

学习记录
-
volatile和atomic
volatile定义的变量只表明它可在所有线程中共享、可见,并不能保证原子性,即不保证安全性。保证只有一个线程在写某个数据。JVM为了提高数据存取的速度,允许每个线程在自己独立的数据块,对进程中共享的数据进行私有拷贝。volatile就是保证每次读数据时,读的都是存在共享数据块里的数据,而不是私有拷贝。
而java.util.concurrent.atomic.Atomic*被用来设计解决原子操作问题,保证操作的安全性。比如 i++(Long i = 0L)操作,实际上是三个动作:获取i、i+1、赋值给i;在多线程环境中,由于多个线程执行顺序的不可预知性,不能保证最后的结果如预期一致。这时就提现了atomic原子类的作用了,它通过 CAS(乐观锁算法)来保证操作的原子性。比如:
CAS比较与交换的伪代码可以表示为:
do{
备份旧数据;
基于旧数据构造新数据;
}while(!CAS( 内存地址,备份的旧数据,新数据 ))
2.原子类运用并不能直接保证操作的原子性(不能保证安全性)
由于多线程中存在着竞态条件(即某个计算的正确性取决于多个线程交替执行的时序),当操作多个变量时,即使用原子类,虽然可以保证单个变量的操作是原子的,但不能保证多个变量同时更新,或者同时获取,多线程环境下必然出错。
3.CAS
CAS,在Java并发应用中通常指CompareAndSwap或CompareAndSet,即比较并交换。
1、CAS是一个原子操作,它比较一个内存位置的值并且只有相等时修改这个内存位置的值为新的值,保证了新的值总是基于最新的信息计算的,如果有其他线程在这期间修改了这个值则CAS失败。CAS返回是否成功或者内存位置原来的值用于判断是否CAS成功。
2、JVM中的CAS操作是利用了处理器提供的CMPXCHG指令实现的。
优点:
-
竞争不大的时候系统开销小。
缺点:
-
循环时间长开销大。
-
ABA问题。
-
只能保证一个共享变量的原子操作
4.synchronized到底锁什么?
Java中每一个对象都可以作为锁,这是synchronized实现同步的基础:
- 普通同步方法,锁是当前实例对象
- 静态同步方法,锁是当前类的class对象
- 同步方法块,锁是括号里面的对象
锁优化
我们知道synchronized是重量级锁,效率不怎么滴,同时这个观念也一直存在我们脑海里,不过在jdk 1.6中对synchronize的实现进行了各种优化,使得它显得不是那么重了,那么JVM采用了那些优化手段呢?
jdk1.6对锁的实现引入了大量的优化,如自旋锁、适应性自旋锁、锁消除、锁粗化、偏向锁、轻量级锁等技术来减少锁操作的开销。
锁主要存在四中状态,依次是:无锁状态、偏向锁状态、轻量级锁状态、重量级锁状态,他们会随着竞争的激烈而逐渐升级。注意锁可以升级不可降级,这种策略是为了提高获得锁和释放锁的效率。
自旋锁
线程的阻塞和唤醒需要CPU从用户态转为核心态,频繁的阻塞和唤醒对CPU来说是一件负担很重的工作,势必会给系统的并发性能带来很大的压力。同时我们发现在许多应用上面,对象锁的锁状态只会持续很短一段时间,为了这一段很短的时间频繁地阻塞和唤醒线程是非常不值得的。所以引入自旋锁。
何谓自旋锁?
所谓自旋锁,就是让该线程等待一段时间,不会被立即挂起,看持有锁的线程是否会很快释放锁。怎么等待呢?执行一段无意义的循环即可(自旋)。
自旋等待不能替代阻塞,先不说对处理器数量的要求(多核,貌似现在没有单核的处理器了),虽然它可以避免线程切换带来的开销,但是它占用了处理器的时间。如果持有锁的线程很快就释放了锁,那么自旋的效率就非常好,反之,自旋的线程就会白白消耗掉处理的资源,它不会做任何有意义的工作,典型的占着茅坑不拉屎,这样反而会带来性能上的浪费。所以说,自旋等待的时间(自旋的次数)必须要有一个限度,如果自旋超过了定义的时间仍然没有获取到锁,则应该被挂起。
自旋锁在JDK 1.4.2中引入,默认关闭,但是可以使用-XX:+UseSpinning开开启,在JDK1.6中默认开启。同时自旋的默认次数为10次,可以通过参数-XX:PreBlockSpin来调整;
如果通过参数-XX:preBlockSpin来调整自旋锁的自旋次数,会带来诸多不便。假如我将参数调整为10,但是系统很多线程都是等你刚刚退出的时候就释放了锁(假如你多自旋一两次就可以获取锁),你是不是很尴尬。于是JDK1.6引入自适应的自旋锁,让虚拟机会变得越来越聪明。
适应自旋锁
JDK 1.6引入了更加聪明的自旋锁,即自适应自旋锁。所谓自适应就意味着自旋的次数不再是固定的,它是由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定。它怎么做呢?线程如果自旋成功了,那么下次自旋的次数会更加多,因为虚拟机认为既然上次成功了,那么此次自旋也很有可能会再次成功,那么它就会允许自旋等待持续的次数更多。反之,如果对于某个锁,很少有自旋能够成功的,那么在以后要或者这个锁的时候自旋的次数会减少甚至省略掉自旋过程,以免浪费处理器资源。
有了自适应自旋锁,随着程序运行和性能监控信息的不断完善,虚拟机对程序锁的状况预测会越来越准确,虚拟机会变得越来越聪明。
锁消除
为了保证数据的完整性,我们在进行操作时需要对这部分操作进行同步控制,但是在有些情况下,JVM检测到不可能存在共享数据竞争,这是JVM会对这些同步锁进行锁消除。锁消除的依据是逃逸分析的数据支持。
如果不存在竞争,为什么还需要加锁呢?所以锁消除可以节省毫无意义的请求锁的时间。变量是否逃逸,对于虚拟机来说需要使用数据流分析来确定,但是对于我们程序员来说这还不清楚么?我们会在明明知道不存在数据竞争的代码块前加上同步吗?但是有时候程序并不是我们所想的那样?我们虽然没有显示使用锁,但是我们在使用一些JDK的内置API时,如StringBuffer、Vector、HashTable等,这个时候会存在隐形的加锁操作。比如StringBuffer的append()方法,Vector的add()方法:
|
1
2
3
4
5
6
7
8
|
public void vectorTest(){ Vector<String> vector = new Vector<String>(); for(int i = 0 ; i < 10 ; i++){ vector.add(i + ""); } System.out.println(vector); } |
在运行这段代码时,JVM可以明显检测到变量vector没有逃逸出方法vectorTest()之外,所以JVM可以大胆地将vector内部的加锁操作消除。
锁粗化
我们知道在使用同步锁的时候,需要让同步块的作用范围尽可能小—仅在共享数据的实际作用域中才进行同步,这样做的目的是为了使需要同步的操作数量尽可能缩小,如果存在锁竞争,那么等待锁的线程也能尽快拿到锁。
在大多数的情况下,上述观点是正确的,LZ也一直坚持着这个观点。但是如果一系列的连续加锁解锁操作,可能会导致不必要的性能损耗,所以引入锁粗话的概念。
锁粗话概念比较好理解,就是将多个连续的加锁、解锁操作连接在一起,扩展成一个范围更大的锁。如上面实例:vector每次add的时候都需要加锁操作,JVM检测到对同一个对象(vector)连续加锁、解锁操作,会合并一个更大范围的加锁、解锁操作,即加锁解锁操作会移到for循环之外。
5.操作重排序
在没有同步的情况下,编译器、处理器以及运行时等都可能对操作的执行顺序进行一些意想不到的调整。在缺乏足够同步的多线程程序中,要想对内存操作的执行顺序进行判断,几乎无法得出正确的结论。(这看上去是一种失败的设计,但却能使JVM充分地利用现代多核处理器的强大性能。例如,在缺少同步的情况下,Java内存模型允许编译器对操作顺序进行重排序,并将数值缓存在寄存器中。此外,它还允许CPU对操作顺序进行冲排序,并将数值缓存在处理器特定的缓存中。)
比如下面的代码:主线程设置number和ready的值,读线程判断ready来打印出number。最后输出的不一定是42,可能一直循环,也可能输出0(因为重排序,先执行了ready=true)
public class NOVisibility {
private static class ReadThread extend Thread {
public void run(){
while(!ready)
Thread.yield();
System.out.println(number);
}
}
public static void main(String[] args){
new ReadThread().start();
number = 42;
ready = true;
}
}
6.线程封闭的方法
一、Ad-hoc线程封闭
指维护线程封闭性的职责完全由程序来实现。
二、栈封闭
在栈封闭中,只能通过局部变量才能访问对象。局部变量固有属性之一就是封闭在执行线程中。它们位于执行线程的栈中,其他线程无法访问这个栈。
三、ThreadLocal类
维持线程封闭性的一种更规范的方法是使用ThreadLocal,这个类能使线程中的某个值与保存值的对象关联起来。TRreadLocal提供了get与set等访问接口或方法,这些方法为每个使用该变量的线程都存有一份独立的副本,一次get总是返回由当前执行线程在调用set时设置的最新值。
7.Arrays.copyOf()方法是传递引用,保证不变性。即新的数组和源数组里的元素是相同的地址
例如:Student[] studentArray={student}, Student[] studentArrayCopy=Arrays.copyOf(studentArray),那么studentArrayCopy和studentArray中的元素student是同一个对象
8.final修饰基本类型变量,则不能改变变量的值。如果修饰引用类型变量,只是变量的地址不变,即每次都调用同一个变量,但变量引用的对象可以变
9.Collections.synchronizedList & CopyOnWriteArrayList
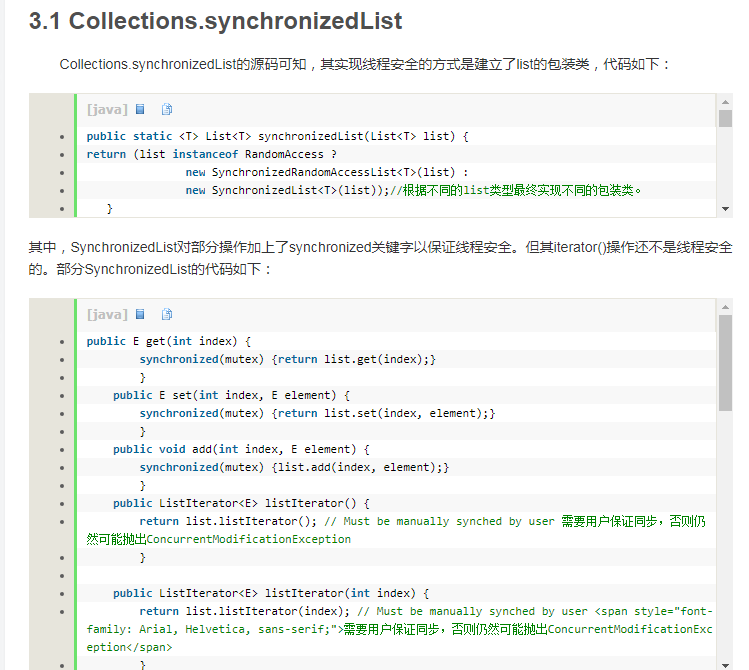
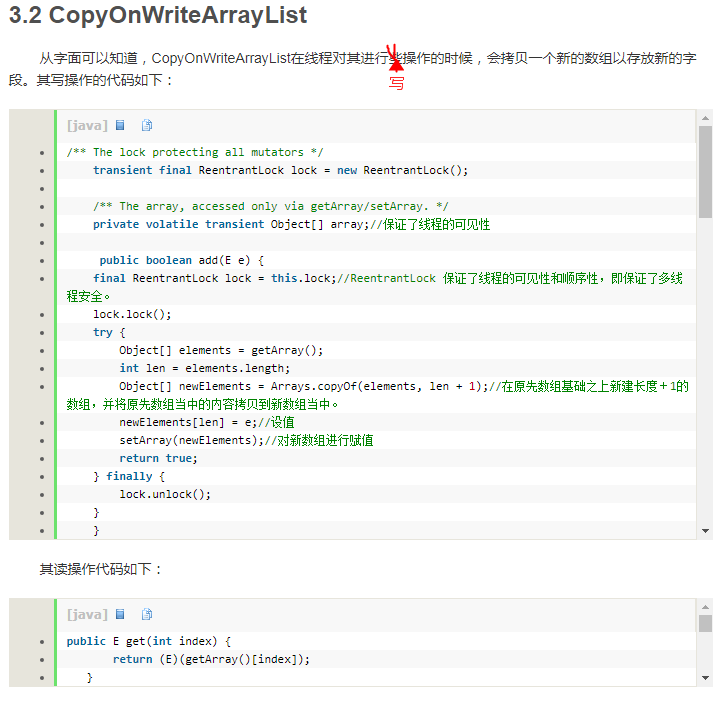
其中setArray()操作仅仅是对array进行引用赋值。Java中“=”操作只是将引用和某个对象关联,假如同时有一个线程将引用指向另外一个对象,一个线程获取这个引用指向的对象,那么他们之间不会发生ConcurrentModificationException,他们是在虚拟机层面阻塞的,而且速度非常快,是一个原子操作,几乎不需要CPU时间。
9.1Collections.synchronizedList和CopyOnWriteArrayList读写性能比较
9.2 结论
10.分布式锁
针对分布式锁的实现,目前比较常用的有以下几种方案:
基于数据库实现分布式锁
基于缓存(Redis,memcached,tair)实现分布式锁
基于Zookeeper实现分布式锁
在分析这几种实现方案之前我们先来想一下,我们需要的分布式锁应该是怎么样的?(这里以方法锁为例,资源锁同理)
可以保证在分布式部署的应用集群中,同一个方法在同一时间只能被一台机器上的一个线程执行。
这把锁要是一把可重入锁(避免死锁)
这把锁最好是一把阻塞锁(根据业务需求考虑要不要这条)
有高可用的获取锁和释放锁功能
获取锁和释放锁的性能要好
基于数据库实现分布式锁
基于数据库表
要实现分布式锁,最简单的方式可能就是直接创建一张锁表,然后通过操作该表中的数据来实现了。
当我们要锁住某个方法或资源时,我们就在该表中增加一条记录,想要释放锁的时候就删除这条记录。
基于数据库排他锁
除了可以通过增删操作数据表中的记录以外,其实还可以借助数据中自带的锁来实现分布式的锁。
我们还用刚刚创建的那张数据库表。可以通过数据库的排他锁来实现分布式锁。
在查询语句后面增加for update,数据库会在查询过程中给数据库表增加排他锁。当某条记录被加上排他锁之后,其他线程无法再在该行记录上增加排他锁。
我们可以认为获得排它锁的线程即可获得分布式锁,当获取到锁之后,可以执行方法的业务逻辑,执行完方法之后,再通过以下方法解锁:
通过connection.commit()操作来释放锁。
基于缓存实现分布式锁
相比较于基于数据库实现分布式锁的方案来说,基于缓存来实现在性能方面会表现的更好一点。而且很多缓存是可以集群部署的,可以解决单点问题。
目前有很多成熟的缓存产品,包括Redis,memcached以及我们公司内部的Tair。
这里以Tair为例来分析下使用缓存实现分布式锁的方案。关于Redis和memcached在网络上有很多相关的文章,并且也有一些成熟的框架及算法可以直接使用。
基于Tair的实现分布式锁其实和Redis类似,其中主要的实现方式是使用TairManager.put方法来实现。
基于Zookeeper实现分布式锁
基于zookeeper临时有序节点可以实现的分布式锁。
大致思想即为:每个客户端对某个方法加锁时,在zookeeper上的与该方法对应的指定节点的目录下,生成一个唯一的瞬时有序节点。
判断是否获取锁的方式很简单,只需要判断有序节点中序号最小的一个。
当释放锁的时候,只需将这个瞬时节点删除即可。同时,其可以避免服务宕机导致的锁无法释放,而产生的死锁问题。
来看下Zookeeper能不能解决前面提到的问题。
-
锁无法释放?使用Zookeeper可以有效的解决锁无法释放的问题,因为在创建锁的时候,客户端会在ZK中创建一个临时节点,一旦客户端获取到锁之后突然挂掉(Session连接断开),那么这个临时节点就会自动删除掉。其他客户端就可以再次获得锁。
-
非阻塞锁?使用Zookeeper可以实现阻塞的锁,客户端可以通过在ZK中创建顺序节点,并且在节点上绑定监听器,一旦节点有变化,Zookeeper会通知客户端,客户端可以检查自己创建的节点是不是当前所有节点中序号最小的,如果是,那么自己就获取到锁,便可以执行业务逻辑了。
-
不可重入?使用Zookeeper也可以有效的解决不可重入的问题,客户端在创建节点的时候,把当前客户端的主机信息和线程信息直接写入到节点中,下次想要获取锁的时候和当前最小的节点中的数据比对一下就可以了。如果和自己的信息一样,那么自己直接获取到锁,如果不一样就再创建一个临时的顺序节点,参与排队。
-
单点问题?使用Zookeeper可以有效的解决单点问题,ZK是集群部署的,只要集群中有半数以上的机器存活,就可以对外提供服务。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号