1-linux 命令和基础知识
- iostat
- 开机启动的应用:systemctl list-unit-files --type=service --state=enable
- systemctl status <service-name>
- systemctl disable <service-name>
- sudo systemctl enable <service-name>
- sudo systemctl start <service-name> // 运行
- 添加自己的应用自启动:
-
sudo nano /etc/systemd/system/myapp.service # 没有就创建 =====内容: [Unit] Description=My Custom Application After=network.target # 确保网络就绪后启动 [Service] Type=simple User=yourusername # 以哪个用户身份运行(如 root 或普通用户) WorkingDirectory=/path/to/your/app ExecStart=/usr/bin/node /path/to/your/app/main.js # 启动命令 Restart=always # 崩溃后自动重启 RestartSec=5 # 5秒后重试 [Install] WantedBy=multi-user.target # 多用户模式下启动 =====然后运行: sudo systemctl daemon-reload # 重新加载 systemd 配置 sudo systemctl enable myapp # 启用开机自启 sudo systemctl start myapp # 立即启动 sudo systemctl status myapp # 检查状态
-
- 查看日志:journalctl -u myapp -f
dmesg 可以 查看内核log
find . -type f ! -name 'cJSON.c' ! -name 'cJSON.h' -delete
//查看默认shell是 dash 还是 bash :
ls -la /bin/sh
//修改默认shell是 dash 还是 bash:
sudo dpkg-reconfigure dash -> 选 no 是 bash ,选 yes 是 dash
// dash 更轻量、启动更快,适合系统脚本(如 init 脚本)
设置开启自启动: sudo systemctl enable mysql 、取消:sudo systemctl disable mysql 、查看所有开启自启动的应用:systemctl list-unit-files --type=service | enabled、查看某个应用是否设置开机自启动:systemctl is-enabled mysql
查看操作系统版本:lsb_release -a
查看驱动:lsmod、 加载驱动:insmod g_ffs.ko 或者 modprobe g_ffs (自动处理依赖关系)、卸载驱动:rmmod g_ffs、 查看驱动(ko)的详细信息: modinfo g_ffs
ss -tulnp 查看 udp, tcp 的端口,p 可以看到它的 pid, 然后可以 ps aux | <pid>
压缩:tar zcvf /app/webs.tar.gz /opt/webs
解压:tar zxvf /app/webs.tar.gz -C /opt/
# 这样 /opt/下面还会有一个 opt 然后里面才是 webs, 也就是 /opt/opt/webs, 因为压缩的适合把 /opt/ 包括了
解决:
1. 压缩的时候:cd /opt/ -> tar -zcvf /app/webs.tar.gz webs
#这里 --strip-components=1 表示从文件路径中移除第一个路径组件。如果您的归档文件中有多层不需要的路径,可以增加这个数字来移除更多的层级
2. 解压的时候:tar -zxvf /app/webs.tar.gz --strip-components=1 -C /opt/
pip3 install wheel # 如果安全的时候提示各种undefined reference: export LDFLAGS="$LDFLAGS -lm -lpthread -ldl -lutil"
pip3 show wheel
pip3 list
为python安装pip: wget https://bootstrap.pypa.io/pip/3.6/get-pip.py -> python get-pip.py
确认模块是否已经被正确安装和发现并显示 curses 模块的实际位置:python -c "import curses; print(curses.__file__)"
指定python版本安装: python3.7 -m pip install <package> # 其实也可以直接 pip3.7 install <package>
查看安装了多少包: python3.7 -m pip list
查看pip版本:python3.7 -m pip --version
如果直接运行 pip 要看一下它对应的版本:pip --version || pip3 --version
# -m 参数用于运行模块。当你使用 python -m 后跟模块名时,Python 将会把该模块作为脚本运行。在这种情况下,
#python3.7 -m pip 实际上是在使用 Python 3.7 解释器来运行 pip 模块,这相当于调用了与 Python 3.7 相关联的 pip 命令
# --user 参数是一个安装选项,当你使用 pip install 时,加上 --user 参数会将包安装到用户的本地目录下,而不是全局的 Python 环境中。
#这意味着不需要管理员权限就可以安装包,并且这些包只对当前用户可用
- find out/lib/ -name *.so -exec nm -DA {} + | grep AAA // 2025-6-27 也是 找到库里面包含 AAA 的 并输出库名, 但是更优雅。 -DA 里的A 是--print-file-name简写、 + 是表示一次尽可能处理多个文件 ( nm -DA lib1.so lib2.so lib3.so ), /; 表示每个文件都单独处理一次(nm -DA lib1.so 、nm -DA lib2.so、nm -DA lib3.so)
- find lib -name *.so -exec nm -D {} \; | grep AAA // 找到库里面包含 AAA
- find lib -name *.so -exec sh -c 'nm -D "$1" | grep "AAA" && echo "$1"' _ {} \; // 找到库里面包含 AAA 的 并输出库名
- find . -path ./mnt -prune -o -name *.conf //
-path ./mnt:匹配的是当前目录下的mnt目录、-prune:如果找到了./mnt目录,不进入该目录、-o:逻辑或操作,用于连接两个条件 - find 4.2.9/1-install-1-/lib -name *.so* -exec du -sh {} +
update-alternatives(更新备选方案)
=== 配置替代版本:
sudo update-alternatives --install /usr/bin/python python /usr/bin/python2.7 10
sudo update-alternatives --install /usr/bin/python python /usr/bin/python3.8 20
这里 /usr/bin/python 是你希望替换的程序的路径
python 是程序的名称
/usr/bin/python2.7 和 /usr/bin/python3.8 分别是两个版本的完整路径
10 和 20 则是它们的优先级。
=== 设置默认版本:
sudo update-alternatives --config python
这将列出所有可用的版本,并让你选择一个作为默认版本
=== 查看当前配置
sudo update-alternatives --display python
=== 删除替代版本
sudo update-alternatives --remove python /usr/bin/python2.7
# ============================ 多个cmake
# 1. 把默认的cmake 改名
mv /usr/bin/cmake /use/bin/cmake3.10.2
# 2.下载并编译新的cmake
wget https://cmake.org/files/v3.21/cmake-3.21.3.tar.gz -O 3.21.3
tar -zxvf 3.21.3.tgz -> cd 3.21.3 -> ./bootstrap --prefix=./1-install-1-/opt/cmake -> make -j4 -> make install
# 3. 把两个cmake 都添加到 update-alternatives
sudo update-alternatives --install /usr/bin/cmake cmake /use/bin/cmkae3.10.2 10
sudo update-alternatives --install /usr/bin/cmake cmake /home/fx/share/compile/21-cmake/3.21.3/1-install-1-/bin/cmake 20
# === python 的一些命令
sudo apt install build-essential libssl-dev libffi-dev python3.6-dev
python3.6 -m pip install cffi
编译时查看支持哪些选项:cmake -LAH . 或者 ./configure --help // 其实cmake的话支持去看cmakelist.txt 最好了,autoreconf -fiv 命令可以根据configure.ac来生成传统的 configure 脚本
这个命令是Autoconf工具套件的一部分
强制指定静态库:-l:libts.aapt 安装了新软件:dpkg --list yasm、dpkg -L yasm | more 可以这样先观察一下新成员
free -d 或者 top
top 显示 203676K used,这指的是包括 buffers 和 cache 的已用 RAM,是总量
free 显示 used 85M(即 85 * 1024 = 87040K),但是 free 还显示了 buff/cache 113M(即 113 * 1024 = 115856K)。将这两者加起来(87040K + 115856K)
您会得到接近 top 命令显示的已用内存数量
Buffers:这部分内存被内核用作文件系统的缓冲区,通常用于存储即将写入磁盘的数据或从磁盘读取的数据
Cached:这部分内存被用作文件内容的缓存,这样当文件再次被读取时,它们就可以直接从内存中获取,而不是从磁盘中读取,从而提高性能
进程:ps
磁盘:df -h
echo -e "a\na" > a.txt
find . ! -path ./a/* ! -path ./b/* -name 't.txt'
// -exec 对 find 找到的每个文件执行指定的命令。-exec 后面跟的是要执行的命令,{} 是一个占位符,它会被 find 命令找到的每个文件或目录的路径替换。 + 或 \; 是 -exec 动作的结束标志, \; 会对每个文件分别执行一次, 而 + 会尝试将尽可能多的文件名作为参数传递给后面的命令,减少执行次数。
find . -name "*.h" -exec grep -l "float32_h" {} + 或者 find . -name *h -print0 | xargs -0 grep -inr aa
find /usr/lib -name libisl.so* -exec ls -la {} + 或者 find /usr/lib -name libisl.so* -exec ls -la {} \;
find webs -type f -exec sed -i 's/1.2.7.6/1.2.7.7/g' {} +
打开终端当前路径的目录: xdg-open . | nautilus .
重启网络服务:sudo systemctl restart NetworkManager.service | sudo service network-manager restart | sudo /etc/init.d/networking restart
高频使用
netstat -tunlp | grep :80 # 通过端口号找到进程的pid
ps | grep 973 # 通过 pid 找到可执行程序
ldd /opt/sbin/webs # 通过可执行程序找到依赖的库文件
nm -D libexample.so || nm -g libexample.a # 找到库文件里的函数
# 对于静态库,还可以查看更详细的信息:ar -t libexample.a || nm libexample.a/object.o
# win也有类似的方法如:dumpbin /exports path\to\library.dll
关机:shutdown -h 0 或者 poweroff
文件和vim
vi插入模式(按 i 可插入)、vi命令行模式(按 Esc 再按:写入命令)、vi初始模式(按Esc) // vi 打开后默认就是初始模式不需要按 Esc
- vi初始模式下( ESC ):
- 位置跳转:gg 跳到文章开头、G 跳到文章结尾、 0 或者 ^ 跳到当前行的行首、按 $ 跳到当前行的行尾、按 10l 跳到当前光标往后的第10个位置(小写的L)
- 删除:
- dd 删除当前行、2dd 从当前行开始往后删除共删除2行、5,10d 是删除5到10行
- x 删除当前光标所在的文字、5x 从当前行文字开始往后删除共删除5个文字、清空文件:.,$d (dG)
- 复制:
- yy 复制当前行、5yy 从当前行开始往下共复制5行;必须使用 p 粘贴 ,粘贴到当前光标的下一行
- yw 复制从光标开始到结尾的字符串中间有空格或符号就停止、 5yw 复制5个字符; 必须使用 p 粘贴,从当前光标开始往后粘贴
- /aaa 在当前文章查找 aaa ,按回车跳到首次出现的那一行 n(查找下一个)、N(查找上一个) # 命令行模式下也可以推荐直接在初始模式用
- u 撤回上次操作 # 撤回一个 i(插入) 的操作、撤回一个 dd或yy
- 99 跳到从当前行往下的第 99 行,超过文件行数跳到末尾
- ctrl + f 向后翻屏、ctrl + b 向前翻屏
- vi命令行模式下( ESC + : ):
- 保存内容并退出:wq(wq!)、不保存内容并退出:q(q!)
- 99 跳到第 99 行
- set nu 显示行数
- 视图(窗口):
- 垂直拆分视图: :vsplit vim.txt、水平拆分视图: :split a.txt、关闭所有未修改过内容(只保留修改过的内容)::on、 会关闭除光标所在文件的其它所有同文件: :only、关闭所有文件: :qa
- 跳向下一个视图:ctrl + ww 、跳向上一个视图:ctrl + wp
- 移动到上方视图:ctrl + w + k 、移动到下方视图:ctrl + w + j 、移动到左方视图:ctrl + w + h 、移动到右方视图:ctrl + w + l
- 还原默认视图宽高:ctrl + w + = 、垂直展开当前视图:ctrl + w + | 、水平展开当前视图:ctrl + w + _
- 垂直拆分视图: :vsplit vim.txt、水平拆分视图: :split a.txt、关闭所有未修改过内容(只保留修改过的内容)::on、 会关闭除光标所在文件的其它所有同文件: :only、关闭所有文件: :qa
- 实例补充:
- vi a.txt +10 打开 a.txt 的同时跳到第10行
linux命令
常用
终端(窗口)操作
Ctrl + Alt + T:开启多个独立终端 Ctrl + Shift + T:一个终端开启多个小终端 (alt + 1 这样切换 ) Ctrl + Shift + 加号:放大终端字体 Ctrl + 减号:缩小终端字体 win + 上下: 最大化 和 标准化 ctrl+alt+上下: 和桌面切换 // 和 win + d 有点像 最大、最小等:和win一样 alt 加 空格然后选就好了 alt + f1: 切换终端等- ls -latr . # 查看当前目录下的所有文件及细节按时间反向排序
- ls | sort -n // 查看同时按数字大小的顺序排序
ls 选项
ls -la > ts.txt 将命令 ls -la 的结果覆盖写入到 ts.txt (没有ts.txt 就自动创建) ls >> ts.txt 将命令 ls 的结果追加写入到 ts.txt; ls -lat (按修改时间升序); ls -latr(按修改时候倒序) 利用sort: ls -l | sort +7 (日期为第8列) 时间从前到后 ls -l | sort -r +7 时间最近的在前面 附,ls命令的参数中文详解: -a 列出目录下的所有文件,包括以 . 开头的隐含文件。 -b 把文件名中不可输出的字符用反斜杠加字符编号(就象在C语言里一样)的形式列出。 -c 输出文件的 i 节点的修改时间,并以此排序。 -d 将目录象文件一样显示,而不是显示其下的文件。 -e 输出时间的全部信息,而不是输出简略信息。 -f -U 对输出的文件不排序。 -g 无用。 -i 输出文件的 i 节点的索引信息。 -k 以 k 字节的形式表示文件的大小。 -l 列出文件的详细信息。 -m 横向输出文件名,并以“,”作分格符。 -n 用数字的 UID,GID 代替名称。 -o 显示文件的除组信息外的详细信息。 -p -F 在每个文件名后附上一个字符以说明该文件的类型,“*”表示可执行的普通文件;“/”表示目录;“@”表示符号链接;“|”表示FIFOs;“=”表示套接字(sockets)。 -q 用?代替不可输出的字符。 -r 对目录反向排序。 -s 在每个文件名后输出该文件的大小。 -t 以时间排序。 -u 以文件上次被访问的时间排序。 -x 按列输出,横向排序。 -A 显示除 “.”和“..”外的所有文件。 -B 不输出以 “~”结尾的备份文件。 -C 按列输出,纵向排序。 -G 输出文件的组的信息。 -L 列出链接文件名而不是链接到的文件。 -N 不限制文件长度。 -Q 把输出的文件名用双引号括起来。 -R 列出所有子目录下的文件。 -S 以文件大小排序。 -X 以文件的扩展名(最后一个 . 后的字符)排序。 -1 一行只输出一个文件。
- cp ./gsoap/wsaapi.c . # 将 ./gsoap/wsaapi.c 文件复制到 当前目录下
cp (GNU coreutils) 8.28 选项
用法:cp [选项]... [-T] 源文件 目标文件 或:cp [选项]... 源文件... 目录 或:cp [选项]... -t 目录 源文件... 将SOURCE复制到DEST,或将多个SOURCE复制到DIRECTORY。 必选参数对长短选项同时适用。 -a, --archive 等于-dR --preserve=all --attributes-only 仅复制属性而不复制数据 --backup[=CONTROL 为每个已存在的目标文件创建备份 -b 类似--backup 但不接受参数 --copy-contents 在递归处理是复制特殊文件内容 -d 等于--no-dereference --preserve=links -f, --force 如果现有的目标文件不能打开,将其删除,然后重试(此选项在同时使用-n选项时被忽略) -i, --interactive 覆盖前提示(覆盖以前的-n选项) -H 遵循SOURCE中的命令行符号链接 -l, --link 硬链接文件而不是复制 -L, --dereference 始终遵循SOURCE中的符号链接 -n, --no-clobber 不要覆盖已存在的文件(使前面的 -i 选项失效) -P, --no-dereference 不跟随源文件中的符号链接 -p 等于--preserve=模式,所有权,时间戳 --preserve[=属性列表 保持指定的属性(默认:模式,所有权,时间戳),如果 可能保持附加属性:环境、链接、xattr 等 --sno-preserve=属性列表 不保留指定的文件属性 --parents 复制前在目标目录创建来源文件路径中的所有目录 -R, -r, --recursive 递归复制目录及其子目录内的所有内容 --reflink[=WHEN] 控制克隆/CoW 副本。请查看下面的内如。 --remove-destination 尝试打开目标文件前先删除已存在的目的地 文件 (相对于 --force 选项) --sparse=WHEN 控制创建稀疏文件的方式 --strip-trailing-slashes 删除参数中所有源文件/目录末端的斜杠 -s, --symbolic-link 只创建符号链接而不复制文件 -S, --suffix=后缀 自行指定备份文件的后缀 -t, --target-directory=目录 将所有参数指定的源文件/目录 复制至目标目录 -T, --no-target-directory 将目标目录视作普通文件 -u, --update 只在源文件比目标文件新,或目标文件 不存在时才进行复制 -v, --verbose 显示详细的进行步骤 -x, --one-file-system 不跨越文件系统进行操作 -Z 设置目标的SELinux安全上下文 文件为默认类型 --context[=CTX] 如-Z,或者如果指定了CTX,则设置SELinux或SMACK安全上下文到CTX --help 显示此帮助信息并退出 --version 显示版本信息并退出 默认情况下,源文件的稀疏性仅仅通过简单的方法判断,对应的目标文件目标文件也 被为稀疏。这是因为默认情况下使用了--sparse=auto 参数。如果明确使用 --sparse=always 参数则不论源文件是否包含足够长的0 序列也将目标文件创文 建为稀疏件。 使用--sparse=never 参数禁止创建稀疏文件。 当指定了--reflink[=always] 参数时执行轻量化的复制,即只在数据块被修改的 情况下才复制。如果复制失败或者同时指定了--reflink=auto,则返回标准复制模式。 备份后缀为“~”,除非使用--suffix或SIMPLE_backup_suffix设置。 版本控制方法可以通过--backup选项选择,也可以通过 VERSION_CONTROL环境变量。以下是值: none, off 不进行备份(即使使用了--backup 选项) numbered, t 备份文件加上数字进行排序 existing, nil 若有数字的备份文件已经存在则使用数字,否则使用普通方式备份 simple, never 永远使用普通方式备份 有一个特别情况:如果同时指定--force 和--backup 选项,而源文件和目标文件 是同一个已存在的一般文件的话,cp 会将源文件备份。
- rm a.txt # 删除 a.txt
rm (GNU coreutils) 8.28 选项
用法:rm [选项]... [文件]... Remove (unlink) the FILE(s). -f, --force 忽略不存在的文件和参数,从不提示 -i 每次删除前提示 -I 删除三个以上的文件之前提示一次,或者 当递归移除时;侵入性小于-i, 同时仍然为大多数错误提供保护 --interactive[=WHEN] 根据WHEN提示:从不,一次(-I),或 始终(-i);没有WHEN,始终提示 --one-file-system 递归删除一个层级时,跳过所有不符合命令行参 数的文件系统上的文件 --no-preserve-root 不要特别对待“/” --preserve-root 不删除“/”(默认值) -r, -R, --recursive 递归地删除目录及其内容 -d, --dir 删除空目录 -v, --verbose 解释正在做什么 --help 显示此帮助信息并退出 --version 显示版本信息并退出 默认时,rm 不会删除目录。使用--recursive(-r 或-R)选项可删除每个给定 的目录,以及其下所有的内容。 要删除名称以“-”开头的文件,例如“-foo”, 使用以下命令之一: rm -- -foo rm ./-foo 请注意,如果使用rm 来删除文件,通常仍可以将该文件恢复原状。如果想保证 该文件的内容无法还原,请考虑使用shred。实例
删除目录下除a.txt和b.txt之外的所有文件:rm !("a.txt"|"b.txt") 删除目录下除a.txt和b.txt之外的所有文件:find . -type f ! -name 'a.txt' ! -name 'b.txt' | xargs rm // makefile 推荐用这个 删除目录下除a.txt和b.txt之外的所有文件:ls | grep -v a.txt | grep -v b.txt | xargs -I . rm . 删除文件名以txt、php、tar结尾的文件:rm -rf *@(txt|php|tar) 删除目录下除a和b之外的所有目录: rm -rf !("a"|"b") 只删除目录下的a目录下的所有文件:rm ./a/\* 删除所有的nsmap文件只保留wsdd.nsmap:find . -name '[^wsdd.nsmap]*.nsmap' | xargs -I . rm . for file in "$dir/"*; do if [[ $file == *$file_name* ]]; then continue fi rm "$file" done
- ln -s f1 f3 # 根据原始文件 f1 创建一个软链接 f3(不加 -s 就是创建硬链接:ln f1 f2)
- 当删除原始文件 f1 后,硬连接 f2 不受影响,但是符号连接(软链接) f3 无效、当修改 f1 f2 f3 其中的一个文件时其它的两个文件自动跟着修改、软链接是以路径的形式存在(ls -l 的时首格显示 l ), 硬链接是以文件副本的形式存在(ls -l 的时首格显示 - ),但不占用实际空间(和源文件索引一样, 就像指针)、软链接可以跨文件系统也可以为目录做软链接, 硬链接这两者都不可以;软连接类似于为文件创建快捷方式, 硬链接类似于文件复制;ls -i 查看文件索引
- find . -type f -newermt "11:46" ! -name "*.sh" | xargs -I % rm -rf % # 在当前目录递归查找 类型是文件的、时间在 11:46之后的、所有的 sh 文件并且把它删除
find (GNU findutils) 4.7.0-git 选项
Usage: find [-H] [-L] [-P] [-Olevel] [-D debugopts] [path...] [expression] 默认路径为当前目录;默认表达式为 -print 表达式可能由下列成份组成:操作符、选项、测试表达式以及动作: 操作符 (优先级递减;未做任何指定时默认使用 -and): ( EXPR ) ! EXPR -not EXPR EXPR1 -a EXPR2 EXPR1 -and EXPR2 EXPR1 -o EXPR2 EXPR1 -or EXPR2 EXPR1 , EXPR2 位置选项 (总是真): -daystart -follow -regextype 普通选项 (总是真,在其它表达式前指定): -depth --help -maxdepth LEVELS -mindepth LEVELS -mount -noleaf --version -xdev -ignore_readdir_race -noignore_readdir_race 测试(N可以是 +N 或-N 或 N):-amin N -anewer FILE -atime N -cmin -cnewer 文件 -ctime N -empty -false -fstype 类型 -gid N -group 名称 -ilname 匹配模式 -iname 匹配模式 -inum N -ipath 匹配模式 -iregex 匹配模式 -links N -lname 匹配模式 -mmin N -mtime N -name 匹配模式 -newer 文件 -nouser -nogroup -path PATTERN -perm [-/]MODE -regex PATTERN -readable -writable -executable -wholename PATTERN -size N[bcwkMG] -true -type [bcdpflsD] -uid N -used N -user NAME -xtype [bcdpfls] -context 文本 actions: -delete -print0 -printf FORMAT -fprintf FILE FORMAT -print -fprint0 FILE -fprint FILE -ls -fls FILE -prune -quit -exec COMMAND ; -exec COMMAND {} + -ok COMMAND ; -execdir COMMAND ; -execdir COMMAND {} + -okdir COMMAND ;实例
find . -type f -newermt "11:46" ! -name "*.sh" | xargs -I % rm -rf % find . -type f -newermt "13:33" ! -name "*.sh" | xargs -I % mv % fx-obj/ -type f 表示只查找文件而非目录或链接等类型 -newermt "11:46" 表示时间在 11:46之后的文件, 前面加个 ! 就是在11:46之前的 ! -name "filename" 表示需要排除名为"filename"的文件 xargs -I % rm -rf % 把查到的删除掉 # xargs 是一条Unix操作系统的常用命令,将参数列表转换成小块分段传递给其他命令 使用 xargs 命令时并不是一定要使用 “{}” 方括号的,可能是因为 find 命令的( -exec )默认是 “{}” (为了统一)使用其他的定义符都是可以的(甚至你都可以用英文,数学等作为定义界定符) find . -name '*.nsmap' ! \( -name a.nsmap -o -name b.nsmap \) 查找所有的 nsmap 但是排除 a.nsmap 和 b.nsmap, 还不如 find . -name '*.nsmap' ! -name a.nsmap ! -name b.nsma 递归删除文件夹(不包括本身):find . -type d | sed -n '2,$p' | xargs rm -rf # sed -n '2,$p' 过滤掉本身 -iname 可以忽略大小写
- grep -inr "ENABLE_APPS" ./srt-master/ # 在 srt-master 里查找有 ENABLE_APPS 的文件,且忽略大小写、显示行号、递归查找
grep (GNU grep) 3.1 各选项解释
用法: grep [选项]... PATTERN [FILE]... -> 在每个文件中搜索PATTERN 例子: grep -i 'hello world' menu.h main.c 模式选择和解释: -E, --extended-regexp PATTERN是一个扩展的正则表达式 -F, --fixed-strings PATTERN是一组换行符分隔的字符串 -G, --basic-regexp PATTERN是一个基本的正则表达式(默认值) -P, --perl-regexp PATTERN是一个Perl正则表达式 -e, --regexp=PATTERN 用 PATTERN 来进行匹配操作 -f, --file=FILE 从 FILE 中取得 PATTERN -i, --ignore-case 忽略大小写 -w, --word-regexp 强制 PATTERN 仅完全匹配字词 -x, --line-regexp 强制 PATTERN 仅完全匹配一行 -z, --null-data 一个 0 字节的数据行,但不是空行 杂项: -s, --no-messages 不显示错误信息 -v, --invert-match 选中不匹配的行 -V, --version 显示版本信息并退出 --help 显示此帮助并退出 输出控制 : -m, --max-count=NUM 在NUM个选定行之后停止 -b, --byte-offset 用输出行打印字节偏移量 -n, --line-number 打印带有输出行的行号 --line-buffered 刷新每行的输出 -H, --with-filename 打印带有输出行的文件名 -h, --no-filename 输出时不显示文件名前缀 --label=LABEL 使用LABEL作为标准输入文件名前缀 -o, --only-matching 只显示匹配PATTERN 部分的行 -q, --quiet, --silent 不显示所有常规输出 --binary-files=TYPE 设定二进制文件的TYPE 类型; TYPE 可以是`binary', `text', 或`without-match' -a, --text 等同于 --binary-files=text -I 等同于 --binary-files=without-match -d, --directories=ACTION 读取目录的方式; ACTION 可以是`read', `recurse',或`skip' -D, --devices=ACTION 读取设备、先入先出队列、套接字的方式; ACTION 可以是`read'或`skip' -r, --recursive 等同于--directories=recurse -R, --dereference-recursive 同上,但遍历所有符号链接 --include=FILE_PATTERN 只查找匹配FILE_PATTERN 的文件 --exclude=FILE_PATTERN 跳过匹配FILE_PATTERN 的文件和目录 --exclude-from=FILE 跳过所有除FILE 以外的文件 --exclude-dir=PATTERN 跳过所有匹配PATTERN 的目录。 -L, --files-without-match 只打印没有选定行的FILEs的名称 -l, --files-with-matches 仅打印具有选定行的FILEs的名称 -c, --count 仅打印每个FILE的选定行数 -T, --initial-tab 使选项卡对齐(如果需要) -Z, --null 在FILE名称后打印0字节 文件控制: -B, --before-context=NUM 打印文本及其前面NUM 行 -A, --after-context=NUM 打印文本及其后面NUM 行 -C, --context=NUM 打印NUM 行输出文本 -NUM same as --context=NUM --color[=WHEN], --colour[=WHEN] 使用标记突出显示匹配的字符串; WHEN is 'always', 'never', or 'auto' -U, --binary 在EOL(MSDOS/Windows)时不要删除CR字符 当FILE为“-”时,读取标准输入。如果没有FILE,请读取“。”如果 递归,否则为“-”。如果少于两个FILEs,则假定-h。 如果选择了任何一行,则退出状态为0,否则为1; 如果出现任何错误并且没有给出-q,则退出状态为2。实例
grep -rn aaa --include="*.c" ../ # 递归查找aa, 且只显示 c 文件grep 正则使用
字符类 //字符类的搜索:如果我想要搜寻 test 或 taste 这两个单字时,可以发现到,其实她们有共通的 't?st' 存在~这个时候,我可以这样来搜寻: [root@www ~]# grep -n 't[ae]st' regular_express.txt 8:I can't finish the test. 9:Oh! The soup taste good. 其实 [] 里面不论有几个字节,他都谨代表某『一个』字节, 所以,上面的例子说明了,我需要的字串是『tast』或『test』两个字串而已! //字符类的反向选择 [^] :如果想要搜索到有 oo 的行,但不想要 oo 前面有 g,如下: [root@www ~]# grep -n '[^g]oo' regular_express.txt 2:apple is my favorite food. 3:Football game is not use feet only. 18:google is the best tools for search keyword. 19:goooooogle yes! 第 2,3 行没有疑问,因为 foo 与 Foo 均可被接受! 但是第 18 行明明有 google 的 goo 啊~别忘记了,因为该行后面出现了 tool 的 too 啊!所以该行也被列出来~ 也就是说, 18 行里面虽然出现了我们所不要的项目 (goo) 但是由於有需要的项目 (too) , 因此,是符合字串搜寻的喔! 至於第 19 行,同样的,因为 goooooogle 里面的 oo 前面可能是 o ,例如: go(ooo)oogle ,所以,这一行也是符合需求的! //字符类的连续:再来,假设我 oo 前面不想要有小写字节,所以,我可以这样写 [^abcd....z]oo , 但是这样似乎不怎么方便, //由於小写字节的 ASCII 上编码的顺序是连续的, 因此,我们可以将之简化为底下这样: [root@www ~]# grep -n '[^a-z]oo' regular_express.txt 3:Football game is not use feet only. 也就是说,当我们在一组集合字节中,如果该字节组是连续的,例如大写英文/小写英文/数字等等, 就可以使用[a-z],[A-Z],[0-9]等方式来书写,那么如果我们的要求字串是数字与英文呢? 呵呵!就将他全部写在一起,变成:[a-zA-Z0-9]。 //我们要取得有数字的那一行,就这样: [root@www ~]# grep -n '[0-9]' regular_express.txt 5:However, this dress is about $ 3183 dollars. 15:You are the best is mean you are the no. 1. 行首与行尾字节 ^ $ 行首字符: //如果我想要让 the 只在行首列出呢? 这个时候就得要使用定位字节了!我们可以这样做: [root@www ~]# grep -n '^the' regular_express.txt 12:the symbol '*' is represented as start. 此时,就只剩下第 12 行,因为只有第 12 行的行首是 the 开头啊~此外 //如果我想要开头是小写字节的那一行就列出呢?可以这样: [root@www ~]# grep -n '^[a-z]' regular_express.txt 2:apple is my favorite food. 4:this dress doesn't fit me. 10:motorcycle is cheap than car. 12:the symbol '*' is represented as start. 18:google is the best tools for search keyword. 19:goooooogle yes! 20:go! go! Let's go. //如果我不想要开头是英文字母,则可以是这样: [root@www ~]# grep -n '^[^a-zA-Z]' regular_express.txt 1:"Open Source" is a good mechanism to develop programs. 21:# I am VBird ^ 符号,在字符类符号(括号[])之内与之外是不同的! 在 [] 内代表『反向选择』,在 [] 之外则代表定位在行首的意义! // 那如果我想要找出来,行尾结束为小数点 (.) 的那一行: [root@www ~]# grep -n '\.$' regular_express.txt 1:"Open Source" is a good mechanism to develop programs. 2:apple is my favorite food. 3:Football game is not use feet only. 4:this dress doesn't fit me. 10:motorcycle is cheap than car. 11:This window is clear. 12:the symbol '*' is represented as start. 15:You are the best is mean you are the no. 1. 16:The world <Happy> is the same with "glad". 17:I like dog. 18:google is the best tools for search keyword. 20:go! go! Let's go. 特别注意到,因为小数点具有其他意义(底下会介绍),所以必须要使用转义字符(\)来加以解除其特殊意义! // 找出空白行: [root@www ~]# grep -n '^$' regular_express.txt 22: 因为只有行首跟行尾 (^$),所以,这样就可以找出空白行啦! 任意一个字节 . 与重复字节 * 这两个符号在正则表达式的意义如下: . (小数点):代表『一定有一个任意字节』的意思; * (星号):代表『重复前一个字符, 0 到无穷多次』的意思,为组合形态 //假设我需要找出 g??d 的字串,亦即共有四个字节, 起头是 g 而结束是 d ,我可以这样做: [root@www ~]# grep -n 'g..d' regular_express.txt 1:"Open Source" is a good mechanism to develop programs. 9:Oh! The soup taste good. 16:The world <Happy> is the same with "glad". 因为强调 g 与 d 之间一定要存在两个字节,因此,第 13 行的 god 与第 14 行的 gd 就不会被列出来啦! 如果我想要列出有 oo, ooo, oooo 等等的数据, 也就是说,至少要有两个(含) o 以上,该如何是好? 因为 * 代表的是『重复 0 个或多个前面的 RE 字符』的意义, 因此,『o*』代表的是:『拥有空字节或一个 o 以上的字节』,因此,『 grep -n 'o*' regular_express.txt 』将会把所有的数据都列印出来终端上! // 当我们需要『至少两个 o 以上的字串』时,就需要 ooo* ,亦即是: [root@www ~]# grep -n 'ooo*' regular_express.txt 1:"Open Source" is a good mechanism to develop programs. 2:apple is my favorite food. 3:Football game is not use feet only. 9:Oh! The soup taste good. 18:google is the best tools for search keyword. 19:goooooogle yes! //如果我想要字串开头与结尾都是 g,但是两个 g 之间仅能存在至少一个 o ,亦即是 gog, goog, gooog.... 等等,那该如何? [root@www ~]# grep -n 'goo*g' regular_express.txt 18:google is the best tools for search keyword. 19:goooooogle yes! //如果我想要找出 g 开头与 g 结尾的行,当中的字符可有可无 [root@www ~]# grep -n 'g.*g' regular_express.txt 1:"Open Source" is a good mechanism to develop programs. 14:The gd software is a library for drafting programs. 18:google is the best tools for search keyword. 19:goooooogle yes! 20:go! go! Let's go. 因为是代表 g 开头与 g 结尾,中间任意字节均可接受,所以,第 1, 14, 20 行是可接受的喔! 这个 .* 的 RE 表示任意字符是很常见的. //如果我想要找出『任意数字』的行?因为仅有数字,所以就成为: [root@www ~]# grep -n '[0-9][0-9]*' regular_express.txt 5:However, this dress is about $ 3183 dollars. 15:You are the best is mean you are the no. 1. 限定连续 RE 字符范围 {} 我们可以利用 . 与 RE 字符及 * 来配置 0 个到无限多个重复字节, 那如果我想要限制一个范围区间内的重复字节数呢? 举例来说,我想要找出两个到五个 o 的连续字串,该如何作?这时候就得要使用到限定范围的字符 {} 了。 但因为 { 与 } 的符号在 shell 是有特殊意义的,因此, 我们必须要使用字符 \ 来让他失去特殊意义才行。 //至於 {} 的语法是这样的,假设我要找到两个 o 的字串,可以是: [root@www ~]# grep -n 'o\{2\}' regular_express.txt 1:"Open Source" is a good mechanism to develop programs. 2:apple is my favorite food. 3:Football game is not use feet only. 9:Oh! The soup taste good. 18:google is the best tools for search ke 19:goooooogle yes! //假设我们要找出 g 后面接 2 到 5 个 o ,然后再接一个 g 的字串,他会是这样: [root@www ~]# grep -n 'go\{2,5\}g' regular_express.txt 18:google is the best tools for search keyword. //如果我想要的是 2 个 o 以上的 goooo....g 呢?除了可以是 gooo*g ,也可以是: [root@www ~]# grep -n 'go\{2,\}g' regular_express.txt 18:google is the best tools for search keyword. 19:goooooogle yes! 扩展grep(grep -E 或者 egrep): 使用扩展grep的主要好处是增加了额外的正则表达式元字符集。 //打印所有包含NW或EA的行。如果不是使用egrep,而是grep,将不会有结果查出。 # egrep 'NW|EA' testfile northwest NW Charles Main 3.0 .98 3 34 eastern EA TB Savage 4.4 .84 5 20 //对于标准grep,如果在扩展元字符前面加\,grep会自动启用扩展选项-E。 #grep 'NW\|EA' testfile northwest NW Charles Main 3.0 .98 3 34 eastern EA TB Savage 4.4 .84 5 20 //搜索所有包含一个或多个3的行。 # egrep '3+' testfile # grep -E '3+' testfile # grep '3\+' testfile #这3条命令将会 northwest NW Charles Main 3.0 .98 3 34 western WE Sharon Gray 5.3 .97 5 23 northeast NE AM Main Jr. 5.1 .94 3 13 central CT Ann Stephens 5.7 .94 5 13 //搜索所有包含0个或1个小数点字符的行。 # egrep '2\.?[0-9]' testfile # grep -E '2\.?[0-9]' testfile # grep '2\.\?[0-9]' testfile #首先含有2字符,其后紧跟着0个或1个点,后面再是0和9之间的数字。 western WE Sharon Gray 5.3 .97 5 23 southwest SW Lewis Dalsass 2.7 .8 2 18 eastern EA TB Savage 4.4 .84 5 20 //搜索一个或者多个连续的no的行。 # egrep '(no)+' testfile # grep -E '(no)+' testfile # grep '\(no\)\+' testfile #3个命令返回相同结果, northwest NW Charles Main 3.0 .98 3 34 northeast NE AM Main Jr. 5.1 .94 3 13 north NO Margot Weber 4.5 .89 5 9 不使用正则表达式 fgrep 查询速度比grep命令快,但是不够灵活:它只能找固定的文本,而不是规则表达式。 //如果你想在一个文件或者输出中找到包含星号字符的行 fgrep '*' /etc/profile for i in /etc/profile.d/*.sh ; do 或 grep -F '*' /etc/profile for i in /etc/profile.d/*.sh ; do
- mkdir -p ts/ts2/ts3 # 在ts目录下创建 ts2 目录并在 ts2 目录里创建 ts3
- wc -l a.txt b.txt #查看文件一共有多少行, 也可以这样计数:ls | wc -l 、ls -A | wc (ls -A 显示隐藏文件不包括 . .. )
- wc -l a.txt b.txt #查看文件一共有多少行, 也可以这样计数:ls | wc -l 、ls -A | wc (ls -A 显示隐藏文件不包括 . .. )
- cat a.txt #查看 a.txt 全部内容
- 如果 a.txt 太长了 可以使用 more a.txt 这样它从头显示按回车才慢慢显示剩下的, 或者使用 less a.txt (
与more类似,但提供了更多的导航和搜索选项。你可以使用上下箭头键、Page Up/Page Down 键等来浏览文件内容,按/键进行搜索,按n键查找下一个匹配项,按N键查找上一个匹配项,以及按q` 键退出) - head -n3 a.txt 查看 a.txt 的前三行(不指定行数默认是10行)
- tail -n2 a.txt 查看 a.txt 最后两行(不指定行数默认是10行)
- 如果 a.txt 太长了 可以使用 more a.txt 这样它从头显示按回车才慢慢显示剩下的, 或者使用 less a.txt (
- echo aaa > ts.txt、echo bbb >> ts.txt #分别是覆盖写入和追加写入到ts.txt
- chmod 666 a.txt #修改 a.txt 权限为 rwrwrw
- chmod 777 -R ts 递归将 ts 文件夹本身及里面所有的文件和文件夹权限修改
- chown -R fx ts 递归所属者( chown -R fx.fx ts 这样同时把组成员也修改了)
- chgrp -R fx ts 递归修改组成员
文件权限&月份缩写
0位:l 表示链接文件、d 表示目录、- 表示文件、b [块设备;硬盘]、c [字符设备文件;鼠标,键盘] 1-3位数字代表文件所有者的权限 4-6位数字代表同组用户的权限 7-9数字代表其他用户的权限 0 [ 无 --- ]、1 [ 执行 --x ]、2 [ 写 -w- ]、3 [ 写加执行 -wx ]、4 [ 读 r-- ]、5 [ 读加执行 r-x ]、6 [ 读加写 rw- ]、7 [ 读加写加执行 rwx ] -rw------- (600) 只有拥有者有读写权限。 -rw-r--r-- (644) 只有拥有者有读写权限;而属组用户和其他用户只有读权限。 -rwx------ (700) 只有拥有者有读、写、执行权限。 -rwxr-xr-x (755) 拥有者有读、写、执行权限;而属组用户和其他用户只有读、执行权限。 -rwx--x--x (711) 拥有者有读、写、执行权限;而属组用户和其他用户只有执行权限。 -rw-rw-rw- (666) 所有用户都有文件读、写权限。 -rwxrwxrwx (777) 所有用户都有读、写、执行权限。 月份缩写(1到12; 周一到周七):jan feb mar apr may jun jul aug sep oct nov dec ; mon tue wed thu fri sat sun
- history #查看之前敲的历史命令
- md5sum a.txt #得到 a.txt 数字指纹(报文),文件通过计算得到的一串字符串,文件内容的唯一标记(文件内容不变,指纹不会变)
- | # 是管道符它将前面每一个进程的输出(stdout)直接作为下一个进程的输入(stdin)
管道符解析
介绍: 管道符“|”仅能处理由前一个命令执行后传来的正确信息,如果命令执行异常,无法对异常信息进行处理 管道符是文本流操作,之后都是文本结果(也就是字符串) 管道符的用法: bash命令 | 管道命令 管道命令是指该命令必须能够接收标准输出, 如选取命令:cut,grep;排序命令:sort,wc,uniq;双向重定向:tee;字符转换命令:tr,col,join,paste,expand;切割命令:split;参数代换命令:xargs 测试: echo "2+4" | bc // 6 单独使用echo命令时直接将“2+4”作为文本输出了,而添加管理后,又将输出结果“2+4”作为输入内容传递给了计算器语言bc,对“2+4”经过运算后输出 cat hello.sh | sort 将前面cat命令输出的结果通过管道丢给sort命令,所以sort命令是对前面cat命令输出的文本进行排序 cat hello.sh | sort | uniq sort跟uniq结合使用才能有效去重,所以通过管道将sort处理后输出的文本丢给uniq处理,所以uniq处理的是排序好的文本,可以进行有效去重 ll -a /etc/ | grep yum 在显示/etc/文件夹里文件的结果中,搜索yum的文件名 例子: 通过ps命令可以查看系统中的进程,但如果需要查看指定进程,就需要在ps命令返回的结果中进行筛选,如查看aiserver进程: ps -aux | grep aiserver 获取/根目录下包含关键字"y"的文件信息: ls / | grep “y” less xxx.txt 使用管道的话则可以写成: cat xxx.txt | less 统计“/”下的文档的个数: ls / | wc -l 但很多命令不支持 | 管道来传递参数,此时需要 xargs 它能够捕获一个命令的输出,然后传递给另外一个命令 xargs 可以将管道或标准输入数据转换成命令行参数,也能够从文件的输出中读取数据。 xargs 也可以将单行或多行文本输入转换为其他格式,例如多行变单行,单行变多行。 xargs 默认的命令是 echo,这意味着通过管道传递给 xargs 的输入将会包含换行和空白,不过通过 xargs 的处理,换行和空白将被空格取代。 xargs 是一个强有力的命令,它能够捕获一个命令的输出,然后传递给另外一个命令。 查看a.txt: ls /home/book/fx/win/a.txt | xargs cat 多行输入单行输出: cat a.txt | xargs // cat a.txt | xargs -n3 这样就是多行输出(一行3个) 递归删除文件: find -name "*.json" | xargs rm -f 递归删除文件夹: find . -type d | sed -n '2,$p' | xargs rm -rf (sed -n '2,$p' 过滤掉本身)
- 查看图片:eog a.jpg
- 打开当前目录:nautilus .
- 修改ip地址(重启不生效):ifconig eth0 192.168.101.195
- which google-chrome ; which ls 搜索系统命令的位置(运行文件 不是安装目录)
- whereis cmake 可以找软件位置,还可以找到命令的二进制文件,源文件和手动页文件, 理解为 which 加强版
- ldd /bin/ln 查看可执行程序链接库,要跟绝对路径,配合which使用; 补充:ldd ts.so、ar t ts.a
- 压缩和解压
实例
.tar.gz 解压:tar zxvf FileName.tar.gz // x 是解开 压缩:tar zcvf FileName.tar.gz DirName // -c 是表示产生新的包, v 是显示压缩的信息 .gz 解压1:gunzip FileName.gz 解压2:gzip -d FileName.gz 压缩:gzip FileName // .tar 只是将多个文件或目录组合成一个单独的文件(打包),它不进行压缩。如果只是解除.tar(打包),直接 tar xvf xxx.tar 即可 // .gz 只能对单独的一个文件进行压缩 // .tar.gz 是一种同时使用了打包(tar)和压缩(gzip)的格式, 这个组合一般就用的很多,也有很多tar和其它的组合,如下就是 .tar.bz2 解压:tar jxvf FileName.tar.bz2 压缩:tar jcvf FileName.tar.bz2 DirName .bz2 解压1:bzip2 -d FileName.bz2 解压2:bunzip2 FileName.bz2 压缩: bzip2 -z FileName .tar.Z 解压:tar Zxvf FileName.tar.Z 压缩:tar Zcvf FileName.tar.Z DirName .Z 解压:uncompress FileName.Z 压缩:compress FileName .zip 解压:unzip FileName.zip 压缩:zip FileName.zip DirName .rar 解压:rar a FileName.rar 压缩:rar e FileName.rar 其它: sudo apt-get install unrar -> unrar x 文件名.rar tar xvJf a.tar.xz
- 获取根目录:pwd
- 查看环境变量:getenv
- 强制停止xx进程:killall -9 xx // kill友好的停止
- 查看编码格式:locale
安装
- 查找某个安装的包: apt list | grep -n '^qq' # -n 用正则 apt list --installed | grep ffmpeg
- 下载工具 wget :wget http://www.tortall.net/projects/yasm/releases/yasm-1.3.0.tar.gz # 单纯的下载工具,可以修改下载后的名字 wget -O wordpress.zip http://xxx
wget、apt-get、apt、dpkg 介绍和区别
1. wget 和 apt 1.1 Ubuntu中apt是一种包管理,直接通过apt install 软件名,即可完成安装,如果安装该软件需要其他的依赖包,也会自动帮你下载。并完成安装,配置 apt一般直接安装已经编译好的可执行文件,会直接帮你处理依赖关系,apt-get install安装目录是包的维护者确定的,不是用户。系统安装软件一般在/usr/share,可执行的文件在/usr/bin,配置文件可能安装到了/etc下等。文档一般在 /usr/share;可执行文件 /usr/bin;配置文件 /etc;lib文件 /usr/lib。 1.2 wget只是一种下载方式,类似于Windows上的迅雷,只是帮你把这个压缩包下载下来,还需要你自己手动安装并且配置环境,如果有相关的依赖包,还需要自己下载 apt的优点就是简单,方便,快捷 wget源码安装,优点:比较灵活,可以自己指定安装到某个路径下面。 2. apt-get 和 apt (apt = apt-get、apt-cache 和 apt-config 中最常用命令选项的集合) 通用的命令(源也是通用的): apt install apt-get install 安装软件包 apt remove apt-get remove 移除软件包, 仅删除包,但不会删除配置文件 apt purge apt-get purge 移除软件包及配置文件,卸载,完全删除 apt update apt-get update 刷新存储库索引 apt upgrade apt-get upgrade 升级所有可升级的软件包 apt autoremove apt-get autoremove 自动删除不需要的包 apt search apt-cache search 搜索应用程序 apt show apt-cache show 显示安装细节 apt full-upgrade apt-get dist-upgrade 在升级软件包时自动处理依赖关系 当然,apt 还有一些自己的命令: apt list 列出包含条件的包(已安装,可升级等) apt edit-sources 编辑源列表 当然,apt-cache 也有一些自己的命令: apt-cache search qq 3. dpkg 和 apt(apt 和 apt-get 命令都是基于 dpkg) dpkg -S softwarename 显示包含此软件包的所有位置 dpkg -L softwarename 显示安装路径。 dpkg -l softwarename查看软件名称 版本
状态
- netstat -a | grep tftp # 通过netstat (监控TCP/IP工具) 找出所有的网络端口然后过滤,当然也可以过滤端口号
net-tools 2.10-alpha 选项
usage: netstat [-vWeenNcCF] [<Af>] -r netstat {-V|--version|-h|--help} netstat [-vWnNcaeol] [<Socket> ...] netstat { [-vWeenNac] -i | [-cnNe] -M | -s [-6tuw] } -r, --route 显示路由表 -i, --interfaces 显示接口表 -g, --groups 显示多播组成员身份 -s, --statistics 显示网络统计信息(如SNMP -M, --masquerade 显示伪装的连接 -v, --verbose 显示详细信息 -W, --wide 不截断IP地址 -n, --numeric 不解析名称 --numeric-hosts 不解析主机名 --numeric-ports 忽略端口名称 --numeric-users 忽略用户名 -N, --symbolic 解析硬件名称 -e, --extend 显示更多信息 -p, --programs 显示套接字的PID/程序名称 -o, --timers 显示计时器 -c, --continuous 连续上市 -l, --listening 显示侦听服务器套接字 -a, --all 显示所有套接字(默认值:已连接) -F, --fib 显示转发信息库(默认) -C, --cache 显示路由缓存而不是 FIB -Z, --context 显示套接字的SELinux安全上下文 <Socket>={-t|--tcp} {-u|--udp} {-U|--udplite} {-S|--sctp} {-w|--raw} {-x|--unix} --ax25 --ipx --netrom <AF>=Use '-6|-4' or '-A <af>' or '--<af>';默认: inet 列出所有支持的协议: inet (DARPA Internet) inet6 (IPv6) ax25 (AMPR AX.25) netrom (AMPR NET/ROM) ipx (Novell IPX) ddp (Appletalk DDP) x25 (CCITT X.25)实例
netstat -nultp # 查看当前所有已经使用的端口情况
- ps aux | grep service_name # 打印出所有进程并过滤一下
ps from procps-ng 3.3.12 选项
Usage: ps [options] Basic options: -A, -e 所有进程 -a all with tty, except session leaders a all with tty, including other users -d all except session leaders -N, --deselect 否定选择 r 仅运行进程 T 该终端上的所有进程 x 不控制tty的进程 按列表选择: -C <command> 命令名称 -G, --Group <GID> 真实的组id或名称 -g, --group <group> 会话或有效组名称 -p, p, --pid <PID> 进程id --ppid <PID> 父进程id -q, q, --quick-pid <PID> 进程id(快速模式) -s, --sid <session> 会话id -t, t, --tty <tty> 航空站 -u, U, --user <UID> 有效的用户id或名称 -U, --User <UID> 真实的用户id或名称 选择选项的参数为: 逗号分隔的列表 e.g. '-u root,nobody' or 空白分隔的列表 list e.g. '-p 123 4567' 输出格式: -F extra full -f 完整格式,包括命令行 f, --forest ascii art process tree -H 显示进程层次结构 -j jobs format j BSD作业控制格式 -l long format l BSD long format -M, Z 添加安全数据(对于SELinux) -O <format> 预加载了默认列 O <format> as-O,具有BSD个性 -o, o, --format <format> 用户定义格式 s 信号格式 u 面向用户的格式 v 虚拟内存格式 X 寄存器格式 -y 不显示标志,显示rss与addr(与 -l 一起使用) --context 显示安全上下文(对于SELinux) --headers 重复标题行,每页一行 --no-headers do not print header at all --cols, --columns, --width <num> set screen width --rows, --lines <num> set screen height 显示线程: H 就好像它们是过程 -L 可能带有LWP和NLWP柱 -m、 m 后处理 -T 可能带有SPID列 其他选项 : -c 如何使用-l选项调度类 c 显示真实的命令名 e 显示命令后的环境 k、 --sort 将排序顺序指定为:[+|-]key[,[+|--]key[、…]] L 显示格式说明符 n 显示数字uid和wchan S、 --cumulative 包括一些已死亡的子进程数据 -y 不显示标志,显示rss(仅与-l一起显示) -V、 V,--version 显示版本信息并退出 -w、 w 无限制输出宽度 --help <simple|list|output|threads|misc|all> display help and exit实例
ps -aux 列表头解释: USER : 进程拥有者 PID : pid %CPU : 占有的CPU使用率 %MEM : 占用的记忆体使用率(物理内存与总内存的百分比) VSZ : 占用的虚拟记忆体大小(虚拟内存) RSS : 占用的记忆体大小(物理内存) TTY : 终端的次要装置号码(也可以认为是一个判断运行的标识) 该进程是在哪个终端机上面运作,若与终端机无关,则显示 ?。另外, tty1-tty6 是本机上面的登入者程序,若为 pts/0 等等的,则表示为由网络连接进主机的程序 STAT : 该进程的状态 R——Runnable(运行):正在运行或在运行队列中等待 S——sleeping(中断):休眠中,受阻,在等待某个条件的形成或接收到信号 D——uninterruptible sleep(不可中断):收到信号不唤醒和不可运行,进程必须等待直到有中断发生 Z——zombie(僵死):进程已终止,但进程描述还在,直到父进程调用wait4()系统调用后释放 T——traced or stoppd(停止):进程收到SiGSTOP,SIGSTP,SIGTOU信号后停止运 状态后缀表示:<:优先级高的进程 N:优先级低的进程 L:有些页被锁进内存 s:进程的领导者(在它之下有子进程)(也就是说包含子线程)l:ismulti-threaded (using CLONE_THREAD, like NPTL pthreads do)多线程 +:位于后台的进程组 START : 进程开始时间 TIME : 进程的执行时间 COMMAND: 该进程所执行的指令 ps aux --sort -rss 按rss排序查看内存
- service --status-all #显示出所有系统服务列表,其中"+"代表服务正在运行,而"-"代表服务处于关闭状态. start(启动)、stop(关闭)、restart(重启)
实例
service SCRIPT start #启动服务 service SCRIPT stop #停止服务 service SCRIPT restart #重启服务 service SCRIPT status #查看状态服务
- systemd -> systemctl :
systemd 介绍以及 systemctl 一些命令
systemd 是一个系统和服务管理器,广泛用于现代 Linux 发行版中。它是一个初始化系统(init system),负责在系统启动时启动和管理各种服务、守护进程和其他系统组件。 systemd 的设计目标是提供更快的启动时间和更强大的系统管理功能。 主要功能 系统初始化: systemd 替代了传统的 SysV init 系统,作为系统的第一个进程(PID 1)启动。 它负责启动系统的基本服务和守护进程,如网络服务、日志服务、定时任务等。 服务管理: systemd 使用 .service 单元文件来定义和管理服务。 提供了丰富的命令(如 systemctl)来启动、停止、重启和查询服务状态。 依赖管理: systemd 支持复杂的依赖关系管理,确保服务按正确的顺序启动。 例如,一个数据库服务可能依赖于网络服务,systemd 会确保在网络服务启动后再启动数据库服务。 系统启动目标: systemd 使用目标(target)来表示不同的系统状态,如 multi-user.target(多用户模式)和 graphical.target(图形界面模式)。 目标类似于传统的运行级别(runlevel),但提供了更多的灵活性和可配置性。 日志管理: systemd 内置了一个日志管理服务 journald,用于收集和存储系统日志。 提供了 journalctl 命令来查询和管理日志,如 journalctl -u myapp.service 定时任务: systemd 提供了 systemd-timer 单元类型,用于定义定时任务。 类似于 cron,但提供了更强大的功能和更好的集成。 资源控制: systemd 可以对服务进行资源限制和控制,如内存、CPU 使用率等。 使用 cgroups(控制组)来实现资源管理。 网络管理: systemd 提供了 systemd-networkd 和 systemd-resolved 等工具,用于网络配置和 DNS 解析。 常用命令 启动服务:sudo systemctl start <service> 停止服务:sudo systemctl stop <service> 重启服务:sudo systemctl restart <service> 查看服务状态:systemctl status <service> 启用服务(开机自启):sudo systemctl enable <service> 禁用服务(关闭自启):sudo systemctl disable <service> 查看所有服务单元文件:systemctl list-unit-files --type=service # 列出所有已安装的服务单元文件及其状态(如 enabled、disabled、static 等) 查看所有活动的服务:systemctl list-units --type=service 列出所有服务(包括未加载的): systemctl list-units --type=service --all 配置文件 systemd 服务的配置文件通常位于以下几个目录中: /etc/systemd/system/:用户自定义的服务单元文件。 /lib/systemd/system/:系统提供的服务单元文件。 /usr/lib/systemd/system/:第三方软件提供的服务单元文件。什么情况下 启动的服务会被 systemctl 托管呢?
systemctl 是 systemd 的一部分,负责管理系统中的服务、套接字、设备、挂载点等。当一个服务被 systemctl 托管时,意味着 systemd 负责管理该服务的启动、停止、重启和状态监控。 以下是几种常见的场景,使得启动的服务会被 systemctl 托管: 系统初始化时启动的服务: 在系统启动过程中,根据 /etc/systemd/system/ 和 /lib/systemd/system/ 目录下的 .service 文件配置,某些服务会被自动启动并由 systemctl 托管。 这些服务通常在系统的默认目标(如 multi-user.target 或 graphical.target)中定义为依赖项。 手动启动的服务: 当你使用 systemctl start <service> 命令手动启动一个服务时,该服务会被 systemctl 托管。 例如:sudo systemctl start apache2.service。 依赖关系启动的服务: 如果某个服务依赖于另一个服务,当主服务启动时,依赖的服务也会被自动启动并托管。 例如,mysql.service 可能依赖于 network-online.target,当网络准备就绪时,mysql.service 会被自动启动。 定时任务启动的服务: 使用 systemd-timer 定义的定时任务可以在指定的时间点启动服务,并且这些服务会被 systemctl 托管。 例如,一个每天运行备份任务的定时器会在指定时间启动备份服务。 用户自定义的服务: 用户可以在 /etc/systemd/system/ 或 ~/.config/systemd/user/ 目录下创建自定义的 .service 文件,并使用 systemctl 命令来管理这些服务。 例如,创建一个自定义的 myapp.service 文件,然后使用 sudo systemctl start myapp.service 启动该服务。 系统更新或配置更改后启动的服务: 在进行系统更新或配置文件更改后,某些服务可能会被重新启动或重新加载,并且这些操作也是由 systemctl 管理的。 例如,更新 nginx 配置文件后,使用 sudo systemctl reload nginx 重新加载配置。怎么样自己的可执行程序被 systemctl 托管呢
将你自己的可执行程序被 systemctl 托管,需要创建一个 .service 单元文件,并将其放置在适当的位置。以下是详细的步骤: 1. 创建服务单元文件 首先,你需要创建一个 .service 文件,该文件定义了你的可执行程序的启动和管理方式。假设你的可执行程序名为 myapp,你可以创建一个名为 myapp.service 的文件。 示例 myapp.service 文件: [Unit] Description=My Custom Application After=network.target [Service] User=your_username Group=your_groupname ExecStart=/path/to/myapp Restart=on-failure WorkingDirectory=/path/to/working_directory EnvironmentFile=/path/to/environment_file PIDFile=/run/myapp.pid [Install] WantedBy=multi-user.target 2. 解释各个部分 [Unit] 部分: Description:服务的简短描述。 After:指定该服务在哪些目标之后启动。这里设置为 network.target 表示在网络服务启动后启动。 [Service] 部分: User 和 Group:指定运行该服务的用户和组。 ExecStart:指定启动服务的命令。 Restart:指定服务在失败时的重启策略,例如 on-failure 表示只有在服务失败时才重启。或者 改为 no 就是不重启 WorkingDirectory:指定服务的工作目录。 EnvironmentFile:指定环境变量文件的路径。 PIDFile:指定 PID 文件的路径,用于跟踪服务的主进程。 [Install] 部分: WantedBy:指定该服务在哪个目标下启动。multi-user.target 表示在多用户模式下启动。 3. 将服务单元文件放置在适当位置 将 myapp.service 文件放置在 /etc/systemd/system/ 目录下。这个目录用于存放用户自定义的服务单元文件。 sudo cp /path/to/myapp.service /etc/systemd/system/ 4. 重新加载 systemd 配置 为了让 systemd 识别新的服务单元文件,需要重新加载配置。 sudo systemctl daemon-reload 5. 启动和管理服务 现在你可以使用 systemctl 命令来启动、停止、重启和查看服务状态。 启动服务:sudo systemctl start myapp.service 查看日志:journalctl -u myapp.service ========================== 临时被托管 systemd-run 命令可以临时创建和管理一个服务,而无需手动创建服务单元文件。 使用 systemd-run 启动服务: sudo systemd-run --unit=myrun-temp --scope ./myrun --unit=myrun-temp:指定服务的名称。 --scope:创建一个临时的服务范围。 /path/to/./myrun:要执行的命令。 最后看一下状态:systemctl status myrun-temp.scope
- 查看空间
- free # 快速显示系统使用和空闲的内存情况:
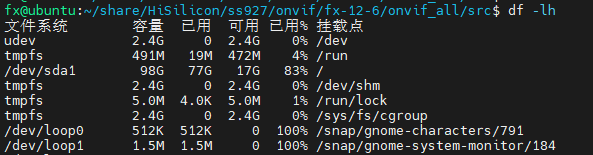
- df -lh # 查看磁盘占用情况:
- cat /proc/meminfo # 查看内存使用情况
- top
- free # 快速显示系统使用和空闲的内存情况:
- top # 查看系统的运行状态,包括负载,内存使用(交换分区),CPU使用、当前运行的线程,进程等信息
实例
top 列表头解释: PID:进程的ID USER:进程所有者 PR:进程的优先级别,越小越优先被执行 NI:nice值 VIRT:进程占用的虚拟内存 RES:进程占用的物理内存 SHR:进程使用的共享内存 S:进程的状态。S表示休眠,R表示正在运行,Z表示僵死状态,N表示该进程优先值为负数 %CPU:进程占用CPU的使用率 %MEM:进程使用的物理内存和总内存的百分比 TIME+:该进程启动后占用的总的CPU时间,即占用CPU使用时间的累加值。 COMMAND:进程启动命令名称
显示系统架构、内核、日期...
显示Linux 系统架构:uname -m 查看系统是 32 位还是 64 位:dpkg --print-architecture arch 显示机器的处理器架构(1) uname -m 显示机器的处理器架构(2) uname -r 显示正在使用的内核版本 dmidecode -q 显示硬件系统部件 - (SMBIOS / DMI) hdparm -i /dev/hda 罗列一个磁盘的架构特性 hdparm -tT /dev/sda 在磁盘上执行测试性读取操作 cat /proc/cpuinfo 显示CPU info的信息 cat /proc/interrupts 显示中断 cat /proc/meminfo 校验内存使用 cat /proc/swaps 显示哪些swap被使用 cat /proc/version 显示内核的版本 cat /proc/net/dev 显示网络适配器及统计 cat /proc/mounts 显示已加载的文件系统 lspci -tv 罗列 PCI 设备 lsusb -tv 显示 USB 设备 date 显示系统日期 cal 2007 显示2007年的日历表 date 041217002007.00 设置日期和时间 - 月日时分年.秒 clock -w 将时间修改保存到 BIOS- 查看硬盘使用情况: df -lf ; 查看磁盘挂载点: df -kh ; 查看硬盘信息:sudo fdisk -l ; 查看各分区结果:sudo blkid

配置相关
补充
架构
x86_64 = amd64: 最开始 intel 搞出来的指令集叫 IA-64,对应于当时的 IA-32 (也就是 x86 指令集)。但是 intel 的这个 IA-64 与 32 位指令集不兼容,反应寥寥,大家都不愿意支持。 这个时候, AMD 搞出了另外一个兼容 IA-32 兼容 X86 的 64 位指令集,名字叫做 amd64 。所以这个指令集正确的叫法就是 amd64。并得到市场认可 所以 intel是直接拿AMD的来用,所以就有这么两个名字了,其实是同一个东西。intel虽然自己额外起了个名,但也没有凑表脸的说什么INTEL64,他们只是起了个公司无关的名字x86_64,而AMD可以骄傲的把自己的公司名放在这个指令集上,这就是作者的特权 从那时起,直到今天,intel每卖出去一颗cpu,都要给amd一笔钱,支付指令集授权的费用。 aarch64(arm64): X86主要追求性能,但会导致功耗大,不节能,而ARM则是追求节能,低功耗,但和X86相比性能较差。 ARM主要应用于移动终端之中,类如手机,平板等,而X86则是主要应用于Intel,AMD等PC机,X86服务器中. x86采用CISC复杂指令集计算机(CISC是复杂指令集CPU,指令较多,因此使得CPU电路设计复杂,功耗大,但是对应编译器的设计简单。),而ARM采用的是RISC精简指令集计算机(RISC的精简指令集CPU,指令较少,功耗比较小,但编译器设计很复杂,它的关键在与流水线操作能在一个时钟周期完成多条指令)。好用的东西随笔
看安装的软件: GUI查看,应用商店 -> 已安装 apt list --installed (apt 和 apt-get 命令都是基于 dpkg) sudo dpkg -l 、sudo dpkg less (像more阅览文件)、dpkg -l |grep xxx 任务管理器: top 看空间: df 查看所有的进程信息: ps aux (如:ps aux | grep 3495、注意 -aux是查看用户名为x所拥有的进程信息) whereis cmake 可以找软件位置,还可以找到命令的二进制文件,源文件和手动页文件, 理解为 which 加强版 ldd /bin/ln 查看可执行程序链接库,要跟绝对路径,配合which使用- 使用bash: sh:#!/bin/bash makefile: SHELL = /bin/bash
- tab自动补全忽略文件大小写:cd ~ -> touch .inputrc -> vi .inputrc (添加 set completion-ignore-case on )
- 从tftp服务器获取文件:tftp -g -r /webs/js/network_e.js -l /opt/webs/js/network_e.js 192.168.101.99
- nfs挂载:mount -t nfs -o nolock,tcp 192.168.50.229:/home/bo/work/webAll /mnt
- 数据同步写入磁盘:sync
本文来自博客园,作者:封兴旺,转载请注明原文链接:https://www.cnblogs.com/fxw1/p/14775789.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号