kafka消费者详解
一、消费者组
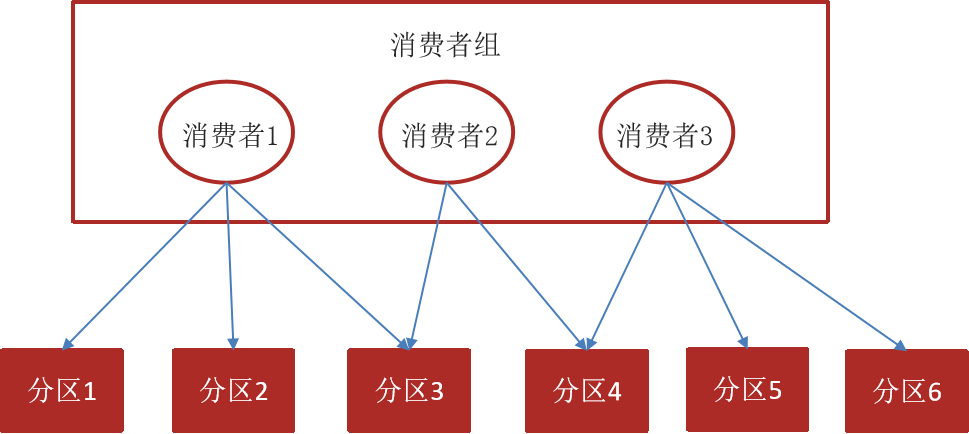
消费者组(Consumer Group) :指的就是由一个或多个消费者组成的群体
一个发布在Topic上消息被分发给此消费者组中的一个消费者
所有的消费者都在一个组中,那么这就变成了queue模型【消息队列,只有一个用户能接收到消息】
所有的消费者都在不同的组中,那么就完全变成了发布-订阅模型【所有用户都能接收到消息】
二、消息有序性
应用场景:
即时消息中的单对单聊天和群聊,保证发送方消息发送顺序与接收方的顺序一致
充值转账两个渠道在同一个时间进行余额变更,短信通知必须要有顺序
……
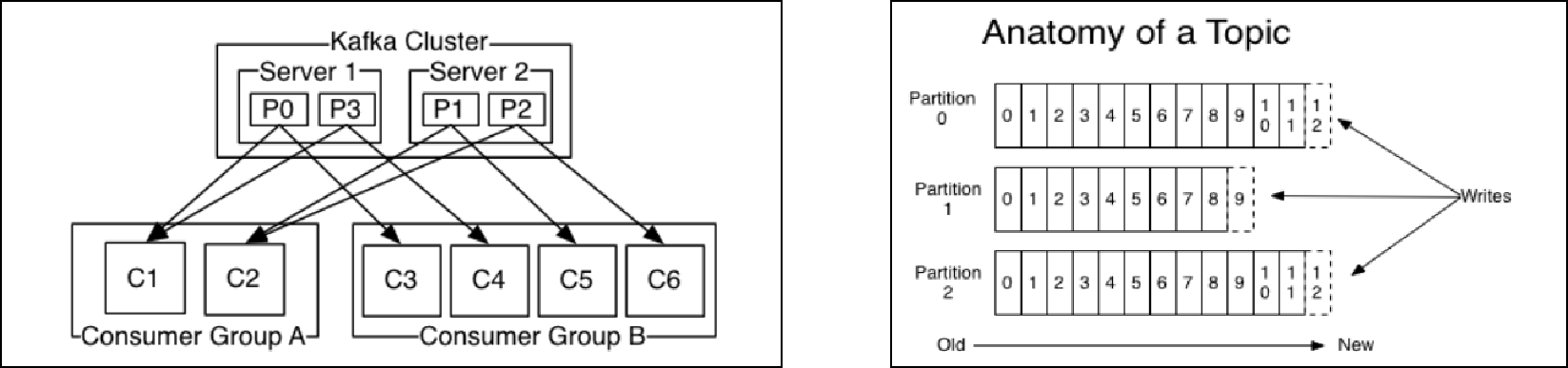
kafka集群托管4个分区(P0-P3),2个消费者组,消费组A有2个消费者,消费组B有4个
topic分区中消息只能由消费者组中的唯一一个消费者处理,所以消息肯定是按照先后顺序进行处理的。但是它也仅仅是保证Topic的一个分区顺序处理,不能保证跨分区的消息先后处理顺序。 所以,如果你想要顺序的处理Topic的所有消息,那就只提供一个分区。
三、提交和偏移量
kafka不会像其他JMS队列那样需要得到消费者的确认,消费者可以使用kafka来追踪消息在分区的位置(偏移量)
消费者会往一个叫做_consumer_offset的特殊主题发送消息,消息里包含了每个分区的偏移量。如果消费者发生崩溃或有新的消费者加入群组,就会触发再均衡【假如消费者2负责的是分区3、4。当消费者2崩溃后, 分区3、4会让消费者1和消费者3消费】
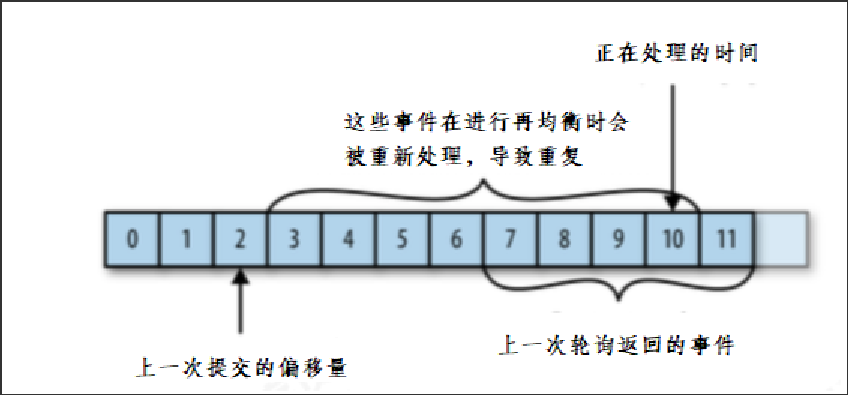
如果提交偏移量小于客户端处理的最后一个消息的偏移量,那么处于两个偏移量之间的消息就会被重复处理。
比如消费者提交的偏移量是2,消费到了10,加入消费者2挂了,事件再均衡后下一个消费这块分区的会从2开始,重复处理。
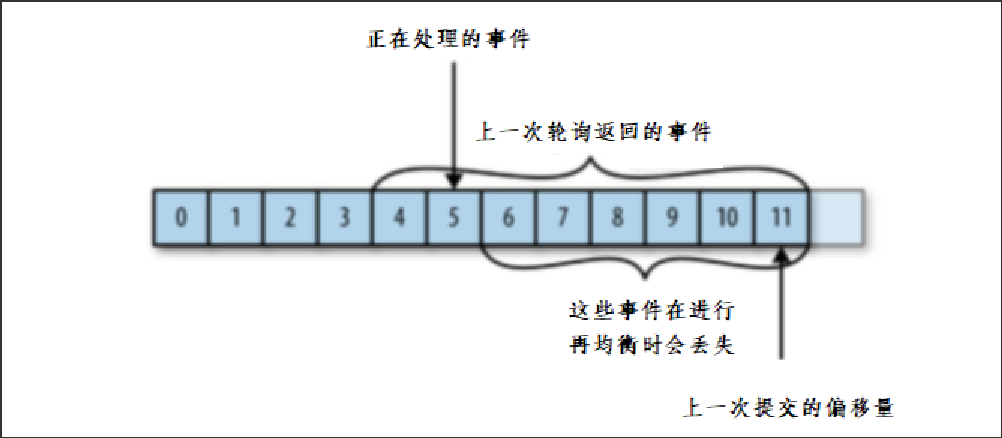
如果提交的偏移量大于客户端的最后一个消息的偏移量,那么处于两个偏移量之间的消息将会丢失。
比如消费者挂掉之前提交的偏移量是11,但其实只处理到了5,那5到10的进行再均衡时会丢失。
四、偏移量提交方式
提交偏移量的方式有两种:分别是自动提交偏移量和手动提交
自动提交偏移量:当enable.auto.commit被设置为true,提交方式就是让消费者自动提交偏移量,每隔5秒消费者会自动把从poll()方法接收的最大偏移量提交上去
手动提交偏移量:当enable.auto.commit被设置为false可以有以下三种提交方式:
1、提交当前偏移量(同步提交):会阻塞,失败会重试
//同步提交偏移量 try { consumer.commitSync(); }catch (CommitFailedException e){ System.out.println("记录提交失败的异常" + e); }
2、异步提交:如果服务器返回失败,不会重试,如果重试可能会导致位移的覆盖
//异步的方式提交偏移量 consumer.commitAsync(new OffsetCommitCallback() { @Override public void onComplete(Map<TopicPartition, OffsetAndMetadata> map, Exception e) { if(e != null){ System.out.println("记录提交错误的偏移量:" + map + ",异常信息为" + e); } } });
3、同步和异步组合提交:异步提交失败后记录日志,然后进行同步提交
//同步提交和异步提交偏移量 try{ while (true) { ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofMillis(1000)); for (ConsumerRecord<String, String> consumerRecord : consumerRecords) { System.out.println(consumerRecord.key()); System.out.println(consumerRecord.value()); //分区,在此只有一个分区0 System.out.println(consumerRecord.partition()); //偏移量,记录消费到什么位置了 System.out.println(consumerRecord.offset()); } //异步提交偏移量 consumer.commitAsync(); } }catch (Exception e){ e.printStackTrace(); System.out.println("记录错误的信息:" + e); }finally { //同步提交 consumer.commitSync(); }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号