C++11/14笔记
这篇文章记录了学习侯捷老师C++11/14课程的笔记。C++11是C++2.0,引入了许多新的特性,将从语言层面和标准库层面来介绍这些新的特性。
可以在https://github.com/FangYang970206/Cpp-Notes/releases下载完整pdf版本的笔记,转载请注明地址,谢谢~
语言层面
怎样确定C++环境是否支持C++11呢?
使用如下语句:
cout << __cplusplus << endl;
如果出现的头六位数是大于等于201103的,则支持C++11。
模板表达式中的空格

在C++11之前,模板后面的尖括号需要空格,C++11之后就不需要了。
nullptr和std::nullptr_t

使用nullptr代替NULL和0来代表指针没有指向值。这可以避免把空指针当int而引发错误。上图中给出了函数调用的实例,使用nullptr不会出现这种问题,这是因为nullptr是std::nullptr_t类型,c++11以后,std::nullptr_t也是基础类型了,可以自己定义变量。
自动推导类型----auto

C++11之后,可以使用auto自动推导变量和对象的类型,而不需要自己手写出来,对于有非常复杂而长的类型来说,这是很方便的,另外auto还可以自动推导lambda表达式的类型,然后就可以把lambda函数当普通函数使用。
典型用法(更简单):

标准库中的使用:

一致性初始化----Uniform Initialization

C++11引入了一个通用的初始化方式——一致性初始化,使用大括号括起来进行初始化,编译器看到这种初始化会转换成一个initializer_list
- 如果对象带有接受initializer_list
的构造函数版本,那使用该构造函数进行初始化。(如上vector 初始化) - 如果对象没有initializer_list
的构造函数版本,那编译器会将initializer_list 逐一分解,传给对应的构造函数。(如上complex初始化)
另外,如果函数的参数就是initializer_list
初始化列表(initializer_list)

大括号可以设定初值(默认值),另外,大括号初始化不允许窄化转换(书籍上这样说的,实际gcc只会给出警告,但这不是好习惯)。

C++11提供了一个std::initializer_list<>, 可以接受任意个数的相同类型,上面是一个实例。
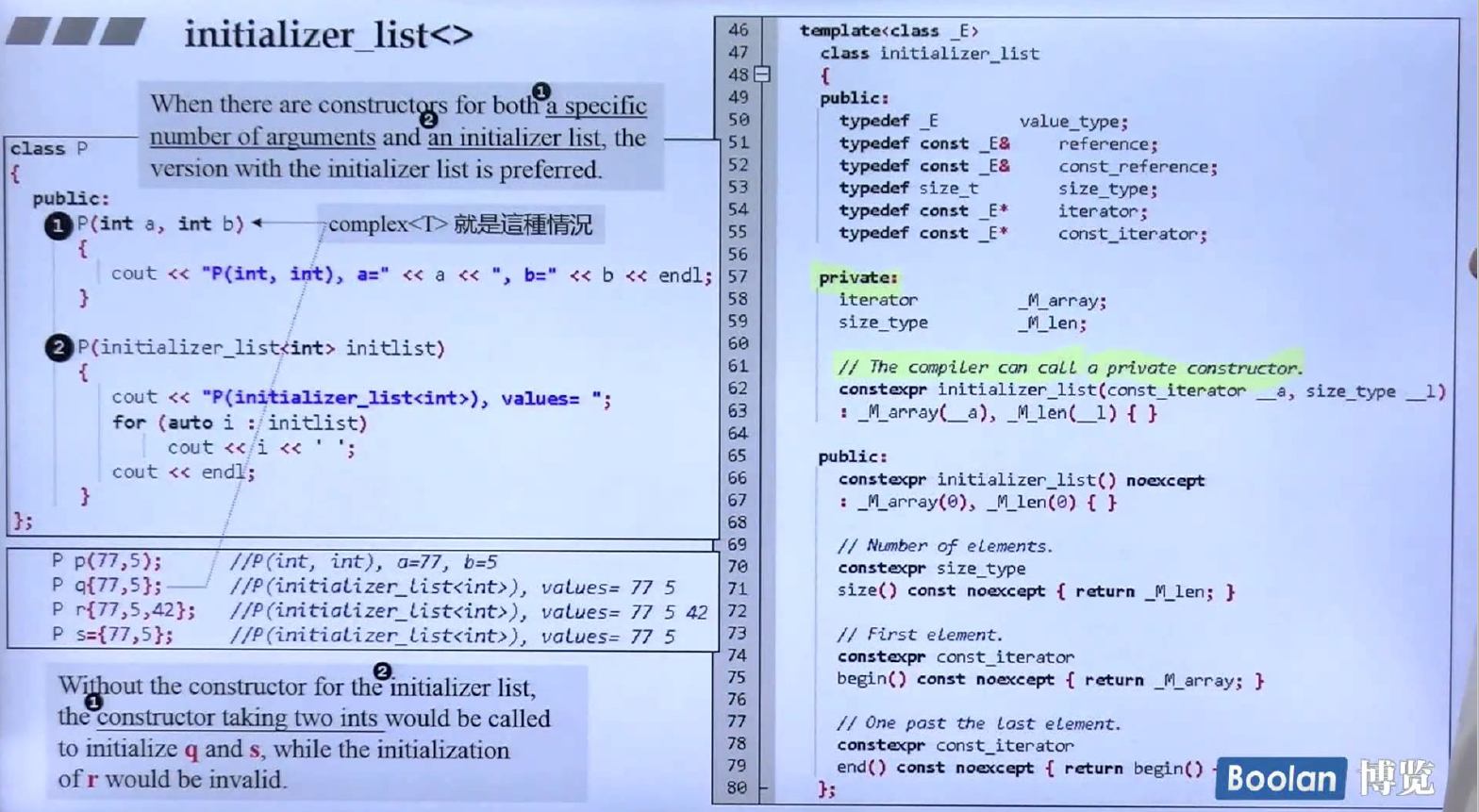
上图的左边是initializer_list在构造函数中的应用,右边是initializer_list的源代码,它的内部有一个array和一个长度,另外initializer_list的构造函数是私有的,但编译器当看到大括号的时候,就会调用这个构造函数,编译器有无上权力。initializer_list构造函数会传入array(C++11新提出的,对数组进行封装,可以使用算法库)的头部迭代器,以及它的长度。

上面是array的源代码,里面就是一个基本的数组,然后封装了begin和end迭代器。
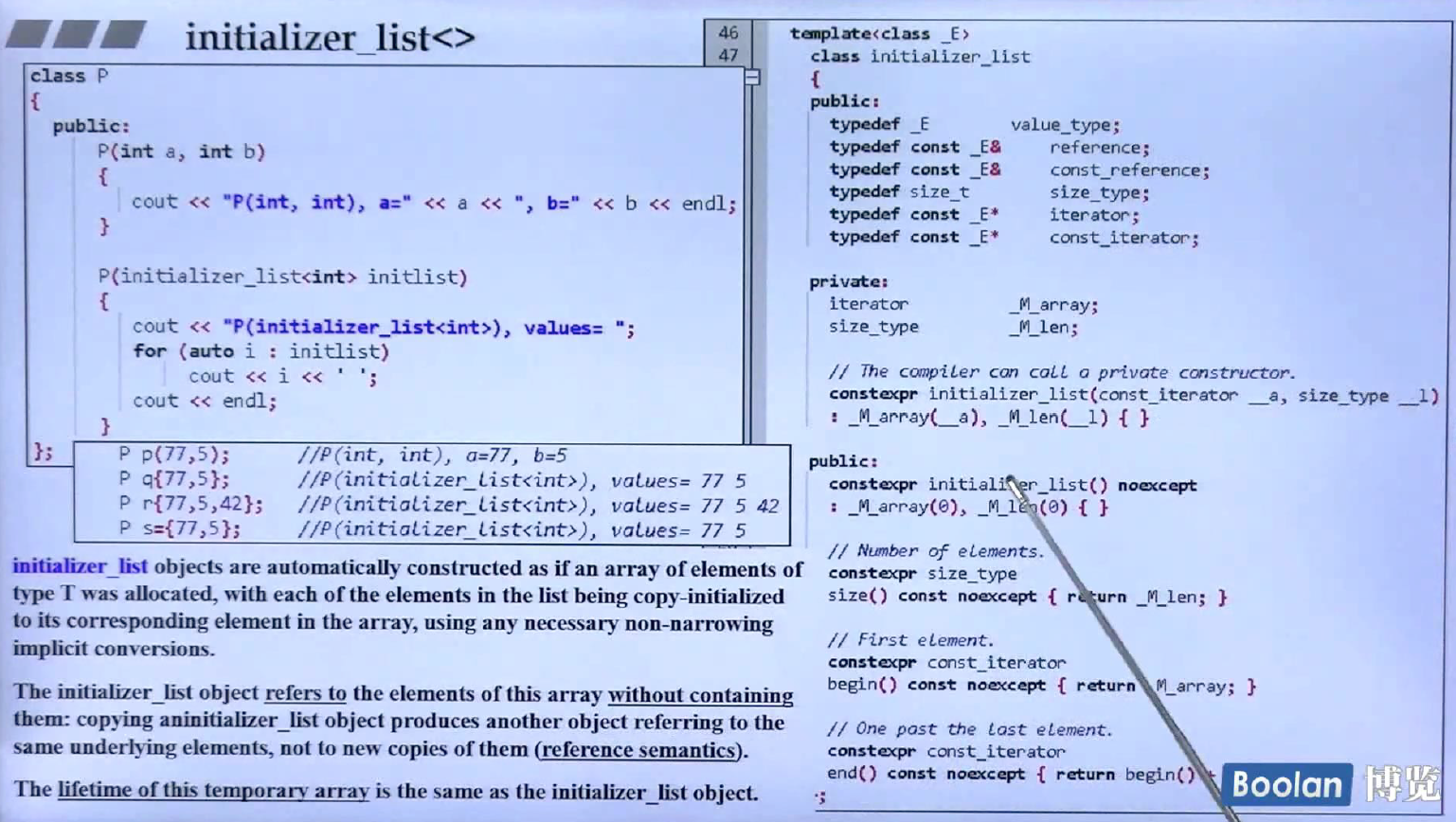
左下角是新东西,其他的之前出现过了,第一句话是指initializer_list背后有一个array在支撑,第二句话是说initializer_list并没有包含那个array,只是有一个指针指向那个array的头部和一个size_t等于array的长度。如果拷贝initializer_list,只是浅拷贝,指向同一个array以及得到同一个长度。最后一句话是说那个临时array的生命周期与initializer_list是相同的。

这是标准库中使用initializer_list的各个地方,非常之多,这里只列举vector里面的使用,有初始化,重载赋值运算符,插入以及分配。
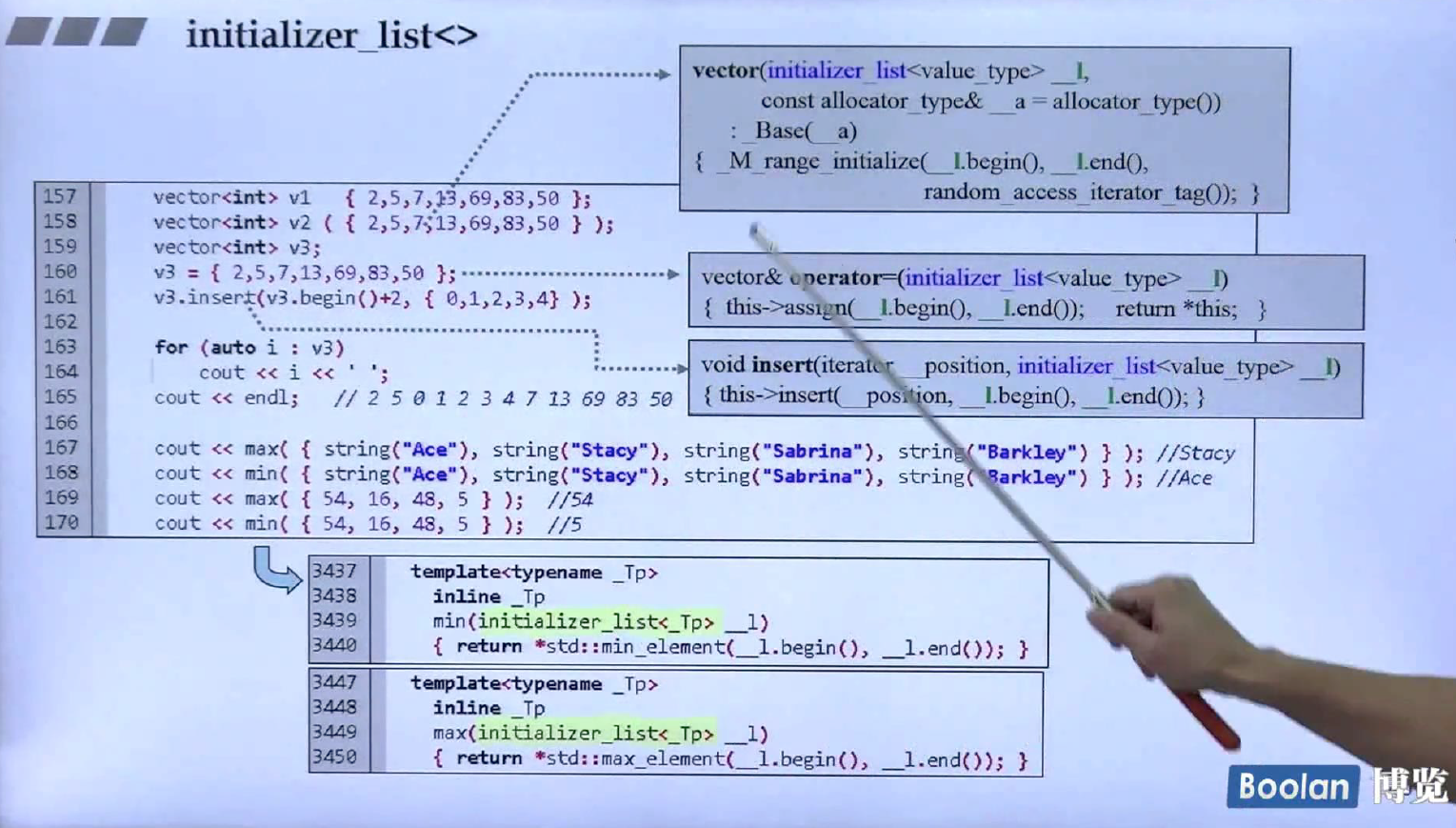
上面的是具体事例以及对应调用有initializr_list的方法。
explicit

这节在C++面向对象高级编程中有很多的补充,可以去看看,在构造函数前面加上explicit, 就是告诉编译器, 不要在将int类型隐式转成Complex, 只能通过显式地进行构造。

之前一张图是只有一个实参,这里是多个实参的例子,当使用运行p3{77, 5, 42}的时候,直接调用的是带有initializer_list的构造函数(一致性初始化),而p5 = {77, 5, 42}, {77, 5, 42}是initialization_list
range-based for

这一小节讲的是非常实用的for,C++11提供了range-based for,如上所述,decl是申明,coll是容器,意思是一个个拿出coll中的元素,下面有实例,可以搭配auto使用,非常方便,需要in-place的话,加上&即可。
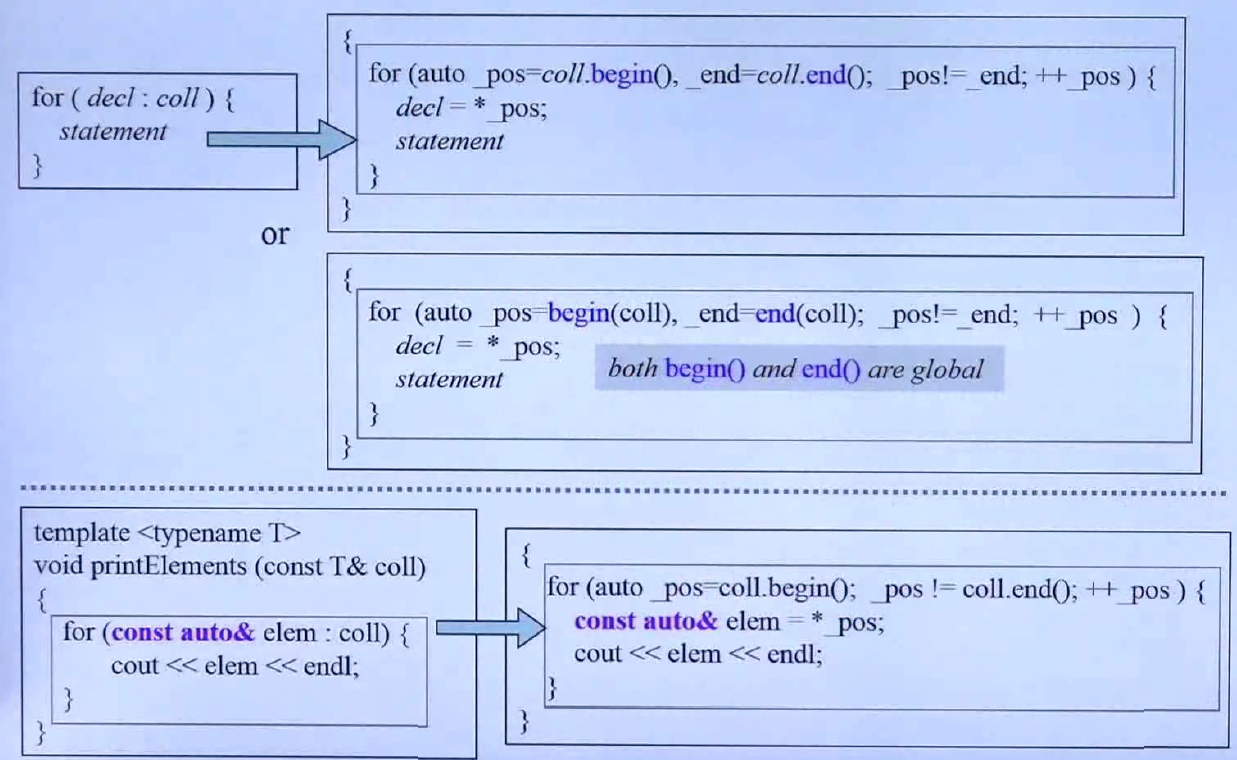
左边是range-based for,右边是编译器对它的解释。

这是explicit的一个例子,禁止编译器隐式将String转化C,所以会报错。
=default, =delete

=default要的是编译器给的default ctor,=delete是不要对应的ctor,例如,上述的Zoo(const Zoo&)=delete是说不要拷贝构造,Zoo(const Zoo&&)=default是说要编译器默认给我的那一个。
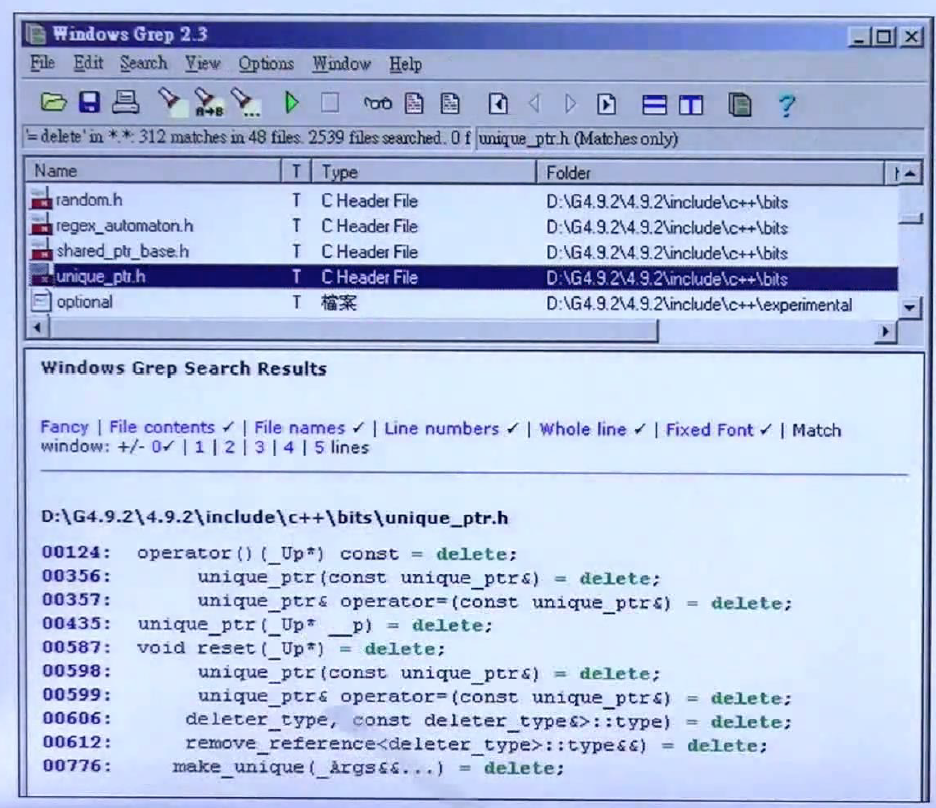
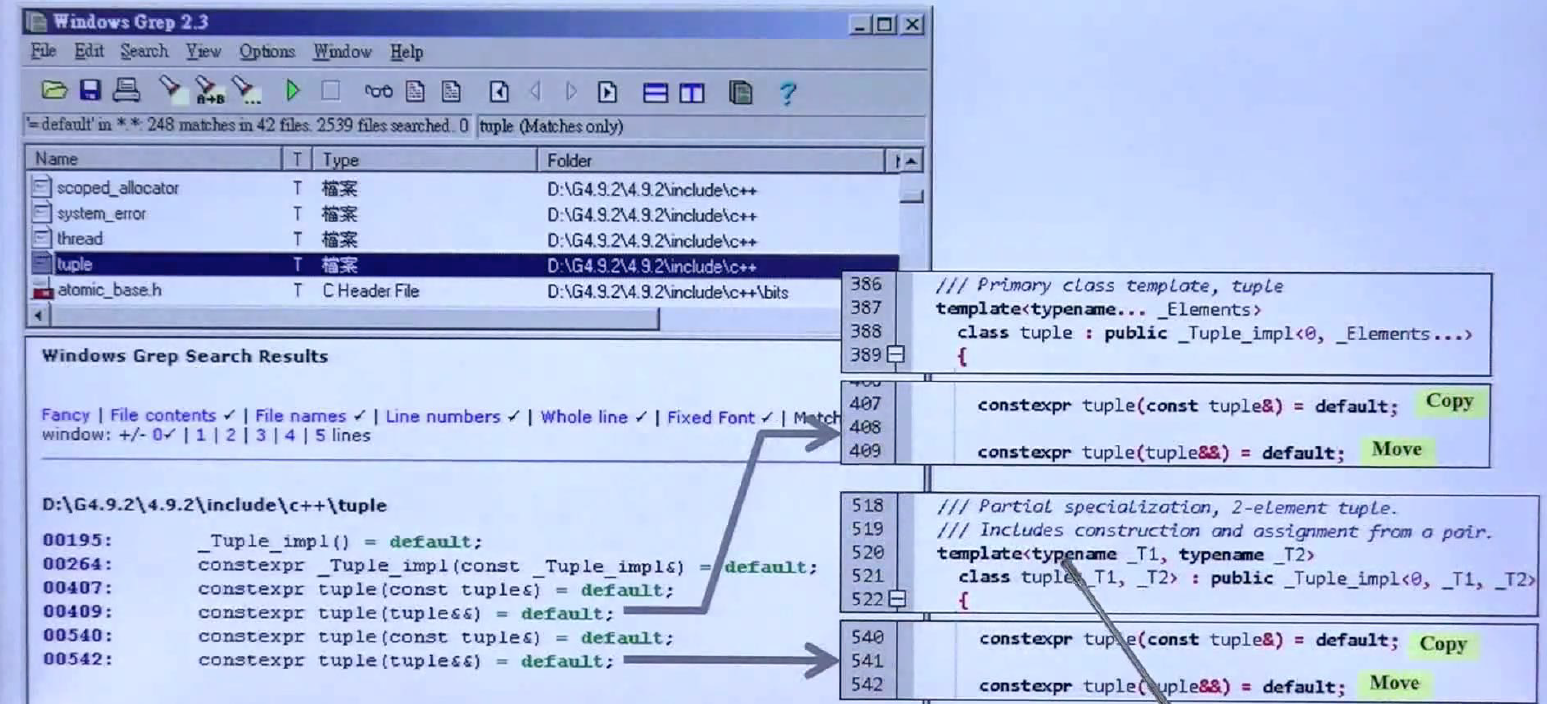
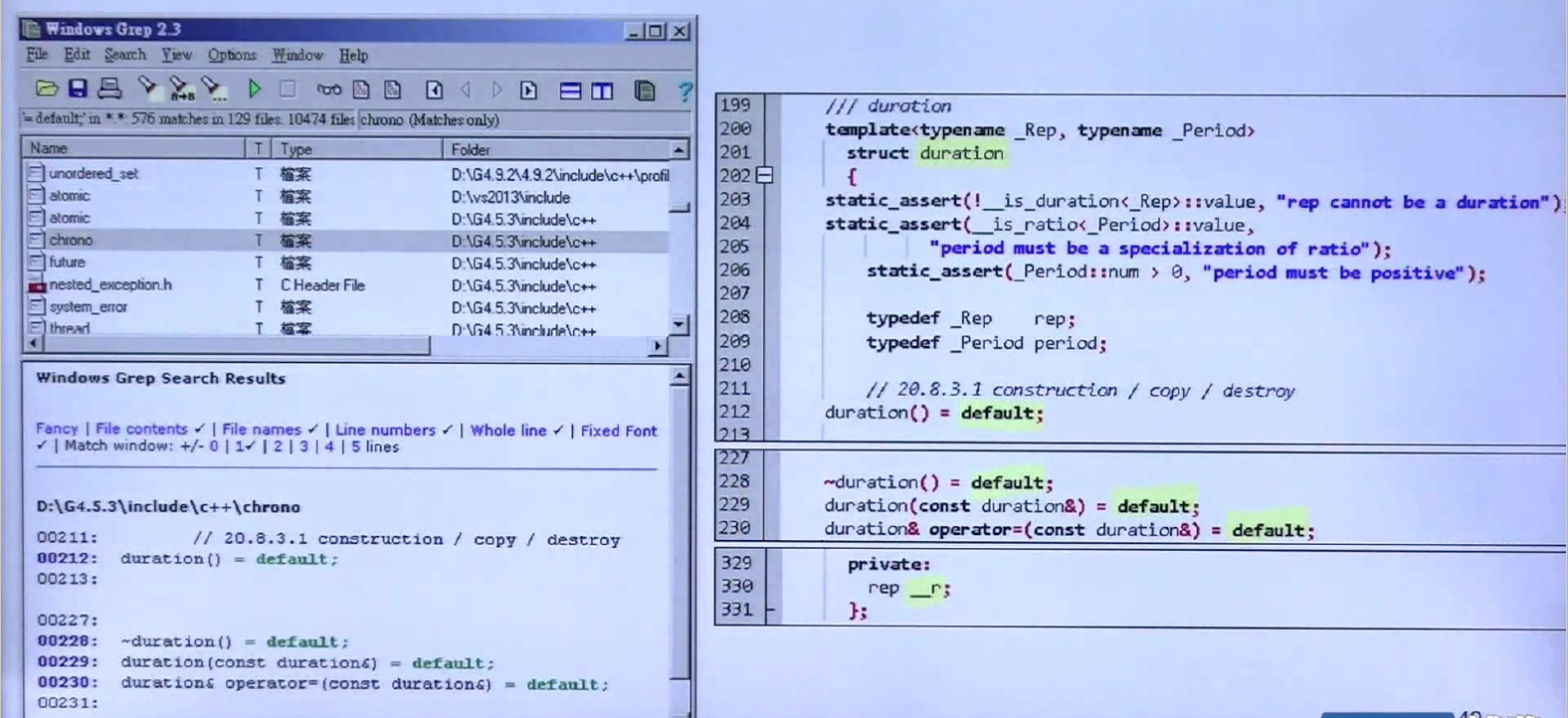
以上三张图是C++标准库中使用=default和=delete的事例,标准库都用了,那自然是好的。(这里注意析构函数不能用=delete,可能会出大问题)

构造函数可以有多个版本,上述定义了两个Foo的构造函数,一个是有实参的,另一个使用=default得到编译器默认给出的构造函数。对于拷贝构造而言,只能允许一个,所以当使用=default的时候,由于已经写出一个了,就无法进行重载了,而使用=delete的时候,由于写出来了,无法进行删除了。拷贝赋值情况类似。对于一般函数来说,没有default版本,所以对一般函数进行=default是不对的,但=delete可以有,但没必要,写出来不要还不如不写。上图中还给出了=default,=delete与=0的区别,区别在与=default只能用于big-five(构造函数,拷贝构造,赋值构造,析构,移动构造,移动赋值), =delete可以用于任何函数,但有时没有必要使用,如上面所说,而=0只能用于虚函数,代表纯虚函数。

对于一个空的class,C++会在空的class内部插入一些代码(默认的构造函数,拷贝构造,拷贝赋值以及析构函数,都是public并且是inline的),这样才会使左下角的的代码运行正常,作用还不止这些,这些默认的函数还给编译器放置藏身幕后的一些代码,比如当涉及继承的时候,调用base classes的构造和析构就会对应放置在默认生成的构造和析构当中。

如果一个类带有pointer member,则需要自己定义big-three,而没有pointer member的话,用编译器默认提供的就足够了。上面的complex就是直接使用编译器默认提供的拷贝赋值和析构。更详细的推荐看我写的面向对象程序设计_part1部分的笔记,有非常详细的讲述。

上图是=default和=delete的使用事例,class NoCopy把拷贝构造和拷贝赋值都=delete,也就是没有这两个了,不允许外界去拷贝这个类的对象,这个在一些事例上是有用的。class NoDtor则不要析构函数了,对象创建无法删除,会报错。(一般不会这么使用)最后的PrivateCopy把拷贝构造和拷贝赋值放入了private里面,这限制了访问这两个函数的使用者,一般用户代码无法调用,但友元以及成员可以进行拷贝。

这是一个Boost库的例子,与上述的PrivateCopy一样,它的作用是让其他类继承这个类,这样其他类也拥有noncopyable同样的性质。
Alias Template 与 Template Template parameter
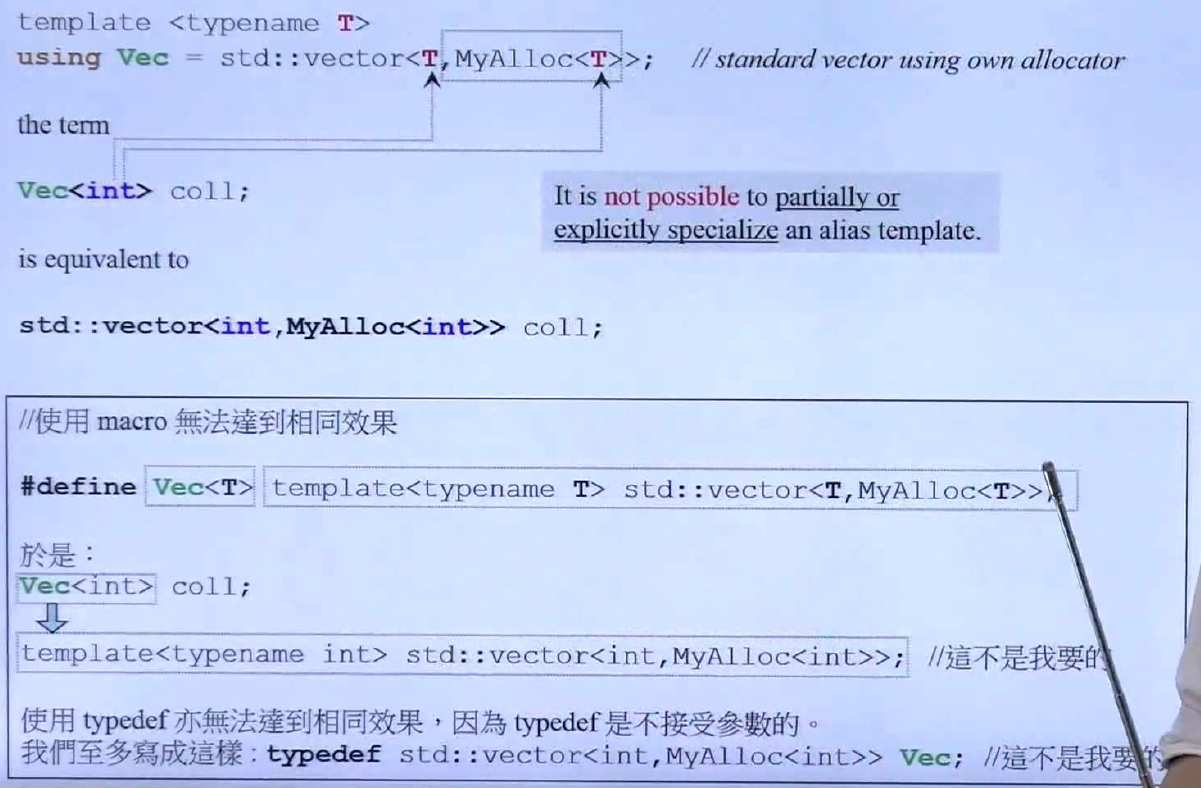
C++11引入了Alias Template,用法如上所示,先些template
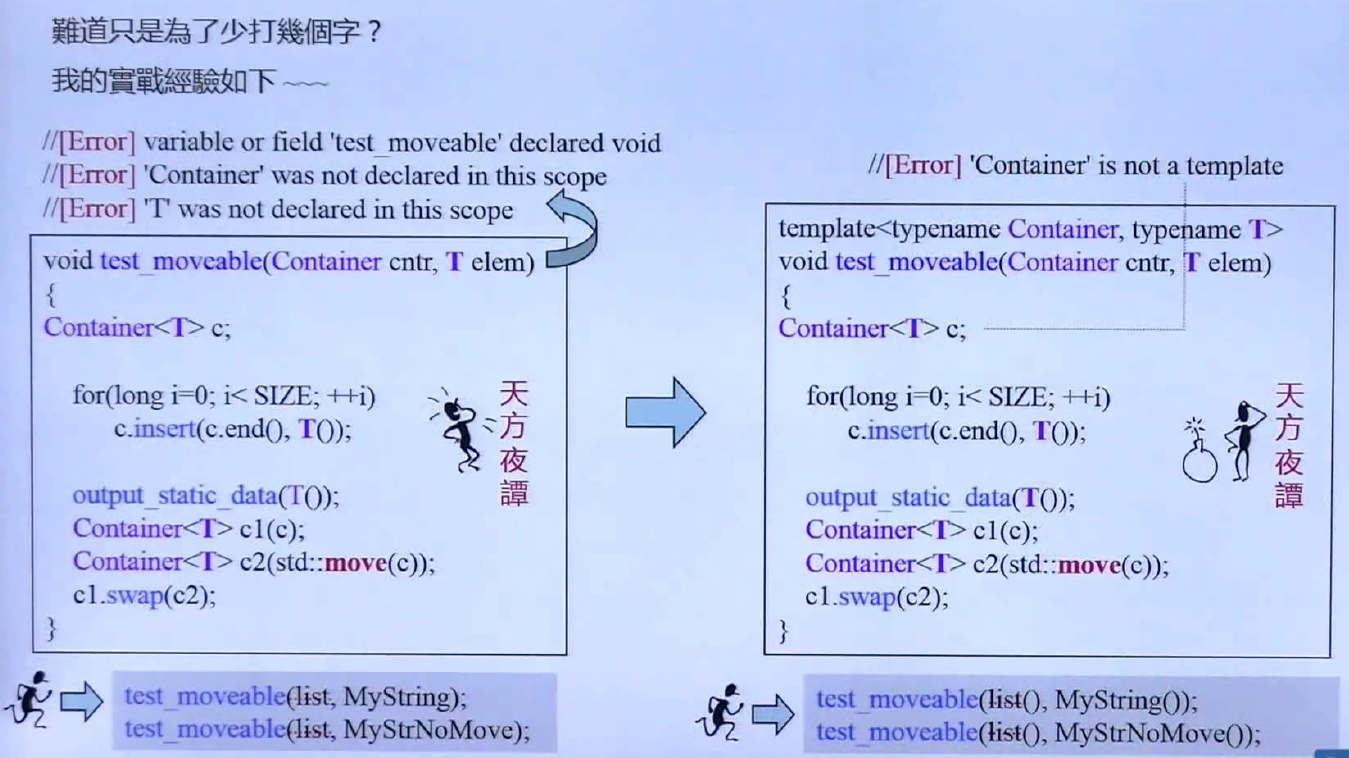
Alias template难道只是少打几个字吗? 不是的,上图进行说明,函数test_moveable测试不同容器的move操作(右值引用)和拷贝操作的时间比较,想使用容器和元素的类型,这是天方夜谈的,container和T是不能再函数内部使用,报出了三个错误。然后再进行改进,改成右边形式的,利用函数模板的实参推导可以推出Container和T的类型,不然依然是天方夜谭,编译器不认识Container是个模板,无法使用尖括号
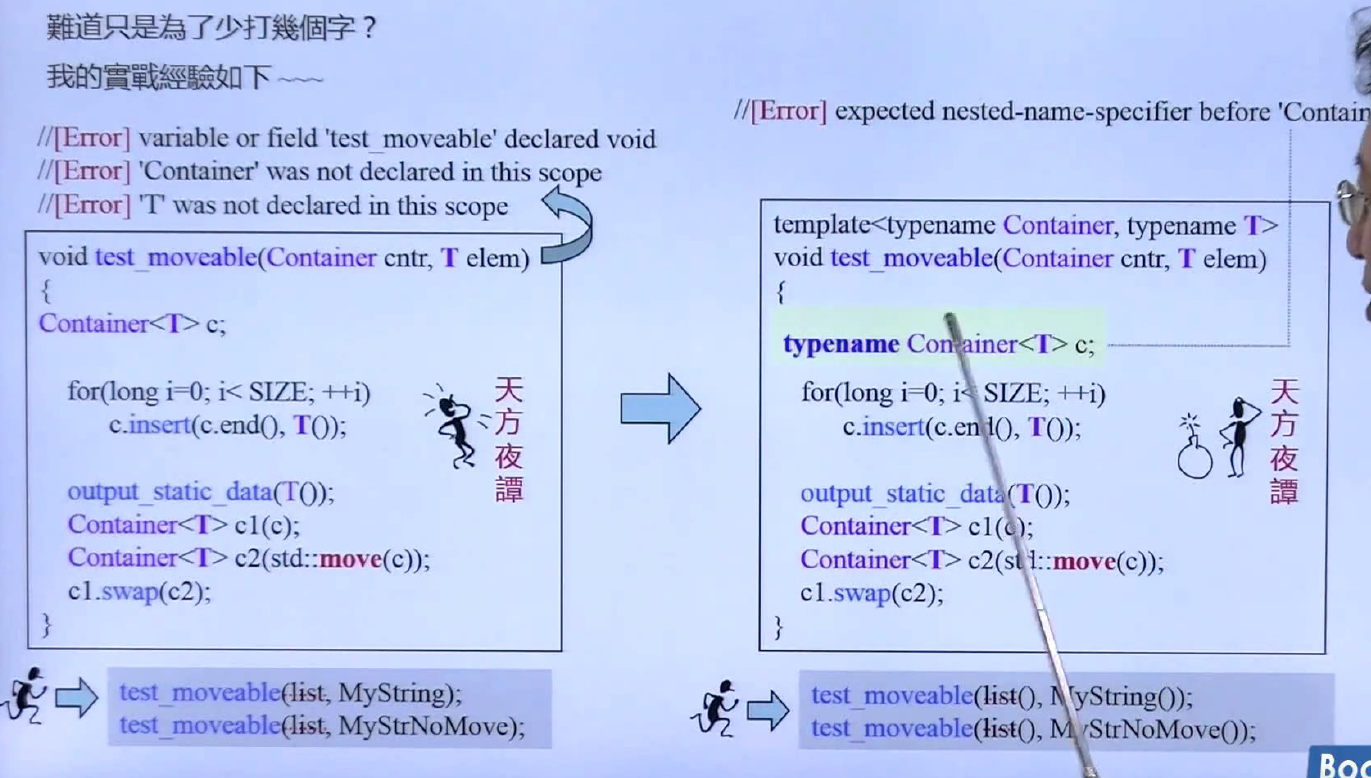
这一页在Container前面加上了typename,告诉编译器Container

上图就是解决方案,传入的实参只有一个,根据模板函数的自动推导,得到它的迭代器(前面要加typename),然后通过一个迭代器萃取机引出对象的Value_type, 然后根据typedef得到值类型,这样就不会报错了。然后看右上角黄色的话语,如果没有iterator和traits,该怎么解决这一问题呢?上面就是思考路径,在模板接受模板,能不能从中取出模板的参数?
这就需要template template parameter了。

模板模板参数是模板嵌套模板,如上面所示,XCI接受两个参数,第一个是T,第二个是模板Container,然后就可以直接使用Container<T> c; 因为Container是一个模板,但再调用XCIs<Mystring, vector> c1;的时候,出现报错,原因是vector有两个模板参数,第二个模板参数(分配器)是默认的,但编译器不知道,这个时候就需要用到Alias Template了。
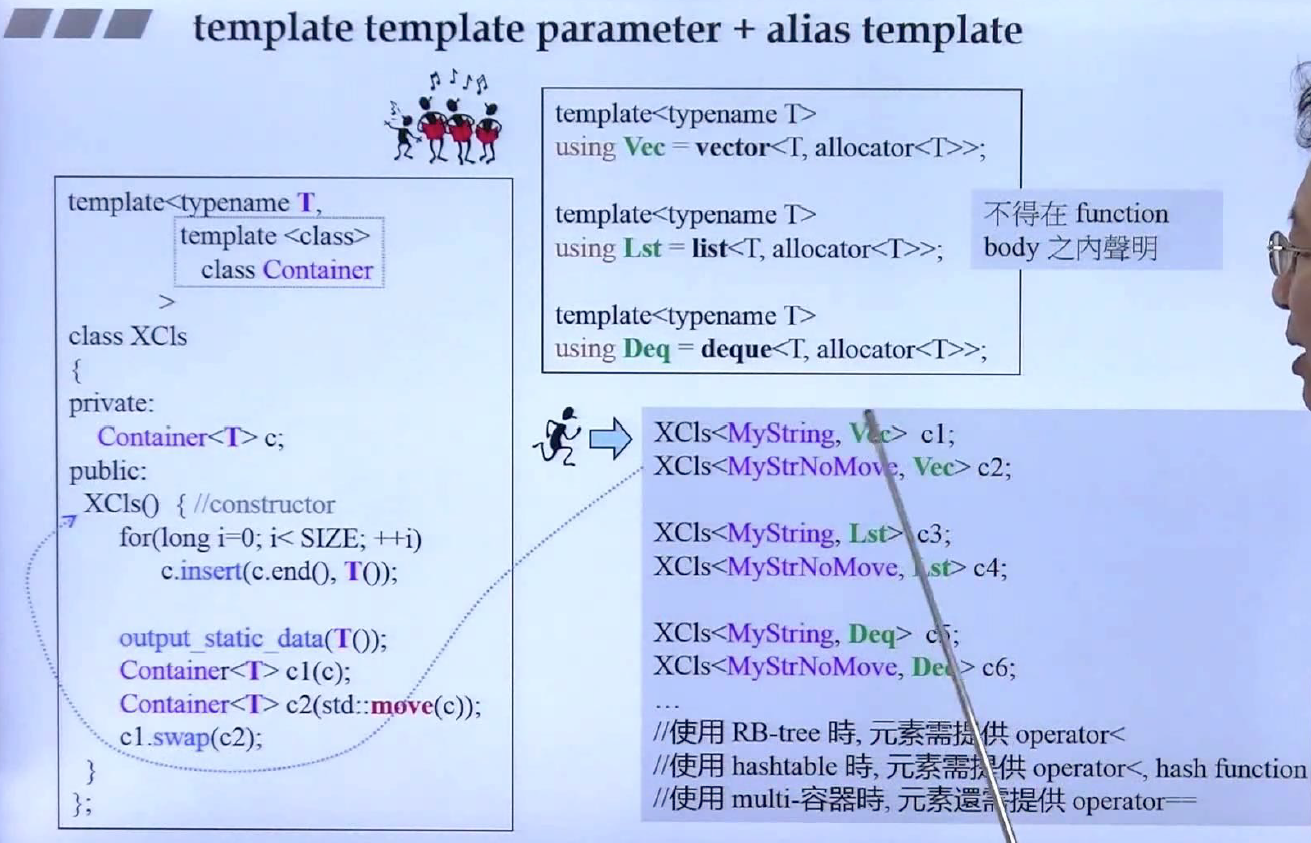
使用Alias Template,就可以将Vec变为一个模板参数的模板,然后就可以初始化对象了。可以看到Alias Template不仅是少打几个字,还有减少模板参数个数以适配模板模板参数,非常有用处。
Type Alias

Type Alias是另一个typedef的写法,不过更加清晰,通过using关键字去实现,左上角的是定义了一个函数指针,用typedef不太明显,用using很清晰,另外还可以用于类中成员,右下角所示。左下角是Alias Template的例子,我们日常使用的string实则是basic_string
using
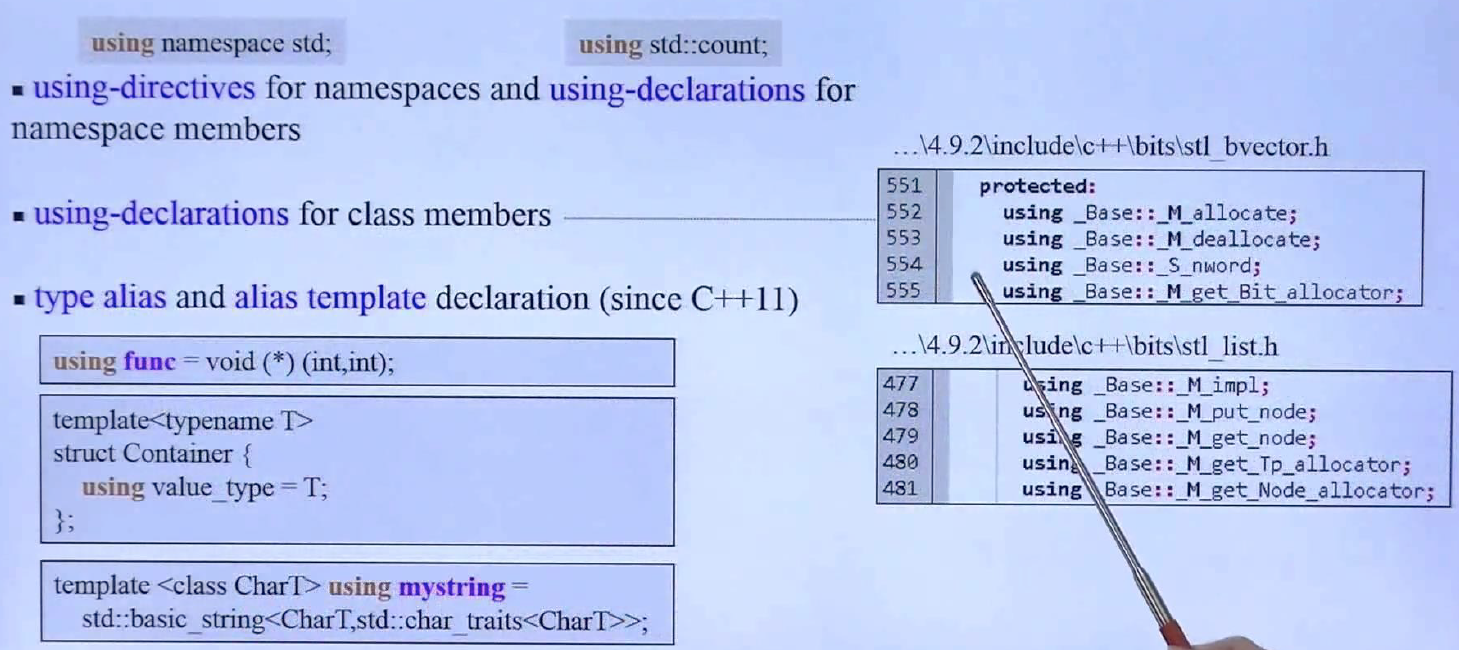
给出了using的使用场景。
noexcept

noexcept是放在函数右括号后,宣称这个函数不会抛出异常(这里还给出异常的回传机制,调用foo如果抛出异常,foo会接着往上层抛出异常,如果最上层没有处理,则会调用terminate函数,terminate函数内部调用abort,使程序退出),noexcept可以接受条件,如上所示,没有加条件,默认是不会抛出异常,swap函数不发生异常的条件是noexcept(x.swap(y))不会发生异常。
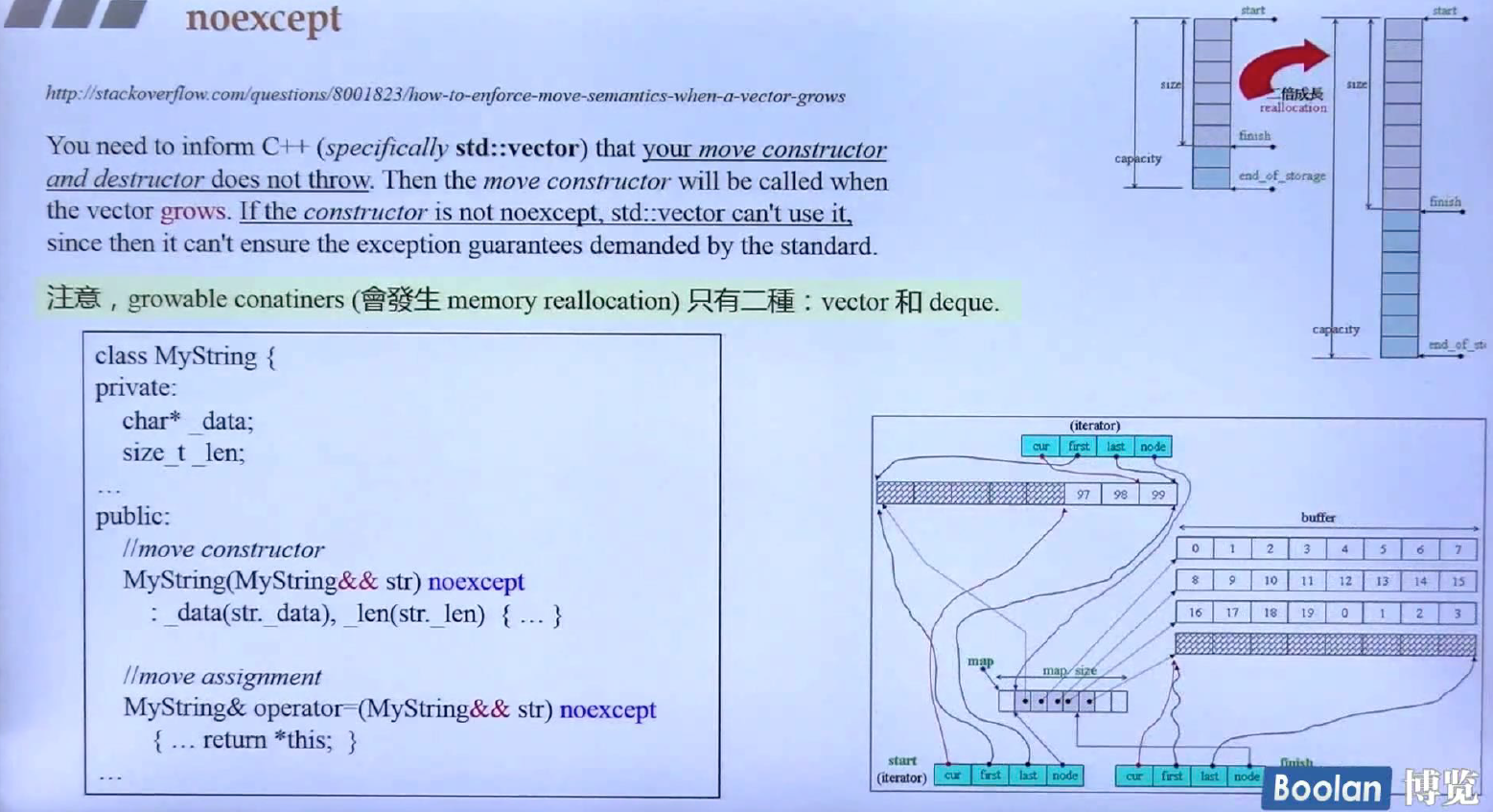
在使用vector和deque的移动构造和移动赋值的时候,如果移动构造和移动赋值没有加上noexcept,则容器增长的时候不会调用move constructor,效率就会偏低(逐一拷贝),所以后面需要加上noexcept,安心使用。
override

override用于虚函数,上面的virtual void vfunc(int)实际上不是重写父类的虚函数,而是定义一个新的虚函数,我们的本意是重写虚函数,但这样写编译器不会报错,确实没问题,那如果像下面加上override的话,则会报错,因为已经告诉了编译器,我确实要重写,但写错了,没有重写,于是就报错了。
final

final关键字用于两个地方,第一个用在类,用于说明该类是继承体系下最后的一个类,不要其他类继承我,当继承时就会报错。第二个用在虚函数,表示这个虚函数不能再被override了,再override就会报错。
decltype

使用decltype关键字,可以让编译器找到一个表达式它的类型,这个很像typeof的功能,然而已存在的typeof的实现并无完整和一致,所以C++11介绍了一个新的关键字,上面给出了一个事例(coll可能离elem很远)。
decltype的应用有三部分,用作返回值的类型,元编程以及lambda函数的类型

上图就是用作返回值的类型,图中第一个代码块编译无法通过,因为return表达式所用的对象没有在定义域内。C++11则允许另外一种写法,第二个代码块,返回类型用auto暂定,但在后面写出,用-> decltype(x+y), 这里要说明,模板是一种半成品,类型没有定义,decltype(x+y)也能是正确的也可能是错误的,取决于调用者本身的使用。-> decltype(x+y)与lambda的返回类似。
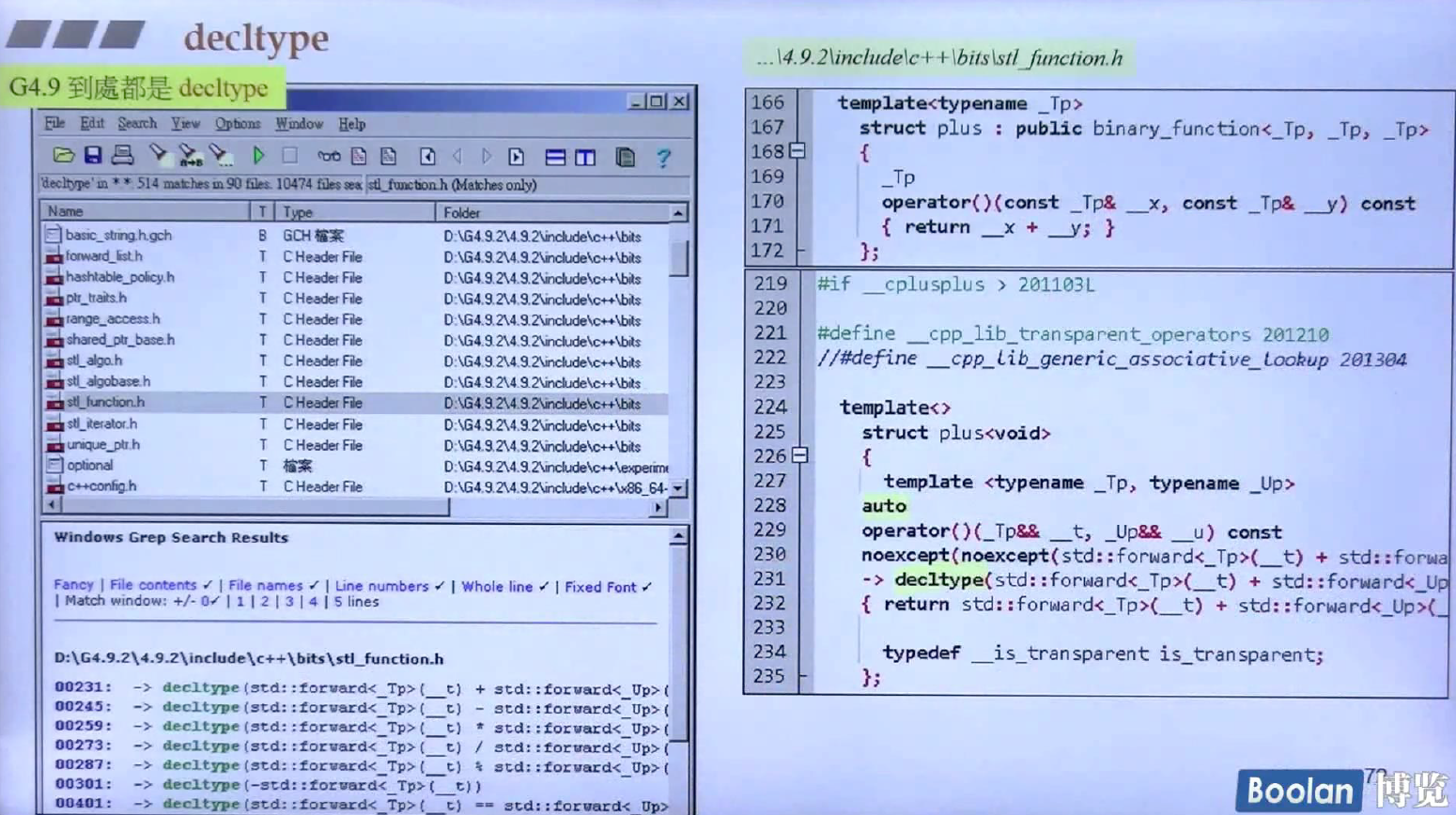
上图是decltype在标准库中的使用,到处可见。

用于元编程推导实参的类型,由于加了::iterator, 传入的实参必须是容器,传入复数会报错,这就是模板的半成品特性。

对于lambda函数,很少有人能够写出它的类型,而有时就需要知道它的类型,如上定义所示,这时候就可以使用decltype来自动推导lambda函数的类型。
lambdas

C++11介绍了lambdas(可以说是匿名函数或仿函数),允许定义在声明和表达式中,作为一种内联函数。如上所示,最简单的lambda通过一个[]{statements}表示,可以直接加()运行,或者使用auto l = []{statements},l则代表lambda函数,可以在后面进行调用。

上面是lambdas函数的结构类型,中括号[]内部是可以抓取外面的非静态对象进行函数内部的使用,有以值[=]进行抓取和以引用[&]进行抓取,如果只抓取部分对象,可以进行指定,如上面的x,y,x就是按值进行抓取,y就是按引用进行抓取。小括号()里面则是可以接函数参数,跟普通函数一样。mutable可选,指的是以值进行抓取的对象是否可变,可变就需要加上,否则会报错。throwSepc是指这个函数可以不可以抛出异常。->retType指的是lambda函数的返回类型。大括号内部则是函数的主体。

上面是一个事例,这页幻灯片说的是lambda函数映射类似一个仿函数和mutable的作用,之所以说类似,这是因为如果lambda以值传递,则要修改值对象,需要加上mutable,否则会报错,而仿函数没有限制。

这页幻灯片是上页的比较,要修改以值传递的对象,需要加mutable,如果是按引用传递的对象,则可以不加,如果修改以值传递的对象而不加mutable,则会报错read-only. 此外,以引用传递的对象,不仅会受lambda函数内部的影响,还会受到外部的影响。另外,在lambda函数中,可以申明变量和返回数值。

上图是编译器给lambda函数生成得代码,可以看到就是一个仿函数(重载了小括号操作符)的类,用lambda形式写非常简洁,并且要高效一些(inline)。

这张图的最上面是说每一个lambda函数都是独特的,要申明lambda对象的类型,可以使用template或者auto进行自动推导。如果需要知道类型,可以使用decltype,比如,让lambda函数作为关联容器或者无序容器的排序函数或者哈希函数。上面代码给出了事例(decltype的第三种用法中的事例),定义了一个lambda函数用cmp表示,用来比较Person对象的大小,传入到Set容器中去,但根据右边的set容器的定义,我们传入的不仅是cmp(构造函数),还要传入模板的cmp类型(Set内部需要声明cmp类型),所以必须使用decltype来推导出类型。(如果没有向构造函数传入cmp,调用的是默认的构造函数,也就是set() : t(Compare()), 这里会报错, 因为Compare()指的是调用默认的lambda构造函数,而lambda函数没有默认构造函数和赋值函数)

函数对象是很强大的,封装代码和数据来自定义标准库的行为,但需要写出函数对象需要写出整个class,这是不方便的,而且是非本地的,用起来也麻烦,需要去看怎样使用,另外编译出错的信息也不友好,而且它们不是inline的,效率会低一些(算法效率还是最重要的)。而lambda函数的提出解决了这个问题,简短有效清晰,上面的事例很好的说明了这个问题,用lambda要简短许多,功能一样,很直观。
Variadic Template (重磅原子弹)
print函数的例子

Variadic Template是指数量不定,类型不定的模板,这是C++11原子弹级别的炸弹,如上所示的print函数,可以看到接受了不同类型的参数,调用的函数就是拥有Variadic Template的函数,print(7.5, "hello", bitset<16>(377), 42)运行的时候,首先会7.5作为firstArg,剩余部分就是一包,然后在函数内部,继续递归调用print函数,然后把"hello"作为firstArg, 其余的作为一包,一直递归直到一包中没有数据,调用边界条件的print(空函数)结束。
函数的...表示一个包,可以看到,用在三个地方,
-
第一个地方是模板参数
typename...,这代表模板参数包。 -
第二个就是函数参数类型包(
Type&...), 指代函数参数类型包。 -
第三个就是函数参数包
args...,指的是函数参数包。另外,还可以使用
sizeof...(args)得到包的长度。右边的是另外一种类型的print,可以和左边的print共同存在,我测试了一下:
#include <iostream>
#include <bitset>
using namespace std;
void print() {};
template <typename T, typename... Types>
void print(const T& firstArg, const Types&... args)
{
cout << firstArg << endl;
print(args...);
}
template <typename... Types>
void print(const Types&... args)
{
cout << "common print" << endl;
}
int main() {
print(7.5, "hello", bitset<16>(377), 42);
return 0;
}
输出的结果如下:
7.5
hello
0000000101111001
42
可以看到调用的还是左边的print,至于为什么,后面再说!
哈希表的例子
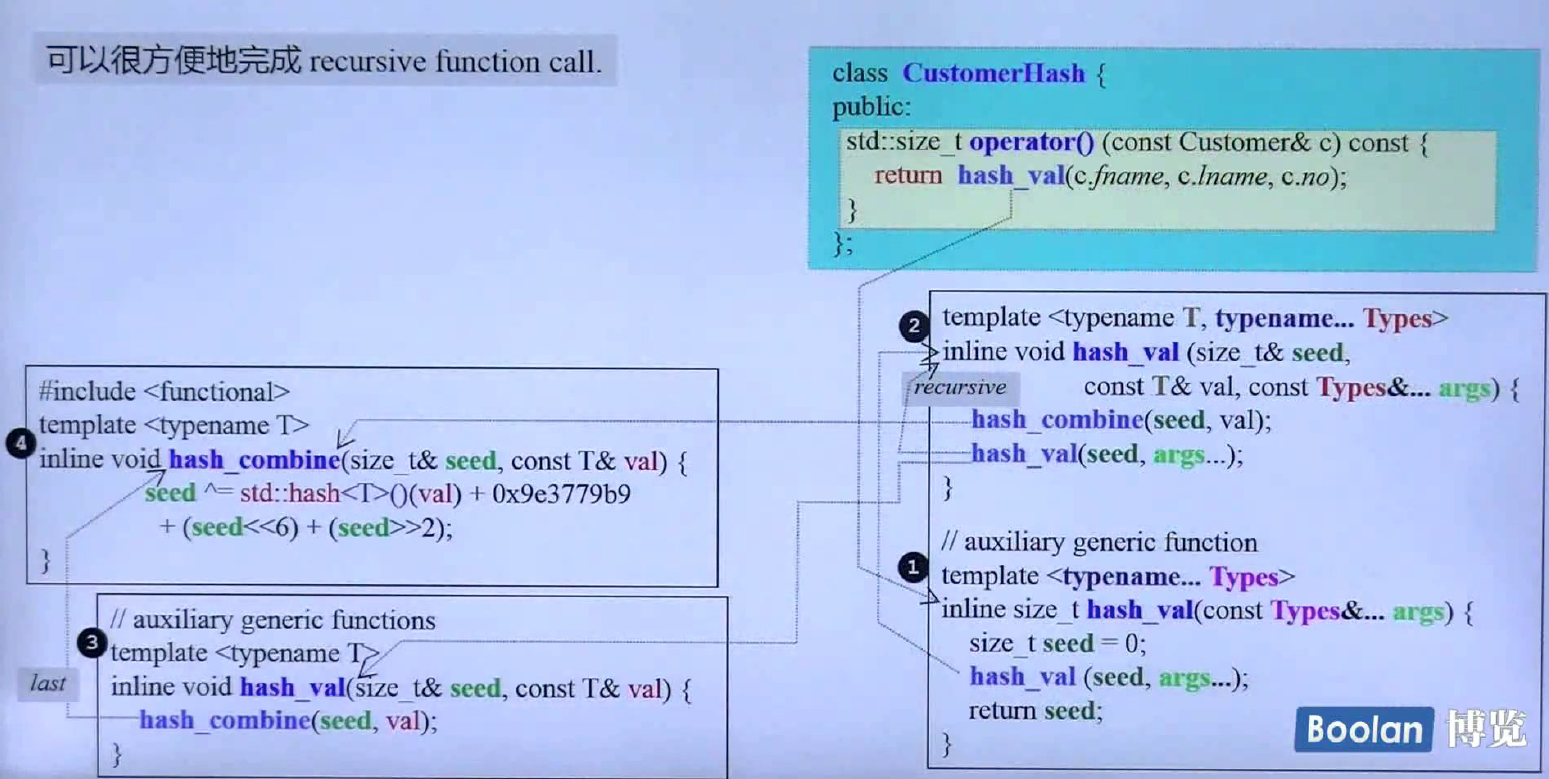
上面这个是用variadic template实现哈希表的过程,CustomerHash重载了小括号操作符,内部调用了hash_val,有三个参数,调用的是前面有圆圈1的hash_val,因为其他的hash_val第一参数不符合,然后这个hash_val函数里面设定种子(seed),调用带有圆圈2的hash_val函数,取出第一个值,调用hash_combine重新设定seed,然后再递归调用圆圈2的hash_val, 再重新得到新种子,直到arg...只有一个参数的时候, 调用圆圈3的hash_val函数,hash_val函数调用hash_combine函数,得到最后的seed,即为哈希值。
tuple

C++11还引入了一种新的容器,名为tuple,可以容纳不同类型的数据,左边是它的简单实现,关注继承那三行代码,可以看到tuple的模板参数是一个Head和一个包...Tail,继承的却是private tuple<...Tail>,而tuple<...Tail>还是tuple,所以又会拆分成tuple<Head, ...Tail>,不断递归,形成一种递归继承,终止条件就是空的tuple类,在左上角定义的,如果定义tuple<int, float, string>,它的具体形式如右上角所示,是不断继承的结构,这就是能容纳不同类型的原因,中上角也是类似的抽象关系。tuple初始化先初始化Head,然后初始化继承的inherited,继承的inherited也会类似初始化,直到到达空的tuple,还给出tuple的两个函数head()和tail(),head()直接返回的是当前类本身的数据(不是从父类继承过来的),而调用tail()返回this指针(指向当前的那一块内存),经过向上转型得到inherited的地址(指向当前继承的那一块)。
以上是开头讲的variadic template,现在进入正式讲解variadic template的环节。

先回顾了template,一般的模板有函数模板,类模板以及成员模板,强大的还是可变化的模板参数,变化表现在参数个数也表现在参数类型,利用参数个数逐一递减的特性,实现函数的递归调用,同时个数上的递减也会导致参数类型也逐一递减,从而实现递归继承(tuple)以及递归复合。最下面的是函数使用variadic template一种常见的写法。

这页幻灯片前面已经讲述了,不过这里给出了之前幻灯片中的一个疑问,print(7.5, "hello", bitset<16>(377), 42)为什么调用左边的函数,而不是右边的,这是因为模板有特化的概念,相对于圆圈3实现的printX(泛化),圆圈1实现的printX更加特化,所以会调用左边的函数。
printf例子

上面这是使用variadic template实现C语言的printf,很简洁的写法。前面的"%d %s %p %f\n"是第一个参数s,后面的参数构造与print类似,一次取一个对象,参数s用以printf里面的循环条件,当*s非空时,
-
如果
*s等于'%'且下一个字符不等于%,则打印取出的对象,同时递归调用printf函数,要对字符指针进行自加移位。 -
如果上述条件不成立,则打印
*s++
最后的终止条件是args...为空,打印完了,调用边界条件的printf,对剩余的*s进行打印,还要进行%判断,因为已经打印完了,还有符合条件的%,则需要抛出异常。
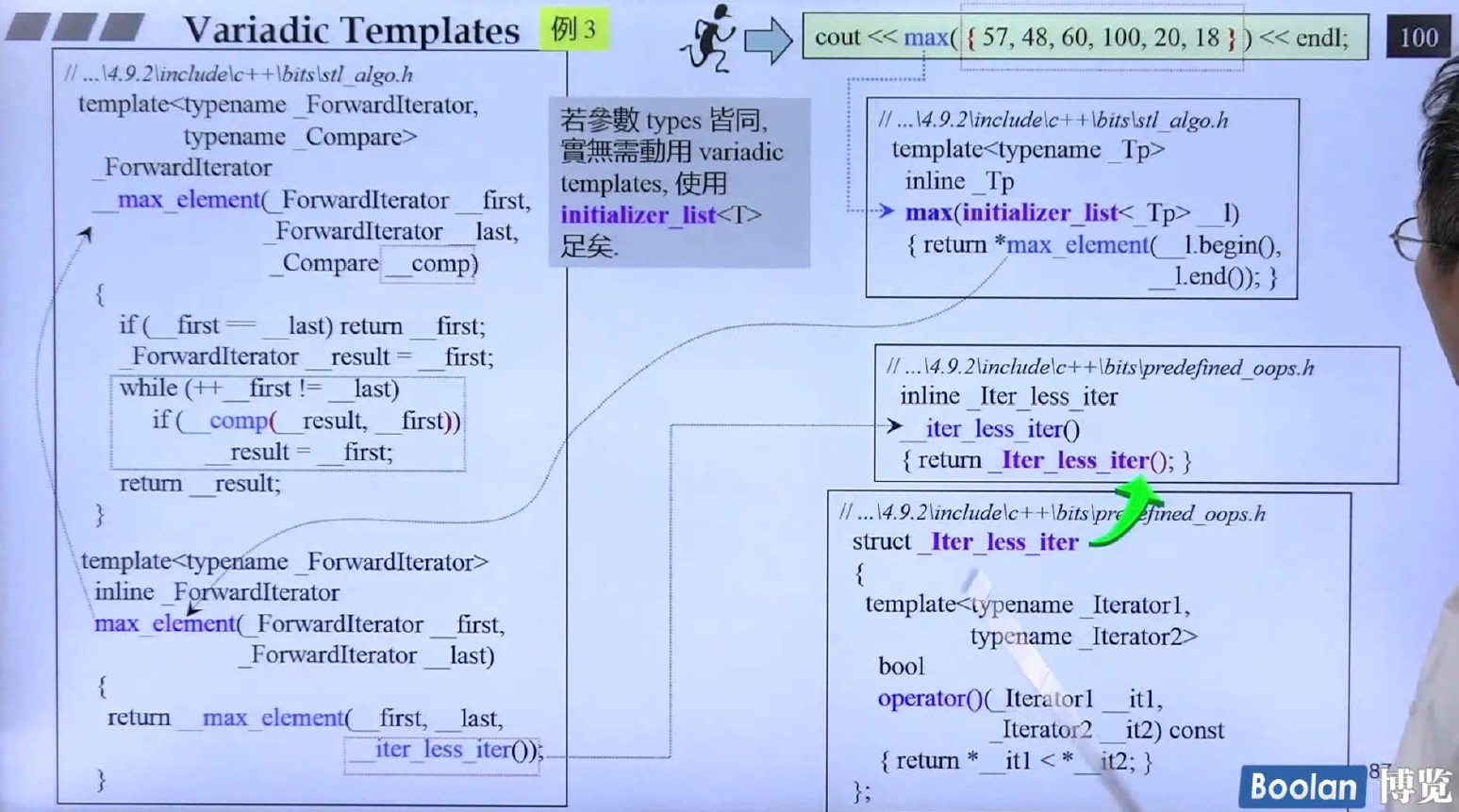
给定一包数据,找出它们的最大值,也可以通过variadic template实现,不过当数据的类型都相同的时候,无需动用大杀器,使用initializer_list足矣。上面是max使用initializer_list的实现,由于使用initializer_list,所以需要讲数据用大括号包起来,编译器会自动生成initializer_list,然后调用max_element函数得到最大值的地址,然后加*得到最大值,而max_element是一个模板函数,调用的是__max_element函数,__max_element函数内部使用了__iter_less_iter类得到一个比大小的临时对象,然后使用临时对象重载操作符的方法对每一个元素进行比较,最后返回最大值的地址。

上面是variadic template实现的方法, 采用的是递归策略,很好懂的。还可以进行改进,讲上图中的int换成模板参数T的话,那么maximum方法就可以接受所有的类型的参数,混合在一起比较(比如double和int混合)。
tuple输出操作符
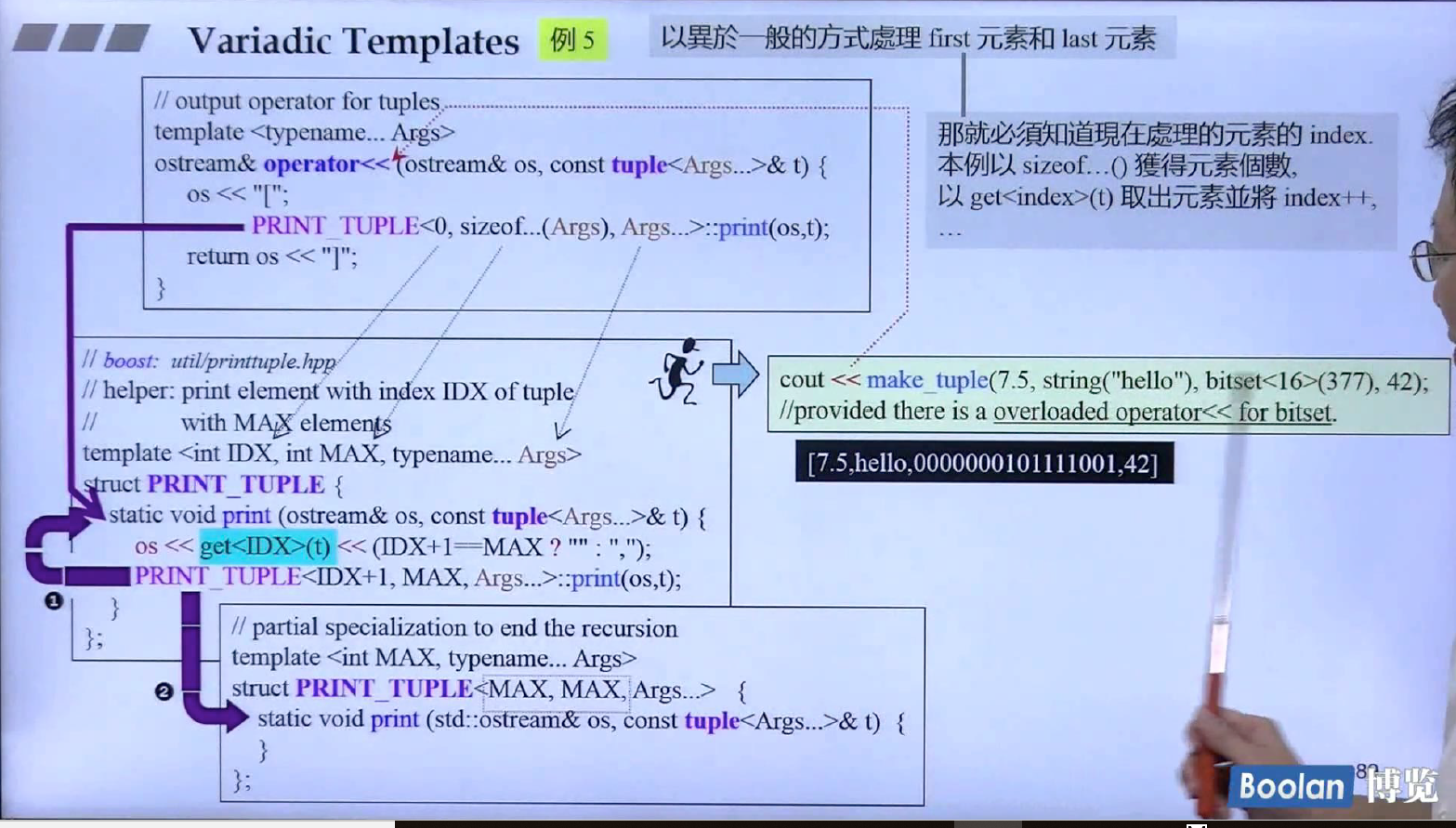
tuple重载的输出流操作符,也使用variadic template,运行右边的那行代码,将得到下面黑色的输出,make_tuple函数是根据参数(可以任意个,内部估计也是使用了variadic template),初始化得到一个tuple,可以看到输出流操作符得第二个参数就是可变模板参数的tuple,内部调用PRINT_TUPLE类中的静态print函数,PRINT_TUPLE有三个模板参数,第一个当前索引IDX,第二个是tuple内含有MAX个对象,第三个就是模板参数包。通过get<IDX>(t)可以得到tuple的第IDX元素,然后进行输出,依次递归调用print函数,如果IDX是最后一个元素了满足IDX+1==MAX, 输出"",然后调用终止的PRINT_TUPLE::print函数(空的)完成打印。
tuple补充

上图之前讲过了,这里有一句话很有意思,递归调用处理的是参数,使用function template,递归继承处理的是类型,使用的是class template。

不过上述的代码编译时不通过的,因为HEAD::type这个原因(比如int::type是没有的)。

然后修改成这样,使用decltype进行类型推导,得到返回类型。不过需要把数据移到上面取,太离谱了。

最终发现直接返回Head就可以了,侯捷老师考虑太复杂了哈哈哈。

之前的tuple是通过递归继承来实现的,上图展示了如何通过递归复合来实现tuple,原理与之前的类似,数据多了Composited类型的m_tail, 依次不断递归,直到最后复合到空的tuple。
variadic template到此结束,真的很强大!
标准库层面
右值引用

右值引用是为了解决不必要的拷贝以及使能完美转发而引入的新的引用类型。当右边的赋值类型是一个右值,左边的对象可以从右边的对象中偷取资源而不是重新分配拷贝,这个偷取的过程叫做移动语义。上述给出了事例,a+b和临时对象就是右值,右值只能出现在右边,左边则可以都出现,这里的complex类和string类是由C++作者写的,引入了不同的修改和赋值,没有遵守右值的定义,所以它们的事例没有报错。方便记忆,可以这里理解右值和左值,可以取地址,有名字的是左值,而不能取地址,没有名字的是右值。还有一种解释,右值由将亡值和纯右值组成,将亡值如a+b赋给a后就死掉,临时对象也是一样,纯右值指的是2,'a',true等等。

右值出现,对其进行资源的搬移是合理的,所以引出了两点,第一点是要有语法告诉编译器这是右值,第二点是被调用段需要写出一个专门处理右值的搬移赋值(move assignment)函数。

上述的是测试程序,在vector尾端插入Mystring的临时对象,调用的vector需要实现带有右值插入的版本,也就是箭头指向的版本——insert(..., &&x),insert函数则会调用MyString的拷贝构造函数,为了不进行拷贝,也需要写出一个右值引用类型的拷贝构造。noexcept是为了让编译器知道构造和析构不会抛出异常,当vector增长的时候,move构造函数才会调用起来。上图中还显示了关于copy和move的区别,可以看到copy中的数据是有两份的,其中一份是拷贝过来的,而move操作的数据是只有一份的,原来可能指向临时对象,现在指向搬移后的对象,原来的对象会设置为空指针。上图中有一个std:move函数很有帮助,它会将左值对象转成右值对象,代码中可以经常用到。
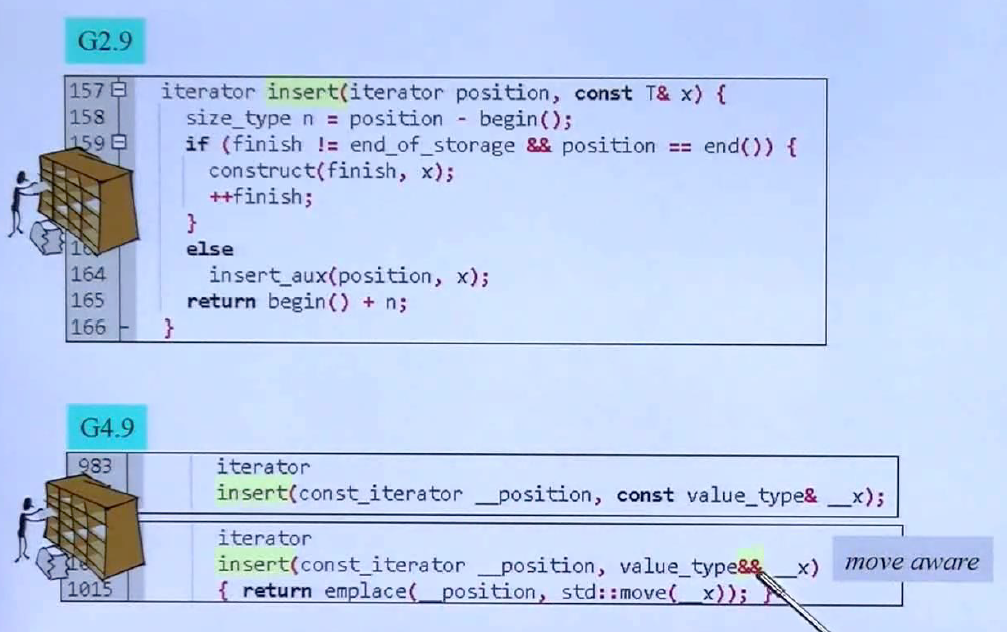
上面的GCC2.9和GCC4.9版的insert函数,可以看到GCC4.9版引入move aware的insert函数。

除了拷贝构造以外,还有拷贝赋值也需要写一个move版本的。
perfect forwarding
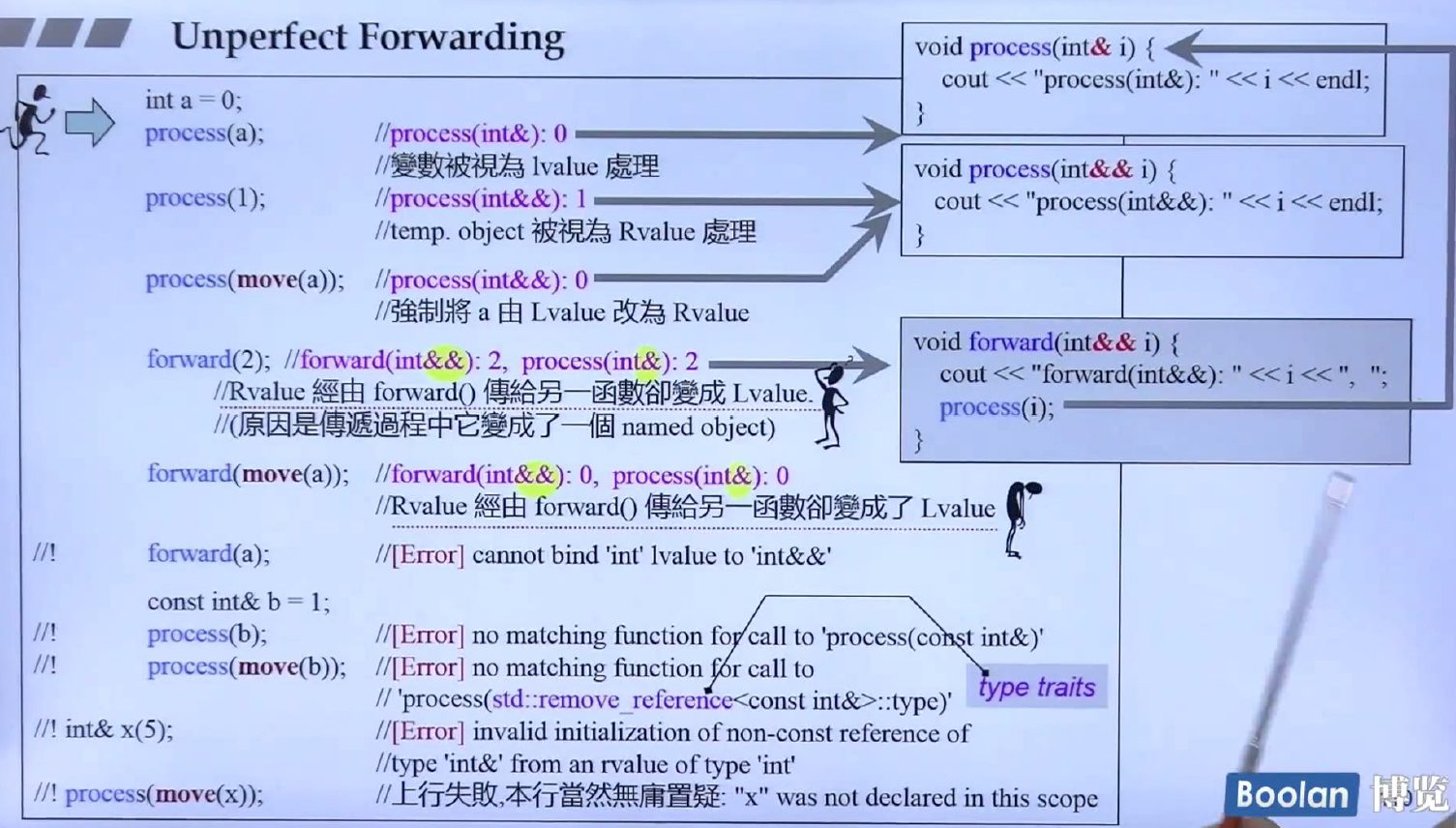
在看perfect forwarding之前,先看看unperfect forwarding,关注一下forward(2)的调用,2是纯右值,调用的是forward(int&& i)函数,但在forward(int&& i)函数里面使用i,i就会变为左值,这是我们不想看到的,左值意味着可能会有不必要的拷贝,所以有perfect forwarding.

perfect forwarding可以允许你写一个函数模板,有任意个参数,透明地转发给另一个函数,其中参数的本质(可修改性,const,左值,右值)都会在转发过程中保留下来,使用的是std::forward模板函数。
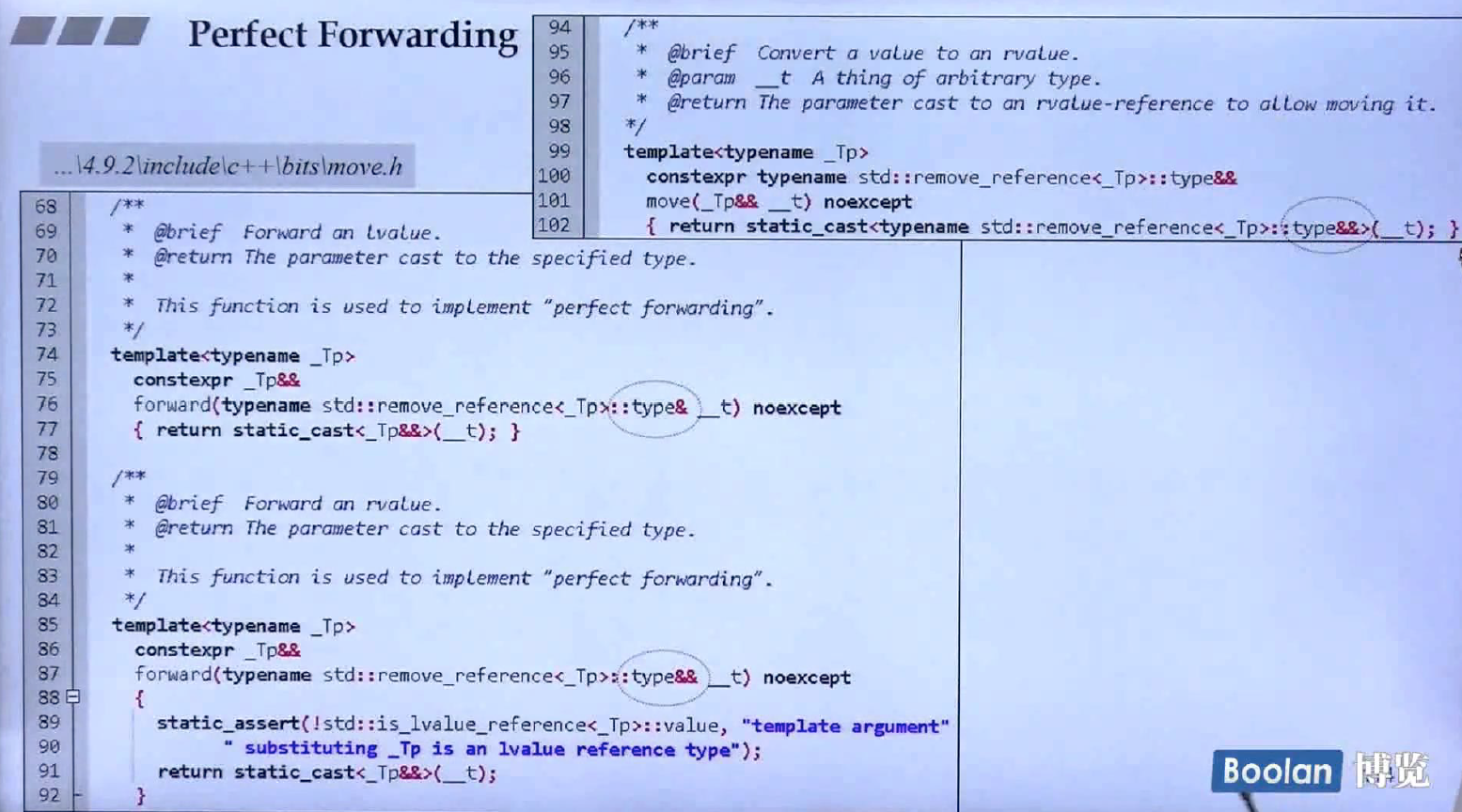
可以看到forward内部使用了static_cast对传入的对象进行转型。move函数也一样。
move aware class

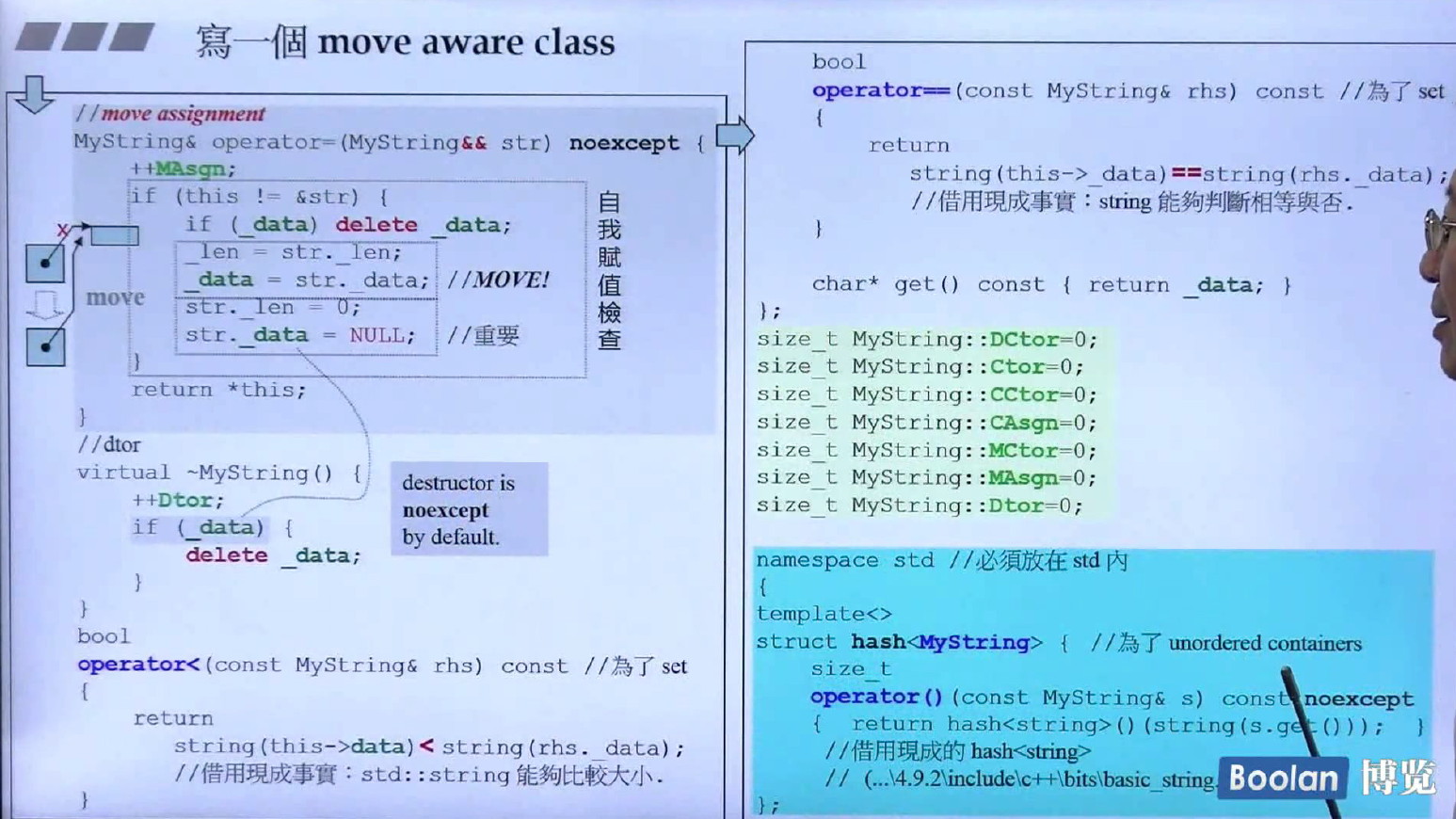
上面两页是带有move aware的Mystring实现,灰色部分就是move版本的拷贝构造与拷贝赋值。可以看到直接就是浅拷贝,对指针和长度直接赋值,然后将原来对象的内部指针设置为空指针,内部长度为0。而不带有move的拷贝构造和拷贝赋值都调用了_init_data函数,内部调用的是memcpy函数进行拷贝。还有一点需要注意,由于有了move版本,析构函数需要进行少量修改,当指针为空时,不进行delete操作,此时没有指向对象了。
move aware测试

与之前的幻灯片相比,多了一个NoMove的参数,这是为了比较copy和move的性能差异。
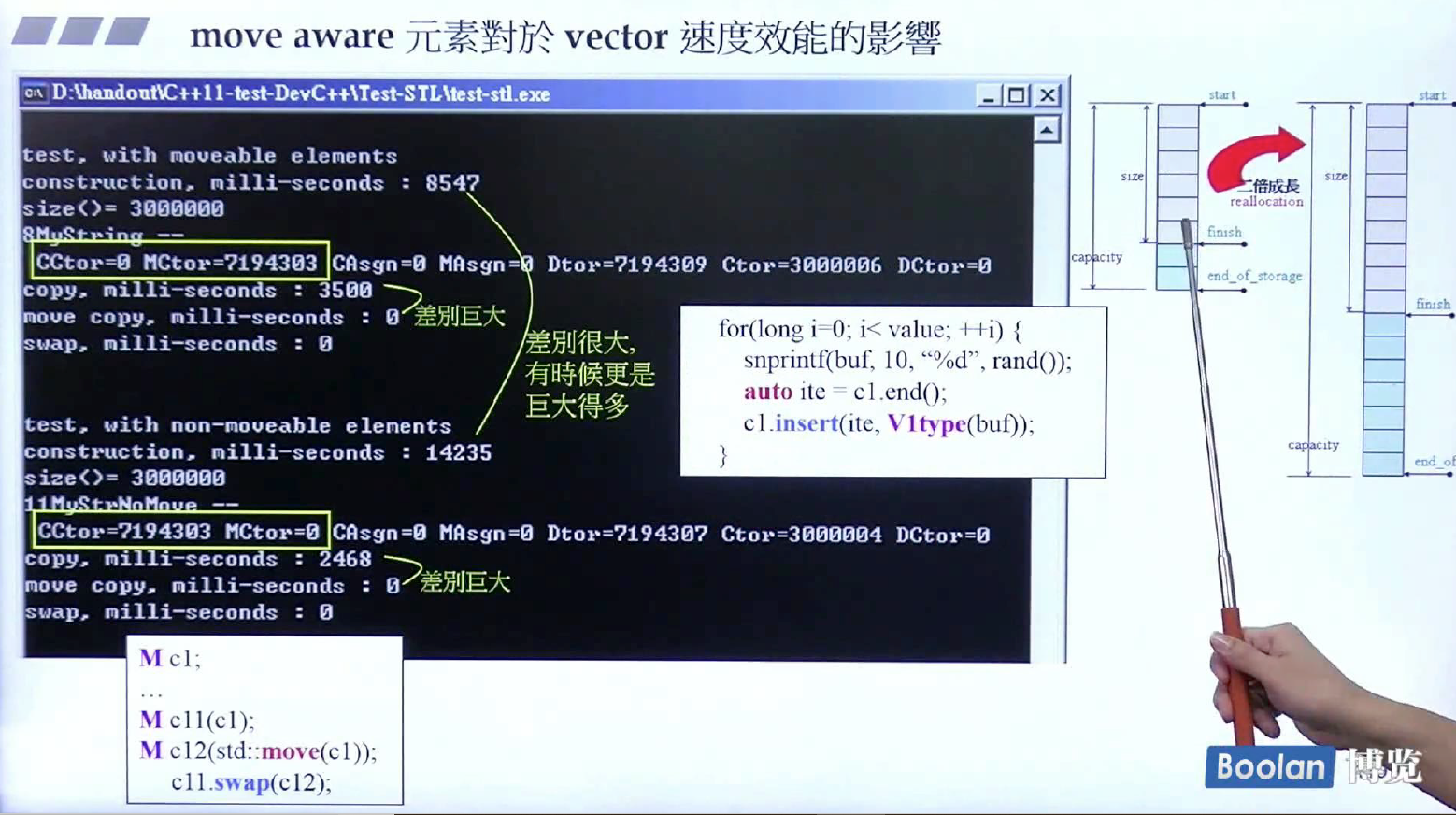
可以看到在vector容器中,使用copy和move版本的insert函数,差异很大,copy操作花费了更多的时间。而对于直接std::move和传统的拷贝构造,更是差异巨大。这里虽说只有三百万个元素,但由于vector有动态增长,所以构造函数调用次数会多于三百万次。
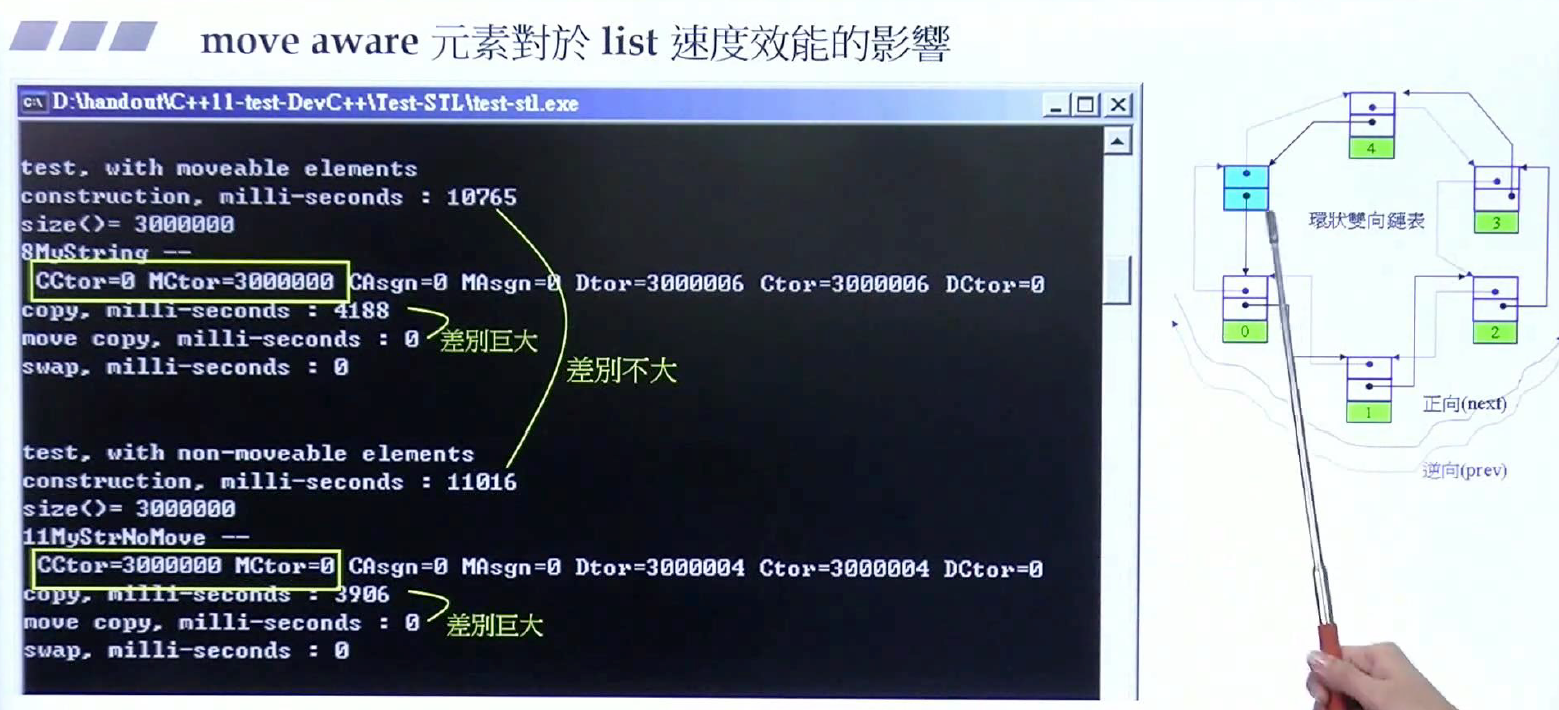

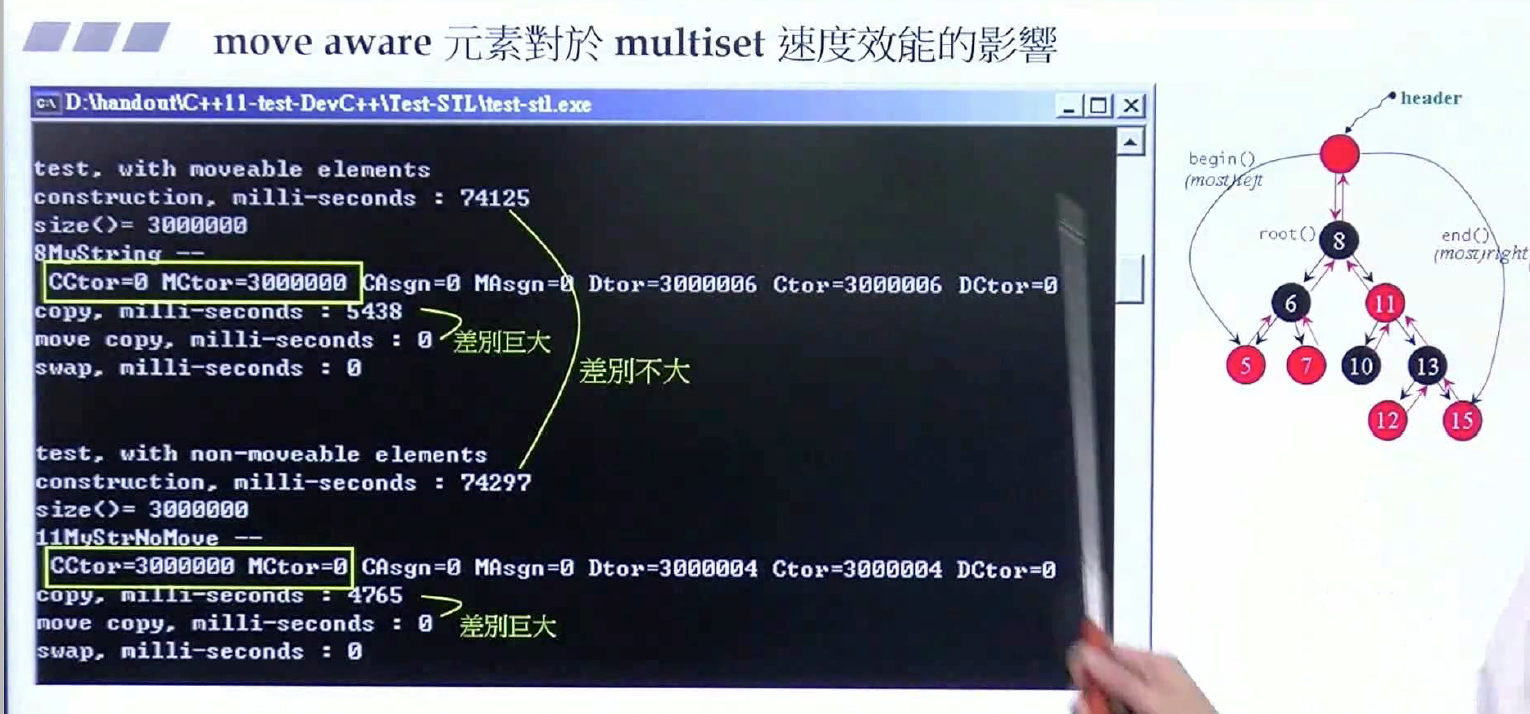

而对于其他容器而言,构造函数阶段差别不大,但move版本还是快一些,当然,std::move与传统的拷贝赋值还是差异巨大,毕竟一个是拷贝所有的值,一个只是拷贝指针。
vector的拷贝构造与移动构造

可以看到拷贝构造实际上是先分配要拷贝的对象的长度的内存,然后调用copy ctors一一复制.(注意看参数的箭头)
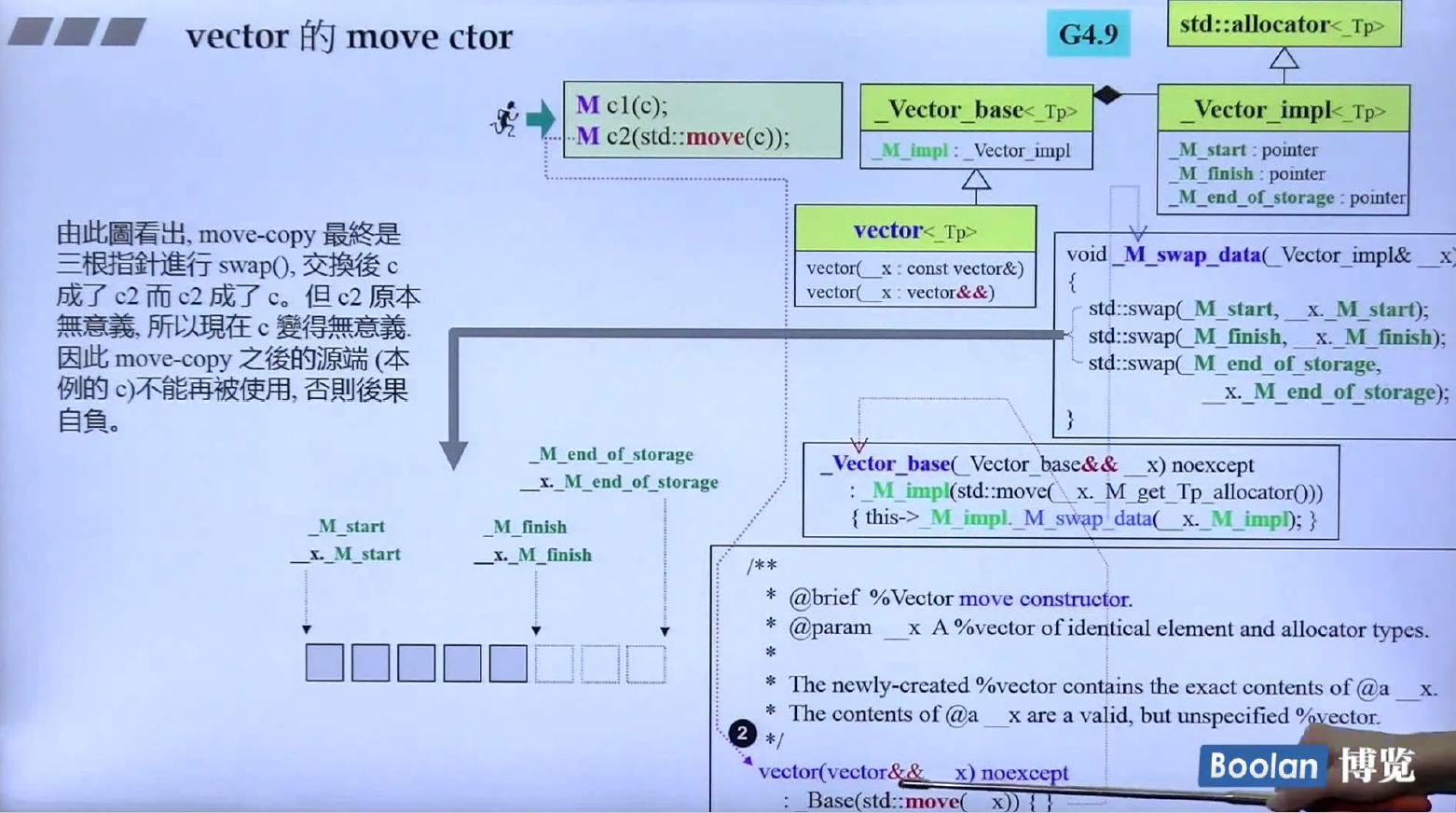
而移动构造调用的是_M_swap_data函数,内部是指针的交换,c2现在成了c,c没有意义了,不能再使用。
array

TR1版本的array,内部是一个数组,封装了一些接口,可以适配算法库。

GCC4.9版本的array,接口一样,用到了面向对象的东西,代码更复杂。
Unordered容器
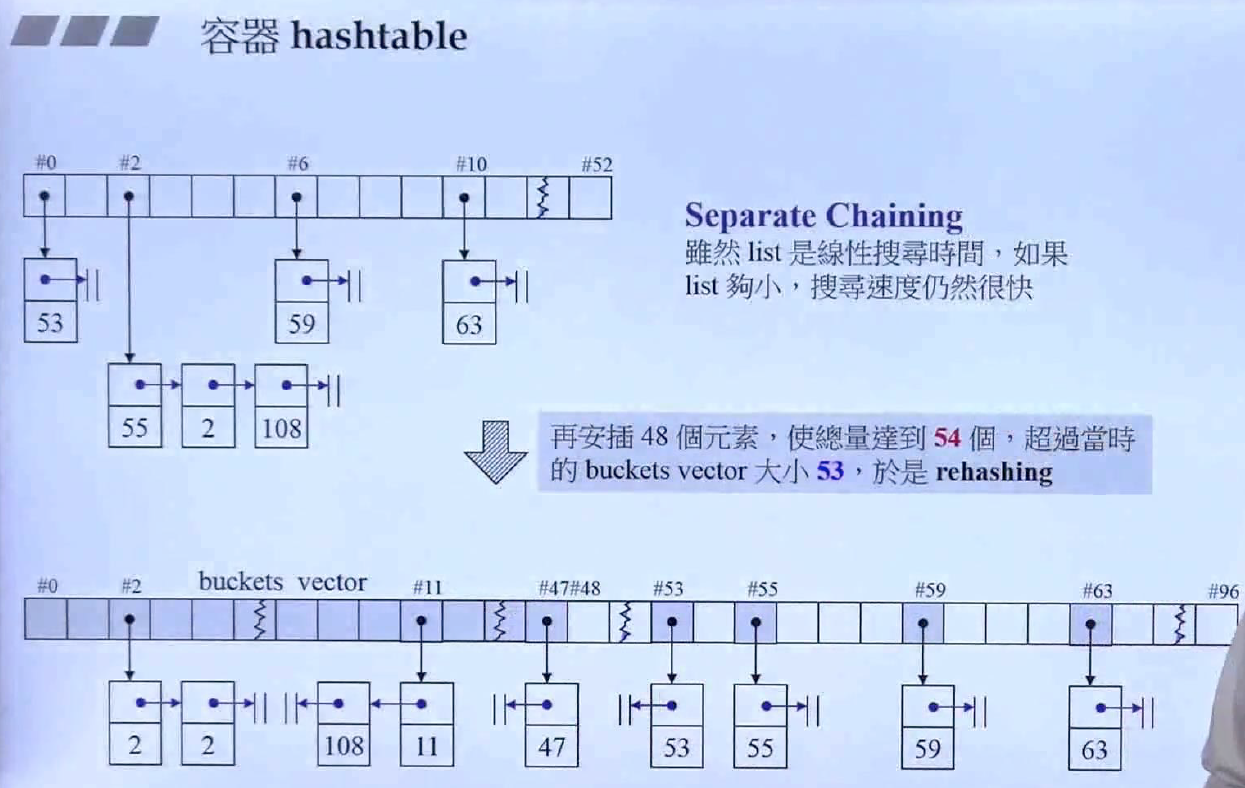
无序容器内部是通过哈希表实现的,哈希表的结构如上所示,key实际上是一个指针vector,vector的长度叫做buckets(分箱), 每个vector中的指针指向一个链表,不同环境的哈希表实现方式不一样,有的是双向链表,有的是单项链表。哈希表是利用键值进行取值,比如键值为6,则访问vector第7个指针所指向的链表,如果链表有多个元素,则按序查找。哈希表都有一个特性,当元素的个数大于buckets时,需要rehashing,将hash表的buckets进行增大,一般是两倍大左右的质数,然后重新分配。

C++11引入了4种无序容器,分别是unordered_set, unordered_multiset, unordered_map以及unordered_multimap。具体使用将在体系结构那一个大课上写。
哈希函数

上面没说如何根据数据得到键值,这就要用到哈希函数了,以上GCC4.9版本计算每一个类型的哈希值事例,其中hash
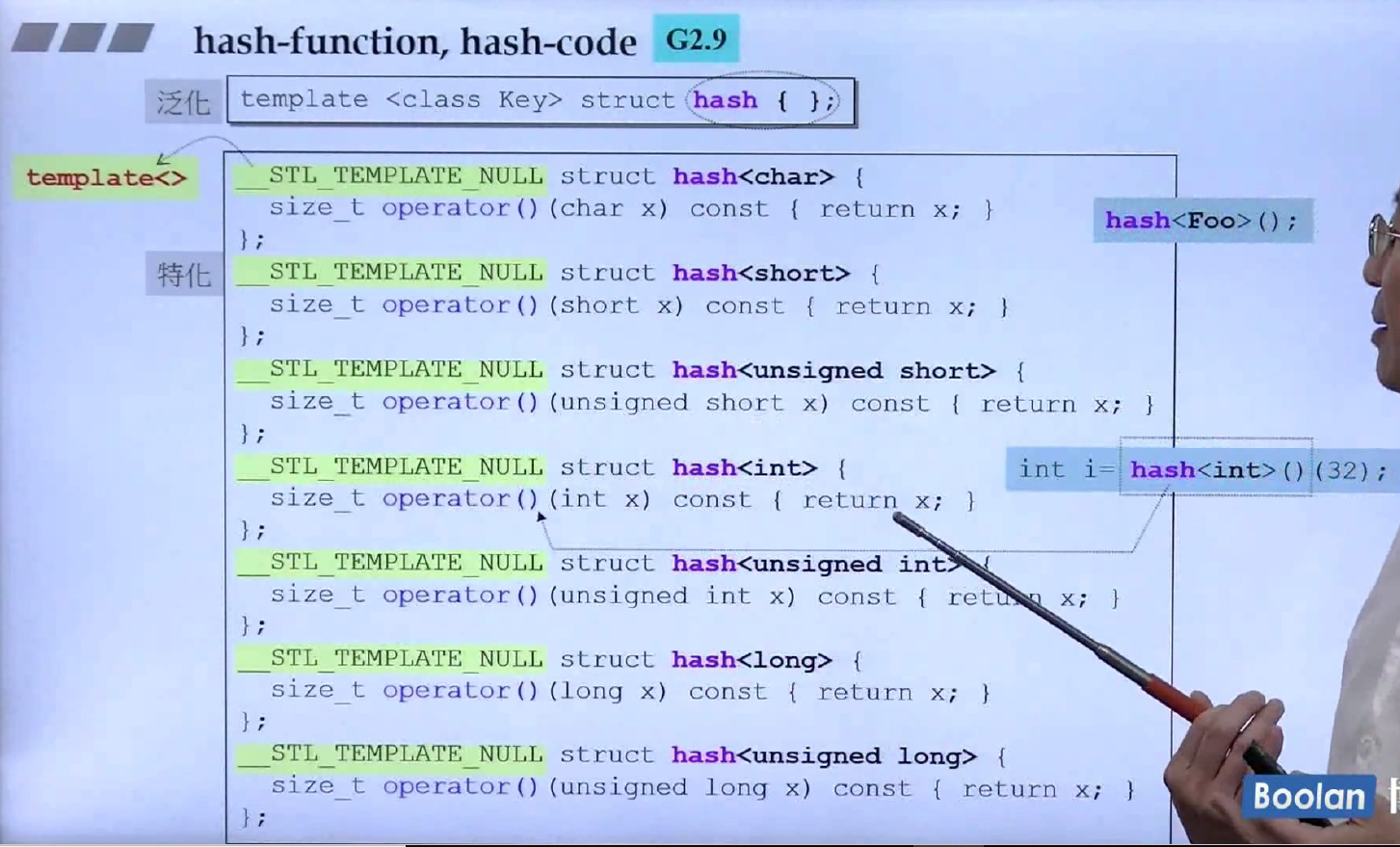
GCC2.9要清楚许多,代码将每一个类型进行了特化,形成对应了哈希函数,上面的都是整型的。

上面的是关于字符数组的哈希函数,再GCC2.9版本中,没有提供string的哈希函数,只有字符数组的。

上面的是字符数组的使用事例,结合之前提到的哈希表的结构,可以很清楚的知道具体流程。

GCC2.9许多类型没有支持,GCC4.9则基本都支持了,思想还是对每种类型进行特化,上面的就是GCC4.9版本的哈希函数,后面几页都是接着这一页的。类__hash_base定义了两种类型,一种是返回结果(哈希函数的返回结果都是size_t), 另 一种是参数类型,用以给哈希函数进行继承。上图左边给出了指针的特化版本,实现是通过reinterpret_cast对指针进行了转型,这种转型的运行期定义的,C++还有另外三种转型——static_cast, dynamic_cast以及const_cast,一般转型使用的是static_cast, dynamic_cast用于继承转型,const_cast用于去除对象的只读性,更多细节请查看《more effective C++》的条目二。
对于整型,使用了宏定义简化相同代码,因为整型都一样,直接返回即可。
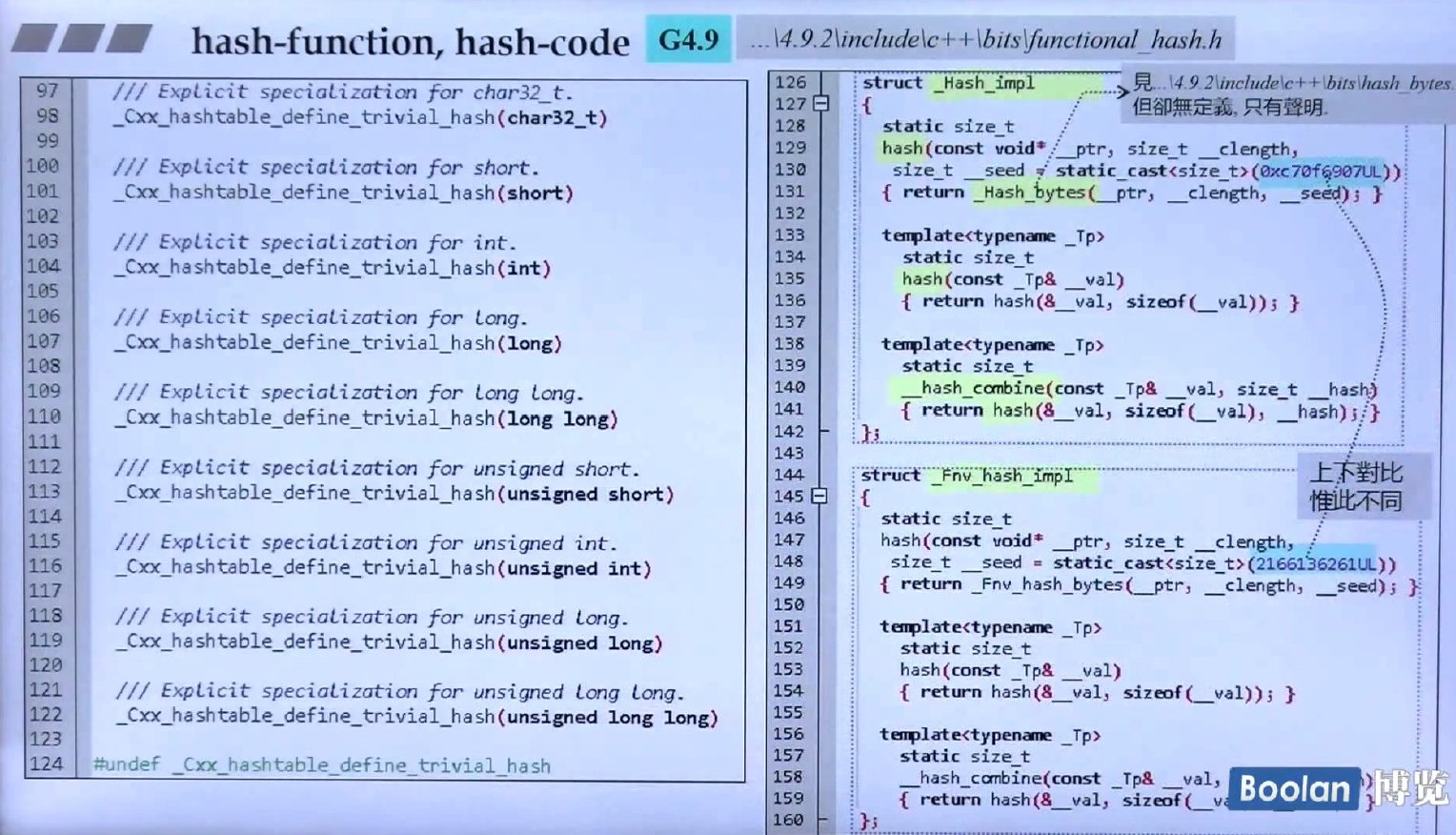
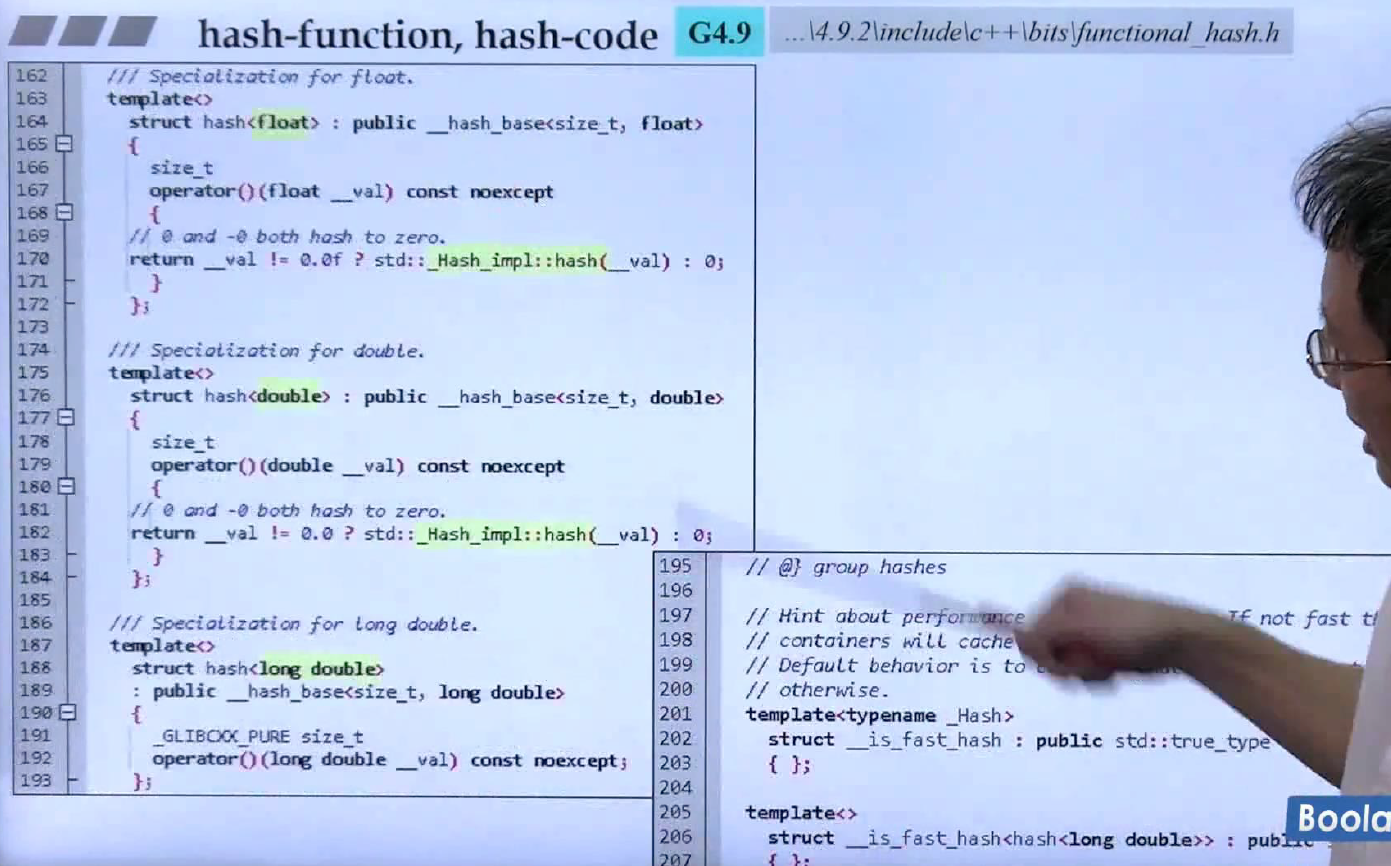

对于上面的浮点数以及字符串来说,调用的是Hash_impl类的hash函数,该函数调用的是_Hash_bytes函数,然后_Hash_bytes函数只有声明,没有定义,侯捷老师认为是该函数是二进制码函数(编译好的二进制),所以无法在源代码中找到。
再探万用的hash函数
对于数据而言,最小组成单元无非都是整形,浮点型以及字符串,所以对于任意对象,是可以进行hash的,这一节就是要设计万用的hash函数。

对于某一个类的哈希函数,可以有以上三种写法,第一种是自定义类,该类是重载()的仿函数,第二种是写成正儿八经的函数,不过在定义容器时,写的类型较复杂。第三种使用namespace,将类包在std中,相当于特化此类,这样定义的时候无需写哈希函数类型。

为了支持不同个数的变量,使用了之前章节的variadic template,可以传入任意个数的参数的hash_val函数,具体流程已在variadic template一节讲述,可以往回看。

上页幻灯片中计算seed表达式中的0x9e3779b9是一个特殊的值,黄金比例,为了让哈希函数生成的键足够乱而引入的。
tuple实例

这里主要示范了一下tuple的一些用法,不细说,看代码就能看懂,对于代码中为什么内存大小不是28的问题,侯捷老师不知道,我也没有查到,在window10-64位电脑的mingw64测试,结果是56,两倍,在vc2017中测试是64。不同编译器有区别,具体原因不太清楚。
右下角的是元编程的范例程序,通常编程是操作变量,元编程是操作类型。
旧版tuple

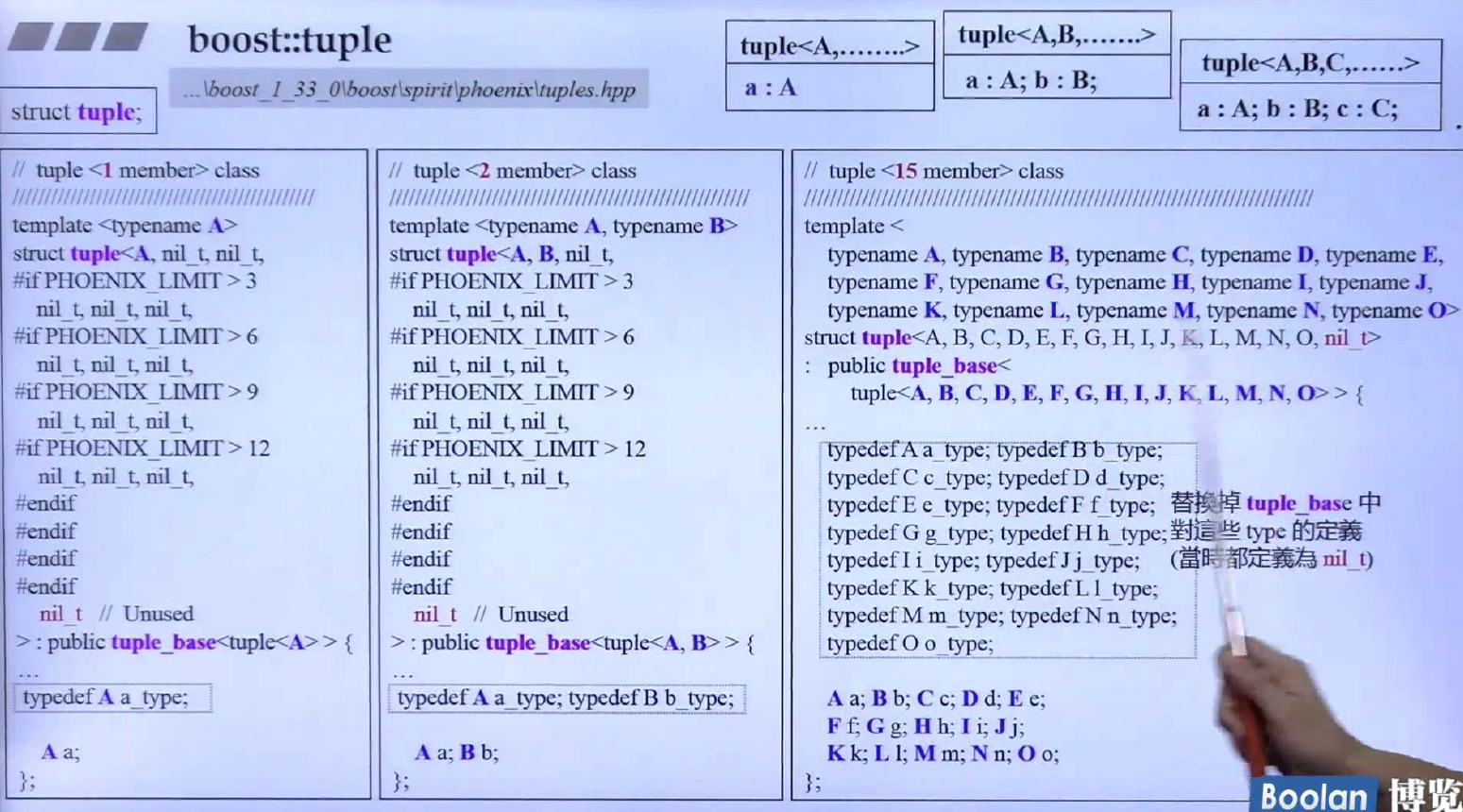
上面两张幻灯片是最早tuple的实现方式,由于没有variadic template,所以boost实现tuple使用多个类,最多可以容纳15个参数,最早的思想是来自与modern C++ design那本书,作者使用宏定义构建了类似variadic template的方式。
好了,关于侯捷老师的C++11/14课程的笔记到这里就结束了,后面会补充一些C++11其他的内容,这些内容是侯捷老师没有提到的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号