Spark SQL: Relational Data Processing in Spark (SIGMOD’15)
Introduction
Big data applications require a mix of processing techniques, data sources and storage formats.
The earliest systems designed for these workloads, such as MapReduce, gave users a powerful, but low-level, procedural programming interface.
Programming such systems was onerous(繁重的) and required manual optimization by the user to achieve high performance.
As a result, multiple new systems sought to provide a more productive user experience by offering relational interfaces to big data.
Systems like Pig, Hive, Dremel and Shark [29, 36, 25, 38] all take advantage of declarative queries to provide richer automatic optimizations.
用户偏向于使用declarative语言,SQL,但是SQL在某些场景下无法满足需求
所以SparkSQL的目的,就是结合relational和procedural;
达成这个目的,主要依靠两个,DataFrame API和Catalyst。
While the popularity of relational systems shows that users often prefer writing declarative queries, the relational approach is insufficient for many big data applications.
First, users want to perform ETL to and from various data sources that might be semior unstructured, requiring custom code.
Second, users want to perform advanced analytics, such as machine learning and graph processing, that are challenging to express in relational systems.
In practice, we have observed that most data pipelines would ideally be expressed with a combination of both relational queries and complex procedural algorithms.
Unfortunately, these two classes of systems—relational and procedural—have until now remained largely disjoint, forcing users to choose one paradigm or the other.
This paper describes our effort to combine both models in Spark SQL, a major new component in Apache Spark [39].
Spark SQL builds on our earlier SQL-on-Spark effort, called Shark.
Rather than forcing users to pick between a relational or a procedural API, however, Spark SQL lets users seamlessly intermix the two.
Spark SQL bridges the gap between the two models through two contributions.
First, Spark SQL provides a DataFrame API that can perform relational operations on both external data sources and Spark’s built-in distributed collections.
This API is similar to the widely used data frame concept in R [32], but evaluates operations lazily so that it can perform relational optimizations.
Second, to support the wide range of data sources and algorithms in big data, Spark SQL introduces a novel extensible optimizer called Catalyst.
Catalyst makes it easy to add data sources, optimization rules, and data types for domains such as machine learning.
The DataFrame API offers rich relational/procedural integration within Spark programs.
DataFrames are collections of structured records that can be manipulated using Spark’s procedural API, or using new relational APIs that allow richer optimizations.
They can be created directly from Spark’s built-in distributed collections of Java/Python objects, enabling relational processing in existing Spark programs.
Other Spark components, such as the machine learning library, take and produce DataFrames as well.
DataFrames are more convenient and more efficient than Spark’s procedural API in many common situations.
For example, they make it easy to compute multiple aggregates in one pass using a SQL statement, something that is difficult to express in traditional functional APIs.
They also automatically store data in a columnar format that is significantly more compact than Java/Python objects.
Finally, unlike existing data frame APIs in R and Python, DataFrame operations in Spark SQL go through a relational optimizer, Catalyst.
To support a wide variety of data sources and analytics workloads in Spark SQL, we designed an extensible query optimizer called Catalyst.
Catalyst uses features of the Scala programming language, such as pattern-matching, to express composable rules in a Turing-complete language.
It offers a general framework for transforming trees, which we use to perform analysis, planning, and runtime code generation.
Through this framework, Catalyst can also be extended with new data sources, including semi-structured data such as JSON and “smart” data stores to which one can push filters (e.g., HBase);
with user-defined functions; and with user-defined types for domains such as machine learning.
Functional languages are known to be well-suited for building compilers [37], so it is perhaps no surprise that they made it easy to build an extensible optimizer. 函数式语言在构建优化器上的优势
We indeed have found Catalyst effective in enabling us to quickly add capabilities to Spark SQL, and since its release we have seen external contributors easily add them as well.
Background and Goals
Spark Overview
Apache Spark is a general-purpose cluster computing engine with APIs in Scala, Java and Python and libraries for streaming, graph processing and machine learning [6].
Released in 2010, it is to our knowledge one of the most widely-used systems with a “language-integrated” API similar to DryadLINQ [20], and the most active open source project for big data processing.
Spark had over 400 contributors in 2014, and is packaged by multiple vendors.
Spark offers a functional programming API similar to other recent systems [20, 11], where users manipulate distributed collections called Resilient Distributed Datasets (RDDs) [39].
Each RDD is a collection of Java or Python objects partitioned across a cluster.
RDDs can be manipulated through operations like map, filter, and reduce, which take functions in the programming language and ship them to nodes on the cluster.
For example, the Scala code below counts lines starting with “ERROR” in a text file:
lines = spark.textFile("hdfs://...")
errors = lines.filter(s => s.contains("ERROR"))
println(errors.count())
Previous Relational Systems on Spark
Shark的3个问题,
首先是数据源,Shark是从Hive改的,所以只能查询存在Hive中的外部数据;
Shark只支持SQL string,无法兼容procedural;
Hive优化器难于扩展支持新的功能
Our first effort to build a relational interface on Spark was Shark [38],
which modified the Apache Hive system to run on Spark and implemented traditional RDBMS optimizations, such as columnar processing, over the Spark engine.
While Shark showed good performance and good opportunities for integration with Spark programs, it had three important challenges.
First, Shark could only be used to query external data stored in the Hive catalog,
and was thus not useful for relational queries on data inside a Spark program (e.g., on the errors RDD created manually above).
Second, the only way to call Shark from Spark programs was to put together a SQL string,
which is inconvenient and error-prone to work with in a modular program.
Finally, the Hive optimizer was tailored for MapReduce and difficult to extend, making it hard to build new features such as data types for machine learning or support for new data sources.
Goals for Spark SQL
With the experience from Shark, we wanted to extend relational processing to cover native RDDs in Spark and a much wider range
of data sources. We set the following goals for Spark SQL:
1. Support relational processing both within Spark programs (on native RDDs) and on external data sources using a programmer-friendly API. 支持内外部的数据结构
2. Provide high performance using established DBMS techniques. 利用DB的技术提供高性能
3. Easily support new data sources, including semi-structured data and external databases amenable to query federation. 半结构化和联邦查询
4. Enable extension with advanced analytics algorithms such as graph processing and machine learning. 支持ML
Programming Interface
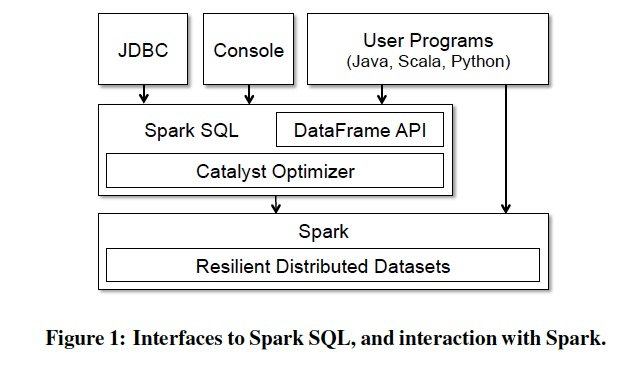
Spark SQL runs as a library on top of Spark, as shown in Figure 1.
It exposes SQL interfaces, which can be accessed through JDBC/ODBC or through a command-line console, as well as the DataFrame API integrated into Spark’s supported programming languages.
We start by covering the DataFrame API, which lets users intermix procedural and relational code.
However, advanced functions can also be exposed in SQL through UDFs, allowing them to be invoked, for example, by business intelligence tools.
We discuss UDFs in Section 3.7.
Catalyst Optimizer
To implement Spark SQL, we designed a new extensible optimizer, Catalyst, based on functional programming constructs in Scala.
Catalyst’s extensible design had two purposes.
First, we wanted to make it easy to add new optimization techniques and features to Spark SQL, Catalyst基于Scala语言,FP更适合优化器;想要让优化器更易于扩展新功能
especially to tackle various problems we were seeing specifically with “big data” (e.g., semistructured data and advanced analytics).
Second, we wanted to enable external developers to extend the optimizer—for example,
by adding data source specific rules that can push filtering or aggregation into external storage systems, or support for new data types.
Catalyst supports both rule-based and cost-based optimization. Catalyst同时支持rbo和cbo,基于scala的pattern-matching更容易编写rules
While extensible optimizers have been proposed in the past,
they have typically required a complex domain specific language to specify rules, and an “optimizer compiler” to translate the rules into executable code [17, 16].
This leads to a significant learning curve and maintenance burden.
In contrast, Catalyst uses standard features of the Scala programming language, such as pattern-matching [14],
to let developers use the full programming language while still making rules easy to specify.
Functional languages were designed in part to build compilers, so we found Scala well-suited to this task.
Nonetheless, Catalyst is, to our knowledge, the first production-quality query optimizer built on such a language.
At its core, Catalyst contains a general library for representing trees and applying rules to manipulate them.
On top of this framework, we have built libraries specific to relational query processing (e.g., expressions, logical query plans),
and several sets of rules that handle different phases of query execution: analysis, logical optimization, physical planning, and code generation to compile parts of queries to Java bytecode.
For the latter, we use another Scala feature, quasi quotes [34], that makes it easy to generate code at runtime from composable expressions.
Finally, Catalyst offers several public extension points, including external data sources and user-defined types.
Trees
The main data type in Catalyst is a tree composed of node objects.
Each node has a node type and zero or more children. New node types are defined in Scala as subclasses of the TreeNode class.
These objects are immutable and can be manipulated using functional transformations, as discussed in the next subsection.
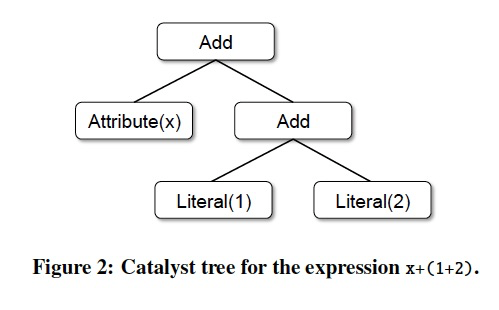
As a simple example, suppose we have the following three node classes for a very simple expression language:
• Literal(value: Int): a constant value
• Attribute(name: String): an attribute from an input row, e.g., “x”
• Add(left: TreeNode, right: TreeNode): sum of two expressions.
These classes can be used to build up trees; for example, the tree for the expression x+(1+2), shown in Figure 2, would be represented in Scala code as follows:
Add(Attribute(x), Add(Literal(1), Literal(2)))
Rules
Trees can be manipulated using rules, which are functions from a tree to another tree.
While a rule can run arbitrary code on its input tree (given that this tree is just a Scala object),
the most common approach is to use a set of pattern matching functions that find and replace subtrees with a specific structure.
Pattern matching is a feature of many functional languages that allows extracting values from potentially nested structures of algebraic data types.
In Catalyst, trees offer a transform method that applies a pattern matching function recursively on all nodes of the tree, transforming the ones that match each pattern to a result.
For example, we could implement a rule that folds Add operations between constants as follows: 用Pattern matching来实现transform rule的例子
tree.transform {
case Add(Literal(c1), Literal(c2)) => Literal(c1+c2)
}
Applying this to the tree for x+(1+2), in Figure 2, would yield the new tree x+3.
The case keyword here is Scala’s standard pattern matching syntax [14], and can be used to match on the type of an object as well as give names to extracted values (c1 and c2 here).
The pattern matching expression that is passed to transform is a partial function, meaning that it only needs to match to a subset of all possible input trees.
Catalyst will tests which parts of a tree a given rule applies to, automatically skipping over and descending into subtrees that do not match.
This ability means that rules only need to reason about the trees where a given optimization applies and not those that do not match.
Thus, rules do not need to be modified as new types of operators are added to the system.
Rules (and Scala pattern matching in general) can match multiple patterns in the same transform call,
making it very concise to implement multiple transformations at once: 单个transform里面有多个rules的例子
tree.transform {
case Add(Literal(c1), Literal(c2)) => Literal(c1+c2)
case Add(left, Literal(0)) => left
case Add(Literal(0), right) => right
}
In practice, rules may need to execute multiple times to fully transform a tree.
Catalyst groups rules into batches, and executes each batch until it reaches a fixed point, that is, until the tree stops changing after applying its rules.
Running rules to fixed point means that each rule can be simple and self-contained, and yet still eventually have larger global effects on a tree.
In the example above, repeated application would constant-fold larger trees, such as (x+0)+(3+3).
As another example, a first batch might analyze an expression to assign types to all of the attributes, while a second batch might use these types to do constant folding.
After each batch, developers can also run sanity checks on the new tree (e.g., to see that all attributes were assigned types), often also written via recursive matching.
Finally, rule conditions and their bodies can contain arbitrary Scala code.
This gives Catalyst more power than domain specific languages for optimizers, while keeping it concise for simple rules.
In our experience, functional transformations on immutable trees make the whole optimizer very easy to reason about and debug.
They also enable parallelization in the optimizer, although we do not yet exploit this.
Using Catalyst in Spark SQL
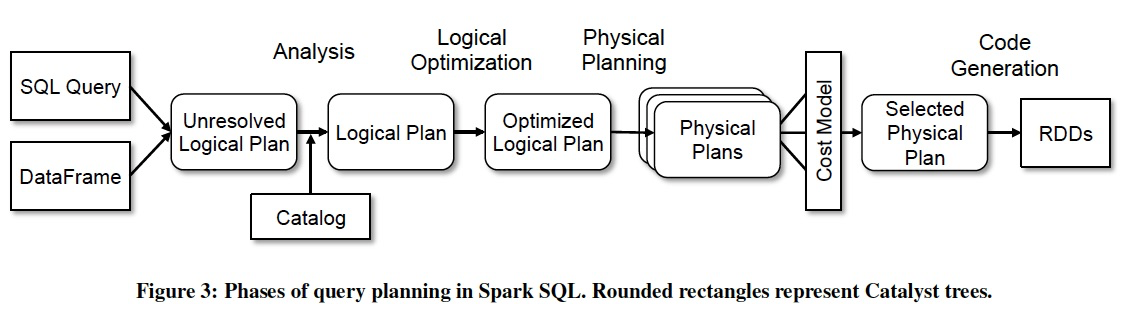
We use Catalyst’s general tree transformation framework in four phases, shown in Figure 3:
(1) analyzing a logical plan to resolve references,
(2) logical plan optimization,
(3) physical planning, and
(4) code generation to compile parts of the query to Java bytecode.
In the physical planning phase, Catalyst may generate multiple plans and compare them based on cost. 只有physical planning的时候会CBO,其他都是RBO
All other phases are purely rule-based. Each phase uses different types of tree nodes;
Catalyst includes libraries of nodes for expressions, data types, and logical and physical operators.
We now describe each of these phases.
Analysis
Spark SQL begins with a relation to be computed, either from an abstract syntax tree (AST) returned by a SQL parser, or from a DataFrame object constructed using the API.
In both cases, the relation may contain unresolved attribute references or relations:
for example, in the SQL query SELECT col FROM sales, the type of col, or even whether it is a valid column name, is not known until we look up the table sales.
An attribute is called unresolved if we do not know its type or have not matched it to an input table (or an alias).
Spark SQL uses Catalyst rules and a Catalog object that tracks the tables in all data sources to resolve these attributes.
It starts by building an “unresolved logical plan” tree with unbound attributes and data types, then applies rules that do the following: 从一个unresolved的逻辑plan开始
• Looking up relations by name from the catalog. 获取元数据,resolved
• Mapping named attributes, such as col, to the input provided given operator’s children.
• Determining which attributes refer to the same value to give them a unique ID (which later allows optimization of expressions such as col = col). 为attributes分配uid
• Propagating and coercing types through expressions: 类型传递,推导?
for example, we cannot know the return type of 1 + col until we have resolved col and possibly casted its subexpressions to a compatible types.
Logical Optimization
The logical optimization phase applies standard rule-based optimizations to the logical plan. RBO,下面给的例子,可以简单的写出一个rule
These include constant folding, predicate pushdown, projection pruning, null propagation, Boolean expression simplification, and other rules.
In general, we have found it extremely simple to add rules for a wide variety of situations.
For example, when we added the fixed-precision DECIMAL type to Spark SQL, we wanted to optimize aggregations such as sums and averages on DECIMALs with small precisions;
it took 12 lines of code to write a rule that finds such decimals in SUM and AVG expressions, and casts them to unscaled 64-bit LONGs, does the aggregation on that, then converts the result back.
A simplified version of this rule that only optimizes SUM expressions is reproduced below:
object DecimalAggregates extends Rule[LogicalPlan] { /** Maximum number of decimal digits in a Long */ val MAX_LONG_DIGITS = 18 def apply(plan: LogicalPlan): LogicalPlan = { plan transformAllExpressions { case Sum(e @ DecimalType.Expression(prec, scale)) if prec + 10 <= MAX_LONG_DIGITS => MakeDecimal(Sum(UnscaledValue(e)), prec + 10, scale) } }
As another example, a 12-line rule optimizes LIKE expressions with simple regular expressions into String.startsWith or String.contains calls.
The freedom to use arbitrary Scala code in rules made these kinds of optimizations, which go beyond pattern matching the structure of a subtree, easy to express.
In total, the logical optimization rules are 800 lines of code.
Physical Planning
In the physical planning phase, Spark SQL takes a logical plan and generates one or more physical plans, using physical operators that match the Spark execution engine.
It then selects a plan using a cost model.
At the moment, cost-based optimization is only used to select join algorithms: CBO仅仅用于选择join的算法
for relations that are known to be small, Spark SQL uses a broadcast join, using a peer-to-peer broadcast facility available in Spark.
The framework supports broader use of cost-based optimization, however, as costs can be estimated recursively for a whole tree using a rule.
We thus intend to implement richer cost-based optimization in the future.
The physical planner also performs rule-based physical optimizations, such as pipelining projections or filters into one Spark map operation. 物理计划阶段也使用RBO
In addition, it can push operations from the logical plan into data sources that support predicate or projection pushdown.
We will describe the API for these data sources in Section 4.4.1.
Code Generation
The final phase of query optimization involves generating Java bytecode to run on each machine.
Because Spark SQL often operates on in-memory datasets, where processing is CPU-bound, we wanted to support code generation to speed up execution.
Nonetheless, code generation engines are often complicated to build, amounting essentially to a compiler.
Catalyst relies on a special feature of the Scala language, quasiquotes [34], to make code generation simpler.
Quasiquotes allow the programmatic construction of abstract syntax trees (ASTs) in the Scala language, which can then be fed to the Scala compiler at runtime to generate bytecode.
We use Catalyst to transform a tree representing an expression in SQL to an AST for Scala code to evaluate that expression, and then compile and run the generated code.
As a simple example, consider the Add, Attribute and Literal tree nodes introduced in Section 4.2, which allowed us to write expressions such as (x+y)+1.
Without code generation, such expressions would have to be interpreted for each row of data, by walking down a tree of Add, Attribute and Literal nodes.
This introduces large amounts of branches and virtual function calls that slow down execution.
With code generation, we can write a function to translate a specific expression tree to a Scala AST as follows: 这里给出一个code generation的例子,如何将表达变成AST
def compile(node: Node): AST = node match { case Literal(value) => q"$value" case Attribute(name) => q"row.get($name)" case Add(left, right) => q"${compile(left)} + ${compile(right)}" }
The strings beginning with q are quasiquotes, q表示,这段string会在编译时被compiler parse,并表示成AST
meaning that although they look like strings, they are parsed by the Scala compiler at compile time and represent ASTs for the code within.
Quasiquotes can have variables or other ASTs spliced(拼接) into them, indicated using $ notation.
For example, Literal(1) would become the Scala AST for 1, while Attribute("x") becomes row.get("x").
In the end, a tree like Add(Literal(1), Attribute("x")) becomes an AST for a Scala expression like 1+row.get("x"),这个例子可以看出如果从plan变成code
Quasiquotes are type-checked at compile time to ensure that only appropriate ASTs or literals are substituted in,
making them significantly more useable than string concatenation, and they result directly in a Scala AST instead of running the Scala parser at runtime.
Moreover, they are highly composable, as the code generation rule for each node does not need to know how the trees returned by its children are constructed.
Finally, the resulting code is further optimized by the Scala compiler in case there are expression-level optimizations that Catalyst missed.
Figure 4 shows that quasiquotes let us generate code with performance similar to hand-tuned programs.
We have found quasiquotes very straightforward to use for code generation, and we observed that even new contributors to Spark SQL could quickly add rules for new types of expressions.
Quasiquotes also work well with our goal of running on native Java objects:
when accessing fields from these objects, we can code-generate a direct access to the required field, instead of having to copy the object into a Spark SQL Row and use the Row’s accessor methods.
Finally, it was straightforward to combine code-generated evaluation with interpreted evaluation for expressions we do not yet generate code for,
since the Scala code we compile can directly call into our expression interpreter.
Extension Points
Catalyst’s design around composable rules makes it easy for users and third-party libraries to extend.
Developers can add batches of rules to each phase of query optimization at runtime, as long as they adhere to the contract of each phase (e.g., ensuring that analysis resolves all attributes).
However, to make it even simpler to add some types of extensions without understanding Catalyst rules,
we have also defined two narrower public extension points:
data sources and user-defined types. These still rely on facilities in the core engine to interact with the rest of the rest of the optimizer.
Data Sources
Developers can define a new data source for Spark SQL using several APIs, which expose varying degrees of possible optimization.
All data sources must implement a createRelation function that takes a set of key-value parameters and returns a BaseRelation object for that relation, if one can be successfully loaded.
Each BaseRelation contains a schema and an optional estimated size in bytes. 对于DataSources的抽象,createRelation
For instance, a data source representing MySQL may take a table name as a parameter, and ask MySQL for an estimate of the table size.
To let Spark SQL read the data, a BaseRelation can implement one of several interfaces that let them expose varying degrees of sophistication(复杂性).
The simplest, TableScan, requires the relation to return an RDD of Row objects for all of the data in the table.
A more advanced PrunedScan takes an array of column names to read, and should return Rows containing only those columns. 裁剪columns
A third interface, PrunedFilteredScan, takes both desired column names and an array of Filter objects, which are a subset of Catalyst’s expression syntax, allowing predicate pushdown. Filter Pushdown
The filters are advisory, i.e., the data source should attempt to return only rows passing each filter, but it is allowed to return false positives in the case of filters that it cannot evaluate.
Finally, a CatalystScan interface is given a complete sequence of Catalyst expression trees to use in predicate pushdown, though they are again advisory.
These interfaces allow data sources to implement various degrees of optimization, while still making it easy for developers to add simple data sources of virtually any type.
We and others have used the interface to implement the following data sources:
• CSV files, which simply scan the whole file, but allow users to specify a schema.
• Avro [4], a self-describing binary format for nested data.
• Parquet [5], a columnar file format for which we support column pruning as well as filters.
• A JDBC data source that scans ranges of a table from an RDBMS in parallel and pushes filters into the RDBMS to minimize communication.
To use these data sources, programmers specify their package names in SQL statements, passing key-value pairs for configuration options.
For example, the Avro data source takes a path to the file:
CREATE TEMPORARY TABLE messages
USING com.databricks.spark.avro
OPTIONS (path "messages.avro")
All data sources can also expose network locality information, i.e., which machines each partition of the data is most efficient to read from.
This is exposed through the RDD objects they return, as RDDs have a built-in API for data locality [39].
Finally, similar interfaces exist for writing data to an existing or new table.
These are simpler because Spark SQL just provides an RDD of Row objects to be written.
User-Defined Types (UDTs)
One feature we wanted to allow advanced analytics in Spark SQL was user-defined types.
For example, machine learning applications may need a vector type, and graph algorithms may need types for representing a graph, which is possible over relational tables [15].
Adding new types can be challenging, however, as data types pervade(遍历) all aspects of the execution engine.
For example, in Spark SQL, the built-in data types are stored in a columnar, compressed format for in-memory caching (Section 3.6), and in the data source API from the previous section,
we need to expose all possible data types to data source authors.
In Catalyst, we solve this issue by mapping user-defined types to structures composed of Catalyst’s built-in types, described in Section 3.2. 如何解决用户自定义类型的问题?
To register a Scala type as a UDT, users provide a mapping from an object of their class to a Catalyst Row of built-in types, and an inverse mapping back.
In user code, they can now use the Scala type in objects that they query with Spark SQL, and it will be converted to built-in types under the hood.
Likewise, they can register UDFs (see Section 3.7) that operate directly on their type.
As a simple example, suppose we wanted to register two-dimensional points (x, y) as a UDT.
We can represent such vectors as two DOUBLE values.
To register the UDT, one would write the following: 这个例子可以看出,如果将UDT转化为structure
class PointUDT extends UserDefinedType[Point] { def dataType = StructType(Seq( // Our native structure StructField("x", DoubleType), StructField("y", DoubleType) )) def serialize(p: Point) = Row(p.x, p.y) def deserialize(r: Row) = Point(r.getDouble(0), r.getDouble(1)) }
After registering this type, Points will be recognized within native objects that Spark SQL is asked to convert to DataFrames, and will be passed to UDFs defined on Points.
In addition, Spark SQL will store Points in a columnar format when caching data (compressing x and y as separate columns),
and Points will be writable to all of Spark SQL’s data sources, which will see them as pairs of DOUBLEs.
We use this capability in Spark’s machine learning library, as we describe in Section 5.2.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号