Adaptive Statistics in Oracle 12c(PVLDB 2017)
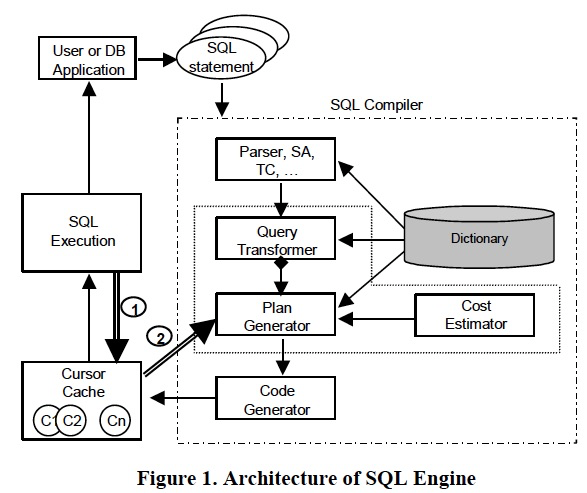
Oracle的SQL引擎大体分为这几部分,
(1)首先要进入Prepare的阶段,Parser,SA和TC
A SQL statement goes through the Parser, Semantic Analysis (SA), and Type-Check (TC) first before reaching the optimizer.
(2)优化器由3部分组成:QT,RBO阶段;PG,CBO阶段,不断的产生等价plan;CE,用于衡量每个candidates的代价
The Oracle optimizer performs a combination of logical and physical optimization techniques [1] and is composed of three parts:
a) The Query Transformer (QT) is responsible for selecting the best combination of transformations. Subquery unnesting and view merging are some examples of Query transformations.
b) Plan Generator (PG) selects best access paths, join methods, and join orders. The QT calls the PG for every candidate set of transformations and retains the one that yields the lowest cost.
c) The PG calls the Cost Estimator (CE) for every alternative access path, join method, and join order and keeps the one that has the lowest cost.
(3)CG会把优化结果放入Cursor,Cursor会被cache在内存的CC中,cache的目的肯定是为了避免反复编译
The Code Generator (CG) stores the optimizer decisions into a structure called a cursor.
All cursors are stored in a shared memory area of the database server called the Cursor Cache (CC).
The goal of caching cursors in the cursor cache is to avoid compiling the same SQL statement every time it is executed by using the cached cursor for subsequent executions of the same statement.
(4)Dictionary,用来存储云数据,各种定义,表,索引,view等;还有统计信息,这个对于优化器很关键
The Dictionary contains the database metadata (definitions of tables, indexes, views, constraints, etc) as well as object and system statistics.
When processing a SQL statement, the SQL compiler components accesses the Dictionary for information about the objects referenced in the statement,
e.g. the optimizer reads the statistics about a column referenced in the WHERE clause.
SQL和cursor匹配的时候,不光看SQL test,还有其他的因为,比如授权
At run-time, the cursor corresponding to a SQL statement is identified based on several criteria, such as the SQL text, the compilation environment, and authentication rules.
If a matching cursor is found then it is used to execute the statement, otherwise the SQL compiler builds a new one.
Several cursors may exist for the same SQL text, e.g. if the same SQL text is submitted by two users that have different authentication rules.
All the factors that affect the execution plan, such as whether a certain optimization is enabled by the user running the SQL statement, are used in the algorithm used to match a cursor from the CC.
Effect of Cardinality on Plan Generation
Plan Generator (PG) is responsible for evaluating various access paths, join methods, and join orders and choosing the plan with the lowest cost.
This section describes the PG module and the important role cardinality estimate plays in picking the most efficient plan.
PG作为CBO引擎,通过Cardinality,可以决定哪些事情?
底下给出4种,Access Path,Join order,Join Method,Transformation
Access Path Selection
PG considers different access path for the tables in a query, e.g. some of the access paths considered for products table are
Full Table Scan – Reads all rows in the table and produces rows that qualify for the specified filter condition.
Index scan – It is used to limit access to rows in the table that qualify for the condition on the index key columns.
Filters on non-index columns can be used to further filter rows once they are accessed.
Join order Selection
PG explores different join orders and chooses the join order with the least cost.
For query Q1, the following join orders are possible - (C->P->S), (C->S->P), (S->C->P), (S->P->C), (P->S->C), (P->C->S), where the letters correspond to the aliases of the tables used in the query. The number of rows of each of the tables and intermediate joins is an important input in computing the cost of the join orders.
If C and P are joined first (a Cartesian product), the intermediate size, and the resulting cost, will be high, compared to joining P and S first.
Join Method Selection
PG also selects the most efficient join method for every join order based on the cost of feasible join methods.
For example, tables P and S can be joined using Nested Loop Join or Hash Join.
Their cost depends on the cardinalities of both inputs to the join. Typically, Nested Loop join is the cheapest option if the left input produces a low number of rows.
Query Transformations
The Query Transformer (QT) module transforms SQL statements into a semantically equivalent form if the newly transformed form is cheaper than the original form.
ADAPTIVE STATISTICS
Architectural Overview
Adaptive statistics solve the cardinality misestimate issues that manifest(显现) due to the limitations of pre-computed statistics.
This technique consists of computing the statistics (selectivity/cardinality, even first class statistics like number of distinct values) during optimization of the SQL statement.
This process happens in the Cost Estimator module.
The statistics are computed by executing a SQL statement against the table with relevant predicates.
This technique can be used to estimate cardinality of operations that involve only single table as well as more complex operations that involve join, group by etc.
These kinds of queries are referred to as statistics queries. 会通过真正执行如下的statistics queries来estimate cardinality
Statistics queries are executed in most stages of plan generation.
Some example statistics queries executed while optimizing the query Q1 in section 1.1, are:


执行这种统计查询,肯定会带来额外的overhead,采用了如下两种方法来降低:
Executing statistics queries as part of optimizing user SQL statements incur additional optimization time.
Oracle employs several techniques to reduce this overhead. We describe two of these, adaptive sampling, and SQL plan directives (SPDs), below.
最容易想到的,就是在Sampling上去执行Statistics查询,
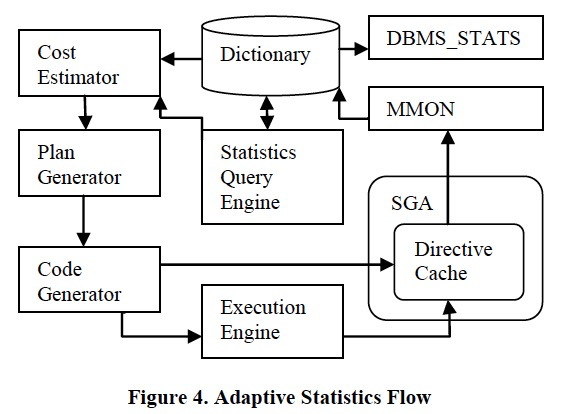
所谓的Adaptive就是,Statistics Query Engine会动态的决定采样大小,并且在有限时间中执行,甚至决定使用full或partial的查询结果来进行CE
最终统计的结果会存储在SPD中
Adaptive Sampling: Use sample of the table in statistics queries to estimate the cardinality.
Sampling is done by Statistics Query Engine as shown in Figure 4.
This module is responsible for computing the optimal sample size, executing the statistics queries within a specified time budget, using the full or partial results from statistics queries to derive the cardinality estimate, and storing the result of statistics queries in SPDs.
SPD,名字有点难理解,应该就是用来保存SQL construct(模板?部分predicts?)的统计信息
ExecutionEngine会把执行后实际产生rows和CE预估较大偏差的,记录下来;避免加重EE的负担,会记录到Directive Cache中,后续flush到Disk上,这些Directives是可以通过Dictionary查询到的
Cost Estimator只会对有记录的SPD所代表的SQL,发请求到SQE,这样避免大量的当前CE就能算准的,也发到SQE,加重Statistics Queries的负担。
另外,Statistics Collector会负责更新这些SPD的统计信息
SQL Plan Directives: SPDs are persistent objects that have run time information of SQL or SQL constructs.
For tracking the SQL constructs that caused misestimates:
This happens in the Execution Engine when the cardinality estimate for a particular construct in an operation is significantly different from the actual rows produced by the operation.
Cost Estimator requests estimates from the Statistics Query Engine only for the constructs for which misestimates are recorded as SPDs.
This is to avoid executing statistics queries for each and every construct.
To avoid the overhead of tracking in the Execution Engine, the directives are first recorded in Directive Cache in memory (SGA) before it is flushed to disk by background process (MMON).
Statistics collector (DBMS_STATS) also looks at the SPDs for constructs with a misestimate in the Dictionary and gathers statistics for them.
For example, if the SQL construct has multiple equality predicates, statistics collector will collect statistics for the group of columns in the predicates.
This allows the statistics collector to collect statistics only for group of columns that caused the misestimate.
For persistently storing the result of statistics queries to avoid repeated execution of the same statistics queries:
Statistics Query Engine first checks if there is a SPD that has the result of the statistics query in Dictionary and uses it if the result is still valid.
If the result is stale(陈旧的), it executes the statistics query to get the correct result and stores the new result in directive.
Adaptive Sampling Methodology
主要的流程如下,就是简单的run and test策略,
Given n, number of blocks in the initial sample, and a query Q:
1. Sample: Randomly sample n blocks from T. Apply the operators on the sample.
2. Cardinality Estimate: Estimate the cardinality of query Q for the entire dataset,
based on the resulting cardinality after applying the operators on this sample and samples from previous iterations (if any).
3. Quality Test: Calculate a confidence interval around the cardinality estimate, and perform a quality test on the confidence interval.
4. Next Sample Size Estimate: If the quality test succeeds, stop. If the test fails, calculate nnext, the number of additional blocks required to be sampled,
so that the resultant sample size meets the quality test (with a certain probability). Set n = nNext. Go to step 1.
这里说了些Block采样带来的问题,主要是block内部rows的相关联性,对于variance的计算的影响
As mentioned earlier, we sample a random set of blocks from T, as opposed to a random set of rows.
This means that internal correlation within rows in a block have to be taken into account during the variance calculation, possibly resulting in larger required sample sizes.
However, block sampling is far cheaper than row sampling, which makes this a reasonable trade-off.
Sampling at the block level introduces another complication(并发症):
it is expensive to remember for each row which block it originated from, making a straightforward estimate of the block-level variance impossible.
To address this problem, we rely on two statistical properties:
SQL Plan Directives
SPDs are persistent objects that have run time information of SQL or SQL constructs.
These objects are stored in the Dictionary, which can be used to improve statistics gathering and query optimization on future executions.
Currently Oracle has two types of directives – “Adaptive Sampling” and “Adaptive Sampling Result” directives. They are described next.
SPD是存储在元数据Dictionary中的,指令,分为两种,“Adaptive Sampling” and “Adaptive Sampling Result”
Adaptive Sampling Directives
这个指令,指出哪些query contructs需要发起Statistics queries或者extended Statistics
Adaptive sampling directives are created if execution-time cardinalities are found to deviate from optimizer estimates.
They are used by the optimizer to determine if statistics queries (using sampling) should be used on portions of a query.
Also, these types of directives are used by the statistics gathering module to determine if additional statistics should be created (e.g. extended statistics).
The directives are stored based on the constructs of a query rather than a specific query, so that similar queries can benefit from the improved estimates.
Creation of directives is completely automated.
The execution plan can be thought of as a tree with nodes that evaluates different SQL constructs of the query.
During compilation of the query (more precisely in Code Generator), the constructs evaluated in these nodes are recorded in a compact form in the system global memory area (SGA), and can be looked up later using a signature. The signature enables sharing of a construct between queries.
这里给出construct是指什么?比如下面的查询,construct的signature是有表名和列名组成的,所以其他查询该表和相应列的查询也可以用到
For example consider Figure 2, node 6 of the query plan for Q1 scans the Products table with predicates on columns PROD_CATEGORY, PROD_SUBCATEGORY.
The signature in this case will be built using PRODUCTS, PROD_CATEGORY, PROD_SUBCATEGORY.
That is, the signature does not use the values used in the predicates.
So if another query has predicates on the same set of columns but with different values, the construct in the SGA can be shared.
下面详细描述,如果自动的创建“Adaptive Sampling” directives
EE会从叶子节点开始,bottom-up的标注估计存在误差的node,并且当子节点已经被标注后,父节点不用继续标注
这些被标注的constructs,会生成directives,并定期的由MMON同步到磁盘,存储在Dictionary中。
At the end of execution of every query, the Execution Engine goes over all nodes in the execution plan starting from the leaf nodes and marks those SQL constructs corresponding to node in SGA, whose cardinality estimate is significantly different from the actual value.
The nodes whose children have misestimates are not marked, as the misestimate can be caused by a misestimate in the children.
For example, in Q1, the optimizer has misestimated the cardinality for products table in node 6.
The construct in this node (PRODUCTS table with PROD_CATEGORY and PROD_SUBCATEGORY) is marked while that of the parent nodes 5, 4 etc are not.
The SQL constructs that are marked (because they caused a misestimate) are used for creating the directive.
The creation is done periodically by a separate background process, called MMON.
The directives are stored persistently in Dictionary along with the objects that constitute constructs. They are called directive objects.
In our example, PRODUCTS, PROD_CATEGORY, PROD_SUBCATEGORY are the directive objects created for the misestimate in node 6 of Q1.
The directive can be used for other queries where these directive objects are present.
Adaptive Sampling Result Directives
这个指令可以认为是Statistics query的结果cache。避免重复执行。
Adaptive sampling directives reduces the number of statistics queries executed in the system by executing statistics queries
only if there is a directive created for the construct it is estimating cardinality for.
For the statistics queries executed, it still adds an overhead to compilation.
The same statistics queries may get executed for several top level SQL statements.
We use directive infrastructure to avoid the overhead of this repeated execution.
The result of the statistics query is stored in a directive of type Adaptive Sampling Result.
This type directive has the following directive objects:
- The tables along with its current number of rows referenced in the statistics query.
- The SQL identifier (sqlid). It is-a hash value created based on the SQL text.
- A signature of the environment (bind variables etc) in which the statistics query is executed.
This type of directive is created immediately after executing a statistics query in Statistics Query Engine.
The usage of the result stored in these type of directives is as follows:
- The statistics query engine first checks if a directive is created for the statistics query before executing the statement. The lookup is done based on the sqlid of the statistics query.
- If there is a directive, we check if the result stored in the directive is stale. The result can be stale if some DML has happened for any of the tables involved in the statistics query. If the current number of rows (maintained in SGA) for any of the tables is significantly different from what is stored in the directive, we consider the directive as stale.
- If a directive is stale, we mark it as such and execute the statistics query to populate the new result in the directive.
Automatic extended statistics
Extended Statistics用于capture列关联性。Oracle 11g可以手工创建
In real-world data, there is often a relationship or correlation between the data stored in different columns of the same table.
For example, in the products table, the values in PROD_SUBCATEGORY column are influenced by the values PROD_CATEGORY.
The optimizer could potentially miscalculate the cardinality estimate if multiple correlated columns from the same table are used in the where clause of a statement.
Extended statistics allows capturing the statistics for group of columns and helps the optimizer to estimate cardinality more accurately [13].
Creation of extended statistics was manual when it was introduced in Oracle 11g.
Oracle had also introduced APIs to find all column groups in a given workload and to create extended statistics for all of them [13].
Oracle 12c会自动为所有misestimate的column groups创建extended Statistics。这里需要依赖SPD
In Oracle 12c, the extended statistics are automatically created for all the column groups found in the SQL constructs that caused the misestimate.
This avoids the creation of extended statistics for unnecessary group of columns that are not causing a misestimate in cardinality and suboptimal plans.
The automatic creation of extended statistics relies on the SPD infrastructure explained in section 3.3.1.
The adaptive sampling directives maintain different states depending on whether the corresponding construct has the relevant extended statistics or not.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号