
【1022 | Day 50】Django之路由层(urls.py)
今日内容
-
图书管理系统表设计
-
django请求生命周期
-
路由层(urls.py)
- 路由分发
- 有/无分组
- 反向解析
- 名称空间
- 伪静态
- django版本区别
1. 图书管理系统表设计
- Book表
- Author表
- Publish表
- Author_detail表
- 表与表之间的关系
- Author和Author_detail是一对一
- Author和Book是多对多
- Publish和Book是一对多
注意:建议外键字段应放在多的那一方,并且在建立关系时变量名不要自己加上_id,系统会自己重命名加上,不要多此一举!

model.py
from django.db import models
#book表
class Book(models.Model):
title = models.CharField(max_length=32)
# 总共八位 小数占两位
price = models.DecimalField(max_digits=8,decimal_places=2)
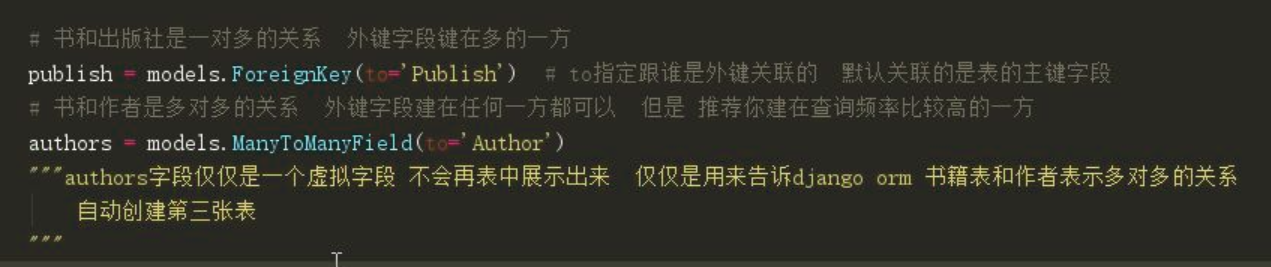
# 书和出版社是一对多的关系 外键字段键在多的一方
publish_id = models.ForeignKey(to='Publish') # to指定跟谁是外键关联的 默认关联的是表的主键字段
"""
ForeignKey字段 django orm在创建表的时候 会自动给该字段添加_id后缀
"""
# 书和作者是多对多的关系 外键字段建在任何一方都可以 但是 推荐你建在查询频率比较高的一方
authors = models.ManyToManyField(to='Author')
"""
authors字段仅仅是一个虚拟字段 不会再表中展示出来 仅仅是用来告诉django orm 书籍表和作者表示多对多的关系
自动创建第三张表
"""
#author表
class Author(models.Model):
name = models.CharField(max_length=32)
phone = models.BigIntegerField()
# 一对一字段 建在哪张表都可以 但是推荐你建在 查询频率比较高的那张表
author_detail = models.OneToOneField(to='AuthorDetail')
"""
OneToOneField字段 django orm在创建表的时候 会自动给该字段添加_id后缀
"""
#publish表
class Publish(models.Model):
name = models.CharField(max_length=32)
addr = models.CharField(max_length=255)
#AuthorDetail表
class AuthorDetail(models.Model):
addr = models.CharField(max_length=255)
age = models.IntegerField()
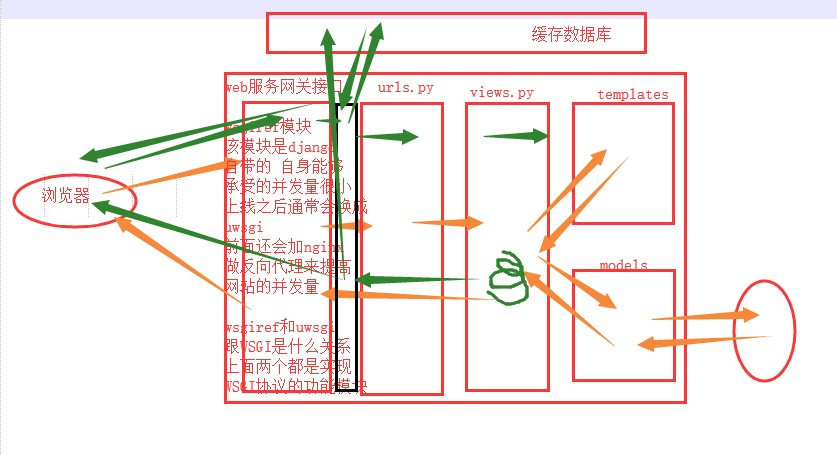
2. django请求生命周期
3. 路由层(urls.py)

原因:
- 随着项目功能的增加,app会越来越多,路由也越来越多,每个app都会有属于自己的路由。
- 如果再将所有的路由都放到一张路由表中,会导致结构不清晰,不便于管理,所以我们应该将app自己的路由交由自己管理。
- 然后在总路由表中做分发。
做法:
-
创建两个app
# 新建项目np1 D:\fxyadela>django-admin startproject np1 # 切换到项目目录下 D:\fxyadela>cd np1 # 创建app01和app02 D:\fxyadela\np1>python3 manage.py startapp app01 D:\fxyadela\np1>python3 manage.py startapp app02 -
在每个app下手动创建
urls.py来存放自己的路由
app01下的urls.py文件
from django.conf.urls import url
# 导入app01的views
from app01 import views
urlpatterns = [
url(r'^index/$',views.index),
]
app01下的views.py文件
from django.shortcuts import render
from django.shortcuts import HttpResponse
def index(request):
return HttpResponse('我是app01的index页面...')
**app02下的urls.py文件**
from django.conf.urls import url
# 导入app02的views
from app02 import views
urlpatterns = [
url(r'^index/$',views.index),
]
app02下的views.py文件
from django.shortcuts import render
from django.shortcuts import HttpResponse
def index(request):
return HttpResponse('我是app02的index页面...')
-
在总的urls.py文件中
from django.conf.urls import url,include from django.contrib import admin # 总路由表 urlpatterns = [ url(r'^admin/', admin.site.urls), # 新增两条路由,注意不能以$结尾 # include函数就是做分发操作的,当在浏览器输入http://127.0.0.1:8001/app01/index/时,会先进入到总路由表中进行匹配,正则表达式r'^app01/'会先匹配成功路径app01/,然后include功能会去app01下的urls.py中继续匹配剩余的路径部分 url(r'^app01/', include('app01.urls')), url(r'^app02/', include('app02.urls')), ]测试:
python manage.py runserver 8001 # 在浏览器输入:http://127.0.0.1:8001/app01/index/ 会看到:我是app01的index页面... # 在浏览器输入:http://127.0.0.1:8001/app02/index/ 会看到:我是app02的index页面...
4. 有名/无名分组
什么是分组?为何要分组呢?

比如我们开发了一个博客系统,当我们需要根据文章的id查看指定文章时,浏览器在发送请求时需要向后台传递参数(文章的id号)。
-
可以使用
http://127.0.0.1:8001/article/?id=3 -
也可以直接将参数放到路径中
http://127.0.0.1:8001/article/3/
针对后一种方式Django就需要直接从路径中取出参数,这就用到了正则表达式的分组功能了。
分组分为两种:无名分组与有名分组
4.1 无名分组
urls.py文件
from django.conf.urls import url
from django.contrib import admin
from app01 import views
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^aritcle/(\d+)/$',views.article),
]
# 下述正则表达式会匹配url地址的路径部分为:article/数字/,匹配成功的分组部分会以位置参数的形式传给 视图函数,有几个分组就传几个位置参数
views.py文件
from django.shortcuts import render
from django.shortcuts import HttpResponse
# 需要额外增加一个形参用于接收传递过来的分组数据
def article(request,article_id):
return HttpResponse('id为 %s 的文章内容...' %article_id)
测试:
python manage.py runserver 8001
# 在浏览器输入:http://127.0.0.1:8001/article/3/ 会看到: id为3的文章内容...
4.2 有名分组
urls.py
from django.conf.urls import url
from django.contrib import admin
from app01 import views
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^aritcle/(?P<article_id>\d+)/$',views.article),
]
# 该正则会匹配url地址的路径部分为:article/数字/,匹配成功的分组部分会以关键字参数(article_id=匹配成功的数字)的形式传给视图函数,有几个有名分组就会传几个关键字参数
views.py
from django.shortcuts import render
from django.shortcuts import HttpResponse
# 需要额外增加一个形参,形参名必须为article_id
def article(request,article_id):
return HttpResponse('id为 %s 的文章内容...' %article_id)
测试:
python manage.py runserver 8001
# 在浏览器输入:http://127.0.0.1:8001/article/3/ 会看到: id为3的文章内容...
总结:
- 有名分组和无名分组都是为了获取路径中的参数,并传递给视图函数,区别在于无名分组是以位置参数的形式传递,有名分组是以关键字参数的形式传递。
- 二者不能混合使用,可以单独多个使用
5. 反向解析
5.1 由来和定义
在软件开发初期,url地址的路径设计可能并不完美,后期需要进行调整,如果项 目中很多地方使用了该路径,一旦该路径发生变化,就意味着所有使用该路径的 地方都需要进行修改,这是一个非常繁琐的操作。
解决方案来了!!!

就是在编写一条url(regex, view, kwargs=None, name=None)时,可以**通过参数name为url地址的路径部分起一个别名****,项目中就可以通过别名来获取这个路径。
以后无论路径如何变化别名与路径始终保持一致。
上述方案中通过别名获取路径的过程称为反向解析
5.2 案例
登录成功跳转到index.html页面
在urls.py文件中
from django.conf.urls import url
from django.contrib import admin
from app01 import views
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^login/$', views.login, name='login_page'), # 路径login/的别名为login_page
url(r'^index/$', views.index, name='index_page'), # 路径index/的别名为index_page
]
在views.py文件中
from django.shortcuts import render
from django.shortcuts import reverse # 用于反向解析
from django.shortcuts import redirect #用于重定向页面
from django.shortcuts import HttpResponse
def login(request):
if request.method == 'GET':
# 当为get请求时,返回login.html页面,页面中的{% url 'login_page' %}会被反向解析成路径:/login/
return render(request, 'login.html')
# 当为post请求时,可以从request.POST中取出请求体的数据
name = request.POST.get('name')
pwd = request.POST.get('pwd')
if name == 'kevin' and pwd == '123':
url = reverse('index_page') # reverse会将别名'index_page'反向解析成路径:/index/
return redirect(url) # 重定向到/index/
else:
return HttpResponse('用户名或密码错误')
def index(request):
return render(request, 'index.html')
login.html文件
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>登录页面</title>
</head>
<body>
<!--强调:login_page必须加引号-->
<form action="{% url 'login_page' %}" method="post">
{% csrf_token %} <!--强调:必须加上这一行,后续我们会详细介绍-->
<p>用户名:<input type="text" name="name"></p>
<p>密码:<input type="password" name="pwd"></p>
<p><input type="submit" value="提交"></p>
</form>
</body>
</html>
index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>首页</title>
</head>
<body>
<h3>我是index页面...</h3>
</body>
</html>
测试:
python manage.py runserver 8001
# 在浏览器输入:http://127.0.0.1:8001/login/ 会看到登录页面,输入正确的用户名密码会跳转到index.html
# 当我们修改路由表中匹配路径的正则表达式时,程序其余部分均无需修改
总结:
#在views.py中,反向解析的使用:
url = reverse('index_page')
#在模版login.html文件中,反向解析的使用
{% url 'login_page' %}
5.3 拓展(了解)
如果路径存在分组的反向解析使用:
from django.conf.urls import url
from django.contrib import admin
from app01 import views
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^aritcle/(\d+)/$',views.article,name='article_page'), # 无名分组
url(r'^user/(?P<uid>\d+)/$',views.article,name='user_page'), # 有名分组
]
- 针对无名分组,比如我们要反向解析出:
/aritcle/1/这种路径,写法如下:
#在views.py中,反向解析的使用:
url = reverse('article_page',args=(1,))
#在模版login.html文件中,反向解析的使用
{% url 'article_page' 1 %}
- 针对有名分组,比如我们要反向解析出:
/user/1/这种路径,写法如下 :
#在views.py中,反向解析的使用:
url = reverse('user_page',kwargs={'uid':1})
#在模版login.html文件中,反向解析的使用
{% url 'user_page' uid=1 %}

6. 名称空间
当我们的项目下创建了多个app,并且每个app下都针对匹配的路径起了别名,如果别名存在重复,那么在反向解析时则会出现覆盖。
6.1 案例(覆盖)
-
创建两个app
# 新建项目np2 D:\fxyadela>django-admin startproject np1 # 切换到项目目录下 D:\fxyadela>cd np1 # 创建app01和app02 D:\fxyadela\np1>python3 manage.py startapp app01 D:\fxyadela\np1>python3 manage.py startapp app02 -
在每个app下手动创建
urls.py来存放自己的路由,并且为匹配的路径起别名app01下的urls.py文件
from django.conf.urls import url # 导入app01的views from app01 import views urlpatterns = [ # 为匹配的路径app01/index/起别名'index_page' url(r'^index/$',views.index,name='index_page'), ]app01下的views.py文件
from django.shortcuts import render from django.shortcuts import HttpResponse from django.shortcuts import reverse def index(request): url=reverse('index_page') return HttpResponse('app01的index页面,反向解析结果为%s' %url)
app02下的urls.py文件
from django.conf.urls import url from app02 import views urlpatterns = [ # 为匹配的路径app02/index/起别名'index_page',与app01中的别名相同 url(r'^index/$',views.index,name='index_page'), ]app02下的views.py文件
from django.shortcuts import render from django.shortcuts import HttpResponse from django.shortcuts import reverse def index(request): url=reverse('index_page') return HttpResponse('app02的index页面,反向解析结果为%s' %url) -
在总的urls.py文件中
from django.conf.urls import url,include from django.contrib import admin # 总路由表 urlpatterns = [ url(r'^admin/', admin.site.urls), # 新增两条路由,注意不能以$结尾 # include函数就是做分发操作的,当在浏览器输入http://127.0.0.1:8001/app01/index/时,会先进入到总路由表中进行匹配,正则表达式r'^app01/'会先匹配成功路径app01/,然后include功能会去app01下的urls.py中继续匹配剩余的路径部分 url(r'^app01/', include('app01.urls')), url(r'^app02/', include('app02.urls')), ]
测试:
```python
python manage.py runserver 8001
# 在浏览器输入:http://127.0.0.1:8001/app01/index/ 会看到:我是app01的index页面...
# 在浏览器输入:http://127.0.0.1:8001/app02/index/ 会看到:我是app02的index页面...
在测试时,无论在浏览器输入:
http://127.0.0.1:8001/app01/index/还是输入http://127.0.0.1:8001/app02/index/
针对别名'index_page'反向解析的结果都 是/app02/index/,覆盖了app01下别名的解析。
6.2 解决方案
-
解决这个问题的方法之一:就是避免使用相同的别名。
-
解决这个问题的方法之二:如果就想使用相同的别名, 那就需要用到django中名称空间的概念,将别名放到不同的名称空间中。这样即便是出现重复,彼此也不会冲突。
具体做法如下:
-
总urls.py在路由分发时,指定名称空间
from django.conf.urls import url, include from django.contrib import admin # 总路由表 urlpatterns = [ url(r'^admin/', admin.site.urls), # 传给include功能一个元组,元组的第一个值是路由分发的地址,第二个值则是我们为名称空间起的名字 url(r'^app01/', include(('app01.urls','app01'))), url(r'^app02/', include(('app02.urls','app02'))), ] -
修改每个app下的view.py中视图函数,针对不同名称空间中的别名
index_page做反向解析app01下的views.py
from django.shortcuts import render from django.shortcuts import HttpResponse from django.shortcuts import reverse def index(request): url=reverse('app01:index_page') # 解析的是名称空间app01下的别名'index_page' return HttpResponse('app01的index页面,反向解析结果为%s' %url) -
测试
python manage.py runserver 8001
浏览器输入:http://127.0.0.1:8001/app01/index/反向解析的结果是/app01/index/
浏览器输入:http://127.0.0.1:8001/app02/index/ 反向解析的结果 是/app02/index/
6.3 总结
1、在视图函数中基于名称空间的反向解析,用法如下
url=reverse('名称空间的名字:待解析的别名')
2、在模版里基于名称空间的反向解析,用法如下
<a href="{% url '名称空间的名字:待解析的别名'%}">哈哈</a>

7. 伪静态
7.1 定义
- 网站本身是动态网页如.php、.asp、.aspx等格式动态网页,有时这类动态网页还跟
“ ? ”加参数来读取数据库内不同资料。 - 很典型的案例即是discuz论坛系统,后台就有一个设置伪静态功能。开启伪静态后,动态网页即被转换重写成静态网页类型页面,通过浏览器访问地址和真的静态页面没区别。
- 前提服务器支持伪静态重写URL Rewrite功能。
需要伪静态功能地方:
- 考虑搜索引擎优化SEO,将动态网页通过服务器处理成静态页面,如
www.xxx.com/jk/fd.php?=12这样的动态网页处理成www.xxx.com/jk-fd-12.html这样格式静态页面。 - 常见的论坛帖子页面,都是经过伪静态处理成静态页面格式
http://www.divcss5.com/html页面。 - 考虑网站所用的程序语言不易被发现,经过重写来伪静态来将动态网页的程序后缀变为html的静态页面格式。
7.2 弊端
当然犹如一篇文章的作者所说的:"如果流量稍大一些使用伪静态就出现CPU使用超负荷,我的同时在线300多人就挂了,而不使用伪静态的时候同时在线超500人都不挂,我的IIS数是1000。”
确实是这样的,由于伪静态是用正则判断而不是真实地址,分辨到底显示哪个页面的责任也由直接指定转由CPU来判断了,所以CPU占有量的上升,确实是伪静态最大的弊病。
8. 虚拟环境
- 通常针对不同的项目只会安装该项目所用的模块(用不到的一般不装)
- 不同的项目由专门的解释器环境与之对应
- 每创建一个虚拟环境就相当于重新下载了一个纯净的python解释器
- 虚拟环境不要创建太多个, 会占硬盘资源的操作
9. Django版本区别
django1.x VS django2.x
区别一:
- urls.py中1.x用的是url,而2.x中用的是path
- 2.x中的path第一个不支持正则表达式(就是不加^和/也不会瞎匹配),写什么匹配什么
- 2.x里面的
re_path就是1.x版本里的url
区别二:
- django2.x默认支持一下5种转换器(Path converters)
str, 匹配除了路径分隔符(/)之外的非空字符串,这是默认的形式
int, 匹配正整数,包含0。
slug, 匹配字母、数字以及横杠、下划线组成的字符串。
uuid, 匹配格式化的uuid,如 075194d3-6885-417e-a8a8-6c931e272f00。
path, 匹配任何非空字符串,包含了路径分隔符(/)(不能用?)
例如:
path('articles/<int:year>/<int:month>/<slug:other>/', views.article_detail)
# 针对路径http://127.0.0.1:8000/articles/2009/123/hello/,path会匹配出参数year=2009,month=123,other='hello'传递给函数article_detail
今天的内容不是一般多,但是其实也没什么大不了!!!正则表达式和数据库都需要复习一下,朋友们!!!别偷懒哦~

