
langchain-ChatGLM调研
https://github.com/imClumsyPanda/langchain-ChatGLM
1. 确定显卡规格
lspci | grep -i nvidia
00:07.0 3D controller: NVIDIA Corporation GV100GL [Tesla V100 SXM2 32GB] (rev a1)
2. 确定显卡运行状况
nvidia-smi
如果有问题,需要先装显卡的驱动
apt search nvidia-driver
根据显卡规格,找到驱动型号,比如是510
apt install nvidia-driver-510
3. 安装依赖
# 拉取仓库
$ git clone https://github.com/imClumsyPanda/langchain-ChatGLM.git
# 进入目录
$ cd langchain-ChatGLM
# 安装依赖
$ pip install -r requirements.txt
4. 运行
python cli_demo.py
会自动加载模型文件
主体的流程参考下图,结合本地知识库的,文本生成方案
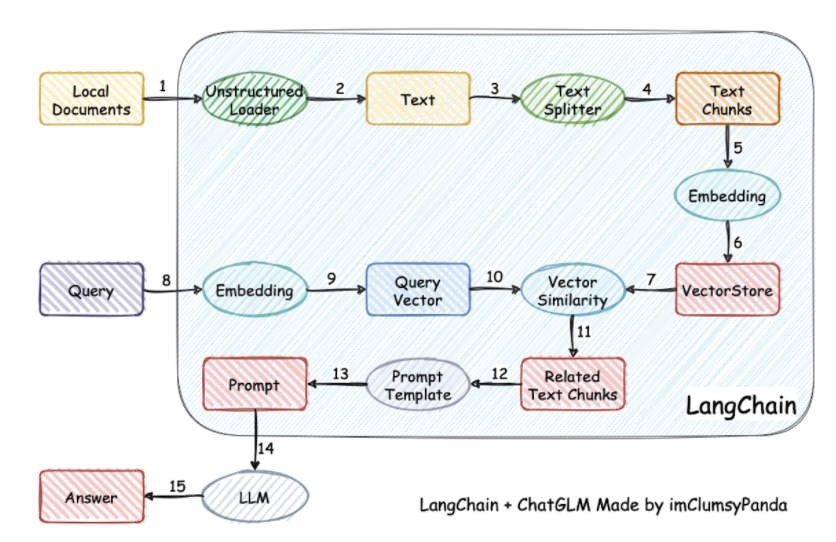
代码的逻辑实现上其实很简单,
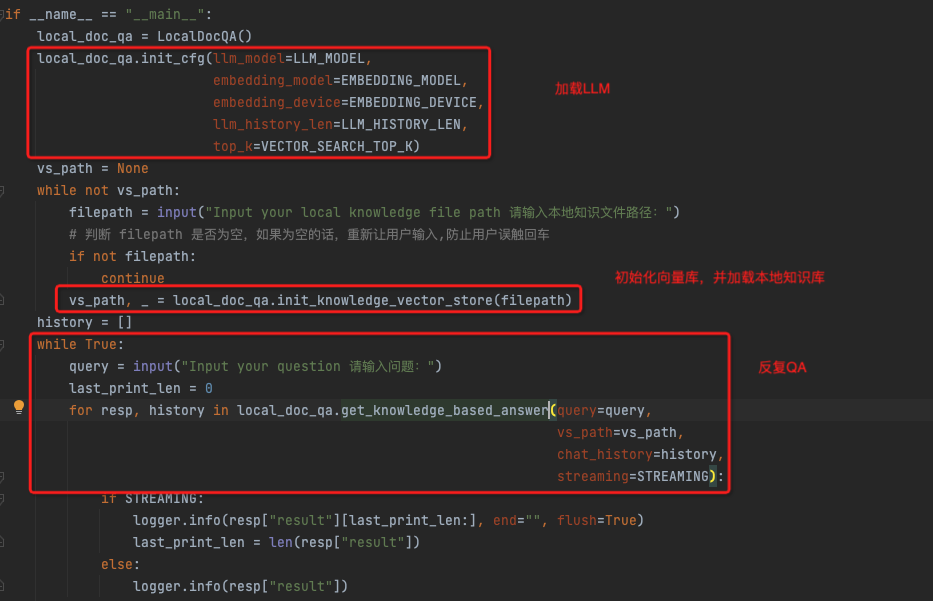
初始化LLM
分两步,加载llm模型和embedding模型
embedding模型是用来将文本转化为词向量的,这里dict中是ernie和text2vec两种
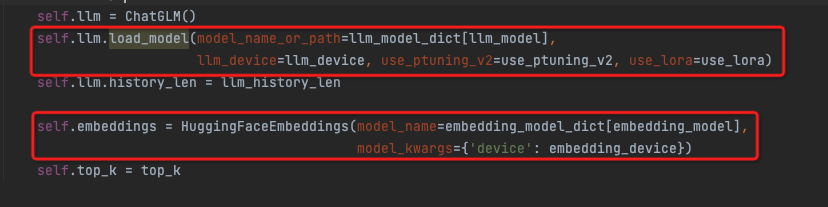
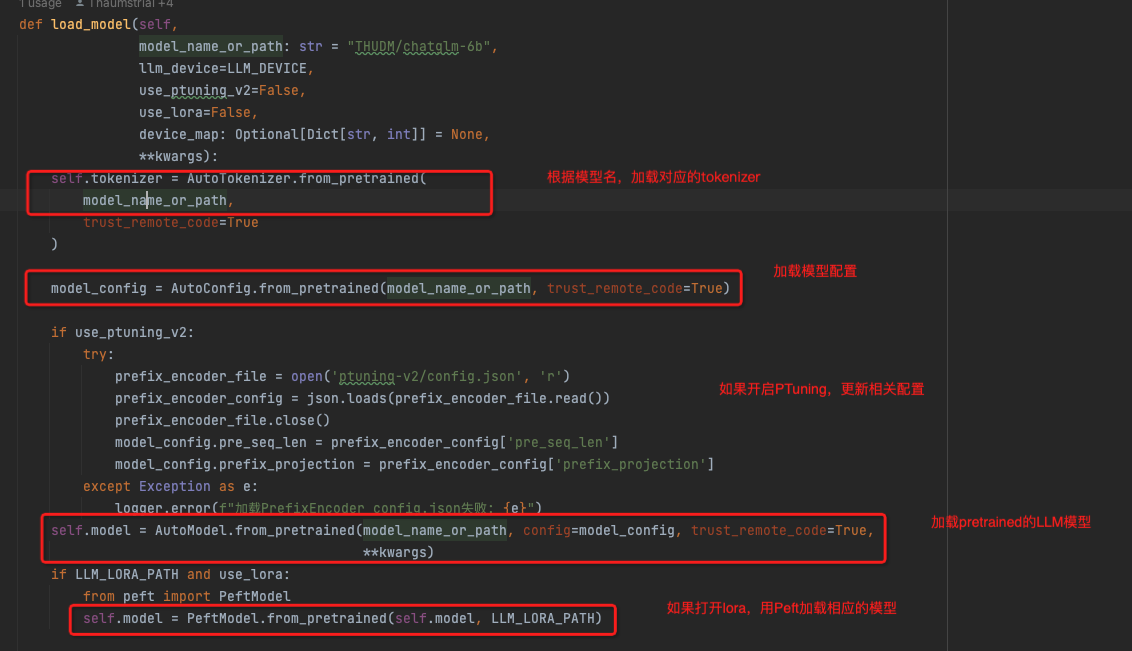
load_model
这里主要使用huggingface的transform模块进行模型加载,transform模块参考,https://zhuanlan.zhihu.com/p/558570740?utm_id=0
huggingface的这个模块封装的非常好,会自动的根据模型名称去自动下载和加载模型,还能自动选择配套的tokenizer或config
这里供选择的LLM,
"chatglm-6b-int4-qe": "THUDM/chatglm-6b-int4-qe",
"chatglm-6b-int4": "THUDM/chatglm-6b-int4",
"chatglm-6b-int8": "THUDM/chatglm-6b-int8",
"chatglm-6b": "THUDM/chatglm-6b",
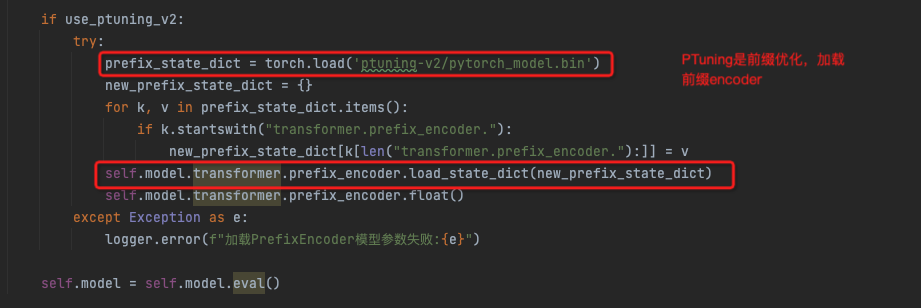
Peft是huggingface提供用于Fineture的模块
lora,p-tuning,ChartGLM采用的微调方式
参考,
https://zhuanlan.zhihu.com/p/627642632,大模型微调总结
https://zhuanlan.zhihu.com/p/583022692,P-Tuning】 一种自动学习 prompt pattern 的方法
https://github.com/huggingface/peft huggingface的peft库,包含prefix-tuning,prompt tuning,p-tuning,lora等
https://zhuanlan.zhihu.com/p/625468667, ChatGLM 微调实战(附源码)
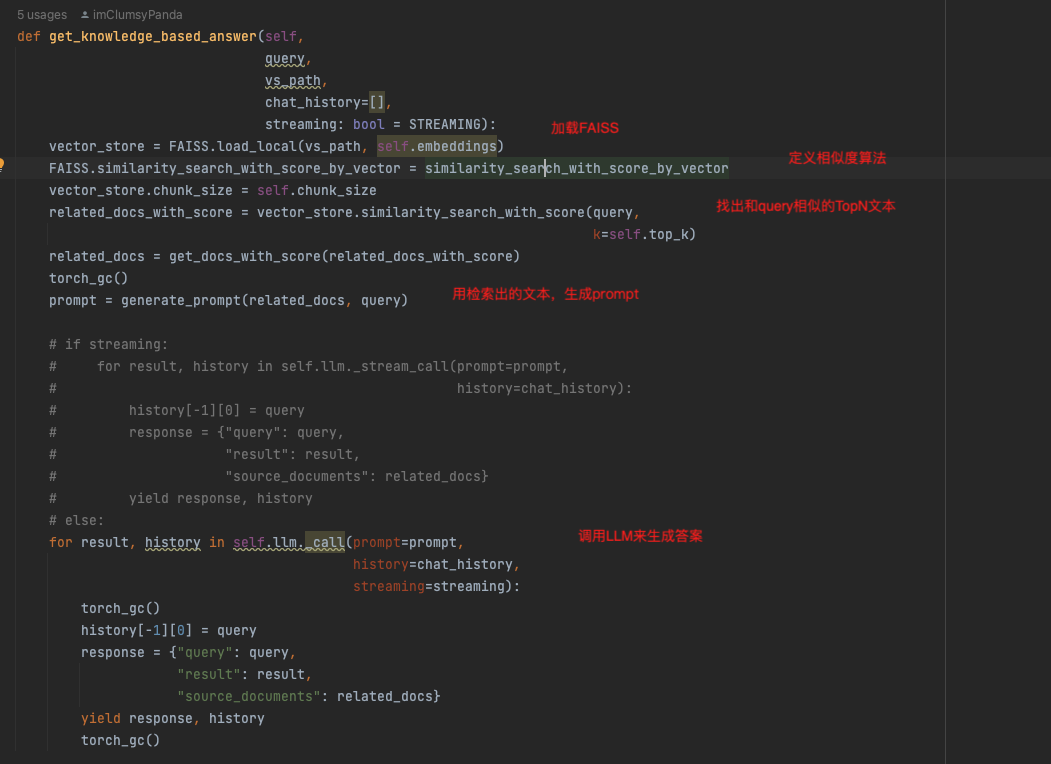
初始化向量库
用的是Faiss,传入embeddings模型
直接把本地知识库的文本加入就可

QA
步骤如下,
在生成prompt的时候,使用如下模板
{context}
根据上述已知信息,简洁和专业的来回答用户的问题。如果无法从中得到答案,请说 “根据已知信息无法回答该问题” 或 “没有提供足够的相关信息”,不允许在答案中添加编造成分,答案请使用中文。 问题是:{question}"""

 浙公网安备 33010602011771号
浙公网安备 33010602011771号