
Apache Hudi 源码分析 - HoodieTableSink
可以看出,分为几种,
bulk_insert
append
default, upsert
compact,clean
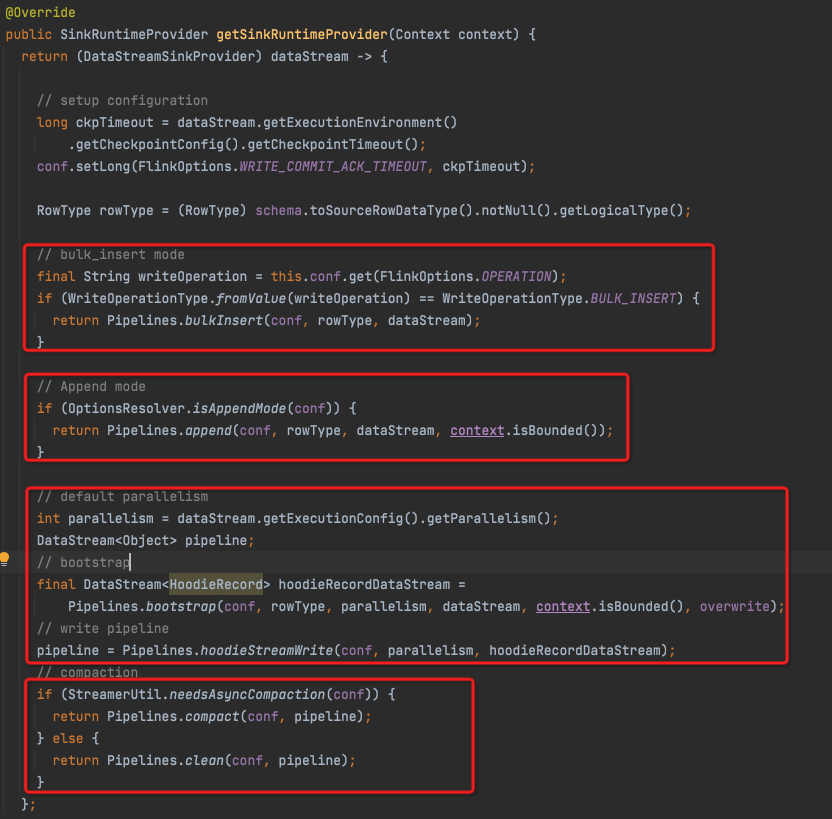
Pipelines这部分,注释写的非常不错
bulk_insert
先按照partition path进行shuffle分区,然后再按照partition path进行排序,一个partition path的record都聚合在一起
这样再按照每个partition path去写文件,有效降低了小文件
/** * Bulk insert the input dataset at once. * * <p>By default, the input dataset would shuffle by the partition path first then * sort by the partition path before passing around to the write function. * The whole pipeline looks like the following: * * <pre> * | input1 | ===\ /=== |sorter| === | task1 | (p1, p2) * shuffle * | input2 | ===/ \=== |sorter| === | task2 | (p3, p4) * * Note: Both input1 and input2's dataset come from partitions: p1, p2, p3, p4 * </pre> * * <p>The write task switches to new file handle each time it receives a record * from the different partition path, the shuffle and sort would reduce small files. * * <p>The bulk insert should be run in batch execution mode. * * @param conf The configuration * @param rowType The input row type * @param dataStream The input data stream * @return the bulk insert data stream sink */
可以看到代码逻辑上也是分成3块,
final String[] partitionFields = FilePathUtils.extractPartitionKeys(conf); if (partitionFields.length > 0) { RowDataKeyGen rowDataKeyGen = RowDataKeyGen.instance(conf, rowType); if (conf.getBoolean(FlinkOptions.WRITE_BULK_INSERT_SHUFFLE_INPUT)) { // shuffle by partition keys,分区 // use #partitionCustom instead of #keyBy to avoid duplicate sort operations, // see BatchExecutionUtils#applyBatchExecutionSettings for details. Partitioner<String> partitioner = (key, channels) -> KeyGroupRangeAssignment.assignKeyToParallelOperator(key, StreamGraphGenerator.DEFAULT_LOWER_BOUND_MAX_PARALLELISM, channels); dataStream = dataStream.partitionCustom(partitioner, rowDataKeyGen::getPartitionPath); } if (conf.getBoolean(FlinkOptions.WRITE_BULK_INSERT_SORT_INPUT)) { SortOperatorGen sortOperatorGen = new SortOperatorGen(rowType, partitionFields); // sort by partition keys,排序 dataStream = dataStream .transform("partition_key_sorter", TypeInformation.of(RowData.class), sortOperatorGen.createSortOperator()) .setParallelism(conf.getInteger(FlinkOptions.WRITE_TASKS)); ExecNodeUtil.setManagedMemoryWeight(dataStream.getTransformation(), conf.getInteger(FlinkOptions.WRITE_SORT_MEMORY) * 1024L * 1024L); } } return dataStream .transform("hoodie_bulk_insert_write", TypeInformation.of(Object.class), operatorFactory) //写入operator // follow the parallelism of upstream operators to avoid shuffle .setParallelism(conf.getInteger(FlinkOptions.WRITE_TASKS)) .addSink(DummySink.INSTANCE) //最后加上DummySink .name("dummy");
这里operatorFactory最终生成的是
BulkInsertWriteFunction
@Override public void processElement(I value, Context ctx, Collector<Object> out) throws IOException { this.writerHelper.write((RowData) value); }
BucketBulkInsertWriterHelper
如果record是连续的,可以直接重用lastFileId对应的file handle,比较高效,所以前面需要排序
public void write(RowData tuple) throws IOException { try { RowData record = tuple.getRow(1, this.recordArity); String recordKey = keyGen.getRecordKey(record); String partitionPath = keyGen.getPartitionPath(record); String fileId = tuple.getString(0).toString(); if ((lastFileId == null) || !lastFileId.equals(fileId)) { LOG.info("Creating new file for partition path " + partitionPath); handle = getRowCreateHandle(partitionPath, fileId); lastFileId = fileId; } handle.write(recordKey, partitionPath, record); //单行写入parquet文件 } catch (Throwable throwable) { LOG.error("Global error thrown while trying to write records in HoodieRowDataCreateHandle", throwable); throw throwable; } }
否则需要调用,getRowCreateHandle
private HoodieRowDataCreateHandle getRowCreateHandle(String partitionPath) throws IOException { if (!handles.containsKey(partitionPath)) { // handles里面没有现成的 // if records are sorted, we can close all existing handles if (isInputSorted) { // close(); //如果Sorted,没有必要cache之前的handle,所以可以close掉 } HoodieRowDataCreateHandle rowCreateHandle = new HoodieRowDataCreateHandle(hoodieTable, writeConfig, partitionPath, getNextFileId(), instantTime, taskPartitionId, taskId, taskEpochId, rowType); handles.put(partitionPath, rowCreateHandle); //创建一个新的加入到handles里面 } else if (!handles.get(partitionPath).canWrite()) { //虽然已经有handle,但是已经写满 // even if there is a handle to the partition path, it could have reached its max size threshold. So, we close the handle here and // create a new one. writeStatusList.add(handles.remove(partitionPath).close()); //所以把当前的handle关掉,并放入writeStatus中 HoodieRowDataCreateHandle rowCreateHandle = new HoodieRowDataCreateHandle(hoodieTable, writeConfig, partitionPath, getNextFileId(), instantTime, taskPartitionId, taskId, taskEpochId, rowType); handles.put(partitionPath, rowCreateHandle); //创建新的handle加入 } return handles.get(partitionPath); //从handles取到handle }
可以看到这里写文件也是单条写入的,
之所以叫BulkInsert,
因为BulkInsertWriteOperator实现BoundedOneInput
public class BulkInsertWriteOperator<I> extends AbstractWriteOperator<I> implements BoundedOneInput {
BoundedOneInput中主要是endInput函数,
/** * End input action for batch source. */ public void endInput() { final List<WriteStatus> writeStatus = this.writerHelper.getWriteStatuses(this.taskID); final WriteMetadataEvent event = WriteMetadataEvent.builder() .taskID(taskID) .instantTime(this.writerHelper.getInstantTime()) .writeStatus(writeStatus) .lastBatch(true) .endInput(true) .build(); this.eventGateway.sendEventToCoordinator(event); }
可以看到,这里会给coordinator发生event来更新meta
所以是bulkinsert,因为当所有数据写完后,需要手动调用一次endInput来更新元数据
append
不考虑update和去重
所以流程很简单直接写
这里画了shuffle,但是没有特意去partition,如果并行度相同应该没有shuffle的过程
这种方式会产生大量的小文件,没有按partition分区,也没有排序
主要是没有分区,没有排序不会有太大的影响文件数目,因为只有在snapshot的时候才会产生新文件
/** * Insert the dataset with append mode(no upsert or deduplication). * * <p>The input dataset would be rebalanced among the write tasks: * * <pre> * | input1 | ===\ /=== | task1 | (p1, p2, p3, p4) * shuffle * | input2 | ===/ \=== | task2 | (p1, p2, p3, p4) * * Note: Both input1 and input2's dataset come from partitions: p1, p2, p3, p4 * </pre> * * <p>The write task switches to new file handle each time it receives a record * from the different partition path, so there may be many small files. * * @param conf The configuration * @param rowType The input row type * @param dataStream The input data stream * @param bounded Whether the input stream is bounded * @return the appending data stream sink */
public static DataStreamSink<Object> append( Configuration conf, RowType rowType, DataStream<RowData> dataStream, boolean bounded) { WriteOperatorFactory<RowData> operatorFactory = AppendWriteOperator.getFactory(conf, rowType); // return dataStream .transform("hoodie_append_write", TypeInformation.of(Object.class), operatorFactory) //直接Append Operator写入 .uid("uid_hoodie_stream_write" + conf.getString(FlinkOptions.TABLE_NAME)) .setParallelism(conf.getInteger(FlinkOptions.WRITE_TASKS)) .addSink(DummySink.INSTANCE) .name("dummy"); }
AppendWriteFunction
首先对于processElement的逻辑和BulkInsert一样,没有区别
不一样的,Append除了支持batch,即boundedOneInput接口,在endInput中flushData
也支持streaming的情况,在snapshotState中,flushData
@Override public void snapshotState() { // Based on the fact that the coordinator starts the checkpoint first, // it would check the validity. // wait for the buffer data flush out and request a new instant flushData(false); } @Override public void processElement(I value, Context ctx, Collector<Object> out) throws Exception { if (this.writerHelper == null) { initWriterHelper(); } this.writerHelper.write((RowData) value); } /** * End input action for batch source. */ public void endInput() { flushData(true); this.writeStatuses.clear(); }
这个flush的逻辑和BulkInsert中的基本一致
private void flushData(boolean endInput) { final List<WriteStatus> writeStatus; final String instant; if (this.writerHelper != null) { // writeStatus = this.writerHelper.getWriteStatuses(this.taskID); // instant = this.writerHelper.getInstantTime(); // } else { writeStatus = Collections.emptyList(); instant = instantToWrite(false); LOG.info("No data to write in subtask [{}] for instant [{}]", taskID, instant); } final WriteMetadataEvent event = WriteMetadataEvent.builder() .taskID(taskID) .instantTime(instant) .writeStatus(writeStatus) .lastBatch(true) .endInput(endInput) .build(); // this.eventGateway.sendEventToCoordinator(event); // // nullify the write helper for next ckp this.writerHelper = null; this.writeStatuses.addAll(writeStatus); // blocks flushing until the coordinator starts a new instant this.confirming = true; }
需要注意的是,在getWriteStatuses的时候,会close file handle
所以一次snapshot会产生一批新的文件
public List<HoodieInternalWriteStatus> getHoodieWriteStatuses() throws IOException { close(); return writeStatusList; }
这里BulkInsert和Append两种模式的设计不太清晰,大部分逻辑雷同
BulkInsert,有按partitionPath分区和排序,但是只支持batch
Append,直接写,但是支持streaming和batch
为啥不能合成一个?
bootstrap
有两种,boundedBootstrap和streamBootstrap
/** * Constructs bootstrap pipeline. * The bootstrap operator loads the existing data index (primary key to file id mapping), * then send the indexing data set to subsequent operator(usually the bucket assign operator). * * @param conf The configuration * @param rowType The row type * @param defaultParallelism The default parallelism * @param dataStream The data stream * @param bounded Whether the source is bounded * @param overwrite Whether it is insert overwrite */ public static DataStream<HoodieRecord> bootstrap( Configuration conf, RowType rowType, int defaultParallelism, DataStream<RowData> dataStream, boolean bounded, boolean overwrite) { final boolean globalIndex = conf.getBoolean(FlinkOptions.INDEX_GLOBAL_ENABLED); if (overwrite || OptionsResolver.isBucketIndexType(conf)) { return rowDataToHoodieRecord(conf, rowType, dataStream); //只是转换成HoodieRecord } else if (bounded && !globalIndex && OptionsResolver.isPartitionedTable(conf)) { return boundedBootstrap(conf, rowType, defaultParallelism, dataStream); // } else { return streamBootstrap(conf, rowType, defaultParallelism, dataStream, bounded); // } }
streamBootstrap
private static DataStream<HoodieRecord> streamBootstrap( Configuration conf, RowType rowType, int defaultParallelism, DataStream<RowData> dataStream, boolean bounded) { DataStream<HoodieRecord> dataStream1 = rowDataToHoodieRecord(conf, rowType, dataStream); //转化成HoodieRecord if (conf.getBoolean(FlinkOptions.INDEX_BOOTSTRAP_ENABLED) || bounded) { dataStream1 = dataStream1 .transform( "index_bootstrap", TypeInformation.of(HoodieRecord.class), new BootstrapOperator<>(conf)) //使用BootstrapOperator .setParallelism(conf.getOptional(FlinkOptions.INDEX_BOOTSTRAP_TASKS).orElse(defaultParallelism)) .uid("uid_index_bootstrap_" + conf.getString(FlinkOptions.TABLE_NAME)); } return dataStream1; }
BootstrapOperator
主要逻辑在initializeState里面,processElement只是forword record
state中,要保存lastPendingInstant,最新的没有完成的instant
主要的逻辑是preLoadIndexRecords
@Override public void snapshotState(StateSnapshotContext context) throws Exception { lastInstantTime = this.ckpMetadata.lastPendingInstant(); // instantState.update(Collections.singletonList(lastInstantTime)); } @Override public void initializeState(StateInitializationContext context) throws Exception { ListStateDescriptor<String> instantStateDescriptor = new ListStateDescriptor<>( "instantStateDescriptor", Types.STRING ); instantState = context.getOperatorStateStore().getListState(instantStateDescriptor); if (context.isRestored()) { Iterator<String> instantIterator = instantState.get().iterator(); // if (instantIterator.hasNext()) { lastInstantTime = instantIterator.next(); // } } this.hadoopConf = StreamerUtil.getHadoopConf(); this.writeConfig = StreamerUtil.getHoodieClientConfig(this.conf, true); this.hoodieTable = FlinkTables.createTable(writeConfig, hadoopConf, getRuntimeContext()); this.ckpMetadata = CkpMetadata.getInstance(hoodieTable.getMetaClient().getFs(), this.writeConfig.getBasePath()); this.aggregateManager = getRuntimeContext().getGlobalAggregateManager(); preLoadIndexRecords(); // } @Override @SuppressWarnings("unchecked") public void processElement(StreamRecord<I> element) throws Exception { output.collect((StreamRecord<O>) element); }
preLoadIndexRecords
对于这个table下的所有partition,满足Pattern,即需要加载index的,调用loadRecords
然后等待所有并发的task都完成loadrecords,这步不完成init就不结束,job不会正式开始
/** * Load the index records before {@link #processElement}. */ protected void preLoadIndexRecords() throws Exception { String basePath = hoodieTable.getMetaClient().getBasePath(); int taskID = getRuntimeContext().getIndexOfThisSubtask(); LOG.info("Start loading records in table {} into the index state, taskId = {}", basePath, taskID); for (String partitionPath : FSUtils.getAllFoldersWithPartitionMetaFile(FSUtils.getFs(basePath, hadoopConf), basePath)) { if (pattern.matcher(partitionPath).matches()) { loadRecords(partitionPath); } }// wait for the other bootstrap tasks finish bootstrapping. waitForBootstrapReady(getRuntimeContext().getIndexOfThisSubtask()); } /** * Wait for other bootstrap tasks to finish the index bootstrap. */ private void waitForBootstrapReady(int taskID) { int taskNum = getRuntimeContext().getNumberOfParallelSubtasks(); int readyTaskNum = 1; while (taskNum != readyTaskNum) { try { readyTaskNum = aggregateManager.updateGlobalAggregate(BootstrapAggFunction.NAME, taskID, new BootstrapAggFunction()); LOG.info("Waiting for other bootstrap tasks to complete, taskId = {}.", taskID); TimeUnit.SECONDS.sleep(5); } catch (Exception e) { LOG.warn("Update global task bootstrap summary error", e); } } }
loadRecords
protected void loadRecords(String partitionPath) throws Exception { HoodieTimeline commitsTimeline = this.hoodieTable.getMetaClient().getCommitsTimeline(); // if (!StringUtils.isNullOrEmpty(lastInstantTime)) { commitsTimeline = commitsTimeline.findInstantsAfter(lastInstantTime); //lastInstantTime是state保存,读取after的timeline } Option<HoodieInstant> latestCommitTime = commitsTimeline.filterCompletedInstants().lastInstant(); //找出timeline中完成instant中最新的一个 if (latestCommitTime.isPresent()) { BaseFileUtils fileUtils = BaseFileUtils.getInstance(this.hoodieTable.getBaseFileFormat()); Schema schema = new TableSchemaResolver(this.hoodieTable.getMetaClient()).getTableAvroSchema(); List<FileSlice> fileSlices = this.hoodieTable.getSliceView() .getLatestFileSlicesBeforeOrOn(partitionPath, latestCommitTime.get().getTimestamp(), true) .collect(toList()); //Before,因为后面都是没有commit的,所以读前面的,读出所有的fileSlices for (FileSlice fileSlice : fileSlices) { // if (!shouldLoadFile(fileSlice.getFileId(), maxParallelism, parallelism, taskID)) { continue; } LOG.info("Load records from {}.", fileSlice); // load parquet records fileSlice.getBaseFile().ifPresent(baseFile -> { //先读BaseFile,parquet格式 // filter out crushed files if (!isValidFile(baseFile.getFileStatus())) { return; } try (ClosableIterator<HoodieKey> iterator = fileUtils.getHoodieKeyIterator(this.hadoopConf, new Path(baseFile.getPath()))) { iterator.forEachRemaining(hoodieKey -> { output.collect(new StreamRecord(new IndexRecord(generateHoodieRecord(hoodieKey, fileSlice)))); }); //最终输出indexRecord,hoodiekey和fileSlice的匹配,这里会输出这个fileslice中所有的recordKey } }); // load avro log records List<String> logPaths = fileSlice.getLogFiles() //后读logfile // filter out crushed files .filter(logFile -> isValidFile(logFile.getFileStatus())) .map(logFile -> logFile.getPath().toString()) .collect(toList()); HoodieMergedLogRecordScanner scanner = FormatUtils.logScanner(logPaths, schema, latestCommitTime.get().getTimestamp(), writeConfig, hadoopConf); //生成对logfile的scanner try { //输出和上面一样,也是indexRecord for (String recordKey : scanner.getRecords().keySet()) { output.collect(new StreamRecord(new IndexRecord(generateHoodieRecord(new HoodieKey(recordKey, partitionPath), fileSlice)))); } } catch (Exception e) { throw new HoodieException(String.format("Error when loading record keys from files: %s", logPaths), e); } finally { scanner.close(); } } }
boundedBootstrap
/** * Constructs bootstrap pipeline for batch execution mode. * The indexing data set is loaded before the actual data write * in order to support batch UPSERT. */ private static DataStream<HoodieRecord> boundedBootstrap( Configuration conf, RowType rowType, int defaultParallelism, DataStream<RowData> dataStream) { final RowDataKeyGen rowDataKeyGen = RowDataKeyGen.instance(conf, rowType); // shuffle by partition keys dataStream = dataStream .keyBy(rowDataKeyGen::getPartitionPath); //加上key,以partitionPath为key return rowDataToHoodieRecord(conf, rowType, dataStream) //转换成HoodieRecord .transform( "batch_index_bootstrap", TypeInformation.of(HoodieRecord.class), new BatchBootstrapOperator<>(conf)) //BathBootStrap .setParallelism(conf.getOptional(FlinkOptions.INDEX_BOOTSTRAP_TASKS).orElse(defaultParallelism)) .uid("uid_batch_index_bootstrap_" + conf.getString(FlinkOptions.TABLE_NAME)); }
BatchBootstrapOperator
和上面不同在于,
这里,preLoadIndexRecords是空的,不做事情
然后在processElement的时候,动态对于record对应的partitionPath进行load
@Override protected void preLoadIndexRecords() { // no operation } @Override @SuppressWarnings("unchecked") public void processElement(StreamRecord<I> element) throws Exception { final HoodieRecord<?> record = (HoodieRecord<?>) element.getValue(); final String partitionPath = record.getKey().getPartitionPath(); if (haveSuccessfulCommits && !partitionPathSet.contains(partitionPath)) { loadRecords(partitionPath); partitionPathSet.add(partitionPath); } // send the trigger record output.collect((StreamRecord<O>) element); }
所以最终bootstrap,除了output正常的record流,还会output indexRecord流
hoodieStreamWrite
先按照recordKey shuffle
然后assign bucket
再按照bucket id,即file group,shuffle,保证一个file group只会在一个task中写入,避免冲突
/** * The streaming write pipeline. * * <p>The input dataset shuffles by the primary key first then * shuffles by the file group ID before passing around to the write function. * The whole pipeline looks like the following: * * <pre> * | input1 | ===\ /=== | bucket assigner | ===\ /=== | task1 | * shuffle(by PK) shuffle(by bucket ID) * | input2 | ===/ \=== | bucket assigner | ===/ \=== | task2 | * * Note: a file group must be handled by one write task to avoid write conflict. * </pre> * * <p>The bucket assigner assigns the inputs to suitable file groups, the write task caches * and flushes the data set to disk. * * @param conf The configuration * @param defaultParallelism The default parallelism * @param dataStream The input data stream * @return the stream write data stream pipeline */
代码逻辑比较清晰,
WriteOperatorFactory<HoodieRecord> operatorFactory = StreamWriteOperator.getFactory(conf); // return dataStream // Key-by record key, to avoid multiple subtasks write to a bucket at the same time .keyBy(HoodieRecord::getRecordKey) //按照record key进行shuffle .transform( "bucket_assigner", TypeInformation.of(HoodieRecord.class), new KeyedProcessOperator<>(new BucketAssignFunction<>(conf))) //分配bucket .uid("uid_bucket_assigner_" + conf.getString(FlinkOptions.TABLE_NAME)) .setParallelism(conf.getOptional(FlinkOptions.BUCKET_ASSIGN_TASKS).orElse(defaultParallelism)) // shuffle by fileId(bucket id) .keyBy(record -> record.getCurrentLocation().getFileId()) //按照bucketID进行shuffle .transform("stream_write", TypeInformation.of(Object.class), operatorFactory) //流式写入 .uid("uid_stream_write" + conf.getString(FlinkOptions.TABLE_NAME)) .setParallelism(conf.getInteger(FlinkOptions.WRITE_TASKS));
BucketAssignFunction
有两个流,一个是从bootstrap过来的indexRecord,一个是正常的数据record
所以对于,indexRecord逻辑很简单,利用KeyedStateStore来存每个recordKey对应的location
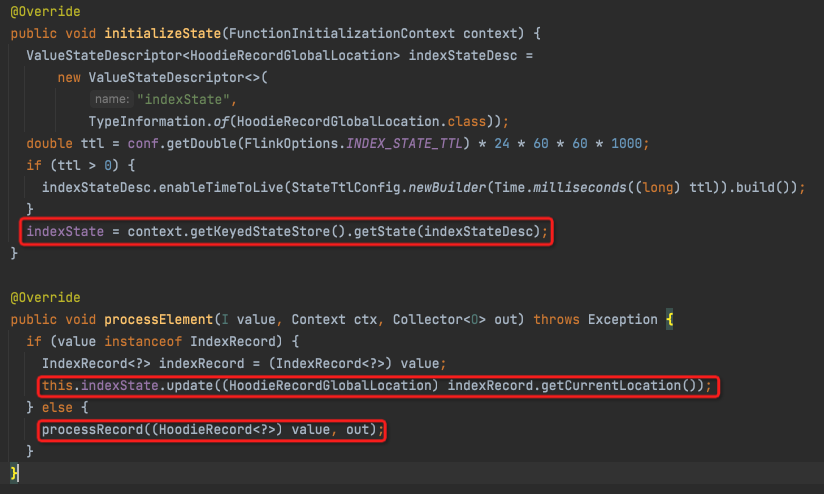
对于正常的record,
几种情况,
如果当前的PartitionPath和老的不一样,
- 如果是globalIndex,需要先创建一条deleteRecord,然后再在当前partitionPath,getNewRecordLocation,即分配一个新的file group
- 如果不是globalIndex,那index是partition内部的,不用管其他的partition,所以直接getNewRecordLocation
如果location一样,那么直接update
private void processRecord(HoodieRecord<?> record, Collector<O> out) throws Exception { // 1. put the record into the BucketAssigner; // 2. look up the state for location, if the record has a location, just send it out; // 3. if it is an INSERT, decide the location using the BucketAssigner then send it out. final HoodieKey hoodieKey = record.getKey(); final String recordKey = hoodieKey.getRecordKey(); final String partitionPath = hoodieKey.getPartitionPath(); final HoodieRecordLocation location; // Only changing records need looking up the index for the location, // append only records are always recognized as INSERT. HoodieRecordGlobalLocation oldLoc = indexState.value(); if (isChangingRecords && oldLoc != null) { // Set up the instant time as "U" to mark the bucket as an update bucket. if (!Objects.equals(oldLoc.getPartitionPath(), partitionPath)) { if (globalIndex) { // if partition path changes, emit a delete record for old partition path, // then update the index state using location with new partition path. HoodieRecord<?> deleteRecord = new HoodieAvroRecord<>(new HoodieKey(recordKey, oldLoc.getPartitionPath()), payloadCreation.createDeletePayload((BaseAvroPayload) record.getData())); deleteRecord.setCurrentLocation(oldLoc.toLocal("U")); deleteRecord.seal(); out.collect((O) deleteRecord); } location = getNewRecordLocation(partitionPath); } else { location = oldLoc.toLocal("U"); this.bucketAssigner.addUpdate(partitionPath, location.getFileId()); } } else { location = getNewRecordLocation(partitionPath); } // always refresh the index if (isChangingRecords) { updateIndexState(partitionPath, location); } record.setCurrentLocation(location); out.collect((O) record); }
getNewRecordLocation,其实是调用了bucketAssigner.addInsert
下面就看下,
bucketAssigner.addInsert和bucketAssigner.addUpdate
addInsert
这里注意,newFileAssignState和bucketInfoMap在每次checkpoint的时候会clear掉
因为cp的时候,所有的file会close掉
public BucketInfo addInsert(String partitionPath) { // for new inserts, compute buckets depending on how many records we have for each partition SmallFileAssign smallFileAssign = getSmallFileAssign(partitionPath); // 先找小文件,如果有可以assign,就update该文件 if (smallFileAssign != null && smallFileAssign.assign()) { return new BucketInfo(BucketType.UPDATE, smallFileAssign.getFileId(), partitionPath); } // 看下当前partitionPath上,是否有现成可以assign的文件,如果有拿过来直接update if (newFileAssignStates.containsKey(partitionPath)) { NewFileAssignState newFileAssignState = newFileAssignStates.get(partitionPath); if (newFileAssignState.canAssign()) { newFileAssignState.assign(); final String key = StreamerUtil.generateBucketKey(partitionPath, newFileAssignState.fileId); if (bucketInfoMap.containsKey(key)) { // the newFileAssignStates is cleaned asynchronously when received the checkpoint success notification, // the records processed within the time range: // (start checkpoint, checkpoint success(and instant committed)) // should still be assigned to the small buckets of last checkpoint instead of new one. // the bucketInfoMap is cleaned when checkpoint starts. // A promotion: when the HoodieRecord can record whether it is an UPDATE or INSERT, // we can always return an UPDATE BucketInfo here, and there is no need to record the // UPDATE bucket through calling #addUpdate. return bucketInfoMap.get(key); } return new BucketInfo(BucketType.UPDATE, newFileAssignState.fileId, partitionPath); } } //如果没有,就要新创建bucket BucketInfo bucketInfo = new BucketInfo(BucketType.INSERT, createFileIdOfThisTask(), partitionPath); final String key = StreamerUtil.generateBucketKey(partitionPath, bucketInfo.getFileIdPrefix()); bucketInfoMap.put(key, bucketInfo); NewFileAssignState newFileAssignState = new NewFileAssignState(bucketInfo.getFileIdPrefix(), writeProfile.getRecordsPerBucket()); // newFileAssignState.assign(); newFileAssignStates.put(partitionPath, newFileAssignState); return bucketInfo; }
addUpdate
这个逻辑就很简单了,对于update已经知道fileid,就直接生成bucketInfo就可以
public BucketInfo addUpdate(String partitionPath, String fileIdHint) { final String key = StreamerUtil.generateBucketKey(partitionPath, fileIdHint); if (!bucketInfoMap.containsKey(key)) { BucketInfo bucketInfo = new BucketInfo(BucketType.UPDATE, fileIdHint, partitionPath); bucketInfoMap.put(key, bucketInfo); } // else do nothing because the bucket already exists. return bucketInfoMap.get(key); }
StreamWriteFunction
可以看到,这里核心逻辑非常简单
processElement只是buffer
当checkpoint的时候去flush所有的buckets
@Override public void open(Configuration parameters) throws IOException { this.tracer = new TotalSizeTracer(this.config); initBuffer(); initWriteFunction(); } @Override public void snapshotState() { // Based on the fact that the coordinator starts the checkpoint first, // it would check the validity. // wait for the buffer data flush out and request a new instant flushRemaining(false); } @Override public void processElement(I value, ProcessFunction<I, Object>.Context ctx, Collector<Object> out) throws Exception { bufferRecord((HoodieRecord<?>) value); }
bufferRecord
把element里面的data加到对应的bucket的buffer中去,
然后会额外做两个判断,flushBucket和flushBuffer
如果bucket过大,就flush掉该bucket;如果buffer太大,从里面找到最大的bucket去flush
/** * Buffers the given record. * * <p>Flush the data bucket first if the bucket records size is greater than * the configured value {@link FlinkOptions#WRITE_BATCH_SIZE}. * * <p>Flush the max size data bucket if the total buffer size exceeds the configured * threshold {@link FlinkOptions#WRITE_TASK_MAX_SIZE}. * * @param value HoodieRecord */ protected void bufferRecord(HoodieRecord<?> value) { final String bucketID = getBucketID(value); // DataBucket bucket = this.buckets.computeIfAbsent(bucketID, k -> new DataBucket(this.config.getDouble(FlinkOptions.WRITE_BATCH_SIZE), value)); // final DataItem item = DataItem.fromHoodieRecord(value); // bucket.records.add(item); // boolean flushBucket = bucket.detector.detect(item); // boolean flushBuffer = this.tracer.trace(bucket.detector.lastRecordSize); // if (flushBucket) { if (flushBucket(bucket)) { this.tracer.countDown(bucket.detector.totalSize); bucket.reset(); } } else if (flushBuffer) { // find the max size bucket and flush it out List<DataBucket> sortedBuckets = this.buckets.values().stream() .sorted((b1, b2) -> Long.compare(b2.detector.totalSize, b1.detector.totalSize)) .collect(Collectors.toList()); final DataBucket bucketToFlush = sortedBuckets.get(0); if (flushBucket(bucketToFlush)) { this.tracer.countDown(bucketToFlush.detector.totalSize); bucketToFlush.reset(); } else { LOG.warn("The buffer size hits the threshold {}, but still flush the max size data bucket failed!", this.tracer.maxBufferSize); } } }
flushRemaining
private void flushRemaining(boolean endInput) { this.currentInstant = instantToWrite(hasData()); //获取instant final List<WriteStatus> writeStatus; if (buckets.size() > 0) { writeStatus = new ArrayList<>(); this.buckets.values() // The records are partitioned by the bucket ID and each batch sent to // the writer belongs to one bucket. .forEach(bucket -> { List<HoodieRecord> records = bucket.writeBuffer(); if (records.size() > 0) { if (config.getBoolean(FlinkOptions.PRE_COMBINE)) { records = FlinkWriteHelper.newInstance().deduplicateRecords(records, (HoodieIndex) null, -1); //去重,在bucket所缓存的records中 } bucket.preWrite(records); // writeStatus.addAll(writeFunction.apply(records, currentInstant)); //利用writeFunction进行真实写入 records.clear(); bucket.reset(); } }); } else { LOG.info("No data to write in subtask [{}] for instant [{}]", taskID, currentInstant); writeStatus = Collections.emptyList(); } final WriteMetadataEvent event = WriteMetadataEvent.builder() .taskID(taskID) .instantTime(currentInstant) .writeStatus(writeStatus) .lastBatch(true) .endInput(endInput) .build(); //将writeStatus发给coordinator,更新meta this.eventGateway.sendEventToCoordinator(event); this.buckets.clear(); this.tracer.reset(); this.writeClient.cleanHandles(); this.writeStatuses.addAll(writeStatus); // blocks flushing until the coordinator starts a new instant this.confirming = true; }
这里的writeFunction,
我们可以挑个看下,
HoodieFlinkWriteClient.upsert
HoodieFlinkCopyOnWriteTable.upsert
FlinkUpsertCommitActionExecutor.execute
FlinkWriteHelper.write
BaseFlinkCommitActionExecutor.execute
protected Iterator<List<WriteStatus>> handleUpdateInternal(HoodieMergeHandle<?, ?, ?, ?> upsertHandle, String fileId) throws IOException { if (upsertHandle.getOldFilePath() == null) { throw new HoodieUpsertException( "Error in finding the old file path at commit " + instantTime + " for fileId: " + fileId); } else { FlinkMergeHelper.newInstance().runMerge(table, upsertHandle); //最终调用 } return Collections.singletonList(upsertHandle.writeStatuses()).iterator(); }
runMerge
producer,readerIterator读取record
consumer,调用mergeHandle
ThreadLocal<BinaryEncoder> encoderCache = new ThreadLocal<>(); ThreadLocal<BinaryDecoder> decoderCache = new ThreadLocal<>(); //producer-consumer模式 wrapper = new BoundedInMemoryExecutor<>(table.getConfig().getWriteBufferLimitBytes(), new IteratorBasedQueueProducer<>(readerIterator), Option.of(new UpdateHandler(mergeHandle)), record -> { if (!externalSchemaTransformation) { return record; } return transformRecordBasedOnNewSchema(gReader, gWriter, encoderCache, decoderCache, (GenericRecord) record); }); wrapper.execute();
mergeHandle
HoodieFlinkWriteClient.upsert中生成,
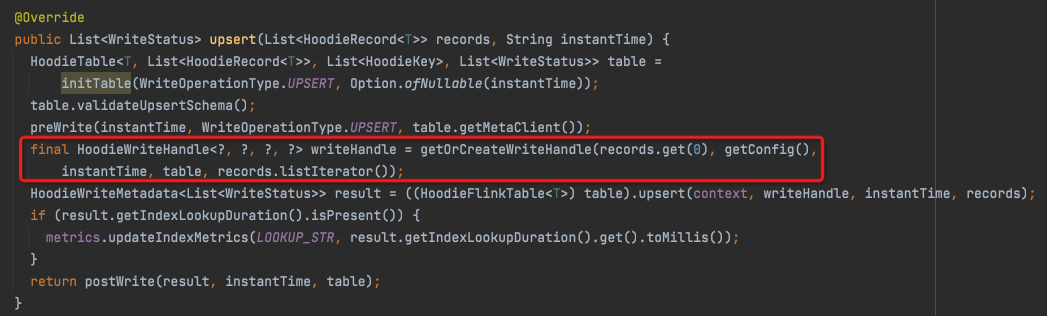
getOrCreateWriteHandle
final boolean isDelta = table.getMetaClient().getTableType().equals(HoodieTableType.MERGE_ON_READ); final HoodieWriteHandle<?, ?, ?, ?> writeHandle; if (isDelta) { //merge on Read writeHandle = new FlinkAppendHandle<>(config, instantTime, table, partitionPath, fileID, recordItr, table.getTaskContextSupplier()); } else if (loc.getInstantTime().equals("I")) { //insert writeHandle = new FlinkCreateHandle<>(config, instantTime, table, partitionPath, fileID, table.getTaskContextSupplier()); } else { //update writeHandle = insertClustering ? new FlinkConcatHandle<>(config, instantTime, table, recordItr, partitionPath, fileID, table.getTaskContextSupplier()) : new FlinkMergeHandle<>(config, instantTime, table, recordItr, partitionPath, fileID, table.getTaskContextSupplier()); }
分成几种,
FlinkAppendHandle,FlinkCreateHandle,FlinkMergeHandle,基本重用HoodieAppendHandle,HoodieCreateHandle,HoodieMergeHandle
StreamWriteOperatorCoordinator
首先是Coordinator,所以要接收Operator发来的消息,
分三种,endInput,bootstrap,writeMeta
@Override public void handleEventFromOperator(int i, OperatorEvent operatorEvent) { ValidationUtils.checkState(operatorEvent instanceof WriteMetadataEvent, "The coordinator can only handle WriteMetaEvent"); WriteMetadataEvent event = (WriteMetadataEvent) operatorEvent; if (event.isEndInput()) { // handle end input event synchronously handleEndInputEvent(event); // } else { executor.execute( () -> { if (event.isBootstrap()) { handleBootstrapEvent(event); // } else { handleWriteMetaEvent(event); // } }, "handle write metadata event for instant %s", this.instant ); } }
EventBuffer,数组,大小等于task的并发度,一个task对应于一个slot
所以通过EventBuffer,就可以很容易看出来各个task的event的情况
this.eventBuffer = new WriteMetadataEvent[this.parallelism];
3个handle event的逻辑
private void handleBootstrapEvent(WriteMetadataEvent event) { this.eventBuffer[event.getTaskID()] = event; //把event放入到buffer if (Arrays.stream(eventBuffer).allMatch(evt -> evt != null && evt.isBootstrap())) { //如果所有的task都收到了bootstrap event // start to initialize the instant. initInstant(event.getInstantTime()); //初始化新的instant } } private void handleEndInputEvent(WriteMetadataEvent event) { addEventToBuffer(event); //放入buffer if (allEventsReceived()) { //如果所有task都收到EndInput // start to commit the instant. commitInstant(this.instant); //commit该instant // The executor thread inherits the classloader of the #handleEventFromOperator // caller, which is a AppClassLoader. Thread.currentThread().setContextClassLoader(getClass().getClassLoader()); // sync Hive synchronously if it is enabled in batch mode. syncHive(); } } private void handleWriteMetaEvent(WriteMetadataEvent event) { // the write task does not block after checkpointing(and before it receives a checkpoint success event), // if it checkpoints succeed then flushes the data buffer again before this coordinator receives a checkpoint // success event, the data buffer would flush with an older instant time. ValidationUtils.checkState( HoodieTimeline.compareTimestamps(this.instant, HoodieTimeline.GREATER_THAN_OR_EQUALS, event.getInstantTime()), String.format("Receive an unexpected event for instant %s from task %d", event.getInstantTime(), event.getTaskID())); addEventToBuffer(event); //写Meta的event直接buffer }
然后,
initInstant
private void initInstant(String instant) { HoodieTimeline completedTimeline = StreamerUtil.createMetaClient(conf).getActiveTimeline().filterCompletedInstants(); //找出所有完成的instant executor.execute(() -> { if (instant.equals("") || completedTimeline.containsInstant(instant)) { // the last instant committed successfully reset(); //如果当前instant已经完成,那就清空eventBuffer } else { LOG.info("Recommit instant {}", instant); commitInstant(instant); //如果没有完成,先commit该instant } // starts a new instant startInstant(); //start一个新的instant // upgrade downgrade this.writeClient.upgradeDowngrade(this.instant); }, "initialize instant %s", instant); }
startInstant
private void startInstant() { // put the assignment in front of metadata generation, // because the instant request from write task is asynchronous. this.instant = this.writeClient.startCommit(tableState.commitAction, this.metaClient); //在Timeline上创建新的instant this.metaClient.getActiveTimeline().transitionRequestedToInflight(tableState.commitAction, this.instant); //将instant的状态迁移成inflight this.ckpMetadata.startInstant(this.instant); //创建start instant对应的cp文件 }
commitInstant,这个是在EndInputEvent中,即是batch写入的时候触发
private boolean commitInstant(String instant, long checkpointId) { List<WriteStatus> writeResults = Arrays.stream(eventBuffer) .filter(Objects::nonNull) .map(WriteMetadataEvent::getWriteStatuses) .flatMap(Collection::stream) .collect(Collectors.toList()); //从Eventbuffer中提取出writeResults if (writeResults.size() == 0) { //如果没有results,直接ack sendCommitAckEvents(checkpointId); return false; } doCommit(instant, writeResults); //commit return true; }
doCommit
private void doCommit(String instant, List<WriteStatus> writeResults) { final Map<String, List<String>> partitionToReplacedFileIds = tableState.isOverwrite ? writeClient.getPartitionToReplacedFileIds(tableState.operationType, writeResults) : Collections.emptyMap(); boolean success = writeClient.commit(instant, writeResults, Option.of(checkpointCommitMetadata), tableState.commitAction, partitionToReplacedFileIds); //commit Metadata if (success) { reset(); this.ckpMetadata.commitInstant(instant); //创建commit instant的cp file LOG.info("Commit instant [{}] success!", instant); } else { throw new HoodieException(String.format("Commit instant [%s] failed!", instant)); } }
HoodieFlinkWriteClient
public boolean commit(String instantTime, List<WriteStatus> writeStatuses, Option<Map<String, String>> extraMetadata, String commitActionType, Map<String, List<String>> partitionToReplacedFileIds) { List<HoodieWriteStat> writeStats = writeStatuses.parallelStream().map(WriteStatus::getStat).collect(Collectors.toList()); return commitStats(instantTime, writeStats, extraMetadata, commitActionType, partitionToReplacedFileIds); }
BaseHoodieWriteClient
public boolean commitStats(String instantTime, List<HoodieWriteStat> stats, Option<Map<String, String>> extraMetadata, String commitActionType, Map<String, List<String>> partitionToReplaceFileIds) { // Create a Hoodie table which encapsulated the commits and files visible HoodieTable table = createTable(config, hadoopConf); // HoodieCommitMetadata metadata = CommitUtils.buildMetadata(stats, partitionToReplaceFileIds, extraMetadata, operationType, config.getWriteSchema(), commitActionType); // HoodieInstant inflightInstant = new HoodieInstant(State.INFLIGHT, table.getMetaClient().getCommitActionType(), instantTime); HeartbeatUtils.abortIfHeartbeatExpired(instantTime, table, heartbeatClient, config); this.txnManager.beginTransaction(Option.of(inflightInstant), lastCompletedTxnAndMetadata.isPresent() ? Option.of(lastCompletedTxnAndMetadata.get().getLeft()) : Option.empty()); try { preCommit(inflightInstant, metadata); //主要是resolve写冲突 commit(table, commitActionType, instantTime, metadata, stats); //commit,将instant存入timeline // 删除marker,自动clean,自动archive postCommit(table, metadata, instantTime, extraMetadata, false); LOG.info("Committed " + instantTime); releaseResources(); } catch (IOException e) { throw new HoodieCommitException("Failed to complete commit " + config.getBasePath() + " at time " + instantTime, e); } finally { this.txnManager.endTransaction(Option.of(inflightInstant)); //更改meta前后需要加减锁 } // do this outside of lock since compaction, clustering can be time taking and we don't need a lock for the entire execution period runTableServicesInline(table, metadata, extraMetadata); //执行定义的table services,如compaction或clustering emitCommitMetrics(instantTime, metadata, commitActionType);
再者,要响应checkpoint
对于流式写入,需要在每次checkpoint的时候去commitInstant,并且开启新的instant
@Override public void notifyCheckpointComplete(long checkpointId) { executor.execute( () -> { // The executor thread inherits the classloader of the #notifyCheckpointComplete // caller, which is a AppClassLoader. Thread.currentThread().setContextClassLoader(getClass().getClassLoader()); // for streaming mode, commits the ever received events anyway, // the stream write task snapshot and flush the data buffer synchronously in sequence, // so a successful checkpoint subsumes the old one(follows the checkpoint subsuming contract) final boolean committed = commitInstant(this.instant, checkpointId); // if (tableState.scheduleCompaction) { // if async compaction is on, schedule the compaction CompactionUtil.scheduleCompaction(metaClient, writeClient, tableState.isDeltaTimeCompaction, committed); // } if (committed) { // start new instant. startInstant(); // // sync Hive if is enabled syncHiveAsync(); } }, "commits the instant %s", this.instant ); } @Override public void notifyCheckpointAborted(long checkpointId) { if (checkpointId == this.checkpointId) { executor.execute(() -> { this.ckpMetadata.abortInstant(this.instant); // }, "abort instant %s", this.instant); } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号