kafka分区机制
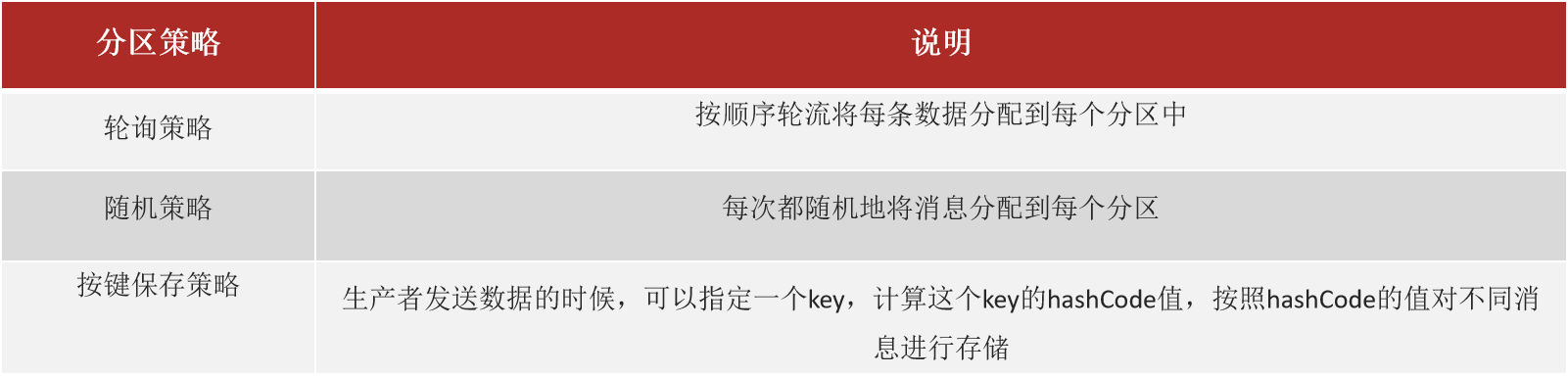
Kafka 中的分区机制指的是将每个主题划分成多个分区(Partition)
可以处理更多的消息,不受单台服务器的限制,可以不受限的处理更多的数据
每一个分区都是一个顺序的、不可变的消息队列, 并且可以持续的添加。分区中的消息都被分了一个序列号,称之为偏移量(offset),在每个分区中此偏移量都是唯一的
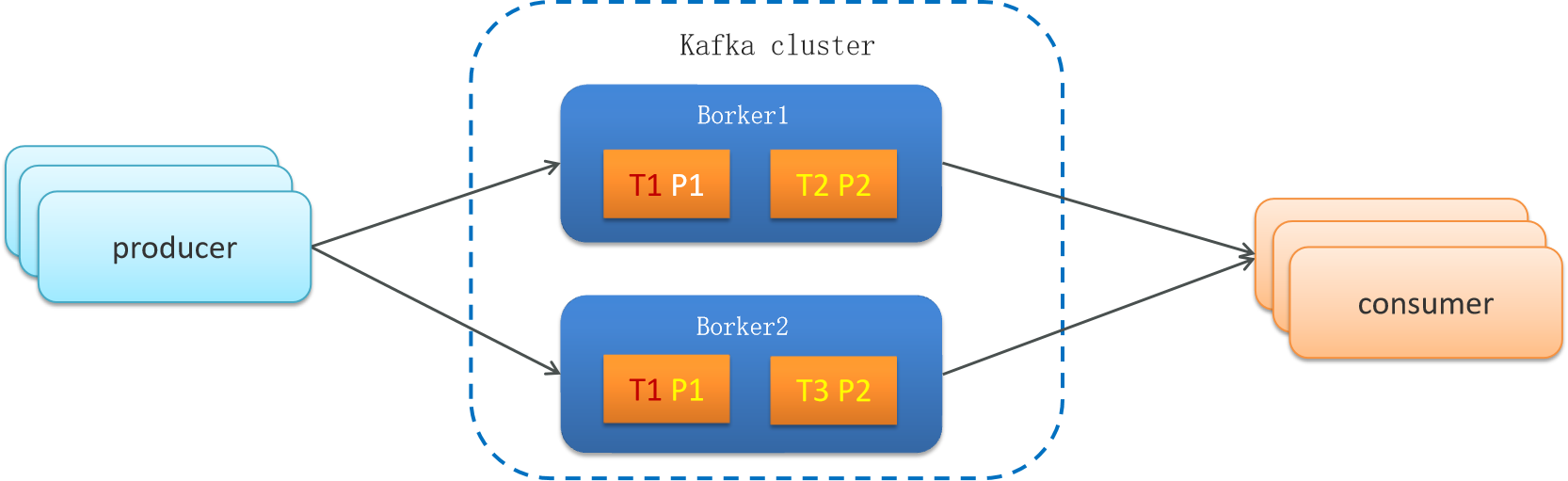
在 Kafka 集群中,一个主题(Topic)被划分为多个分区(Partition)。每个分区都有一个主副本(Leader Replica)和零个或多个副本(Follower Replica)。这些副本都存在于同一个 Kafka 集群的不同服务器上。
具体来说,一个 Kafka 集群由多个服务器(或者称为 Broker)组成。每个服务器可以承载多个分区的副本。当创建一个新的分区时,Kafka 集群会自动将该分区的主副本和副本分配到不同的服务器上,以分散负载和提供数据冗余。
每个分区都有一个主副本,它负责处理读写请求,并保持与其他副本之间的同步。其他副本则用于故障转移和数据冗余。当主副本故障时,Kafka 集群会自动从副本中选举一个新的领导者(主副本)来接管分区。
因此,一个主题的不同分区会分布在同一个 Kafka 集群的不同服务器上,并且每个服务器上会有分区的副本。这种设计允许 Kafka 实现数据的冗余备份、故障转移和高可用性,从而确保数据的可靠性和可扩展性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号