
Hudi Concepts
和Hadoop比,增加两个功能,
更新和删除
delta,变更流
Apache Hudi (pronounced “Hudi”) provides the following streaming primitives over hadoop compatible storages
- Update/Delete Records (how do I change records in a table?)
- Change Streams (how do I fetch records that changed?)
Timeline
提出Timeline和Instant的概念,
Instant,瞬间,即Timeline上的一个点
Instant,由3部分组成,action,time,state
At its core, Hudi maintains a timeline of all actions performed on the table at different instants of time that helps provide instantaneous views of the table, while also efficiently supporting retrieval of data in the order of arrival. A Hudi instant consists of the following components
Instant action: Type of action performed on the tableInstant time: Instant time is typically a timestamp (e.g: 20190117010349), which monotonically increases in the order of action's begin time.state: current state of the instant
Hudi guarantees that the actions performed on the timeline are atomic & timeline consistent based on the instant time.
Key actions performed include
COMMITS- A commit denotes an atomic write of a batch of records into a table.CLEANS- Background activity that gets rid of older versions of files in the table, that are no longer needed.DELTA_COMMIT- A delta commit refers to an atomic write of a batch of records into a MergeOnRead type table, where some/all of the data could be just written to delta logs.COMPACTION- Background activity to reconcile differential data structures within Hudi e.g: moving updates from row based log files to columnar formats. Internally, compaction manifests as a special commit on the timelineROLLBACK- Indicates that a commit/delta commit was unsuccessful & rolled back, removing any partial files produced during such a writeSAVEPOINT- Marks certain file groups as "saved", such that cleaner will not delete them. It helps restore the table to a point on the timeline, in case of disaster/data recovery scenarios. SavePoint不会被clean,作为归档
Any given instant can be in one of the following states
REQUESTED- Denotes an action has been scheduled, but has not initiatedINFLIGHT- Denotes that the action is currently being performedCOMPLETED- Denotes completion of an action on the timeline
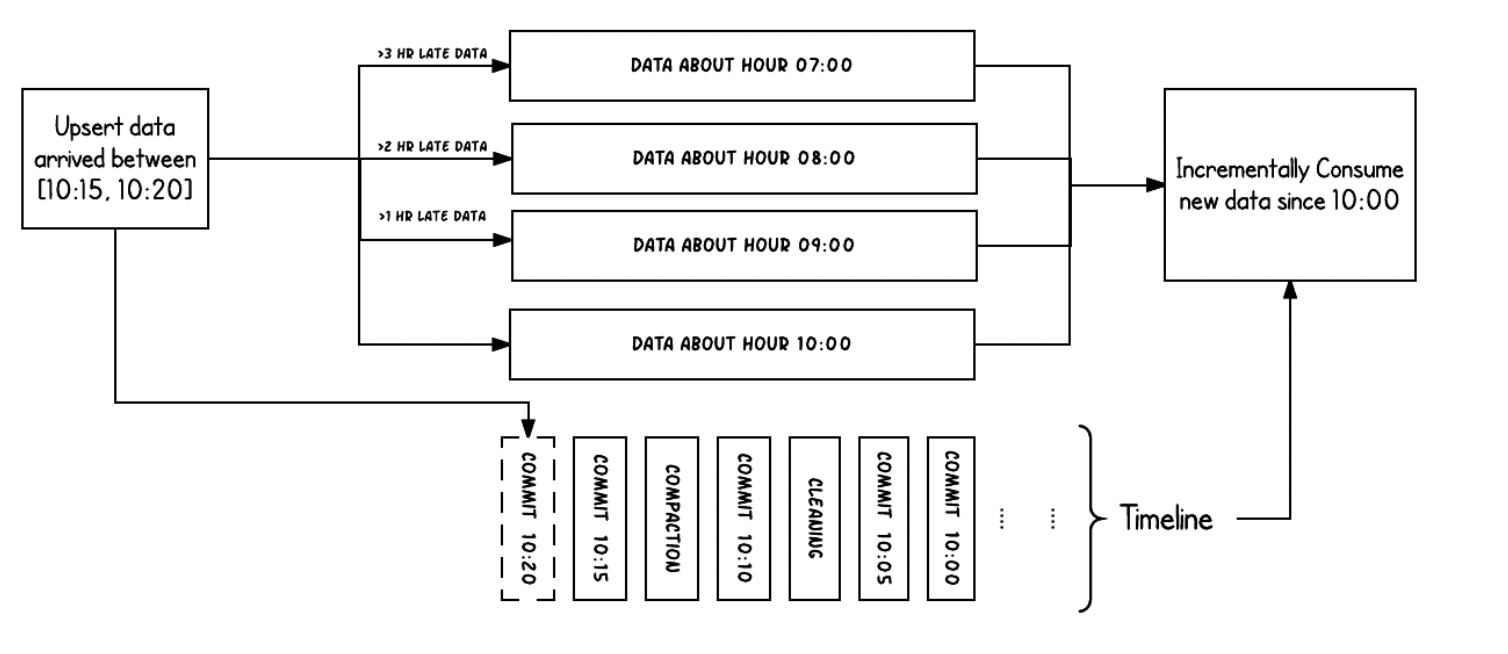
到达时间和event time
10:15到10:20到达的数据,event time的时间跨度是从7点到10点
所以如果没有记录下delta,那么做增量更新只能全部重新scan从7点到10点所有数据
但是如果有delta stream,就可以直接拿到更新的数据
File management
文件组织分两层,basepath和partitionpath
file groups,代表一个文件,唯一file id标识
group中包含多个slices,每个slice代表一次compaction,理论只需要保存最新的slices就可以,但是MVCC,还是要保留多个
slice,由一个basefile和多个delta logs组成
Hudi organizes a table into a directory structure under a basepath on DFS.
Table is broken up into partitions, which are folders containing data files for that partition, very similar to Hive tables.
Each partition is uniquely identified by its partitionpath, which is relative to the basepath.
Within each partition, files are organized into file groups, uniquely identified by a file id.
Each file group contains several file slices, where each slice contains a base file (*.parquet) produced at a certain commit/compaction instant time,
along with set of log files (*.log.*) that contain inserts/updates to the base file since the base file was produced.
Hudi adopts a MVCC design, where compaction action merges logs and base files to produce new file slices and cleaning action gets rid of unused/older file slices to reclaim space on DFS.
Table Types & Queries
两种类型的Table,
Merge On Read,就是常用的,由basefile和delta log组成
Copy On Write,可以理解成,每次commit都做compact,所以写放大很大,但是对读友好
3种查询方式,
Snapshot和Incremental都比较好理解,Read Optimized其实就是不读delta,只读base,这样牺牲一些数据准确性,来提升读取性能
Hudi table types define how data is indexed & laid out on the DFS and how the above primitives and timeline activities
are implemented on top of such organization (i.e how data is written).
In turn, query types define how the underlying data is exposed to the queries (i.e how data is read).
| Table Type | Supported Query types |
|---|---|
| Copy On Write | Snapshot Queries + Incremental Queries |
| Merge On Read | Snapshot Queries + Incremental Queries + Read Optimized Queries |
Table Types
Hudi supports the following table types.
- Copy On Write : Stores data using exclusively columnar file formats (e.g parquet). Updates simply version & rewrite the files by performing a synchronous merge during write.
- Merge On Read : Stores data using a combination of columnar (e.g parquet) + row based (e.g avro) file formats. Updates are logged to delta files & later compacted to produce new versions of columnar files synchronously or asynchronously.
File slices in Copy-On-Write table only contain the base/columnar file and each commit produces new versions of base files.
In other words, we implicitly compact on every commit, such that only columnar data exists.
As a result, the write amplification (number of bytes written for 1 byte of incoming data) is much higher, where read amplification is zero.
This is a much desired property for analytical workloads, which is predominantly read-heavy.
Query types
Hudi supports the following query types
- Snapshot Queries : Queries see the latest snapshot of the table as of a given commit or compaction action.
In case of merge on read table, it exposes near-real time data(few mins) by merging the base and delta files of the latest file slice on-the-fly.
For copy on write table, it provides a drop-in replacement for existing parquet tables, while providing upsert/delete and other write side features. - Incremental Queries : Queries only see new data written to the table, since a given commit/compaction.
This effectively provides change streams to enable incremental data pipelines. - Read Optimized Queries : Queries see the latest snapshot of table as of a given commit/compaction action.
Exposes only the base/columnar files in latest file slices and guarantees the same columnar query performance compared to a non-hudi columnar table.
Index
record key和file id的对应关系,一旦形成不会改变
Hudi provides efficient upserts, by mapping a given hoodie key (record key + partition path) consistently to a file id, via an indexing mechanism.
This mapping between record key and file group/file id, never changes once the first version of a record has been written to a file.
In short, the mapped file group contains all versions of a group of records.

Currently, Hudi supports the following indexing options.
- Bloom Index (default): Employs bloom filters built out of the record keys, optionally also pruning candidate files using record key ranges.
- Simple Index: Performs a lean join of the incoming update/delete records against keys extracted from the table on storage.
- HBase Index: Manages the index mapping in an external Apache HBase table.
- Bring your own implementation: You can extend this public API to implement custom indexing.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号