Calcite分析 -- TopDownRuleDriver
Calcite Version:1.26.0
Debug
TopDownOptTest, 加入
@Test void testMY() {
final String sql = "select mgr, count(*) from sales.emp\n"
+ "group by mgr order by mgr desc nulls last limit 5";
Query.create(sql).check();
}
RelOptTestBase.checkPlanning,会调用核心优化过程,
planner.setRoot(relBefore);
RelNode r = planner.findBestExp();
Graphviz,
StringWriter sw = new StringWriter();
final PrintWriter pw = new PrintWriter(sw);
Dumpers.dumpGraphviz(this, pw);
static void dumpGraphviz(VolcanoPlanner planner, PrintWriter pw)
本身逻辑都是基于task栈,
所以只要了解有哪些task,和其中的状态机图,就了解其运行的方式,

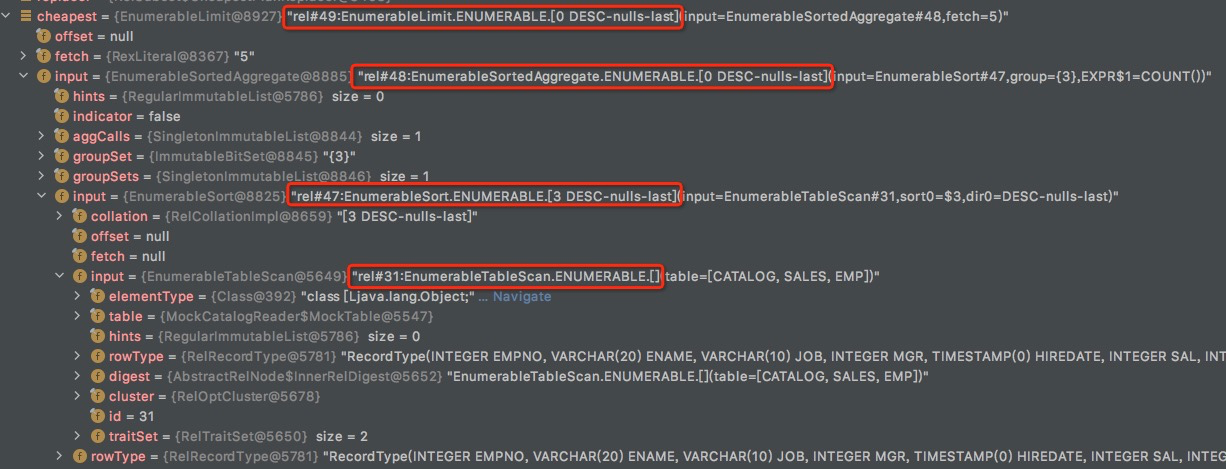
执行的SQL,"select mgr, count(*) from sales.emp group by mgr order by mgr desc nulls last limit 5"
当前planner的情况,
4个RelSet,对应于上面SQL的4个算子,sort,aggre,project,tablescan
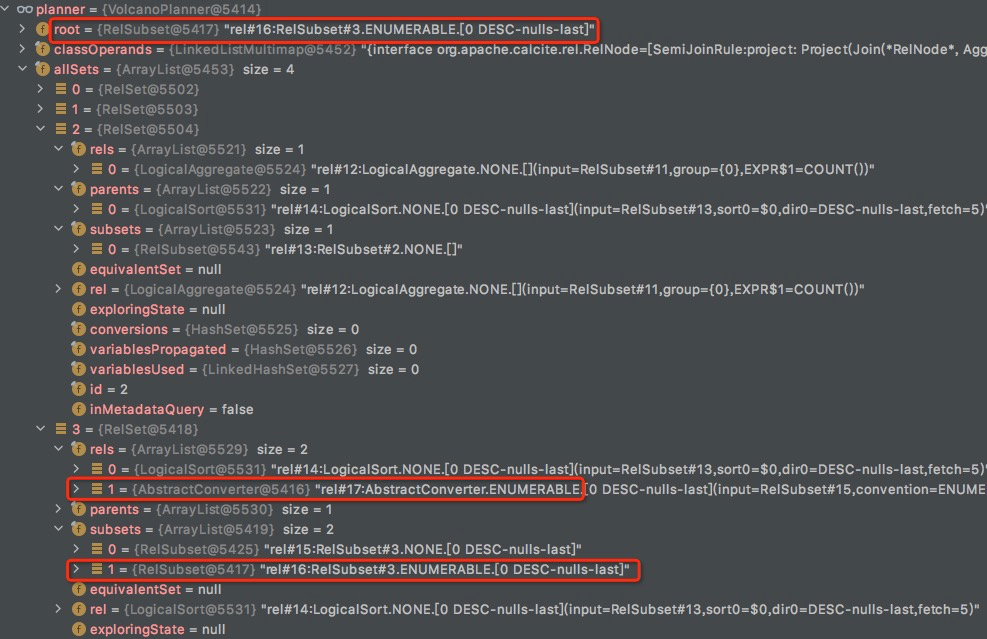
root是RelSubset#3,并且已经提前将convention转化为Enumerable,为了满足这个convention,所以给RelSet增加一个parent,AbstractConverter
从Root开始,
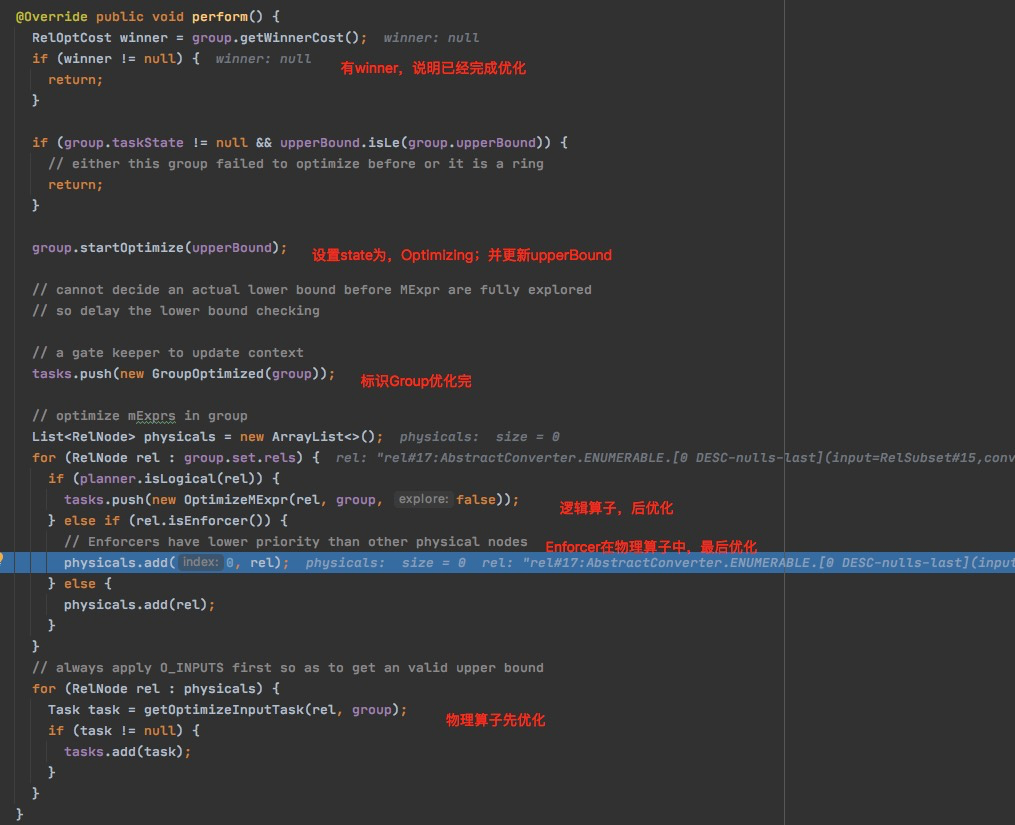
// Starting from the root's OptimizeGroup task.
tasks.push(new OptimizeGroup(planner.root, planner.infCost));
OptimizeGroup
优化什么?优化group是对于,group所在的Relset的Rels中的Relnode进行优化
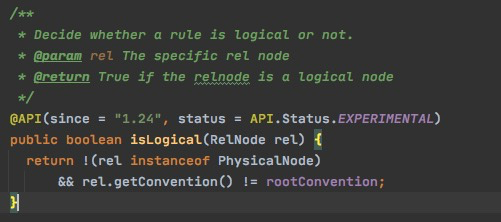
区分逻辑算子和物理算子,
逻辑算子,非物理节点,并且convention不等于rootConvention;注意并不是名字叫logical就是逻辑,要看convention
针对,逻辑算子和物理算子所生成的task是不同的
看回这个例子,这时root所在的Relset有两个Relnode,
logicalSort是逻辑的
AbstractConverter是物理的,并且是enforcer,enforcer是要放在物理算子最后进行优化,我的理解这个选项就是为了converter
所以最终生成的tasks,注意这里OptimizeMExpr的explore是false
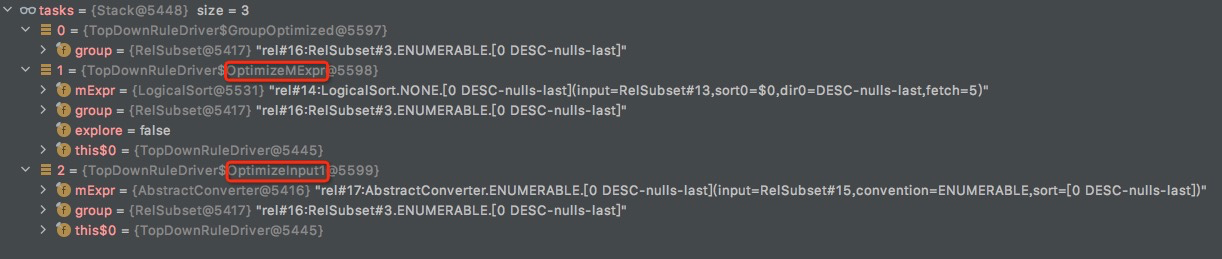
getOptimizeInputTask
在OptimizeGroup似乎,对所有的RelNodes都进行优化
但是对于物理算子,这里其实还是要匹配Traits的,可以看到如果traits不匹配,那么要先passthrough,也就是把Rel的input的traits进行convert后,生成新的passThroughRel,再去OptimizeInput
4种case,
- 如果rel和group的traits不相匹配,先convert生成pass through的Relnode
- 如果convert失败,passThroughRel=null,那么不生成task
- 如果成功继续,
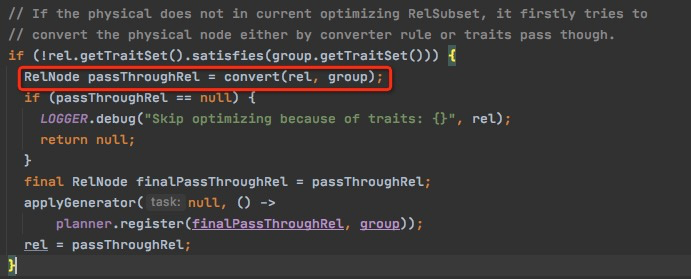
- 如果rel的所有input已经完成优化,那么只需要生成DeriveTrait Task;因为OptimizeInput的目的就是继续优化input group

- 根据input的数目,选择相应的函数,

OptimizeInput1
对于物理算子,继续对input进行OptimizeGroup;
在OptimizeGroup前,先push两个task,也就是说,在OptimizeGroup任务结束后,需要检查以下两点
- CheckInput任务,mExpr的input是否改变,如果变了,需要重新调度优化task
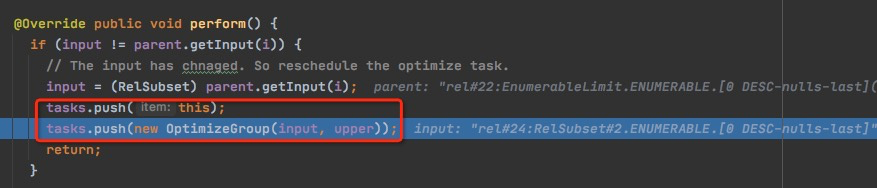
- DeriveTrait任务,用到再说
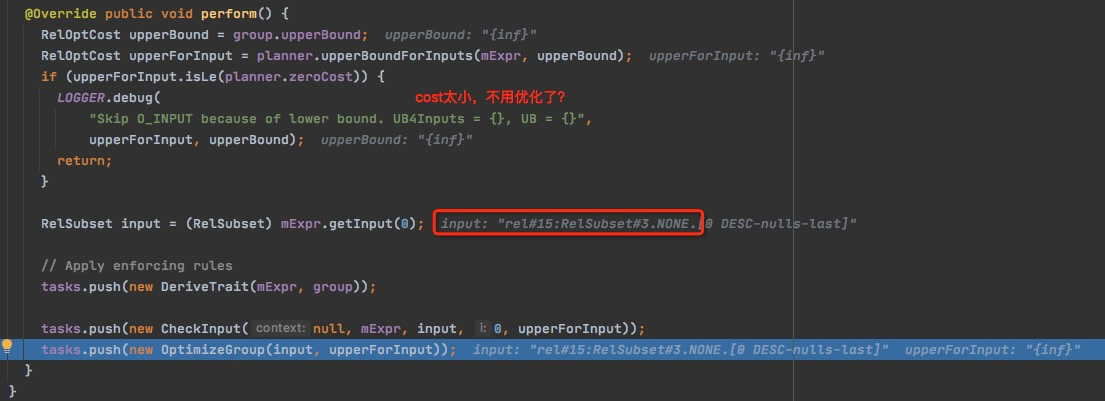
所以这里是,
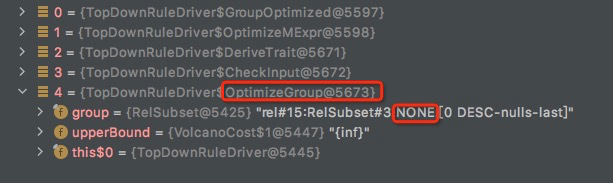
下一步继续优化,rel#15:RelSubset#3.NONE.[0 DESC-nulls-last]
这个和root同一个RelSet,所以包含的Relnodes是一样的,
所以也会生成对于logicalSort的优化,但是属于不同的group,
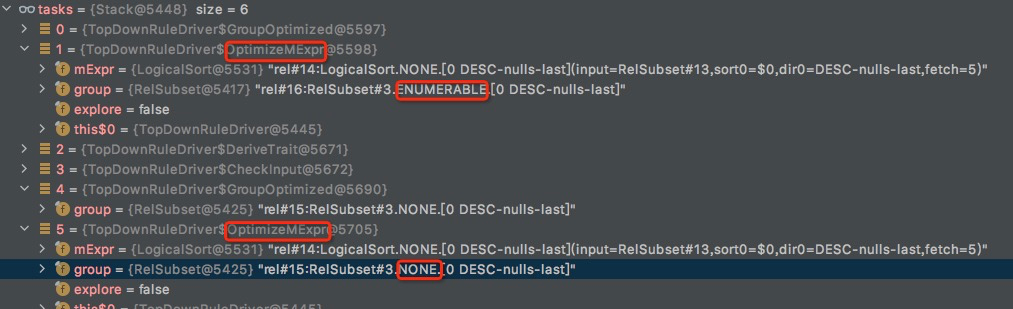
OptimizeMExpr
对于逻辑算子。只有对于逻辑算子才会applyRules;
这个task,目的就是递归topdown,在各个逻辑算子上进行ApplyRules
OptimizeMExpr-> ApplyRules-> ExploreInput-> OptimizeMExpr
(这里explore是false,由于这个OptimizeMExpr是从OptimizeGroup产生的)
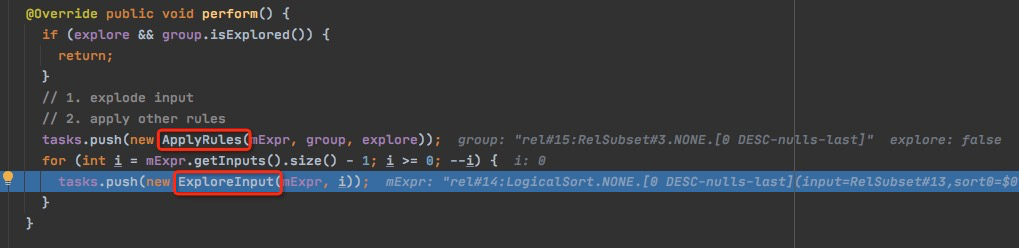
在rel#15:RelSubset#3.NONE.[0 DESC-nulls-last]执行的结果,
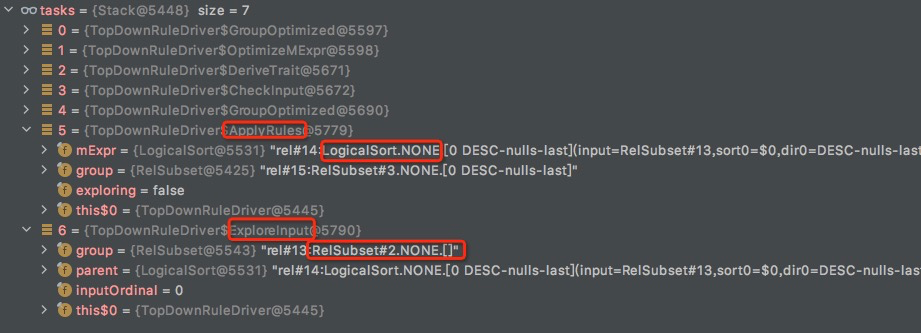
ExploreInput
和OptimizeGroup对等的作用,也是优化group,差别是这里只处理group.set.rels中的逻辑算子
还有一个很容易被忽略的细节,这里explore的值,
如果是通过OptimizeGroup生成的OptimizeMExpr,explore=false
而通过ExploreInput生成的OptimizeMExpr,explore=true,
explore会影响applyRules的时候的rule的筛选,为true,只会apply TransformationRule
并且在开始会判断,group.explore,这个逻辑这样写是不合理的,会产生误解, 应该写group.set.explore
因为实际是判断的是set的属性,set.exploringState != null
exploreInput实际也是explore set.rels,所以只要有其他的subset已经做了,就没有必要做了
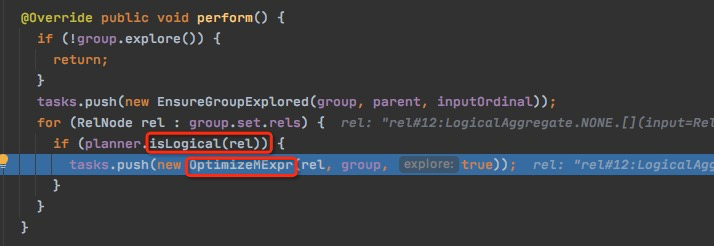
结果如下,

按照这个一直Topdown下去,形成一系列的applyRules,

到此为止,经过的路径
Root -> AbstractConventer -> RelSubset#3.NONE -> LogicalSort.NONE -> RelSubset#2.NONE ...... -> LogicalTableScan.NONE
只是逻辑算子的展开,还没有对plan做任何优化
下面开始ApplyRule的过程,开始真正的优化
ApplyRules
逻辑比较简单,把matches中相应的rule加上,

结果,只加上一条rule,

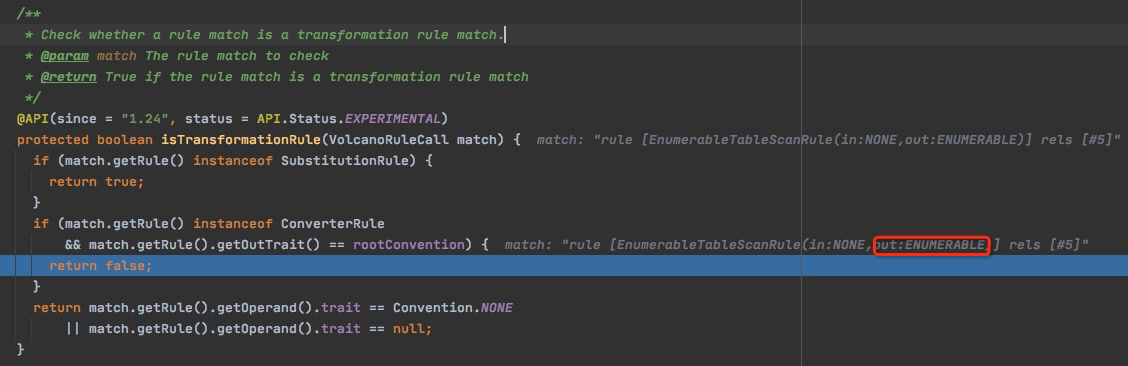
EnumerableTableScanRule为啥没有加上?
EnumerableTableScanRule是ConverterRule,但不是TransformationRule
为何对于ConverterRule,outTrait==rootConvention,就不是TransformationRule?这个只是用于转换输出的Convention,放后面做?
筛选的时候,有TransformationRule,但是不满足,不会pop,还继续留在ruleQueue里面
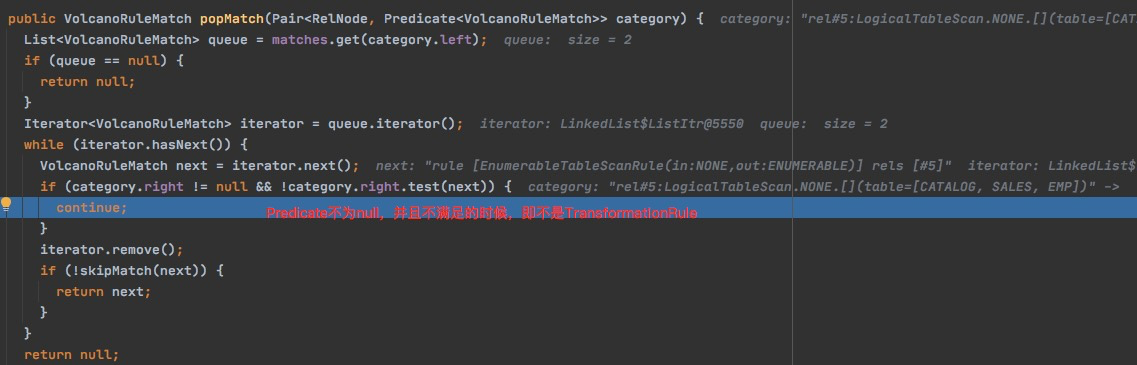
ApplyRule
就是调用Rule的onMatch

例子,
AggregateProjectMergeRule
逻辑算子的变化rule
实际就是将Aggre和Project进行merge成一个新的Aggre,可以看到新的Aggre的input就是原先project的input

transformTo
Rule最后都会调用transformTo,
这里的逻辑,主要是处理Rule所新产生的Relnode
主要的逻辑是,ensureRegistered,但是这里equivRel是原先的RelNode, 可以重用RelSet,
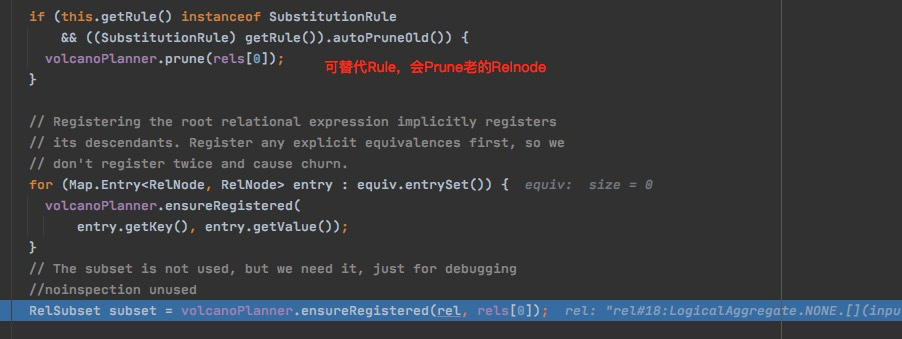
结果,rule生成新的RelNode被加入原先的Relset中,作为等价的关系算子;并且对于RelSet#0,多了一个parent

ruleDriver.onProduce
Rule生成新的RelNode,会调用addRelToSet
这里会对应新增加的Node,增加新的Task
- 逻辑算子,增加OptimizeMExpr task,

- 物理算子,增加OptimizeInput Task
有3种可能性,
- optimizingGroup不等于null,正常调用getOptimizeInputTask
- RelNode本身的subset在优化中
- pass through,但是pass through的subset和RelNode的traits相匹配
- optimizingGroup等于null,对于passThrough subset,调用getOptimizeInputTask成功
- addTask,这里task,可能是OptimizeInput,也可能是DeriveTrait
- optimizingGroup等于null,对于passThrough subset,调用getOptimizeInputTask返回null
-啥都不做
这里passThrough的逻辑的case,参考Calcite分析 -- ConverterRule
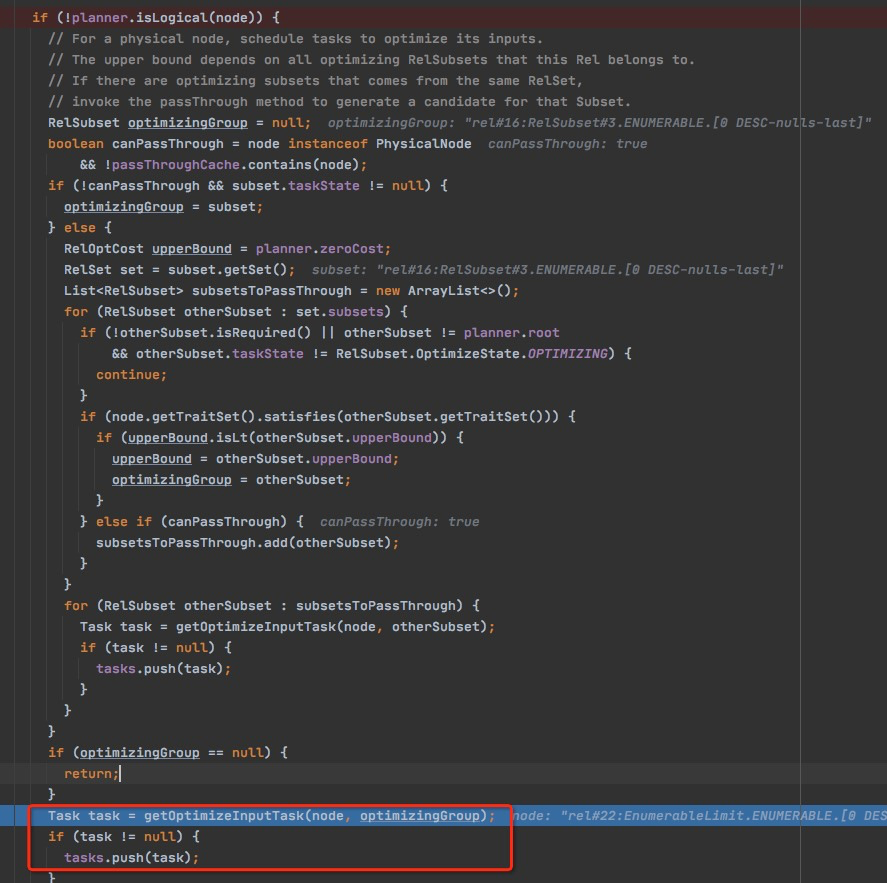
EnsureGroupExplored
主要是设置group完成Explored

经过一系列的apply rules,所有针对rel#15:RelSubset#3.NONE.[0 DESC-nulls-last]的逻辑优化已经结束,
剩下的是一些EnumerableRule,包含在ruleQueue里面没有被pop的,因为之前的applyRules中的explore一直是true
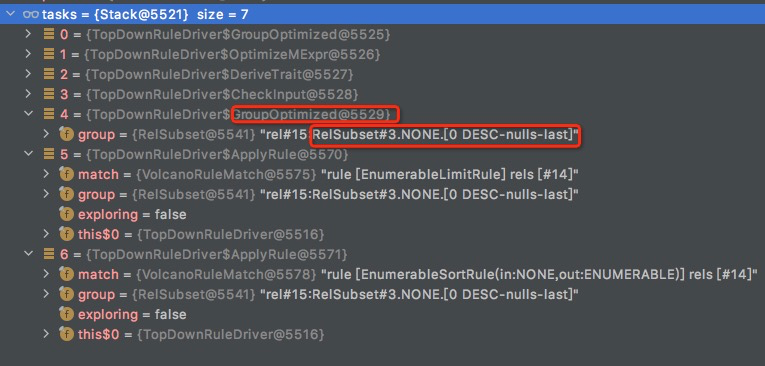
其中EnumerableLimitRule(具体过程,参考Calcite分析 -- ConverterRule),会生成一个一个新的logicalSort,对后续优化有较大的影响
我理解原因是,在物理实现的时候,sort和limit是分开的,所以带limit的logicalSort需要拆成两个算子,
生成的新的sort算子,通过convert,生成带convention的subset,logicalSort的convention并不会变,仍然是None
基于Sort算子,生成EnumerableLimit算子,这个算子在注册的时候,会和旧的Sort算子注册在一个RelSet中,
这里注意EnumerableLimit的input是rel#21:RelSubset#4.ENUMERABLE.[0 DESC-nulls-last]

同时在增加物理算子,rel#22:EnumerableLimit.ENUMERABLE.[0 DESC-nulls-last](input=RelSubset#21,fetch=5)
会触发增加新的Task,

总结一下上面的流程,
逻辑优化Topdown展开,Root -> AbstractConventer -> RelSubset#3.NONE -> LogicalSort.NONE -> RelSubset#2.NONE ...... -> LogicalTableScan.NONE
逻辑算子Bottomup优化,各层apply transformtionRule,
物理优化的TopDown展开,BottomUp到RelSubset#3.NONE,开始apply Enumerable Rule,
可以看下当前的matches里面,logical算子基本都还留一个EnumerableRule没有触发;
rel#14:LogicalSort.NONE,是因为已经触发EnumerableRule,生成了EnumerableLimit,所以size=0;rel#19:LogicalSort.NONE,刚生成,group还没优化
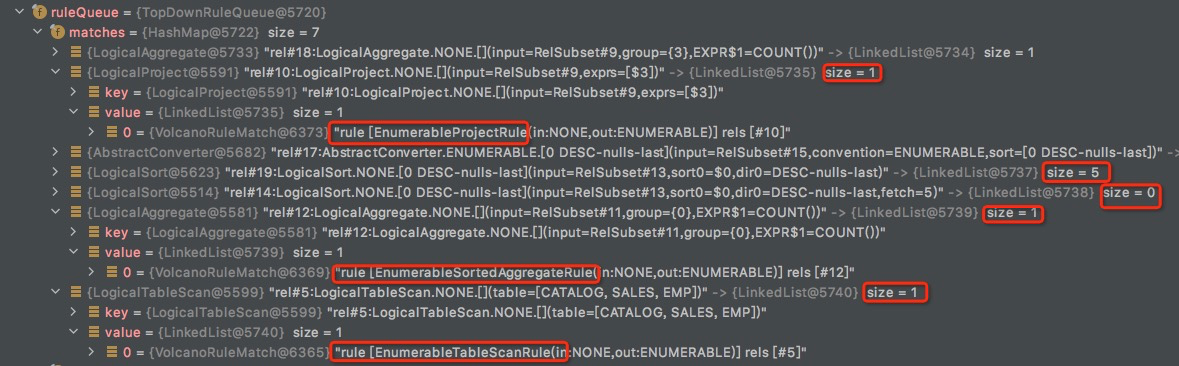
沿着EnumerableLimit的input,
OptimizeInput(rel#22) -> OptimizeGroup(rel#21) -> OptimizeMExpr -> ApplyRules -> Apply到上面size=5的logicalSort
其中有一个rule,是SortRemoveRule,过程,参考,Calcite分析 -- SortRemoveRule
SortRemove Rule中做了RelSet merge,这个过程中整个Relset#4和他的subset rel#21,在merge中被remove掉
并且这个操作会重新触发被merge到的RelSet,以及他的parent的RelSet的重新优化,直到Root
所以这里触发了重新优化Root的OptimizeGroup,其他的Group后面会连锁的被优化
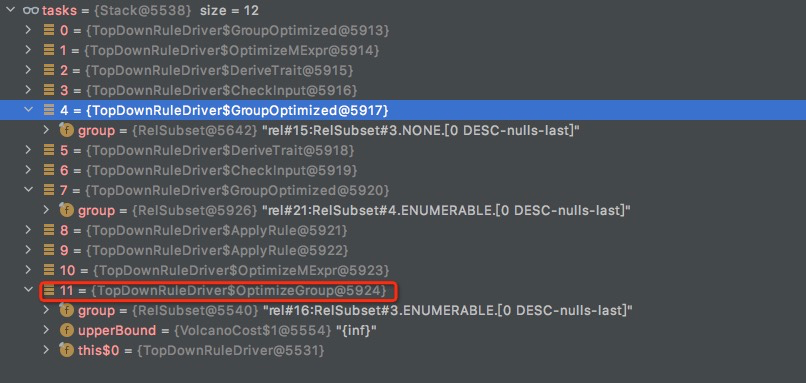
OptimizeGroup(rel#16:RelSubset#3.ENUMERABLE.[0 DESC-nulls-last])-> OptimizeInput (rel#22:EnumerableLimit.ENUMERABLE) -> OptimizeGroup(rel#24:RelSubset#2.ENUMERABLE)
虽然开始的时候就调用过OptimizeGroup(rel#16:RelSubset#3.ENUMERABLE),但是现在多了rel#22:EnumerableLimit,所以触发到RelSubset#2.ENUMERABLE的优化
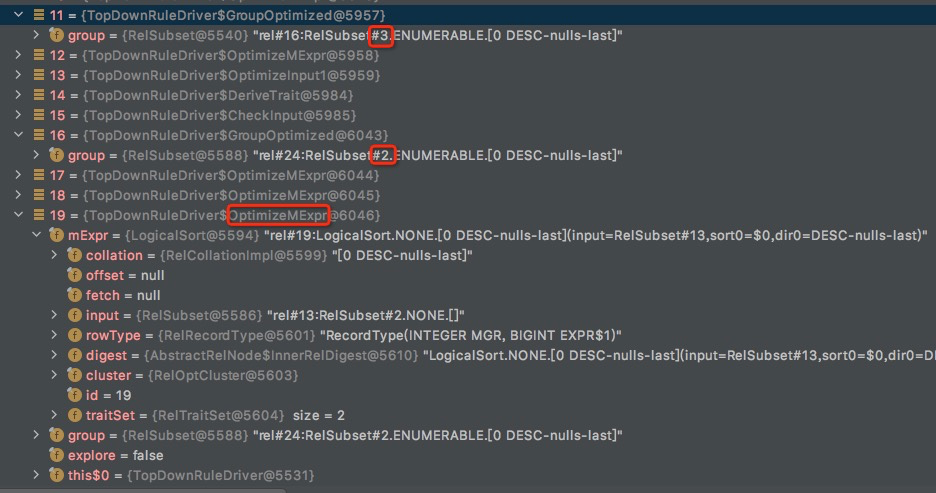
RelSubset#2.ENUMERABLE的优化,会产生3个OptimizeMExpr
但是当前RuleQueue里面只剩下EnumerableRule,没有逻辑优化rule可以触发,
所以OptimizeMExpr的作用,只能是apply MExpr所对应的EnumerableRule
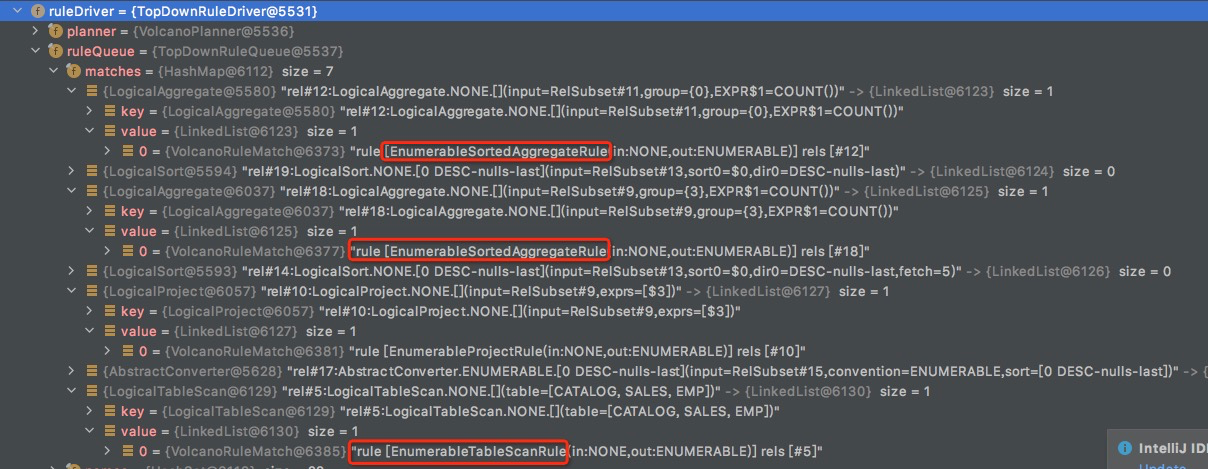
触发完EnumerableSortedAggregateRule后,具体过程参考,Calcite分析 -- ConverterRule
结果如下,
由于EnumerableSortedAggregateRule,中的addConverter,PassThrough,生成两个新的物理算子
从而触发了两个OptimizeInput task

rel#29:RelSubset#0.ENUMERABLE.[3 DESC-nulls-last]
从Task19 OptimizeInput触发到rel#29:RelSubset#0.ENUMERABLE.[3 DESC-nulls-last]的优化,

rel#29:RelSubset#0.ENUMERABLE.[3 DESC-nulls-last]优化触发EnumerableTableScanRule
生成一个物理算子和两个converter
之前在changeTraits时,结果只是增加一个subset,觉得好像没啥用,为啥不直接改RelNode的convention?
原来是增加的subset的required为true,后续在生成物理算子的时候,会触发conventer的生成
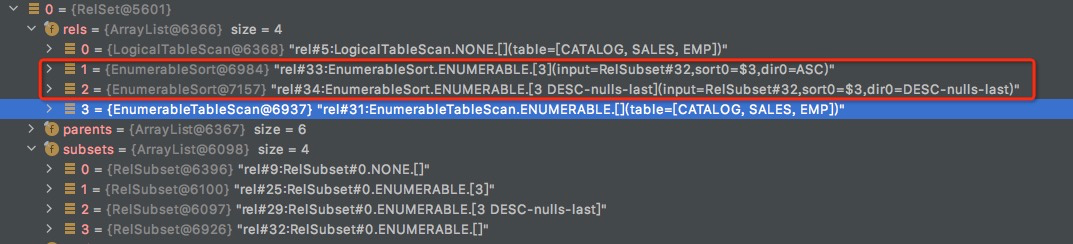
但在增加converter,调用addRelToSet的时候,触发driver.onProduce, 会走到pass through的逻辑,
比如对于,rel#33,

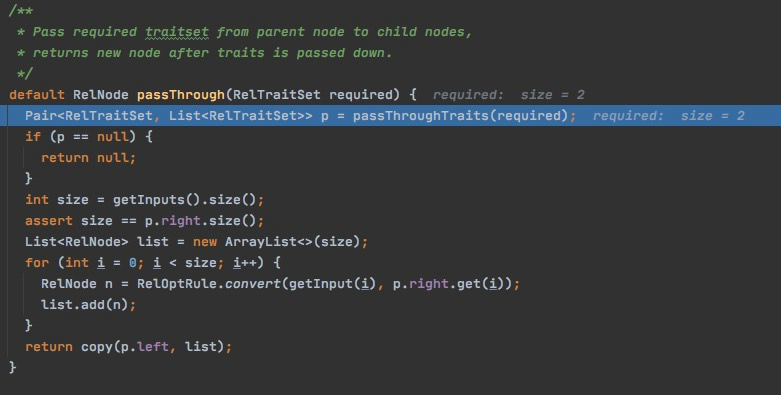
这里的passThroughTraits,大部分情况下返回null,
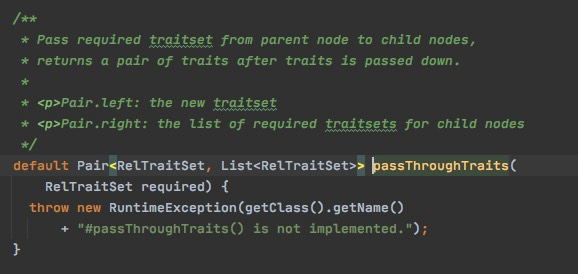
只有这些类实现了这个函数,

PassThrough的目的,是把required的traits,传递到RelNode的inputs,那么也不是什么算子都可以传递traits,
比如rel#33,是sort,那么input应该是没有经过sort的数据,所以这个traits是无法传递的;
比如EnumerableFilter,那么对于filter算子的input就应该保持traits一致。
所以这里PassThrough的RelNode的特点是,本身不会改变traits,所以才可以passThrough?
rel#34,也走到passThrough逻辑,不过34的traits本身就和rel#29:RelSubset#0.ENUMERABLE.[3 DESC-nulls-last]匹配,所以无需新生成passThroughRel,只是增加一个OptimizeInput

注册完converter,
继续加入物理算子,rel#31:EnumerableTableScan.ENUMERABLE.[](table=[CATALOG, SALES, EMP])
第一次有效的触发了subset的cost更新和propagate,参考Calcite分析 -- Cost
OptimizeInput(rel#34) -> OptimizeGroup(rel#32:RelSubset#0.ENUMERABLE.[])
到此rel#29:RelSubset#0.ENUMERABLE.[3 DESC-nulls-last]的优化完成.
OptimizeGroup(rel#24:RelSubset#2.ENUMERABLE -> OptimizeGroup(rel#29:RelSubset#0.ENUMERABLE.[3 DESC-nulls-last] -> OptimizeGroup(rel#32:RelSubset#0.ENUMERABLE.[])
继续优化,rel#24:RelSubset#2.ENUMERABLE
从Task18开始,

从Task18 OptimizeInput触发到rel#27:RelSubset#2.ENUMERABLE.[0]的优化
OptimizeGroup(rel#24:RelSubset#2.ENUMERABLE -> OptimizeGroup(rel#27:RelSubset#2.ENUMERABLE.[0] -> OptimizeGroup(rel#25:RelSubset#0.ENUMERABLE.[3]

在优化到rel#12,触发EnumerableSortedAggregateRule,参考前面的关于这个rule的分析,结果如下,
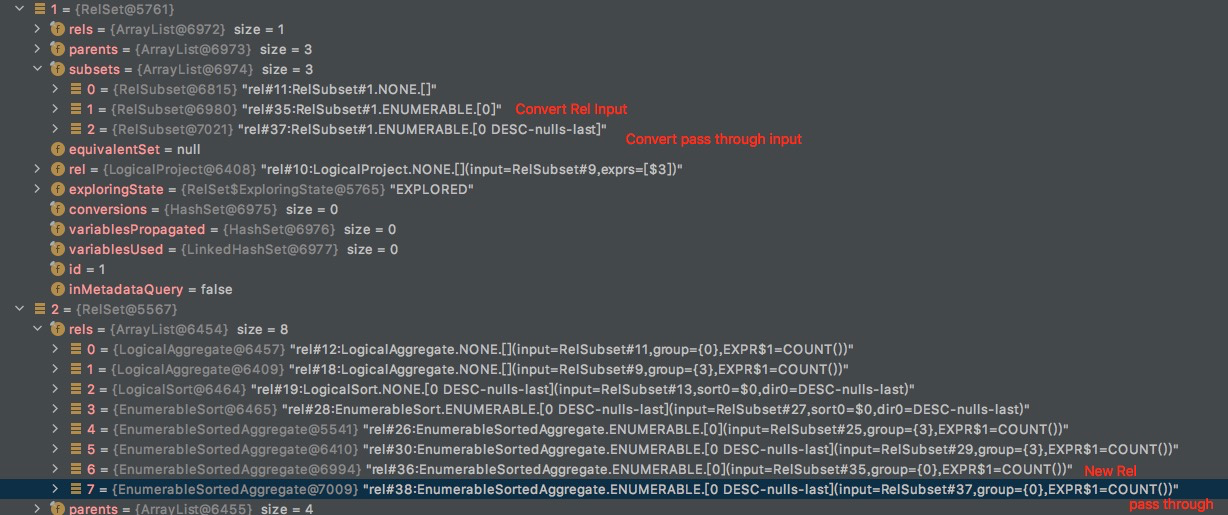
有Pass through,会对其触发OptimizeInput,
OptimizeGroup(rel#27:RelSubset#2.ENUMERABLE.[0] -> OptimizeGroup(rel#37:RelSubset#1.ENUMERABLE.[0 DESC-nulls-last]
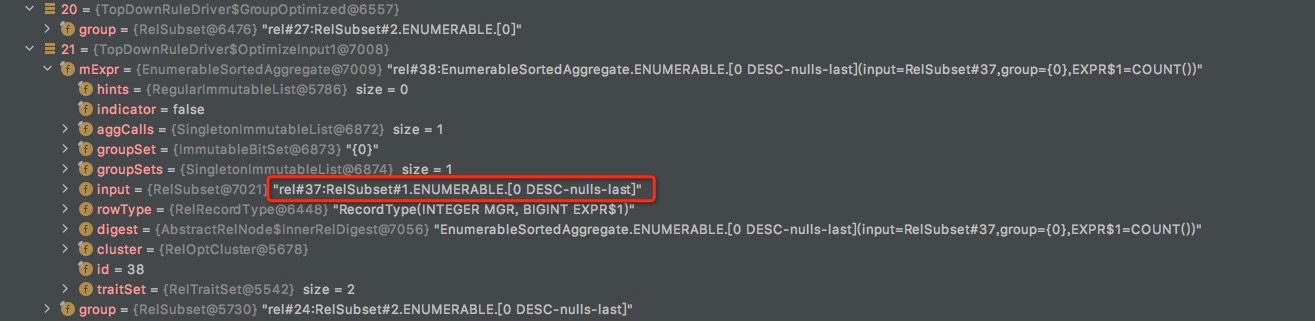
触发,EnumerableProjectRule

OptimizeInput,PassThroughRel
OptimizeGroup(rel#27:RelSubset#2.ENUMERABLE.[0] -> OptimizeGroup(rel#37:RelSubset#1.ENUMERABLE.[0 DESC-nulls-last] -> OptimizeGroup(rel#40:RelSubset#1.ENUMERABLE.[]

之后,一路到优化,到完成rel#24:RelSubset#2.ENUMERABLE
一路回退到Task13,OptimizeInput(rel#17:AbstractConverter.ENUMERABLE.[0 DESC-nulls-last](input=RelSubset#15,convention=ENUMERABLE,sort=[0 DESC-nulls-last]))
再次触发到rel#15的优化,
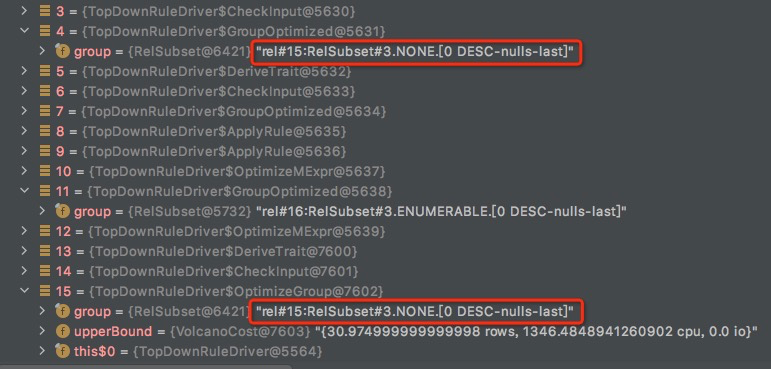
在DeriveTrait中触发,ExpandConversionRule
注释写的是,将AbstractConverter转换成一系列的converters,但是这里没有生成实际的converter

这样就完成rel#16:RelSubset#3.ENUMERABLE.[0 DESC-nulls-last]的优化
后面一路bottomup上去,直到完成所有节点的优化。
buildCheapestPlan
其实逻辑很简单,
从root,沿着input进行遍历,将subset,替换成best的RelNode
最终优化成3个算子,#47是converter