Apache Hudi 源码分析 - JavaClient
JavaClient
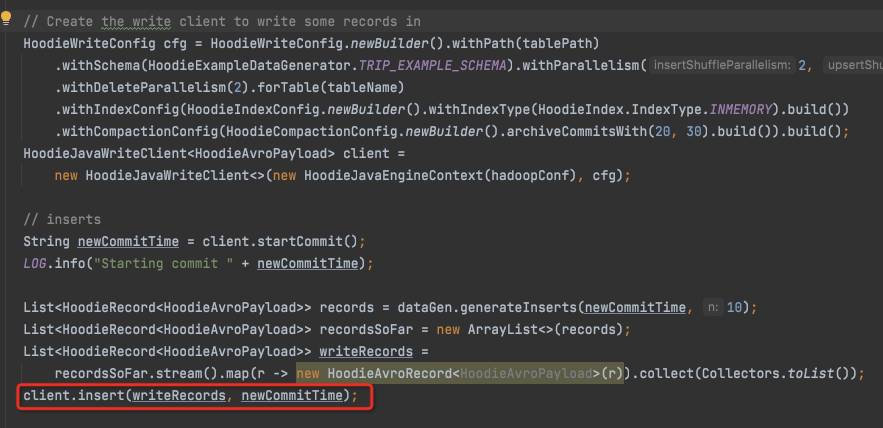
Insert,
@Override public List<WriteStatus> insert(List<HoodieRecord<T>> records, String instantTime) { HoodieTable<T, List<HoodieRecord<T>>, List<HoodieKey>, List<WriteStatus>> table = initTable(WriteOperationType.INSERT, Option.ofNullable(instantTime)); //见下 table.validateUpsertSchema(); //验证records和table的schema是否匹配,hoodie是写的时候检查schema preWrite(instantTime, WriteOperationType.INSERT, table.getMetaClient()); //pre-do,比如从inflight中移除改instant,开启cleaner和archive等服务 HoodieWriteMetadata<List<WriteStatus>> result = table.insert(context, instantTime, records); //见下 if (result.getIndexLookupDuration().isPresent()) { metrics.updateIndexMetrics(LOOKUP_STR, result.getIndexLookupDuration().get().toMillis()); } return postWrite(result, instantTime, table); // }
initTable,
注意在改meta的时候会用事务,加全局锁
/** * Instantiates and initializes instance of {@link HoodieTable}, performing crucial bootstrapping * operations such as: * * NOTE: This method is engine-agnostic and SHOULD NOT be overloaded, please check on * {@link #doInitTable(HoodieTableMetaClient, Option, boolean)} instead * * <ul> * <li>Checking whether upgrade/downgrade is required</li> * <li>Bootstrapping Metadata Table (if required)</li> * <li>Initializing metrics contexts</li> * </ul> */ protected final HoodieTable initTable(WriteOperationType operationType, Option<String> instantTime, boolean initialMetadataTableIfNecessary) { HoodieTableMetaClient metaClient = createMetaClient(true); //读取Meta文件的client HoodieTable table; Option<HoodieInstant> ownerInstant = Option.empty(); // Instant代表Timeline中一个具体的时间点 if (instantTime.isPresent()) { ownerInstant = Option.of(new HoodieInstant(true, CommitUtils.getCommitActionType(operationType, metaClient.getTableType()), instantTime.get())); } this.txnManager.beginTransaction(ownerInstant, Option.empty()); //开始事务,调用lockManager.lock,加全局锁 try { tryUpgrade(metaClient, instantTime); //对Table做些准备和恢复工作,比如rollbackFailedWrites,metaClient.reloadActiveTimeline table = doInitTable(metaClient, instantTime, initialMetadataTableIfNecessary); // } finally { this.txnManager.endTransaction(ownerInstant); }
doInitTable,生成Table对象

insert
@Override public HoodieWriteMetadata<List<WriteStatus>> insert(HoodieEngineContext context, String instantTime, List<HoodieRecord<T>> records) { return new JavaInsertCommitActionExecutor<>(context, config, this, instantTime, records).execute(); //异步线程 }
JavaInsertCommitActionExecutor
这里调用execute时,会把this作为参数传入
@Override public HoodieWriteMetadata<List<WriteStatus>> execute() { return JavaWriteHelper.newInstance().write(instantTime, inputRecords, context, table, config.shouldCombineBeforeInsert(), config.getInsertShuffleParallelism(), this, operationType); }
JavaWriteHelper
Write
将executor传入继续调用execute的方式,有些tricky
public HoodieWriteMetadata<O> write(String instantTime, I inputRecords, HoodieEngineContext context, HoodieTable<T, I, K, O> table, boolean shouldCombine, int shuffleParallelism, BaseCommitActionExecutor<T, I, K, O, R> executor, WriteOperationType operationType) { try { // De-dupe/merge if needed I dedupedRecords = combineOnCondition(shouldCombine, inputRecords, shuffleParallelism, table); //消重,merge,见下 Instant lookupBegin = Instant.now(); I taggedRecords = dedupedRecords; if (table.getIndex().requiresTagging(operationType)) { // perform index loop up to get existing location of records context.setJobStatus(this.getClass().getSimpleName(), "Tagging"); taggedRecords = tag(dedupedRecords, context, table); //Tag,即在index中查找location,见下 } Duration indexLookupDuration = Duration.between(lookupBegin, Instant.now()); //记录下查index的耗时 HoodieWriteMetadata<O> result = executor.execute(taggedRecords); //调用传入的executor继续execute,见下 result.setIndexLookupDuration(indexLookupDuration); return result;
消重,合并该次插入中相同key的record,并进行reduce
@Override
public List<HoodieRecord<T>> deduplicateRecords(
List<HoodieRecord<T>> records, HoodieIndex<?, ?> index, int parallelism) {
boolean isIndexingGlobal = index.isGlobal();
Map<Object, List<Pair<Object, HoodieRecord<T>>>> keyedRecords = records.stream().map(record -> { //
HoodieKey hoodieKey = record.getKey();
// If index used is global, then records are expected to differ in their partitionPath
Object key = isIndexingGlobal ? hoodieKey.getRecordKey() : hoodieKey; //如果index是global,那么recordKey就全局唯一的,否则会重复,只能用hoodieKey
return Pair.of(key, record);
}).collect(Collectors.groupingBy(Pair::getLeft)); //按Key去group
return keyedRecords.values().stream().map(x -> x.stream().map(Pair::getRight).reduce((rec1, rec2) -> { //把相同key的record进行reduce
@SuppressWarnings("unchecked")
T reducedData = (T) rec1.getData().preCombine(rec2.getData());
// we cannot allow the user to change the key or partitionPath, since that will affect
// everything
// so pick it from one of the records.
return new HoodieAvroRecord<T>(rec1.getKey(), reducedData);
}).orElse(null)).filter(Objects::nonNull).collect(Collectors.toList());
}
tag
@Override protected List<HoodieRecord<T>> tag(List<HoodieRecord<T>> dedupedRecords, HoodieEngineContext context, HoodieTable<T, List<HoodieRecord<T>>, List<HoodieKey>, List<WriteStatus>> table) { return HoodieList.getList( table.getIndex().tagLocation(HoodieList.of(dedupedRecords), context, table)); }
tagLocation有多种实现,针对不同的index,看个最简单的HoodieInMemoryHashIndex
@Override public <R> HoodieData<HoodieRecord<R>> tagLocation( HoodieData<HoodieRecord<R>> records, HoodieEngineContext context, HoodieTable hoodieTable) { return records.mapPartitions(hoodieRecordIterator -> { List<HoodieRecord<R>> taggedRecords = new ArrayList<>(); while (hoodieRecordIterator.hasNext()) { HoodieRecord<R> record = hoodieRecordIterator.next(); if (recordLocationMap.containsKey(record.getKey())) { //index中找到该record record.unseal(); // record.setCurrentLocation(recordLocationMap.get(record.getKey())); //将location set到record中 record.seal(); // } taggedRecords.add(record); //记录一下找到location的Record } return taggedRecords.iterator(); }, true); }
execute
BaseJavaCommitActionExecutor
@Override public HoodieWriteMetadata<List<WriteStatus>> execute(List<HoodieRecord<T>> inputRecords) { HoodieWriteMetadata<List<WriteStatus>> result = new HoodieWriteMetadata<>(); WorkloadProfile workloadProfile = null; if (isWorkloadProfileNeeded()) { workloadProfile = new WorkloadProfile(buildProfile(inputRecords), table.getIndex().canIndexLogFiles()); //构造Workload profile,见下 final Partitioner partitioner = getPartitioner(workloadProfile); //获取partitioner,初步分配文件,每个文件对于的record数目 try { saveWorkloadProfileMetadataToInflight(workloadProfile, instantTime); //生成inflight的instant } catch (Exception e) { } Map<Integer, List<HoodieRecord<T>>> partitionedRecords = partition(inputRecords, partitioner); //真正的把record分配到各个bucket中去 List<WriteStatus> writeStatuses = new LinkedList<>(); partitionedRecords.forEach((partition, records) -> { if (WriteOperationType.isChangingRecords(operationType)) { handleUpsertPartition(instantTime, partition, records.iterator(), partitioner).forEachRemaining(writeStatuses::addAll); //写文件 } else { handleInsertPartition(instantTime, partition, records.iterator(), partitioner).forEachRemaining(writeStatuses::addAll); // } }); updateIndex(writeStatuses, result); //为何index要update两遍 updateIndexAndCommitIfNeeded(writeStatuses, result); //Commit,见下 return result; }
buildProfile
protected Pair<HashMap<String, WorkloadStat>, WorkloadStat> buildProfile(List<HoodieRecord<T>> inputRecords) { HashMap<String, WorkloadStat> partitionPathStatMap = new HashMap<>(); //按Partiton的WL统计 WorkloadStat globalStat = new WorkloadStat(); //全局的WL统计,WLStat,insert count和每个fileGroup的update count //<PartitionPath,<fileGroupid, record count>> Map<Pair<String, Option<HoodieRecordLocation>>, Long> partitionLocationCounts = inputRecords .stream() .map(record -> Pair.of( Pair.of(record.getPartitionPath(), Option.ofNullable(record.getCurrentLocation())), record)) .collect(Collectors.groupingBy(Pair::getLeft, Collectors.counting())); for (Map.Entry<Pair<String, Option<HoodieRecordLocation>>, Long> e : partitionLocationCounts.entrySet()) { String partitionPath = e.getKey().getLeft(); Long count = e.getValue(); Option<HoodieRecordLocation> locOption = e.getKey().getRight(); if (!partitionPathStatMap.containsKey(partitionPath)) { partitionPathStatMap.put(partitionPath, new WorkloadStat()); } if (locOption.isPresent()) { // update partitionPathStatMap.get(partitionPath).addUpdates(locOption.get(), count); // globalStat.addUpdates(locOption.get(), count); // } else { // insert partitionPathStatMap.get(partitionPath).addInserts(count); //更新Partition级别的WL globalStat.addInserts(count); //更新全局WL } } return Pair.of(partitionPathStatMap, globalStat); }
getPartitioner
public JavaUpsertPartitioner(WorkloadProfile workloadProfile, HoodieEngineContext context, HoodieTable table, HoodieWriteConfig config) { updateLocationToBucket = new HashMap<>(); partitionPathToInsertBucketInfos = new HashMap<>(); bucketInfoMap = new HashMap<>(); this.workloadProfile = workloadProfile; this.table = table; this.config = config; assignUpdates(workloadProfile); //update本身就是指定了location,assign比较简单,copy assignInserts(workloadProfile, context); //insert要考虑现有文件的均衡性,assign复杂些
assignInserts
把所有inserts分配到各个文件,即bucket上
但是这里只是按数目分,粗分
private void assignInserts(WorkloadProfile profile, HoodieEngineContext context) { // for new inserts, compute buckets depending on how many records we have for each partition Set<String> partitionPaths = profile.getPartitionPaths(); long averageRecordSize = averageBytesPerRecord(table.getMetaClient().getActiveTimeline().getCommitTimeline().filterCompletedInstants(), config); //根据之前的commit的record,估算record的平均size LOG.info("AvgRecordSize => " + averageRecordSize); Map<String, List<SmallFile>> partitionSmallFilesMap = getSmallFilesForPartitions(new ArrayList<String>(partitionPaths), context); //找到每个partition里面的小文件,小文件可以继续insert for (String partitionPath : partitionPaths) { WorkloadStat pStat = profile.getWorkloadStat(partitionPath); //得到每个partition的input Stat WorkloadStat outputWorkloadStats = profile.getOutputPartitionPathStatMap().getOrDefault(partitionPath, new WorkloadStat()); //初始化output stat if (pStat.getNumInserts() > 0) { List<SmallFile> smallFiles = partitionSmallFilesMap.getOrDefault(partitionPath, new ArrayList<>()); //先得到该partition中的small files this.smallFiles.addAll(smallFiles); long totalUnassignedInserts = pStat.getNumInserts(); //Stat中的inserts数目作为unassigned List<Integer> bucketNumbers = new ArrayList<>(); //bucket概念, List<Long> recordsPerBucket = new ArrayList<>(); //这两个list等同于一个map // first try packing this into one of the smallFiles,先尽量利用现有的小文件 for (SmallFile smallFile : smallFiles) { long recordsToAppend = Math.min((config.getParquetMaxFileSize() - smallFile.sizeBytes) / averageRecordSize, totalUnassignedInserts); //看下这个small file还能放多少条record,直接按MaxFileSize来算 if (recordsToAppend > 0) { // create a new bucket or re-use an existing bucket int bucket; if (updateLocationToBucket.containsKey(smallFile.location.getFileId())) { bucket = updateLocationToBucket.get(smallFile.location.getFileId()); //看下这个file有没有对应的bucket } else { bucket = addUpdateBucket(partitionPath, smallFile.location.getFileId()); //创建一个bucket,bucketid从0递增 } if (profile.hasOutputWorkLoadStats()) { outputWorkloadStats.addInserts(smallFile.location, recordsToAppend); } bucketNumbers.add(bucket); //更新每个bucket,append多少条records recordsPerBucket.add(recordsToAppend); totalUnassignedInserts -= recordsToAppend; // } } // if we have anything more, create new insert buckets, like normal //如果现有的文件已经放满,创建新的文件 if (totalUnassignedInserts > 0) { long insertRecordsPerBucket = config.getCopyOnWriteInsertSplitSize(); if (config.shouldAutoTuneInsertSplits()) { insertRecordsPerBucket = config.getParquetMaxFileSize() / averageRecordSize; } int insertBuckets = (int) Math.ceil((1.0 * totalUnassignedInserts) / insertRecordsPerBucket); //算出一共需要新增几个文件,即bucket for (int b = 0; b < insertBuckets; b++) { bucketNumbers.add(totalBuckets); // if (b < insertBuckets - 1) { //是不是最后一个bucket,最后一个bucket,record数目不定的 recordsPerBucket.add(insertRecordsPerBucket); } else { recordsPerBucket.add(totalUnassignedInserts - (insertBuckets - 1) * insertRecordsPerBucket); } BucketInfo bucketInfo = new BucketInfo(BucketType.INSERT, FSUtils.createNewFileIdPfx(), partitionPath); //新建bucket bucketInfoMap.put(totalBuckets, bucketInfo); if (profile.hasOutputWorkLoadStats()) { outputWorkloadStats.addInserts(new HoodieRecordLocation(HoodieWriteStat.NULL_COMMIT, bucketInfo.getFileIdPrefix()), recordsPerBucket.get(recordsPerBucket.size() - 1)); } totalBuckets++; } } // Go over all such buckets, and assign weights as per amount of incoming inserts. // List<InsertBucketCumulativeWeightPair> insertBuckets = new ArrayList<>(); double currentCumulativeWeight = 0; for (int i = 0; i < bucketNumbers.size(); i++) { InsertBucket bkt = new InsertBucket(); bkt.bucketNumber = bucketNumbers.get(i); bkt.weight = (1.0 * recordsPerBucket.get(i)) / pStat.getNumInserts(); //weight,bucket被分配的record数目 / 该partition的总插入records数目 currentCumulativeWeight += bkt.weight; //到当前的bucket,累计weight,最终累计应该是1 insertBuckets.add(new InsertBucketCumulativeWeightPair(bkt, currentCumulativeWeight)); //记录当前bucket,和累计的weight } LOG.info("Total insert buckets for partition path " + partitionPath + " => " + insertBuckets); partitionPathToInsertBucketInfos.put(partitionPath, insertBuckets); // } if (profile.hasOutputWorkLoadStats()) { profile.updateOutputPartitionPathStatMap(partitionPath, outputWorkloadStats); // } } }
saveWorkloadProfileMetadataToInflight
在timeline上产生一个inflight的instant,如果后面失败,可以直接rollback
/** * Save the workload profile in an intermediate file (here re-using commit files) This is useful when performing * rollback for MOR tables. Only updates are recorded in the workload profile metadata since updates to log blocks * are unknown across batches Inserts (which are new parquet files) are rolled back based on commit time. // TODO : * Create a new WorkloadProfile metadata file instead of using HoodieCommitMetadata */ void saveWorkloadProfileMetadataToInflight(WorkloadProfile profile, String instantTime) throws HoodieCommitException { try { HoodieCommitMetadata metadata = new HoodieCommitMetadata(); profile.getOutputPartitionPaths().forEach(path -> { WorkloadStat partitionStat = profile.getOutputWorkloadStat(path); HoodieWriteStat insertStat = new HoodieWriteStat(); insertStat.setNumInserts(partitionStat.getNumInserts()); insertStat.setFileId(""); insertStat.setPrevCommit(HoodieWriteStat.NULL_COMMIT); metadata.addWriteStat(path, insertStat); Map<String, Pair<String, Long>> updateLocationMap = partitionStat.getUpdateLocationToCount(); Map<String, Pair<String, Long>> insertLocationMap = partitionStat.getInsertLocationToCount(); Stream.concat(updateLocationMap.keySet().stream(), insertLocationMap.keySet().stream()) .distinct() .forEach(fileId -> { HoodieWriteStat writeStat = new HoodieWriteStat(); //记录每个文件的更新和insert的record数目 writeStat.setFileId(fileId); // Pair<String, Long> updateLocation = updateLocationMap.get(fileId); // Pair<String, Long> insertLocation = insertLocationMap.get(fileId); // TODO : Write baseCommitTime is possible here ? writeStat.setPrevCommit(updateLocation != null ? updateLocation.getKey() : insertLocation.getKey()); //commit版本? if (updateLocation != null) { writeStat.setNumUpdateWrites(updateLocation.getValue()); // } if (insertLocation != null) { writeStat.setNumInserts(insertLocation.getValue()); } metadata.addWriteStat(path, writeStat); //生成metadata }); }); metadata.setOperationType(operationType); HoodieActiveTimeline activeTimeline = table.getActiveTimeline(); //获取Timeline String commitActionType = getCommitActionType(); HoodieInstant requested = new HoodieInstant(State.REQUESTED, commitActionType, instantTime); //创建Instant activeTimeline.transitionRequestedToInflight(requested, Option.of(metadata.toJsonString().getBytes(StandardCharsets.UTF_8)), config.shouldAllowMultiWriteOnSameInstant()); //将meta转成JSON,写入timeline } catch (IOException io) { throw new HoodieCommitException("Failed to commit " + instantTime + " unable to save inflight metadata ", io); } }
partition
private Map<Integer, List<HoodieRecord<T>>> partition(List<HoodieRecord<T>> dedupedRecords, Partitioner partitioner) { Map<Integer, List<Pair<Pair<HoodieKey, Option<HoodieRecordLocation>>, HoodieRecord<T>>>> partitionedMidRecords = dedupedRecords .stream() .map(record -> Pair.of(Pair.of(record.getKey(), Option.ofNullable(record.getCurrentLocation())), record)) //<<recordKey, locatiaon> record> .collect(Collectors.groupingBy(x -> partitioner.getPartition(x.getLeft()))); //group by bucket, getPartition返回record分配的bucket Map<Integer, List<HoodieRecord<T>>> results = new LinkedHashMap<>(); partitionedMidRecords.forEach((key, value) -> results.put(key, value.stream().map(x -> x.getRight()).collect(Collectors.toList()))); // return results; }
getPartition
不明白这通操作的意义何在,看着有点唬人
按分配好的bucket,一个个排过去不行?这个基于hash的方式如何保证各个bucket分配的是均匀的?
@Override public int getPartition(Object key) { Pair<HoodieKey, Option<HoodieRecordLocation>> keyLocation = (Pair<HoodieKey, Option<HoodieRecordLocation>>) key; if (keyLocation.getRight().isPresent()) { //如果这个record有location,那就是update,不需要分配 HoodieRecordLocation location = keyLocation.getRight().get(); // return updateLocationToBucket.get(location.getFileId()); } else { String partitionPath = keyLocation.getLeft().getPartitionPath(); // List<InsertBucketCumulativeWeightPair> targetBuckets = partitionPathToInsertBucketInfos.get(partitionPath); //获取之前assignInserts生成的累计weight,到每个bucket为止 // pick the target bucket to use based on the weights. final long totalInserts = Math.max(1, workloadProfile.getWorkloadStat(partitionPath).getNumInserts()); //该partition一共的inserts数目 final long hashOfKey = NumericUtils.getMessageDigestHash("MD5", keyLocation.getLeft().getRecordKey()); //对recordKey取hash值 final double r = 1.0 * Math.floorMod(hashOfKey, totalInserts) / totalInserts; //hash值对total取模,再除以total,这就得到这个key在total中的位置r int index = Collections.binarySearch(targetBuckets, new InsertBucketCumulativeWeightPair(new InsertBucket(), r)); //二分查,这个r在哪个bucket的累计weight范围内 if (index >= 0) { return targetBuckets.get(index).getKey().bucketNumber; } if ((-1 * index - 1) < targetBuckets.size()) { return targetBuckets.get((-1 * index - 1)).getKey().bucketNumber; } // return first one, by default return targetBuckets.get(0).getKey().bucketNumber; } }
handleUpsertPartition
把数据写入文件
protected Iterator<List<WriteStatus>> handleUpsertPartition(String instantTime, Integer partition, Iterator recordItr, Partitioner partitioner) { JavaUpsertPartitioner javaUpsertPartitioner = (JavaUpsertPartitioner) partitioner; BucketInfo binfo = javaUpsertPartitioner.getBucketInfo(partition); BucketType btype = binfo.bucketType; try { if (btype.equals(BucketType.INSERT)) { return handleInsert(binfo.fileIdPrefix, recordItr); //Insert写入 } else if (btype.equals(BucketType.UPDATE)) { return handleUpdate(binfo.partitionPath, binfo.fileIdPrefix, recordItr); //update更新 } else {
handleInsert -> JavaLazyInsertIterable
这里做了抽象,producer就是读input,consumer是insertHandler
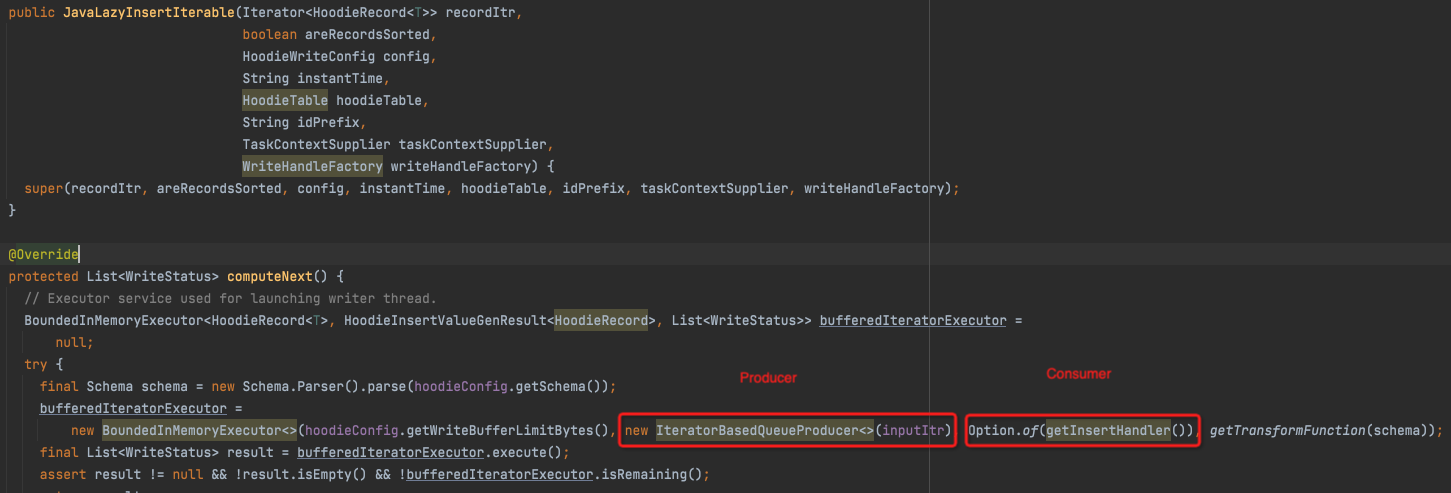
CopyOnWriteInsertHandler -> HoodieCreateHandle -> HoodieParquetWriter.writeAvroWithMetadata
handleUpdate,逻辑复杂写,需要merge,总体差不多
updateIndexAndCommitIfNeeded
public void updateIndexAndCommitIfNeeded(List<WriteStatus> writeStatuses, HoodieWriteMetadata result) { Instant indexStartTime = Instant.now(); // Update the index back List<WriteStatus> statuses = HoodieList.getList( table.getIndex().updateLocation(HoodieList.of(writeStatuses), context, table)); //增加index,record和file的对应关系 result.setIndexUpdateDuration(Duration.between(indexStartTime, Instant.now())); // result.setWriteStatuses(statuses); result.setPartitionToReplaceFileIds(getPartitionToReplacedFileIds(result)); commitOnAutoCommit(result); //commit }
commitOnAutoCommit -> autoCommit
protected void autoCommit(Option<Map<String, String>> extraMetadata, HoodieWriteMetadata<O> result) { final Option<HoodieInstant> inflightInstant = Option.of(new HoodieInstant(State.INFLIGHT, getCommitActionType(), instantTime)); this.txnManager.beginTransaction(inflightInstant, lastCompletedTxn.isPresent() ? Option.of(lastCompletedTxn.get().getLeft()) : Option.empty()); //开始事务 try { setCommitMetadata(result); // reload active timeline so as to get all updates after current transaction have started. hence setting last arg to true. TransactionUtils.resolveWriteConflictIfAny(table, this.txnManager.getCurrentTransactionOwner(), result.getCommitMetadata(), config, this.txnManager.getLastCompletedTransactionOwner(), true, pendingInflightAndRequestedInstants); //解决写冲突,见下 commit(extraMetadata, result); // } finally { this.txnManager.endTransaction(inflightInstant); } }
resolveWriteConflictIfAny
public static Option<HoodieCommitMetadata> resolveWriteConflictIfAny( final HoodieTable table, final Option<HoodieInstant> currentTxnOwnerInstant, final Option<HoodieCommitMetadata> thisCommitMetadata, final HoodieWriteConfig config, Option<HoodieInstant> lastCompletedTxnOwnerInstant, boolean reloadActiveTimeline, Set<String> pendingInstants) throws HoodieWriteConflictException { if (config.getWriteConcurrencyMode().supportsOptimisticConcurrencyControl()) { //是否支持乐观锁 // deal with pendingInstants Stream<HoodieInstant> completedInstantsDuringCurrentWriteOperation = getCompletedInstantsDuringCurrentWriteOperation(table.getMetaClient(), pendingInstants); //找出本次写操作过程中完成的Instants ConflictResolutionStrategy resolutionStrategy = config.getWriteConflictResolutionStrategy(); Stream<HoodieInstant> instantStream = Stream.concat(resolutionStrategy.getCandidateInstants(reloadActiveTimeline ? table.getMetaClient().reloadActiveTimeline() : table.getActiveTimeline(), currentTxnOwnerInstant.get(), lastCompletedTxnOwnerInstant), completedInstantsDuringCurrentWriteOperation); //加入更多可能冲突的instants final ConcurrentOperation thisOperation = new ConcurrentOperation(currentTxnOwnerInstant.get(), thisCommitMetadata.orElse(new HoodieCommitMetadata())); instantStream.forEach(instant -> { try { ConcurrentOperation otherOperation = new ConcurrentOperation(instant, table.getMetaClient()); if (resolutionStrategy.hasConflict(thisOperation, otherOperation)) { //是否冲突,看两个写操作涉及的文件,是否有交集 LOG.info("Conflict encountered between current instant = " + thisOperation + " and instant = " + otherOperation + ", attempting to resolve it..."); resolutionStrategy.resolveConflict(table, thisOperation, otherOperation); //发现conflict,抛异常,当前写入失败 } } catch (IOException io) { throw new HoodieWriteConflictException("Unable to resolve conflict, if present", io); } }); LOG.info("Successfully resolved conflicts, if any"); return thisOperation.getCommitMetadataOption(); } return thisCommitMetadata; }
commit
protected void commit(Option<Map<String, String>> extraMetadata, HoodieWriteMetadata<List<WriteStatus>> result, List<HoodieWriteStat> writeStats) { String actionType = getCommitActionType(); LOG.info("Committing " + instantTime + ", action Type " + actionType); result.setCommitted(true); result.setWriteStats(writeStats); // Finalize write finalizeWrite(instantTime, writeStats, result); try { HoodieActiveTimeline activeTimeline = table.getActiveTimeline(); HoodieCommitMetadata metadata = result.getCommitMetadata().get(); writeTableMetadata(metadata, actionType); //写入meta activeTimeline.saveAsComplete(new HoodieInstant(true, getCommitActionType(), instantTime), Option.of(metadata.toJsonString().getBytes(StandardCharsets.UTF_8))); //将当前instant的state变成complete LOG.info("Committed " + instantTime); result.setCommitMetadata(Option.of(metadata)); } catch (IOException e) { throw new HoodieCommitException("Failed to complete commit " + config.getBasePath() + " at time " + instantTime, e); } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号