李宏毅BERT笔记
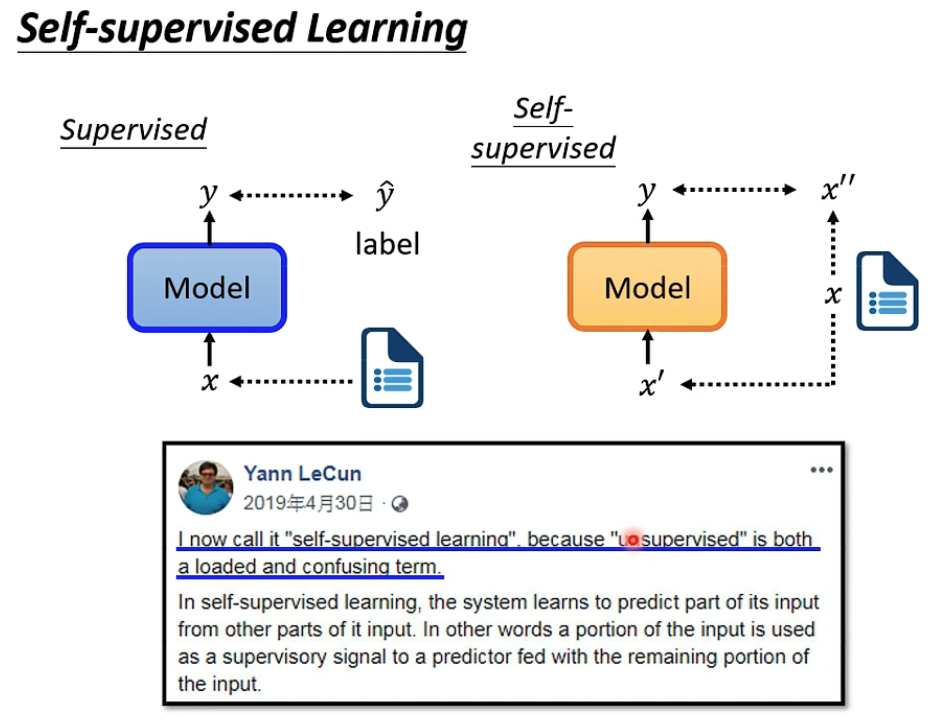
Self-supervised是LeCun提出的,将unsupervised learning的一部分称为Self-supervisor
常用于NLP,一段文字分成两部分,用第一部分来预测第二部分
自监督学习的模型名,大都来自芝麻街的角色

BERT有两种训练的方式,
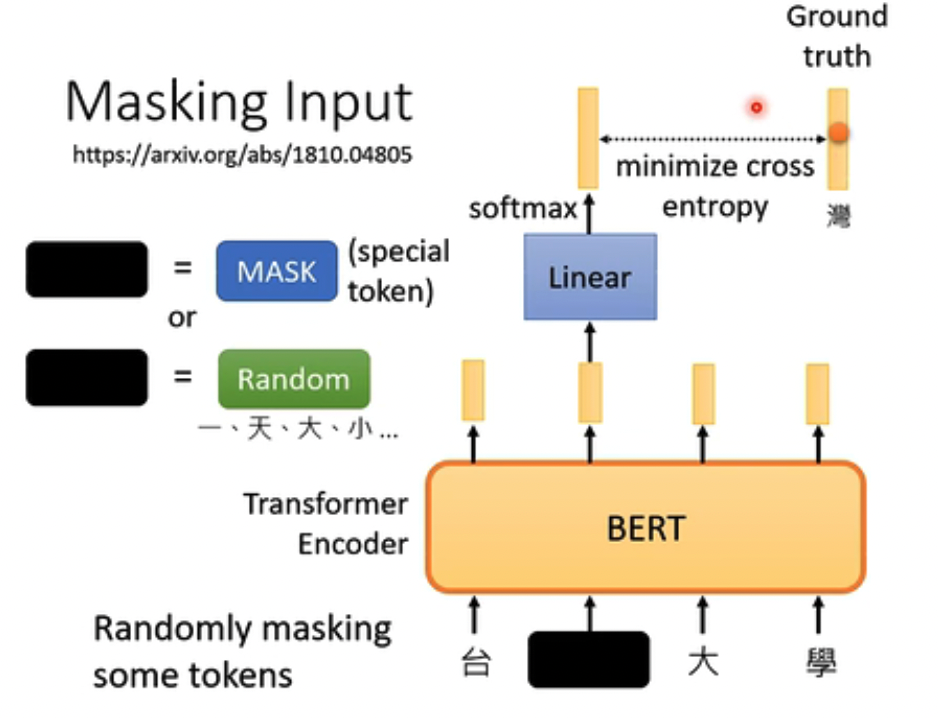
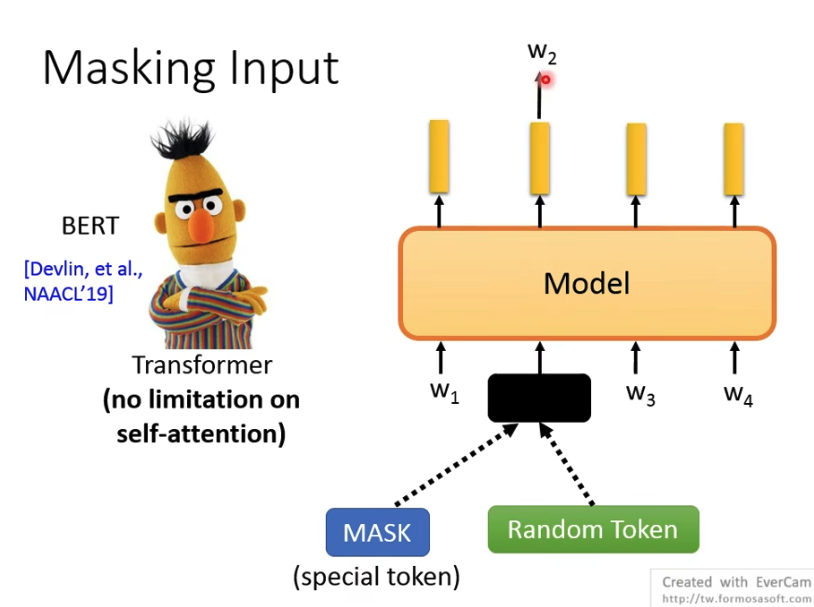
第一种是Masking Input,可以用特殊的MASK token或是Random token来替换原有的,经过BERT模型后,输出为原先的token
第二组是判断两段文字是否相接的,但是后来验证这种训练的方法不是很有效
所以BERT的主要的方式,是完形填空

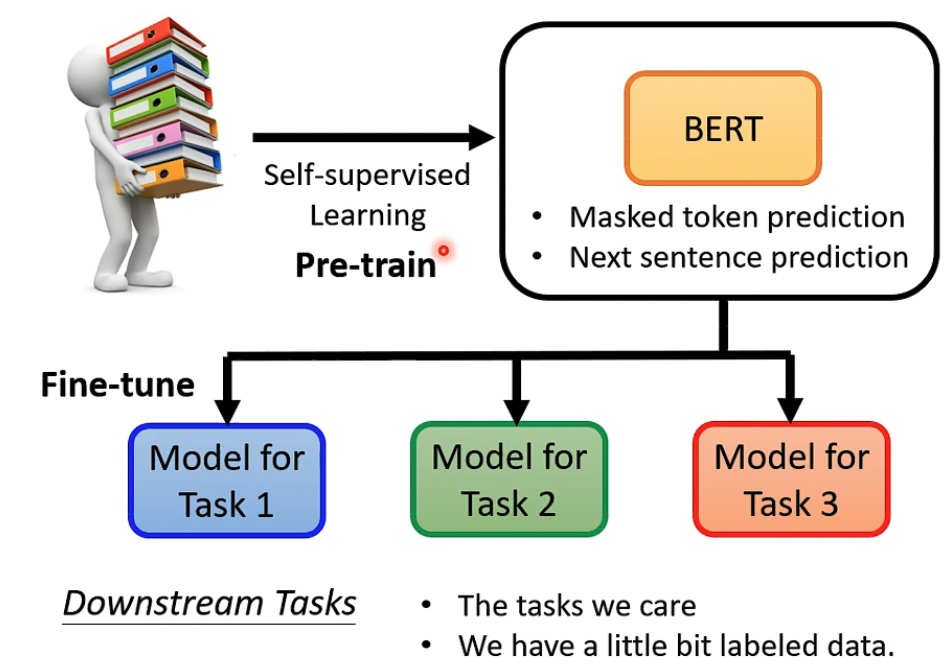
BERT的架构很像Transformer的Encoder,
所以Pre-train的model无法直接使用,需要加外挂,进行Fine-tune才能用于Downstream Tasks,注意BERT fine-tune的时候是要更新参数的
GPT模型,更像decoder,更适合于生成任务,但GPT使用中,使用的in-context learning是不会改变模型参数的
用于验证BERT这样模型的标准叫GLUE


看下如何Fine tune BERT来生成可使用的模型
BERT的Pre-train是self-supervised学习,但是fine-tune是supervised学习,需要大量的训练集的
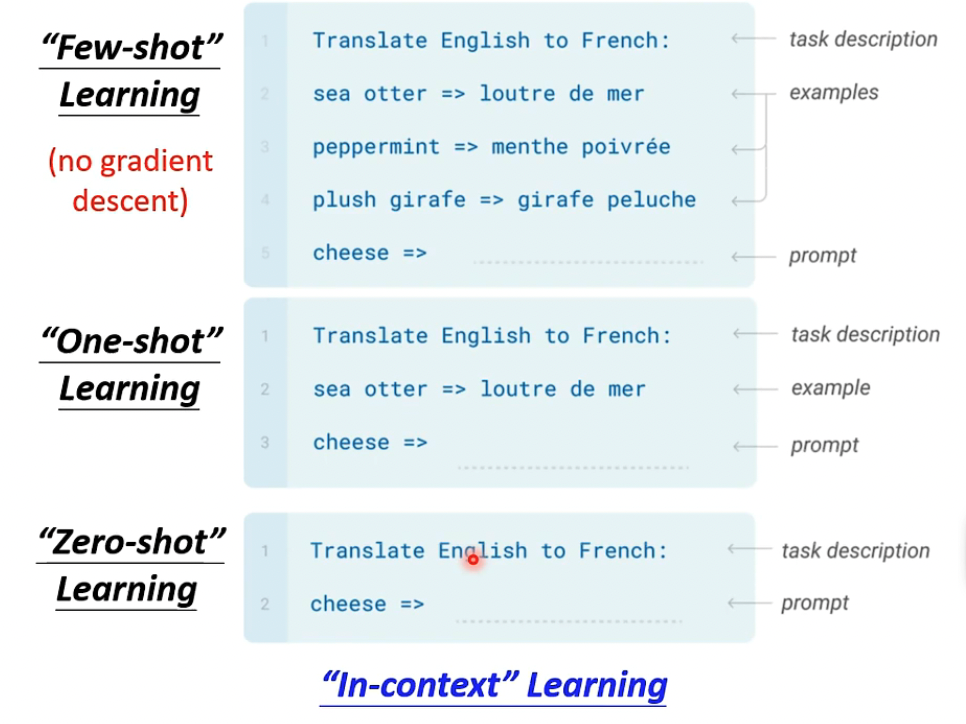
第一个例子是,情感分析
这里注意,BERT的参数是在Pre-train时init的,而Linear是随机init的
Fine-tune的时候,Linear和BERT的参数都是要进行调整的
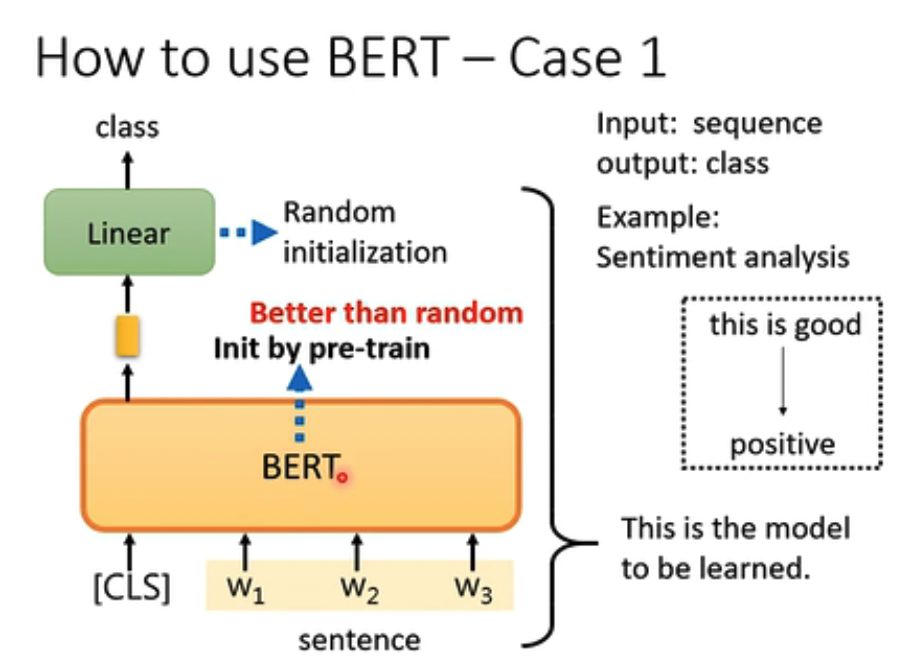
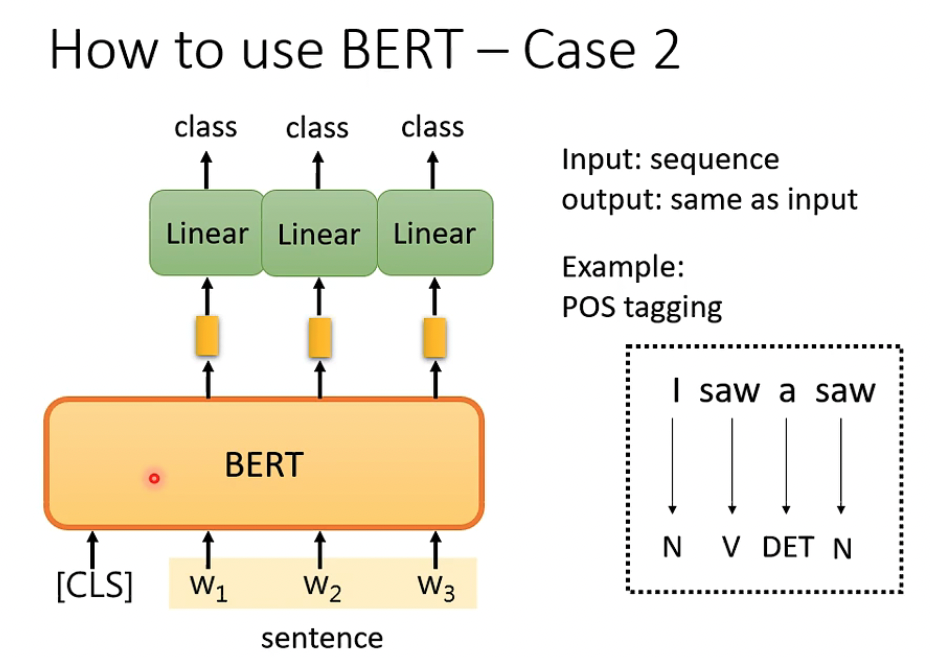
第二个例子比较简单,n to n
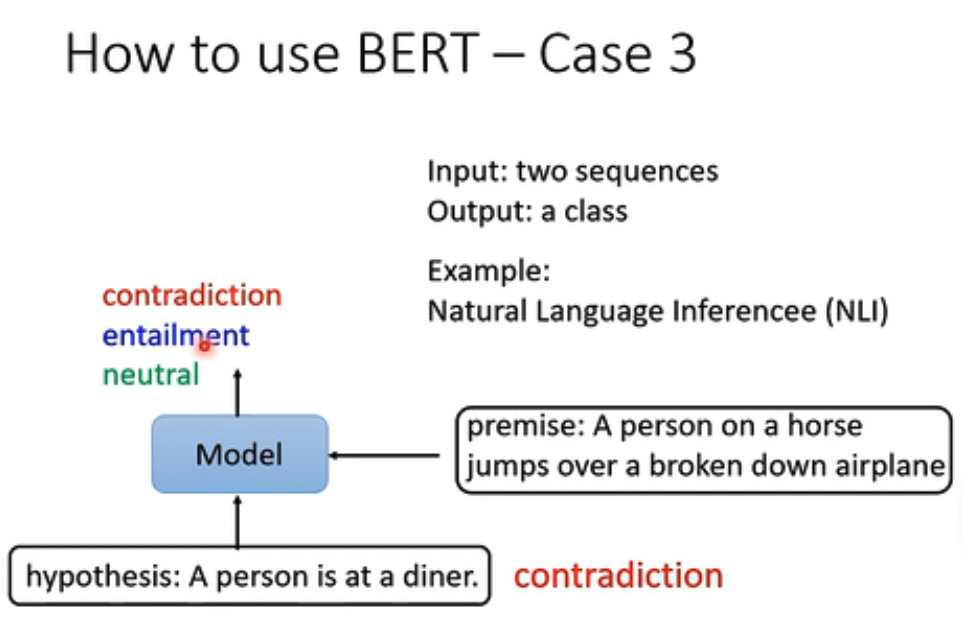
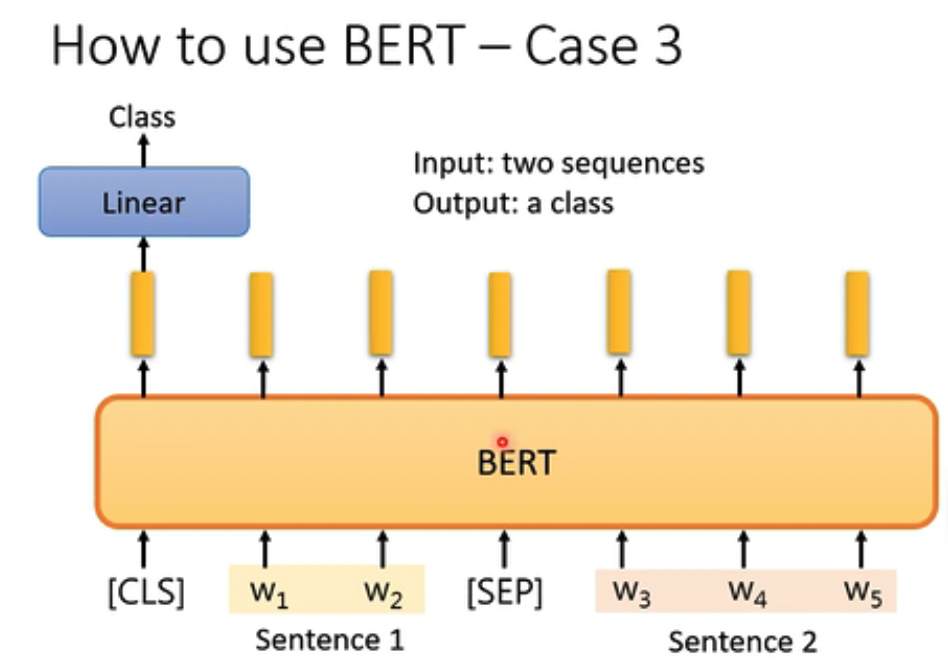
第三个例子,NLI,一个前提,一个假设,判断是否符合
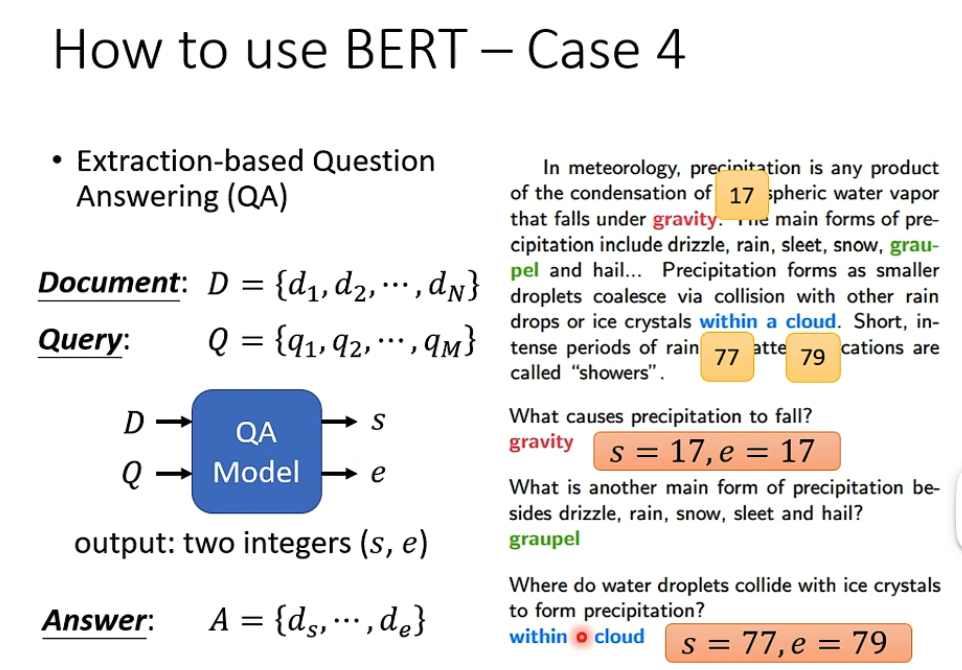
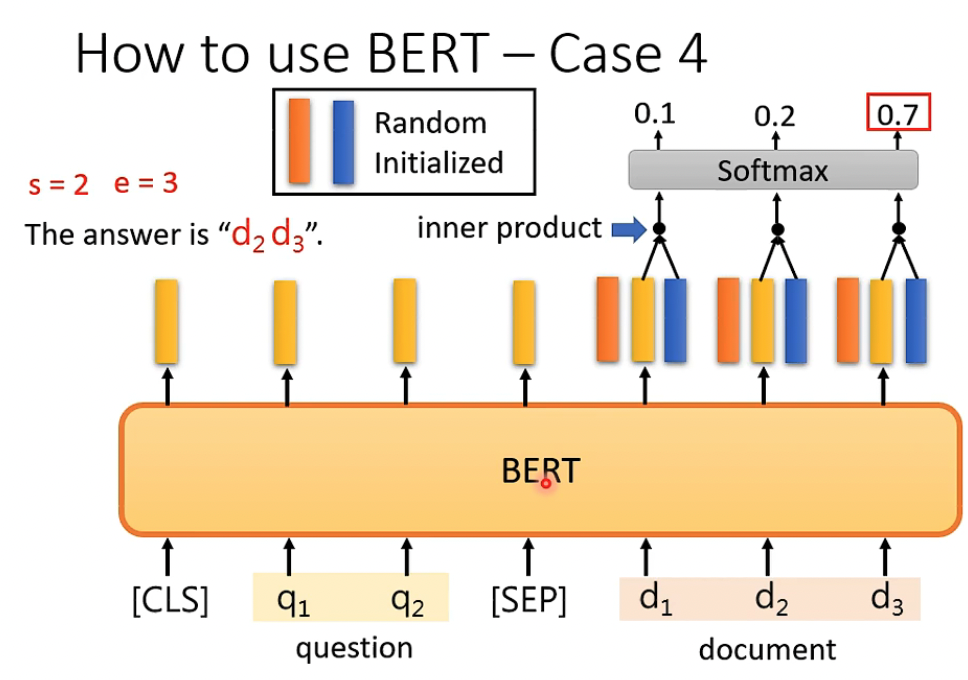
第四个例子比较复杂,QA
给出Document和Query,输出答案的index
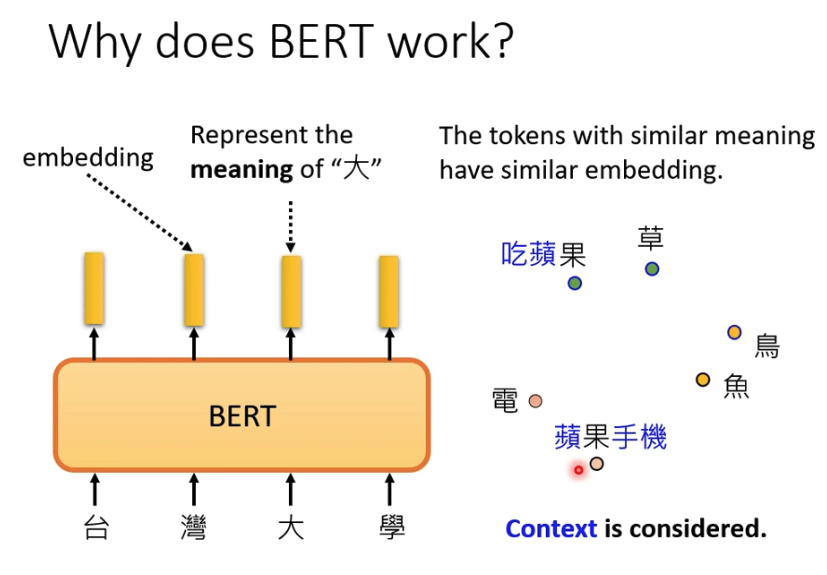
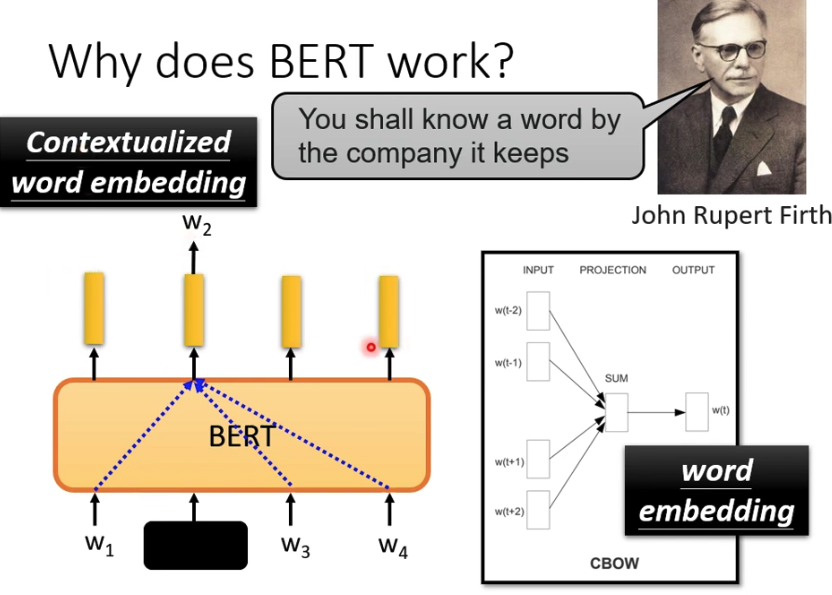
BERT为何会有效?
因为BERT是一种Encoder,所以BERT其实学习生成的是embedding,代表词出现的上下文
这里看到都是”果“,在不同的上下文语境下,产生的embedding是很不相同的
这就区别于传统的光看单个词的embedding
对于大模型成本比较高,自然有人研究是否可以做便宜些的小模型


继续聊下Pre-train和finetune
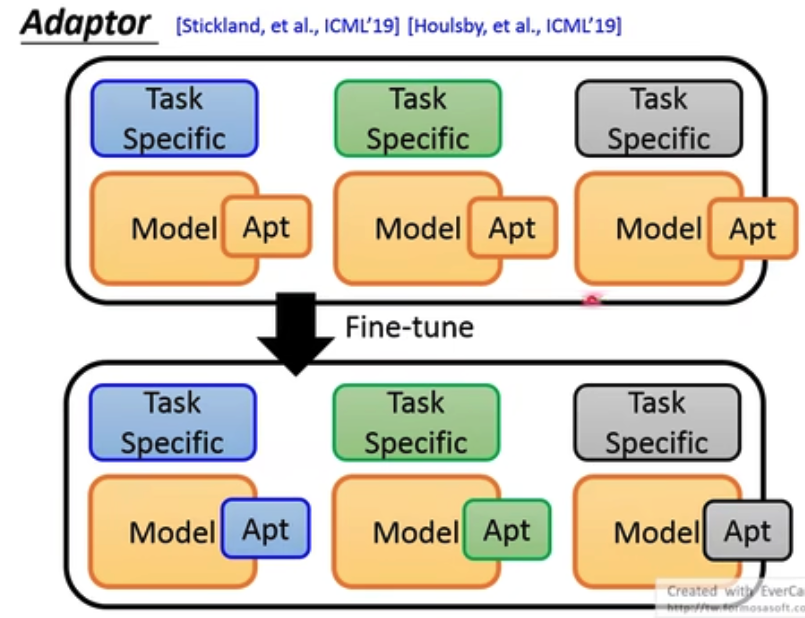
finetune有两种,只tune任务层,和整体一起tune
效果是一起tune更好些,但是这样要保存很多的tune后的大模型,所以产生了adaptor技术

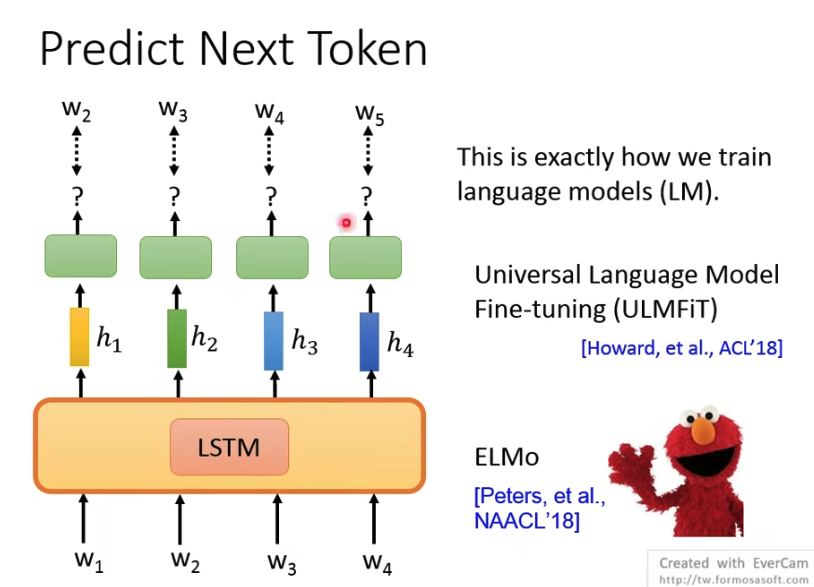
语言模型pre-train的方式,就是用前面的文字去predict后面的文字
在之前大家用的比较多的,是LSTM,很直觉,文字本身就是一段序列,典型的代表,就是ELMo,还是双向的LSTM
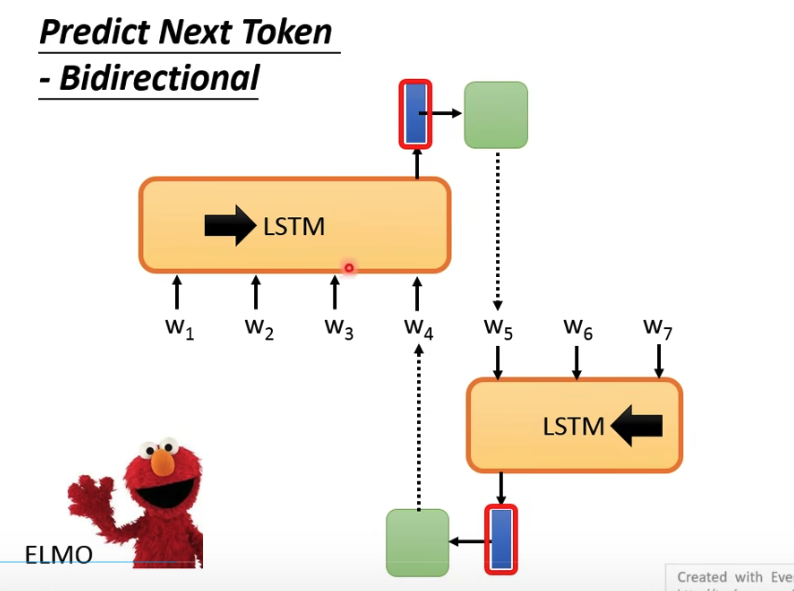
后来大家都用Self-Attention模型替换LSTM,
但是Self-Attention的问题是,一下可以看到所有的输入,这样对于模型学不到啥东西
所以在训练的时候需要加constraints来现在Attention,来让模型只能看到前面的输入
典型的代表,GPT
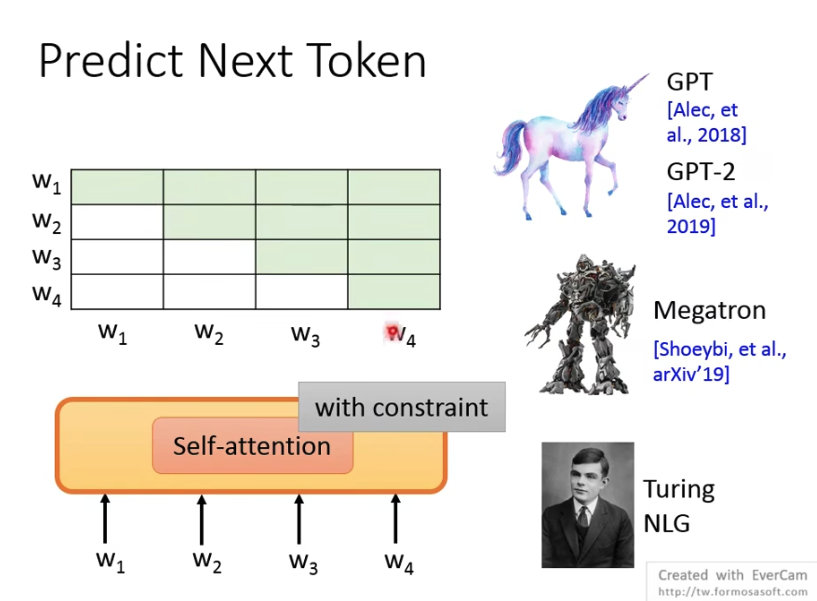
还有种思路就是BERT,
你虽然看到所有的输入,把部分mask掉来训练,
但是这个就没法直接用做语言模型,不是一种自回归的生成方式

 浙公网安备 33010602011771号
浙公网安备 33010602011771号