
Iceberg Table Spec
https://iceberg.apache.org/spec/#partition-transforms
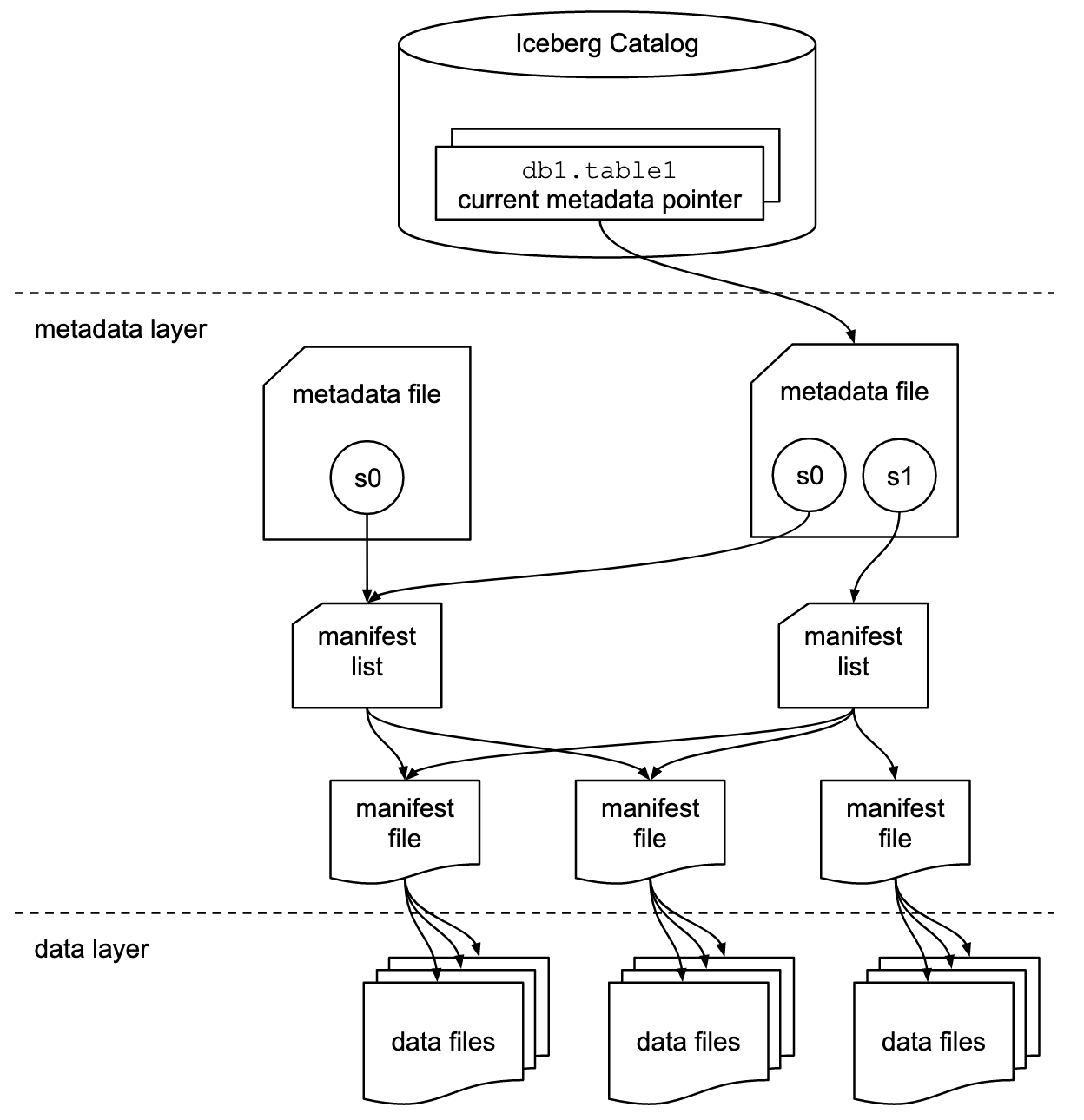
以文件形式而非目录形式,形成table format;传统的Hive和Hudi,都是以目录来区分Table partitions
This table format tracks individual data files in a table instead of directories.
This allows writers to create data files in-place and only adds files to the table in an explicit commit.
Table状态以metadata file维护,状态更新是通过,创建新的metadata file,最终进行一次指针的atomic swap来实现
metadata file中包含schema,分区配置,snapshots,其中snapshots,如图中s0,s1,代表某一时刻的table的内容
Table state is maintained in metadata files. All changes to table state create a new metadata file and replace the old metadata with an atomic swap.
The table metadata file tracks the table schema, partitioning config, custom properties, and snapshots of the table contents.
A snapshot represents the state of a table at some time and is used to access the complete set of data files in the table.
既然没有以目录来组织,肯定要以某种形式来组织文件。
manifest file,其实就是文件集合,用以组织文件,记录文件的分区信息和metrics;
灵活性,可以任意数据文件的子集,不一定要按分区来组织manifest。
复用性,manifest可以在不同的snapshot中复用,如图中所示。
Data files in snapshots are tracked by one or more manifest files that contain a row for each data file in the table, the file’s partition data, and its metrics.
The data in a snapshot is the union of all files in its manifests.
Manifest files are reused across snapshots to avoid rewriting metadata that is slow-changing.
Manifests can track data files with any subset of a table and are not associated with partitions.
manifest list,就是文件的二层组织,代表一个snapshot
一个manifest list,包含一组manifest
The manifests that make up a snapshot are stored in a manifest list file.
Each manifest list stores metadata about manifests, including partition stats and data file counts.
These stats are used to avoid reading manifests that are not required for an operation.
Partitioning
一个record属于哪个partition,由该record产生的partition values决定;
一个datafile中的数据都是属于同一个partition的;
但是一个manifest,包含的datafile可以来自不同的partitions。
Data files are stored in manifests with a tuple of partition values that are used in scans to filter out files that cannot contain records that match the scan’s filter predicate.
Partition values for a data file must be the same for all records stored in the data file. (Manifests store data files from any partition, as long as the partition spec is the same for the data files.)
partition spec定义了如何产生partition values
其中关键的就是transform,这里支持的,有bucket-hash方式,truncate方式等

partition可以evolve,partition是由partition spec决定的,生成新的spec,或设成默认,就会改变partition
Table partitioning can be evolved by adding, removing, renaming, or reordering partition spec fields.
Changing a partition spec produces a new spec identified by a unique spec ID that is added to the table’s list of partition specs and may be set as the table’s default spec.
When evolving a spec, changes should not cause partition field IDs to change because the partition field IDs are used as the partition tuple field IDs in manifest files.
Manifests
详细看下Manifest,
首先,Manifest是个不可变更的Avro文件,用于记录data files或者delete files;并且Manifest是个valid的Iceberg的data files
其次,Manifest同时只能存data files或者delete files其中一种,因为查询的时候需要先扫描delete的Manifest;到底存储哪一种是记录在manifest metadata中的
最后,Manifest对应单个partition spec,虽然Manifest下面的文件可以属于不同的partition;
所以如果spec变了,那么就需要写入新的manifest。
A manifest is an immutable Avro file that lists data files or delete files, along with each file’s partition data tuple, metrics, and tracking information.
A manifest is a valid Iceberg data file: files must use valid Iceberg formats, schemas, and column projection.
A manifest may store either data files or delete files, but not both because manifests that contain delete files are scanned first during job planning. Whether a manifest is a data manifest or a delete manifest is stored in manifest metadata.
A manifest stores files for a single partition spec. When a table’s partition spec changes, old files remain in the older manifest and newer files are written to a new manifest.
This is required because a manifest file’s schema is based on its partition spec (see below).
The partition spec of each manifest is also used to transform predicates on the table’s data rows into predicates on partition values that are used during job planning to select files from a manifest.
Manifest Metadata结构,Avro meta
主要是schema和partition spec;
format version表明是1.0还是2.0的iceburg,content表明data file还是delete file
A manifest file must store the partition spec and other metadata as properties in the Avro file’s key-value metadata:

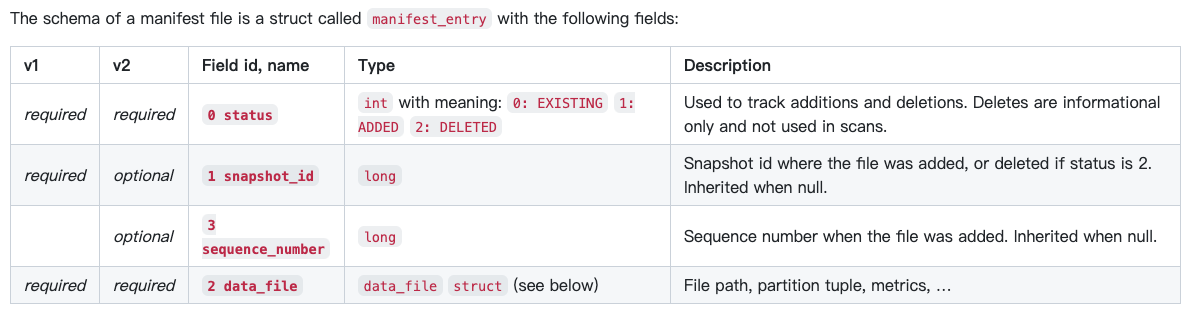
Manifest表schema,一行代表一个file,称为manifest entry
Status表示状态,added或deleted
snapshot_id, 表示对于在哪个snapshot完成的add或delete,对应于status
可以看到在V2中,snapshot_id是可选的,因为多了sequence_number,
seq_num,两种情况是null
一种,当file刚被add时,因为seq_num只有在snapshot被完全committed的时候才会被设置
另一种,继承manifest list中的seq_num的值
Manifests track the sequence number when a data or delete file was added to the table.
When adding new file, its sequence number is set to null because the snapshot’s sequence number is not assigned until the snapshot is successfully committed.
When reading, sequence numbers are inherited by replacing null with the manifest’s sequence number from the manifest list.
When writing an existing file to a new manifest, the sequence number must be non-null and set to the sequence number that was inherited.
Inheriting sequence numbers through the metadata tree allows writing a new manifest without a known sequence number, so that a manifest can be written once and reused in commit retries.
To change a sequence number for a retry, only the manifest list must be rewritten.
When reading v1 manifests with no sequence number column, sequence numbers for all files must default to 0.
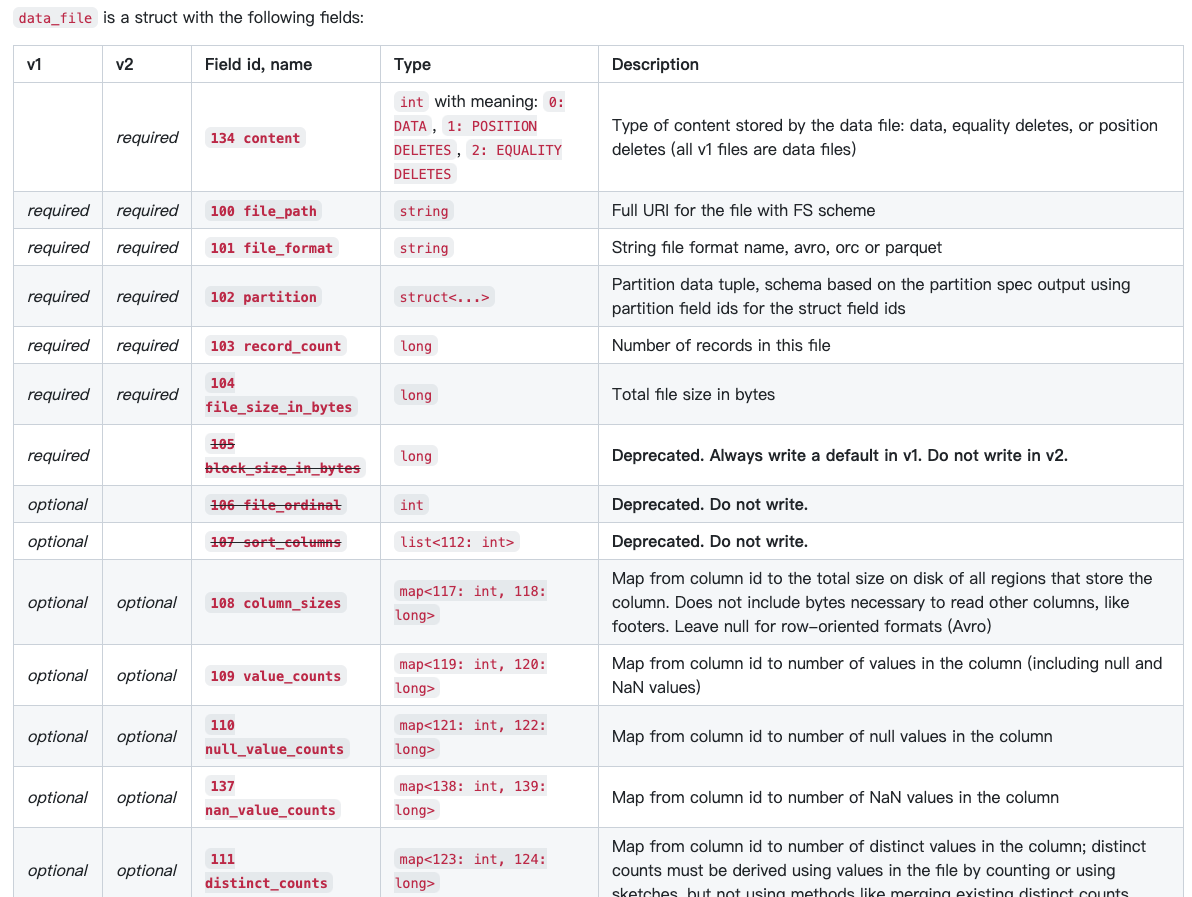
manifest entry中并没有文件的信息,因为都放在data_file中,
content,什么类型的文件,data还是delete
partition,一个文件属于一个partition,partition value
剩下后面都是和file相关的,统计信息
Snapshots
sequence-number,V2增加用于表示change的顺序的,之前的snapshot-id不是递增的,所以无法表示顺序
summary中,会包含operation,可以用于知道这个snapshot包含合作操作,用于skip
最关键的是,manifest-list,指向manifest-list file

Manifest Lists
manifest list文件是一个正常的Iceberg data file
manifest list文件,每次当commit snapshot的时候会被产生,因为commit之前内容随时都会变。
manifest list文件生成后,这个snapshot的sequence number被写入所有新的manifest 文件
manifest list文件,每一行代表一个manifest文件,包含各种summary meta,可以用于dataskip
Snapshots are embedded in table metadata, but the list of manifests for a snapshot are stored in a separate manifest list file.
A new manifest list is written for each attempt to commit a snapshot because the list of manifests always changes to produce a new snapshot.
When a manifest list is written, the (optimistic) sequence number of the snapshot is written for all new manifest files tracked by the list.
A manifest list includes summary metadata that can be used to avoid scanning all of the manifests in a snapshot when planning a table scan.
This includes the number of added, existing, and deleted files, and a summary of values for each field of the partition spec used to write the manifest.
A manifest list is a valid Iceberg data file: files must use valid Iceberg formats, schemas, and column projection.
manifest_file,包含path,length,manifest对应的partition spec,以及各种统计。
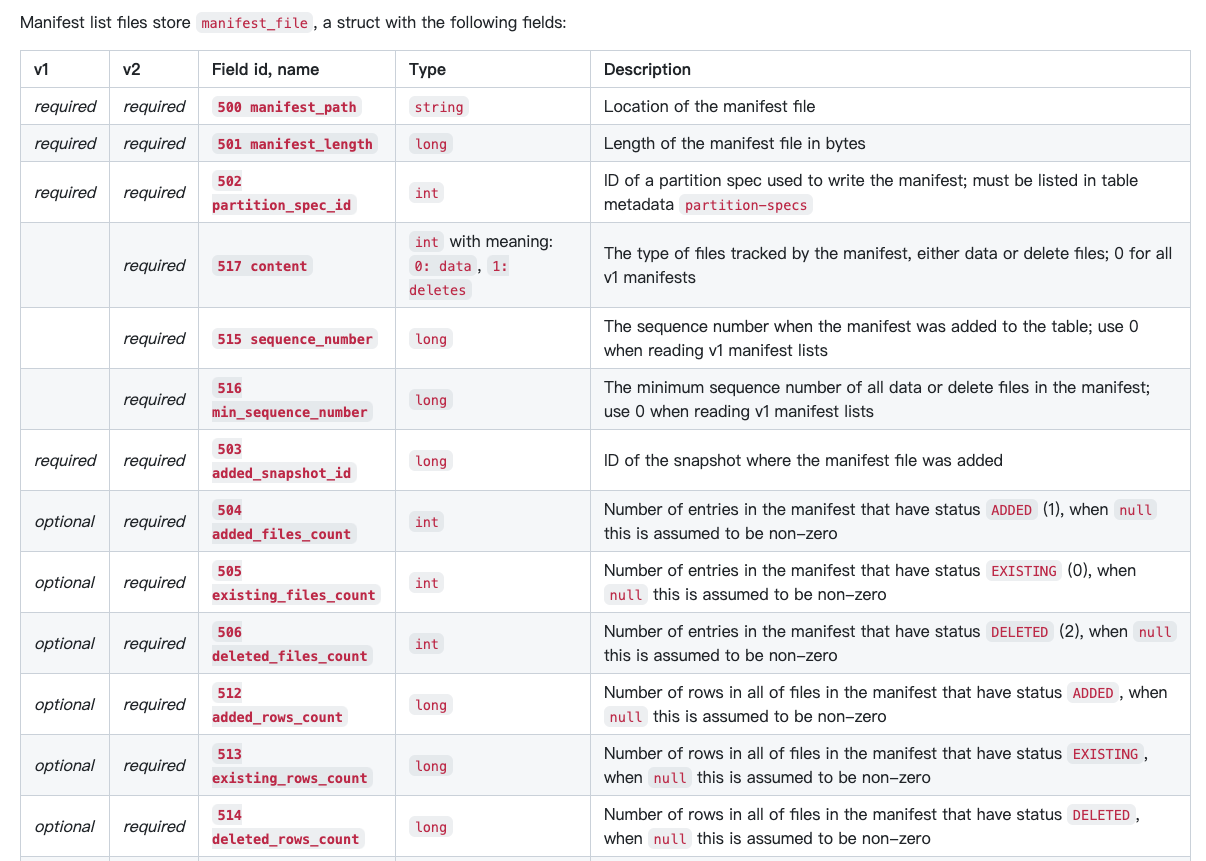
Table Metadata
首先,Table metadata是JSON,不是iceberg文件了。
再者,每次更新是产生一个新的metadata文件,通过原子操作进行commit,切换。
Table metadata is stored as JSON.
Each table metadata change creates a new table metadata file that is committed by an atomic operation.
This operation is used to ensure that a new version of table metadata replaces the version on which it was based.
This produces a linear history of table versions and ensures that concurrent writes are not lost.


 浙公网安备 33010602011771号
浙公网安备 33010602011771号