
K8S权威指南摘要
Master


Node

RC,Replication Controller


Replica Set

Deployment

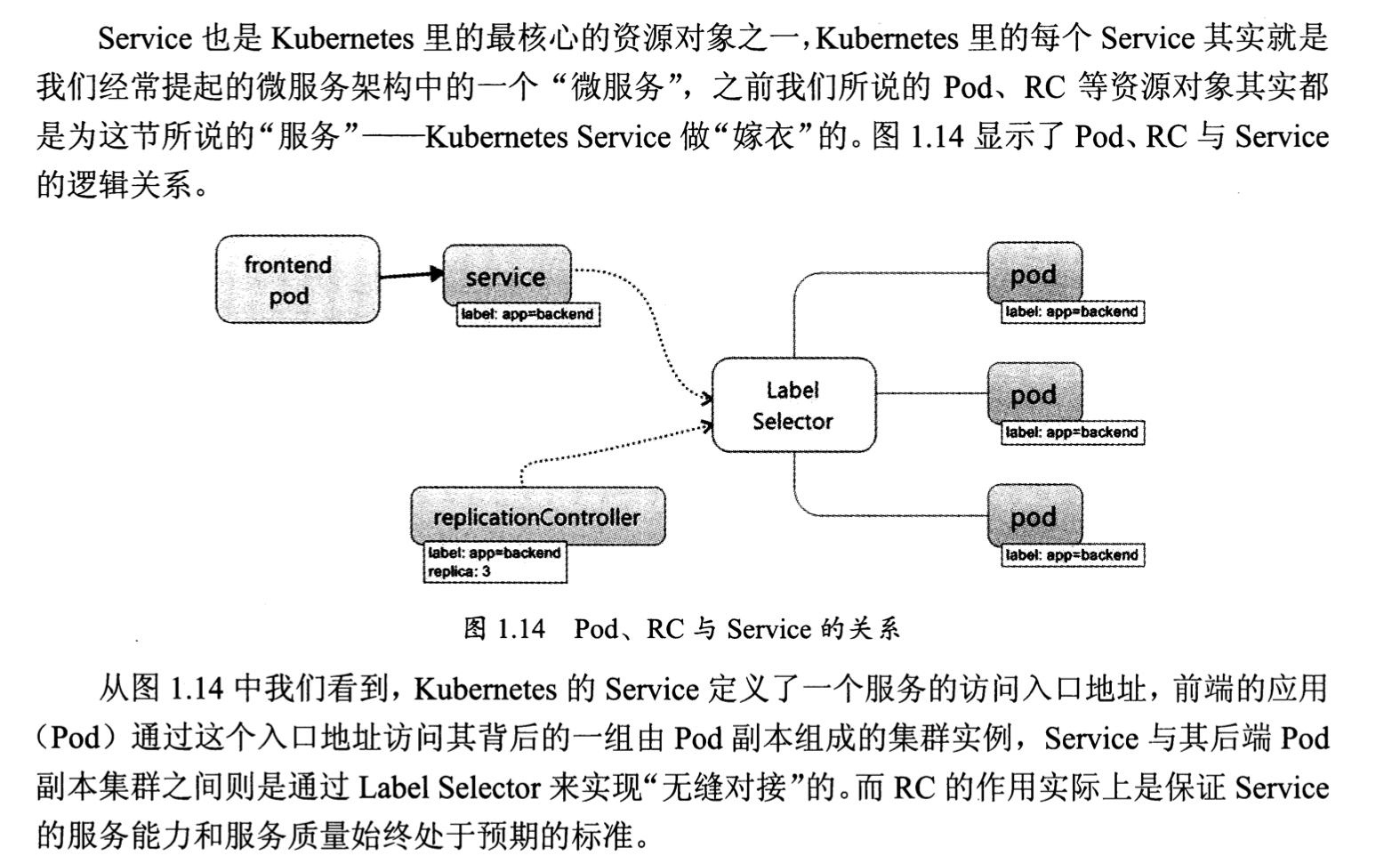
Service



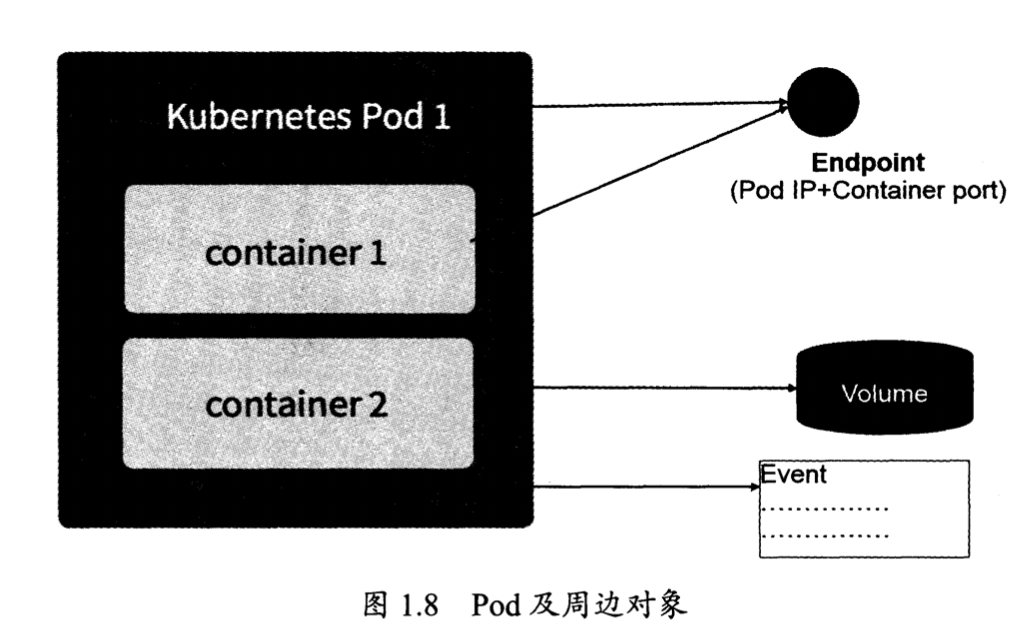
Pod

Lable

Annotation

Namespace

服务发现

网络IP


采用NodePort,对外暴露service,

kubelet

kube-proxy

Operator
纯转载,这个对于operator解释的比较清楚,
k8s operator的开发感悟
k8s的文档中本身没有operator这个词,operator实质是指:用户注册自己自定义的Custom Resource Definition,然后创建对应的资源实例(称为Custom Resource,简称CR),而后通过自己编写Controller来不断地检测当前k8s中所定义的CR的状态,如果状态和预期不一致,则调整。Controller具体做的事就是通过调用k8s api server的客户端,根据比较预期的状态和实际的状态,来对相应的资源进行 增,删,改。
举个例子,deployment中的replica数量是3,意味着pod的数量必须维持在3,多了,就去除,少了,就创建。由于deployment是k8s内置的资源,k8s本身就有内置的controller来维护deployment的状态。如果自己要创建一个新的逻辑,那么就创建新的CRD和controller,来创建和维护对应的deployment,service之类的服务。
开发自己的k8s的controller的好处是什么?现在一般部署k8s上自家的代码,几乎都是stateless,也就是说,对应的pod崩了之后,在重启一个就行,吞吐上不来的时候,横向增加pod数量就行。但是如果代码的逻辑需要维护一个状态(比如当前消息读取的offset),怎么办?pod崩了之后,如何恢复状态?可以上wal,上zookeeper,甚至k8s自身的etcd,如何自动化这部分“恢复的逻辑”?就是controller可以做的事儿,其实你用ansible等脚本也可以做,只是operator给你提供了一个开发友好的方式。你可以测试,部署,发布,一切都用go写,而不是在脚本里挣扎。还有就是用go自己写如何扩展伸缩。
这个Controller可以运行在k8s集群里,也可以是另外一个地方,本质就是一个使用了k8s客户端的小程序。
这里的开发逻辑是基于pull,而不是push,也就是说k8s的api server不会主动的发送事件给controller,而是k8s的go的client不断地‘拉’消息来获取最新的集群状态。这个‘拉’的方式的效率低,需要不断地get状态,这个肯定被考虑了,go的client内置就有一个队列来缓存事件消息,controller的逻辑就只需从队列中取消息处理即可。
https://engineering.bitnami.com/articles/a-deep-dive-into-kubernetes-controllers.html
https://engineering.bitnami.com/articles/kubewatch-an-example-of-kubernetes-custom-controller.html 这两篇文章就清楚的展示了go的client的内部工作原理。
教程
具体的开发主要是使用controller-runtime和k8s api的Go库。
可以自己写,也可以使用框架:kubebuilder或operator-sdk
https://book-v1.book.kubebuilder.io/ 虽然这个教程是v1的,但是我个人认为是最好的入门材料
https://sdk.operatorframework.io/ https://github.com/kubernetes-sigs/controller-runtime 两者要结合一起看
注意的点
创建CRD的时候,最好要设置owner,这样删除CRD的时候,其附带的deployment等资源,也会被自动删除。
CRD的删除事件是通过监测metadata中的deletionTimestamp域,如果deletionTimestamp不为空,那么说明这个资源被删除了(其对应的k8s内部的资源,比如service等也会被自动删除),但是如果需要删除一些外部的资源,比如数据库的一些数据,那么可以通过设置CRD的Finalizer域,一般情况下,Finalizer域为null,k8s看到后就直接把资源删除了,但是如果Finalizer域不为空,那么k8s就不会删除资源,而是等待,知道我们的controller把外部的资源删了,并且把Finalizer设置为空,k8s才会删除资源。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号