
Readings in Streaming Database Systems系列笔记
The Future of SQL: Databases Meet Stream Processing
https://www.confluent.io/blog/databases-meet-stream-processing-the-future-of-sql/
首先时代的改变,导致SQL所面对的场景的改变,以前是静态数据,而当前更多是 data is always in motion,其实就是StreamingSQL的概念
再者,tables只是记录了current,静态数据,而logs可以记录动态数据,其实就是流表一体的概念,通过流可以回放出表
给个例子,
这个SQL就是流表一体,不光会返回静态数据,还会动态的emit新的数据

接着,提出
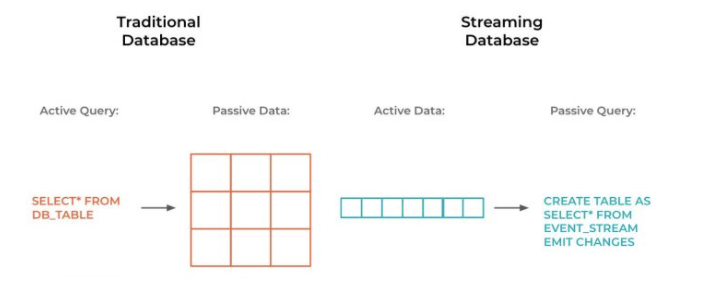
data-passive, query-active,可以认为是pull
data-active, query-passive,可以认为是push
这个是传统数据库和流式数据库最大的不同
pull有个问题,当数据量越来越大的时候,每次都全量去检索,效率比较低
也就是说对于delta数据,没有一个有效的方式
我突然觉得对于lambda架构的理解又加深了,一个emit changes,就是一个lambda架构的体现
pull更适合静态的全量数据,因为有强索引,不需要扫描所有数据
而push流式处理更适合解决delta的问题
对于流式数据库的一个问题,流式数据流过就没了
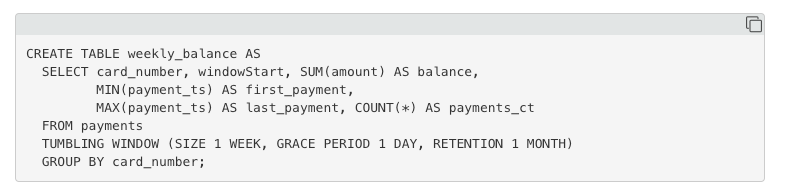
如果把查询关了,再查又需要扫一遍数据,这个太费,所有自然的想法是persistence,也就是物化视图
有物化视图,这里实现可以是一个kafka的topic或是一个database,其他的查询就可以直接读到,就可以形成topology

流式数据库的扩展语法
首先是窗口,dataflow模型,熟悉Flink的无需多言
Join
这块分为两块,
stream-stream joins
这块没啥好说的,注意CEP场景

stream-table joins
这块反而更有意思一些,
其实就是维表问题,而且还是一个拉链表问题,不是一个静态维表
所以底层实现,应该和stream-stream joins没有区别
如何处理late数据?丢弃?

同时支持大量的connector,

4 Key Design Principles and Guarantees of Streaming Databases

Lambda架构在结合实时和batch的时候会产生不精确性,
当前他这样讲是基于Linkedin提出的Kappa架构,基于Kafka可以低成本的对于全量数据的回放
他底下的两点的问题,
1. 如果对于真正的海量数据,Kappa架构也不好用
2. 高并行独立或轻量协调的运行,自动failover,但是对于有全局状态的情况怎解决?
4个原则
第一条,自动恢复,尤其是对于有状态的任务

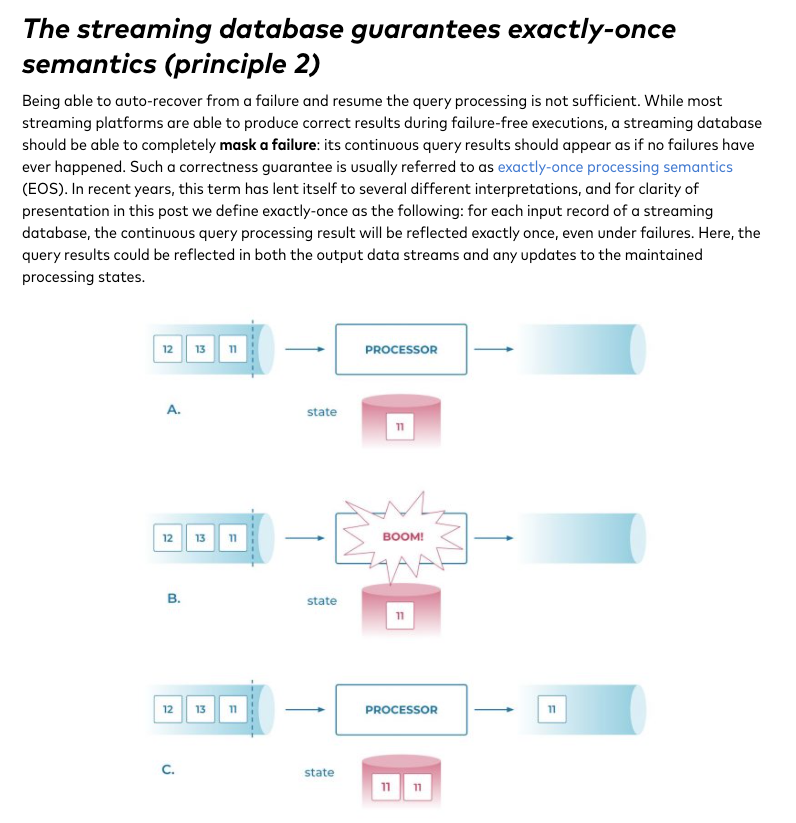
第二条,Exactly-once
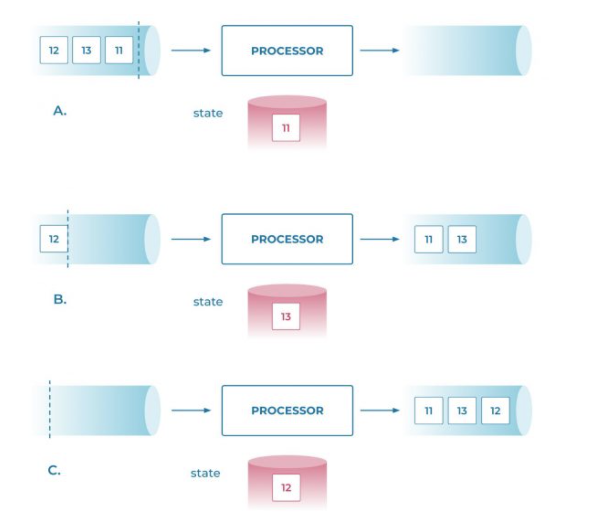
第三条,对乱序的处理

第四条,查询结果的一致性

下面说下confluent是如何用 “A persistent log-based approach” 保障上面4条原则的
0.11开始kafka开始支持事务写,保障同时写到多个topic的log的原子性

Exactly Once
把state,看成一个changelog topic,所以,只需要保证data topic和changelog topic事务写就可以保证

完整性保证
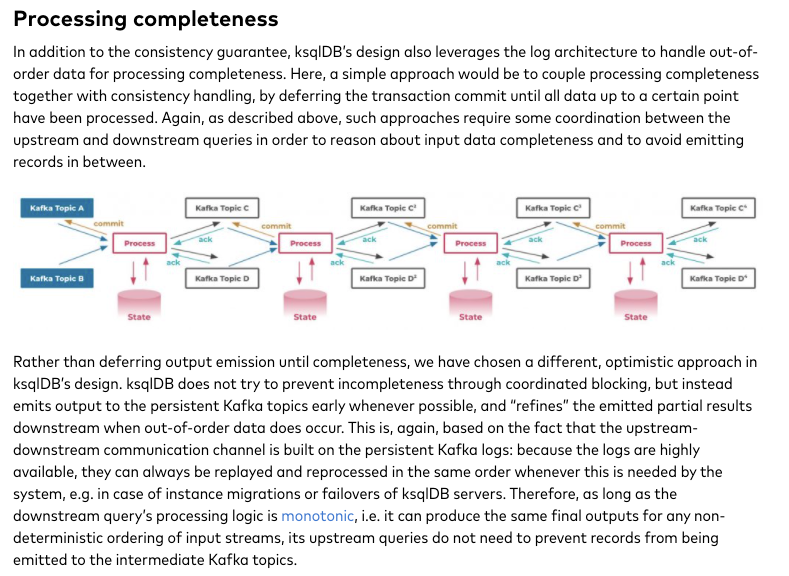
对于乱序,或者聚合时间很长这种,是不是要等到所有数据到到期了再emit
答案肯定是否定,dataflow论文里面对这个分析的已经比较清楚
这里的方案是,先emit,后面有乱序数据来的时候,refine并再次emit
不同他也说了,这个要求downstream查询的处理逻辑是单调的,这个假设不一定成立
对于KSqlDB这种最终一致性,如果要保证更强的一致性,怎么搞
如图中,如何保证KsqlDB和OLTP查询的一致性
两种方式,传统就是写OLTP和KsqlDB同一个事务
一般的方式,也是Ksql的方式,就是限制读


 浙公网安备 33010602011771号
浙公网安备 33010602011771号