RFC') start_time=datetime.datetime.now() clf_RFC=RandomForestClassifier() clf_RFC.fit(x_train,y_train) pre_y_train_RFC=clf_RFC.predict(x_train) pre_y_test_RFC=clf_RFC.predict(x_test) print('train_RFC') print(clf_RFC.score(x_train,y_train)) print(metrics.classification_report(y_train,pre_y_train_RFC)) print(metrics.confusion_matrix(y_train,pre_y_train_RFC)) print('test_RFC') RFC_score=clf_RFC.score(x_test,y_test) print(RFC_score) print(metrics.classification_report(y_test,pre_y_test_RFC)) print(metrics.confusion_matrix(y_test,pre_y_test_RFC)) end_time=datetime.datetime.now() time_RFC=end_time-start_time print("time:",time_RFC) #Keras print('Keras') start_time=datetime.datetime.now() model=Sequential() model.add(Dense(units=13,input_shape=(13,))) model.add(Activation('relu')) model.add(Dense(100)) model.add(Activation('relu')) model.add(Dense(100)) model.add(Activation('relu')) model.add(Dense(6)) model.add(Activation('softmax')) model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy']) y_train_ohe=np_utils.to_categorical(y_train,6) y_test_ohe=np_utils.to_categorical(y_test,6) model.fit(x_train,y_train_ohe,epochs=50,batch_size=1,verbose=2,validation_data=(x_test,y_test_ohe)) loss,accuracy=model.evaluate(x_test,y_test_ohe) print(loss,accuracy) classes=model.predict(x_test,batch_size=1,verbose=2) end_time=datetime.datetime.now() time_Keras=end_time-start_time print("time:",time_Keras) #Matplotlib model=['tree','MultinomialNB','GaussianNB','BernoulliNB','SVM','GBM','XGBoost','RFC'] column=['Score','Time'] datas=[] for i in model: data=[] data.append(eval(i+"_score")) data.append(eval("time_"+i).total_seconds()) datas.append(data) df_Matplotlib=pandas.DataFrame(datas,columns=column,index=model) print(df_Matplotlib) print('Keras',loss,accuracy,time_Keras.total_seconds()) df_Matplotlib.plot() plt.grid() plt.show()
输出结果:
Risk Risk high 105 low 165 medium 108 no 483 very_high 39 Risk Age Trestbps Risk 1.000000 0.230261 0.160204 Age 0.230261 1.000000 0.280738 Trestbps 0.160204 0.280738 1.000000
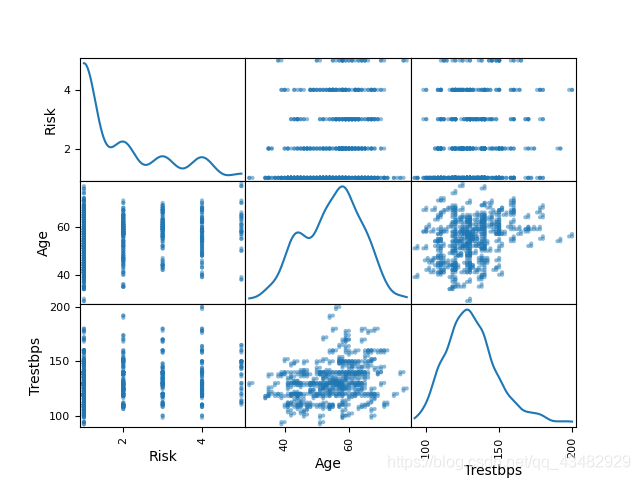
Score Time tree 0.916667 0.012999 MultinomialNB 0.472222 0.007978 GaussianNB 0.594444 0.011939 BernoulliNB 0.533333 0.012960 SVM 0.527778 0.049867 GBM 0.894444 0.642369 XGBoost 0.933333 0.319671 RFC 0.933333 0.271275 Keras 1.0383968353271484 0.7444444298744202 32.102378
越努力越幸运!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号