全面认识Web标准和浏览器内核引擎
Web、网页、浏览器
Web
Web(World Wide Web)即全球广域网,也称为万维网。
我们常说的Web端就是网页端。
网页
网页是构成网站的基本元素。网页主要由文字、图像和超链接等元素构成。当然,除了这些元素,网页中还可以包含音频、视频以及Flash等。
我们在浏览器上输入网址后,打开的任何一个页面,都是属于网页。
浏览器
浏览器是网页运行的平台,常见的浏览器有谷歌(Chrome)、Safari、火狐(Firefox)、IE、Edge、Opera等。
Web标准
W3C组织
W3C:万维网联盟组织,用来制定web标准的机构(组织)。
W3C 万维网联盟是国际最著名的标准化组织。1994年成立后,至今已发布近百项相关万维网的标准,对万维网发展做出了杰出的贡献。
W3C 组织就类似于现实世界中的联合国。
为什么要遵循WEB标准呢?因为很多浏览器的浏览器内核不同,导致页面解析出来的效果可能会有差异,给开发者增加无谓的工作量。因此需要指定统一的标准。
Web 标准
Web标准:制作网页要遵循的规范。
Web标准不是某一个标准,而是由W3C组织和其他标准化组织制定的一系列标准的集合。
1、Web标准包括三个方面:
-
结构标准(HTML):用于对网页元素进行整理和分类。
-
表现标准(CSS):用于设置网页元素的版式、颜色、大小等外观样式。
-
行为标准(JS):用于定义网页的交互和行为。
根据上面的Web标准,可以将 Web前端分为三层,如下。
2、Web前端分三层:
- HTML(HyperText Markup Language):超文本标记语言。从语义的角度描述页面的结构。相当于人的身体组织结构。
- CSS(Cascading Style Sheets):层叠样式表。从审美的角度美化页面的样式。相当于人的衣服和打扮。
- JS:JavaScript。从交互的角度描述页面的行为。相当于人的动作,让人有生命力。
3、打个比方:
HTML 相当于人的身体组织结构:
CSS 相当于人的衣服和打扮:
JS 相当于人的行为:
浏览器
常见的浏览器
浏览器是网页运行的平台,常见的浏览器有谷歌(Chrome)、Safari、火狐(Firefox)、IE、Edge、Opera等。我们重点需要学习的是 Chrome 浏览器。
浏览器的组成
浏览器分成两部分:
-
1、渲染引擎(即:浏览器内核)
-
2、JS 引擎
1、渲染引擎(浏览器内核)
浏览器所采用的「渲染引擎」也称之为「浏览器内核」,用来解析 HTML与CSS。渲染引擎决定了浏览器如何显示网页的内容以及页面的格式信息。
渲染引擎是浏览器兼容性问题出现的根本原因。
渲染引擎的英文叫做 Rendering Engine。通俗来说,它的作用就是:读取网页内容,计算网页的显示方式并显示在页面上。
常见浏览器的内核如下:
| 浏览器 | 内核 |
|---|---|
| chrome | Blink |
| 欧鹏 | Blink |
| 360安全浏览器 | Blink |
| 360极速浏览器 | Blink |
| Safari | Webkit |
| Firefox 火狐 | Gecko |
| IE | Trident |
备注:360的浏览器,以前使用的IE浏览器的Trident内核,但是现在已经改为使用 chrome 浏览器的 Blink内核。
四种内核的简介:
1、Trident:微软开发的引擎,其产品IE产品都是它驱动,也有很多其他浏览器也用它做内核。
2、Gecko:开源的渲染引擎,有C++编写,功能强大,功能强大、丰富,可以支持很多复杂网页效果和浏览器扩展接口,FireFox就是代表,对w3c标准支持很好,开发和调试都很强大,就是启动速度不太给力;
3、WebKit:苹果公司基于KHTML开发的,对网页的解析比较快,仅此于Presto,但是容错比较差,不标准的网页无法正常显示。用它做核心开发的浏览器代表是Safari,Chrome;
4、Presto:Opera Software公司开始的,是被大家公认为最快的渲染引擎。处理JS脚本等脚本语言时,会比其他的内核快3倍左右,但是快也存在一些问题,就是丢掉了一些网页兼容性;
2、JS 引擎
也称为 JS 解释器。 用来解析网页中的JavaScript代码,对其处理后再运行。
浏览器本身并不会执行JS代码,而是通过内置 JavaScript 引擎(解释器) 来执行 JS 代码 。JS 引擎执行代码时会逐行解释每一句源码(转换为机器语言),然后由计算机去执行。所以 JavaScript 语言归为脚本语言,会逐行解释执行。
常见浏览器的 JS 引擎如下:
| 浏览器 | JS 引擎 |
|---|---|
| chrome / 欧鹏 | V8 |
| Safari | Nitro |
| Firefox 火狐 | SpiderMonkey(1.0-3.0)/ TraceMonkey(3.5-3.6)/ JaegerMonkey(4.0-) |
| Opera | Linear A(4.0-6.1)/ Linear B(7.0-9.2)/ Futhark(9.5-10.2)/ Carakan(10.5-) |
| IE | Trident |
浏览器工作原理
1、地址栏输入URL
浏览器根据输入的URL查找域名的IP地址,DNS查找过程如下:
1、浏览器缓存:浏览器会缓存DNS记录一段时间,不同浏览器默认缓存时间不一样,IE默认为30分钟,Firefox默认是1分钟。
2、系统缓存:如果在浏览器缓存里没有找到需要的缓存记录,浏览器会到系统缓存中查找。
3、路由器缓存:如果系统缓存中也没有,就会将请求发给路由器并在其DNS缓存中查找。
4、ISP缓存:如果路由器缓存中没有,就会将请求发给ISP的DNS缓存服务器并在其记录中查找。
5、访问根域名服务器:如果ISP缓存中没有,就会由ISP向根域名服务器进行递归搜索,查找到对应记录并返回。
浏览器与对应Web服务器建立TCP连接,并发送HTTP请求,Web服务器接收到请求后进行一系列分析处理(关于HTTP请求响应的详细过程以后再进行剖析)并返回HTML文件。
2、浏览器解析HTML
浏览器接收到服务器返回的HTML文件,解析标签:
1、关于页面的一些配置标签,例如、、等,以后再进行剖析,这些会对页面属性进行设置。<br/>
2、碰到内联CSS和JS会立即解析执行。<br/>
3、碰到外部CSS和JS会并发请求相关资源,然后解析执行。不同浏览器针对同一域的同一时间默认并发连接数会有不同,一般在10个以内。<br/>
4、接着,浏览器开始解析里的内容:
碰到需要获取其他地址内容的标签,例如、
当HTML解析器遇到
3、浏览器渲染原理
渲染引擎简介
浏览器——Firefox、Chrome和Safari是基于两种渲染引擎构建的,Firefox使用Geoko——Mozilla自主研发的渲染引擎,Safari和Chrome都使用webkit。
渲染主流程
渲染引擎首先通过网络获得所请求文档的内容,通常以8K分块的方式完成。下面是渲染引擎在取得内容之后的基本流程:
解析html以构建dom树 -> 构建render树 -> 布局render树 -> 绘制render树

这里先解释一下几个概念,方便大家理解:
DOM Tree:浏览器将HTML解析成树形的数据结构。
CSS Rule Tree:浏览器将CSS解析成树形的数据结构。
Render Tree: DOM和CSSOM合并后生成Render Tree。
layout: 有了Render Tree,浏览器已经能知道网页中有哪些节点、各个节点的CSS定义以及他们的从属关系,从而去计算出每个节点在屏幕中的位置。
painting: 按照算出来的规则,通过显卡,把内容画到屏幕上。
reflow(回流):当浏览器发现某个部分发生了点变化影响了布局,需要倒回去重新渲染,内行称这个回退的过程叫 reflow。reflow 会从 <html> 这个 root frame 开始递归往下,依次计算所有的结点几何尺寸和位置。reflow几乎是无法避免的。现在界面上流行的一些效果,比如树状目录的折叠、展开(实质上是元素的显 示与隐藏)等,都将引起浏览器的 reflow。鼠标滑过、点击……只要这些行为引起了页面上某些元素的占位面积、定位方式、边距等属性的变化,都会引起它内部、周围甚至整个页面的重新渲 染。通常我们都无法预估浏览器到底会 reflow 哪一部分的代码,它们都彼此相互影响着。
repaint(重绘):改变某个元素的背景色、文字颜色、边框颜色等等不影响它周围或内部布局的属性时,屏幕的一部分要重画,但是元素的几何尺寸没有变。
注意:
(1)display:none 的节点不会被加入Render Tree,而visibility: hidden 则会,所以,如果某个节点最开始是不显示的,设为display:none是更优的。
(2)display:none 会触发 reflow,而 visibility:hidden 只会触发 repaint,因为没有发现位置变化。
(3)有些情况下,比如修改了元素的样式,浏览器并不会立刻reflow 或 repaint 一次,而是会把这样的操作积攒一批,然后做一次 reflow,这又叫异步 reflow 或增量异步 reflow。但是在有些情况下,比如resize 窗口,改变了页面默认的字体等。对于这些操作,浏览器会马上进行 reflow。
来看看webkit的主要流程:

再来看看Geoko的主要流程:

Gecko 里把格式化好的可视元素称做“帧树”(Frame tree)。每个元素就是一个帧(frame)。 webkit 则使用”渲染树”这个术语,渲染树由”渲染对象”组成。webkit 里使用”layout”表示元素的布局,Gecko则称为”reflow”。Webkit使用”Attachment”来连接DOM节点与可视化信息以构建渲染树。一个非语义上的小差别是Gecko在HTML与DOM树之间有一个附加的层 ,称作”content sink”,是创建DOM对象的工厂。
尽管Webkit与Gecko使用略微不同的术语,这个过程还是基本相同的,如下:
- 浏览器会将HTML解析成一个DOM树,DOM 树的构建过程是一个深度遍历过程:当前节点的所有子节点都构建好后才会去构建当前节点的下一个兄弟节点。
- 将CSS解析成 CSS Rule Tree 。
- 根据DOM树和CSSOM来构造 Rendering Tree。注意:Rendering Tree 渲染树并不等同于 DOM 树,因为一些像Header或display:none的东西就没必要放在渲染树中了。
- 有了Render Tree,浏览器已经能知道网页中有哪些节点、各个节点的CSS定义以及他们的从属关系。下一步操作称之为layout,顾名思义就是计算出每个节点在屏幕中的位置。
- 再下一步就是绘制,即遍历render树,并使用UI后端层绘制每个节点。
4、浏览器的主要组件
1. 用户界面——包括地址栏、后退/前进按钮、书签目录等,也就是你所看到的除了用来显示你所请求页面的主窗口之外的其他部分。
2. 浏览器引擎——用来查询及操作渲染引擎的接口。
3. 渲染引擎——用来显示请求的内容,例如,如果请求内容为HTML,它负责解析HTML及CSS,并将解析后的结果显示出来。
4. 网络——用来完成网络调用,例如HTTP请求,它具有平台无关的接口,可以在不同平台上工作。
5. UI后端——用来绘制类似组合选择框及对话框等基本组件,具有不特定于某个平台的通用接口,底层使用操作系统的用户接口。
6. JS解释器——用来解释执行JS代码。
7. 数据存储——属于持久层,浏览器需要在硬盘中保存类似cookie的各种数据,HTML5定义了web database技术,这是一种轻量级完整的客户端存储技术。
浏览器渲染过程图:
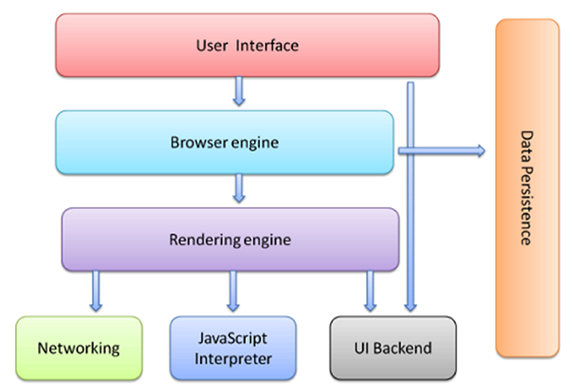
1、User Interface 用户界面,我们所看到的浏览器
2、Browser engine 浏览器引擎,用来查询和操作渲染引擎
3、Rendering engine 用来显示请求的内容,负责解析HTML、CSS
4、Networking 网络,负责发送网络请求
5、JavaScript Interpreter(解析者) JavaScript解析器,负责执行JavaScript的代码
6、UI Backend UI后端,用来绘制类似组合框和弹出窗口
7、Data Persistence(持久化) 数据持久化,数据存储 cookie、HTML5中的sessionStorage

 浙公网安备 33010602011771号
浙公网安备 33010602011771号