论文解析 -- A Survey on Advancing the DBMS Query Optimizer: Cardinality Estimation, Cost Model, and Plan Enumeration (Data Science and Engineering 2021)
Why Key Components in Optimizer are Still Not Accurate?
In this section, we summarize the reasons why the cardinality estimation, cost model, and plan enumeration do not perform well, respectively.
The studies reviewed in this paper try to improve the quality of the optimizer by handling these shortages.
这个查询优化的核心组件为何做不到accurate?
Cardinality Estimation
Cardinality estimation is the ability to estimate the tuples generated by an operator and is used in the cost model to calculate the cost of that operator.
Lohman [61] points out that the cost model can introduce errors of at most 30%, while the cardinality estimation can easily introduce errors of many orders of magnitude. Cost Model最多产生30%的误差,而CE可以产生的误差要大好几个数量级
Leis et al. [55] experimentally revisit the components, CE, CM, and PE in the classical optimizers with complex workloads.
They focus on the quality of the physical plan on multi-join queries and get the same conclusion with Lohman.
The errors in cardinality estimation are mainly introduced in three cases:
(1) Error in single table with predications 单表的误差主要来自于使用Histogram,偏低估,基于单列均匀,多列无关的假设;Multi-Histogram过于庞大
Database systems usually take histograms as the approximate distribution of data.
Histograms are smaller than the original data.
Thus, it cannot represent the true distribution entirely and some assumptions (e.g., uniformity on a single attribute, independence assumption among different attributes) are proposed.
When those assumptions are not hold, estimation errors occur, leading to sub-optimal plans.
The correlation among attributes in a table is not unusual. Multi-histograms have been proposed. However, it suffers from a large storage size.
(2) Error in multi-join queries 多表join的CE问题,更为复杂,难于建模多表多列的摘要和相关性,一般基于inclusion principle,带来较大误差;对于复杂查询误差会逐级放大
Correlations possibly exist in columns from different tables.
However, there is no efficient way to get synopses(摘要) between two or more tables. Inclusion principle has been introduced for this case.
The cardinality of a join operator is calculated using the inclusion principle with cardinalities of its children.
It has large errors when the assumption is not held.
Besides, for a complex query with multiple tables, the estimation errors can propagate and amplify from the leaves to root of the plan.
The optimizers of commercial and open-source database systems still struggle in cardinality estimation for mult-join queries [55 ].
(3) Error in user defined function 如何估计UDF的CE
Most of database systems support the user-defined function (UDF).
When a UDF exists in the condition, there is no general method to estimate how many tuples satisfying it [8 ].
Cost Model
Cost-based optimizers use a cost model to generate the estimate of cost for a (sub)query. The cost of (sub)plan is the sum of costs of all operators in it.
The cost of an operator depends on the hardware where the database is deployed, the operator’s implementation, the number of tuples processed by the operator,
and the current database state (e.g., data in the buffer, concurrent queries) [64].
Thus, a large number of magic numbers should be determined when combining all factors, and errors in cardinality estimation also affect the quality of the cost model.
Furthermore, when the cost-based optimizer is deployed in a distributed or parallel database, the cloud environment,
or the cross-platform query engines, the complexity of cost model is increasing dramatically.
Moreover, even with the true cardinality, the cost estimation of a query is not linear to the running time, which may lead to a suboptimal execution plan [45, 81].
总的来说,就是CM所依赖的条件太多了,很难精确建模,尤其在分布式和云环境下;并且CE有时候和running time也并不成线性关系;
Plan Enumeration
Plan enumeration algorithm is used to find the optimal join order from the space of semantically equivalent join orders such that the query cost is minimized.
It has been proven to be an NP-hard problem [41]. Exhaustive query plan enumeration is a prohibitive(禁止的) task for large databases with multi-join queries.
Thus, it is crucial to explore the right search space which should consist of the optimal join orders or approximately optimal join orders and design an efficient enumeration algorithm.
The join trees in the search space could be zigzag trees, left-deep trees, right-deep trees, and bushy trees or the subset of them.
Different systems consider different forms of join tree.
There are three enumeration algorithms in traditional database systems: Join tree的形式有zigzag,ld,rd,bushy四种,enum算法有bottom up,top down和随机三种
(1) bottom up join enumeration via dynamic programming (DP) (e.g., System R [79]),
(2) top-down join enumeration through memorization (e.g., Volcano/Cascades [26 , 27 ]),
and (3) randomized algorithms (e.g., genetic algorithm in PostgreSQL [77 ] with numerous tables joining).
Plan enumeration suffers from three limitations: PE的限制主要是,CE和CM本身带来的误差;搜索空间Prune的rule;当join表很多的时候的性能问题
(1) the errors in cardinality estimation and cost model,
(2) the rules used to prune the search space,
and (3) dealing with the queries with large number of tables.
When a query touches a large number of tables, optimizers have to sacrifice optimality and employ heuristics to keep optimization time reasonable,
like genetic algorithm in PostgreSQL, greedy method in DB2, which usually generates poor plans.
We should notice the errors in cardinality will propagate to the cost model and lead to suboptimal join order.
Eliminating or reducing the errors in cardinality is the first step to build a capable optimizer as Lohman [61 ] says
“The root of all evil, the Achilles Heel of query optimization, is the estimation of the size of intermediate results, known as cardinalities” .
Cardinality Estimation
At present, there are three major strategies for cardinality estimation as shown in Fig. 2.
We only list some representative work for each category.
Every method tries to approximate the distribution of data well with less storage. 研究目标
Some proposed methods combine different techniques, e.g., [91, 92].
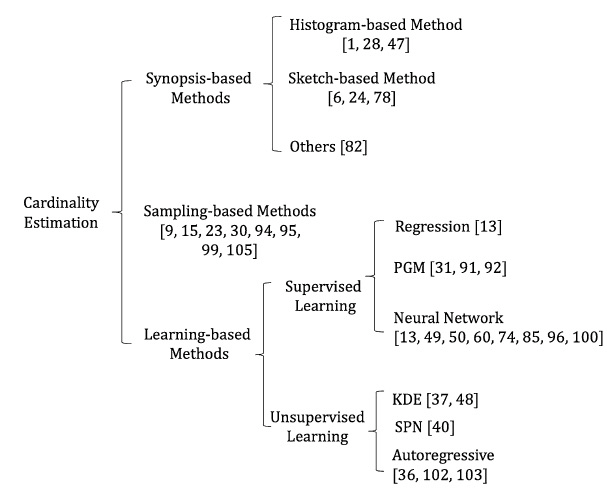
Synopsis‑Based Methods(基于摘要的方法)
Synopsis-based methods introduce new data structures to record the statistics information. 基本的ideal,主要的两种结构是Histogram和Sketch
Histogram and sketch are the widely adopted forms.
A survey on synopses has been proposed in 2012 [10], which focuses on distinguishing aspects of synopses that are pertinent(相关的) to approximate query processing (AQP).
Histogram
There are two histogram types: 1-dimensional and d-dimensional histograms, where d ≥ 2 .
d-dimensional histograms can capture the correlation between different attributes.
A 1-dimensional histogram on attribute a is constructed by partitioning the sorted tuples into B(≥ 1) mutually disjoint subsets, called buckets 何为1维Histogram?
and approximates the frequencies and values in each bucket in some common fashion, e.g., uniform distribution and continuous values.
A d-dimensional histogram on an attribute group A is constructed by partitioning the joint data distribution of A .
Because there is no order between different attributes, the partition rule needs to be more intricate(错综复杂).
Ioannidis [43 ] present a comprehensive survey on histograms following the classification method in [76 ].
Gunopulos et al. [29 ] also propose a survey in 2003, which focuses on the work used to estimate the selectivity over multiple attributes.
They summarize the multi-dimensional histograms and kernel density estimators.
After 2003, the work in histograms can be divided into three categories: 2003后,研究集中在3个方面,构建算法;分桶方法;query based的构建方法,adaptive
(1) fast algorithm for histogram construction [1 , 28 , 32 , 33 , 42 ];
(2) new partition methods to divide the data into different buckets to achieve better accuracy [14 , 58 , 88 ];
(3) histogram construction based on query feedback [47 , 57 , 83 ].
Query feedback methods are also summarized in [10 ] (Section 3.5.1.2) and readers can refer to it for details.
histogram构建方法的研究,贪婪算法,基于随机samples
Guha et al. [28 ] analyze the previous algorithm, VODP [44 ] and find some calculations on the minimal sumof-squared-errors (SSE) can be reduced.
Halim et al. [32 , 33 ] propose GDY, a fast histogram construction algorithm based on greedy local search.
GDY generates good sample boundaries, which then are used to construct B final partitions optimally using VODP.
Instead of scanning the whole dataset [28 , 42 ] design a greedy algorithm to construct the histogram on the random samples from dataset with time complexity O((B5∕8) log2 n) and sample complexity O((B∕)2 log n) .
[1 ] study the same problem with [42 ] and propose a merging algorithm with time complexity O(1∕2) .
Methods in [1 , 28 , 42 ] can be extended to approximate distributions by piecewise polynomials.
Histogram分桶的研究,基于tree或多次Histogram,有效组织;基于最小熵,类似聚类
当前分桶的研究都是基于单列的
Considering the tree-based indexes divide the data into different segments (nodes), which is quite similar with buckets in the histogram,
Eavis and Lopez [14 ] build the multidimensional histogram based on R-tree.
They first build a native R-tree histogram on the Hilbert sort of data
and then propose a sliding window algorithm to enhance the naive histogram under a new proposed metric, which seeks to minimize the dead space between bucket points.
Lin et al. [58 ] design a two-level histogram for one attribute, which is quite similar to the idea of the B-tree index.
The first level is used to locate which leaf histograms to be used, and the leaf histograms store the statistics information.
To et al. [88 ] construct a histogram based on the principle of minimizing the entropy reduction of the histogram.
They design two different histograms for the equality queries and an incremental algorithm to construct the histogram.
However, it only considers the one-dimensional histogram and does not handle range queries well.
Sketch
Sketch models a column as a vector or matrix to calculate the distinct count (e.g., HyperLogLog [21]) or frequency of tuples (e.g., Count Min [11]) on a value. 何为sketch?
用sketch来预估join size,仅仅可以用于等价join和单列join,不能有filter
Rusu and Dobra [78 ] summarize how to use different sketches to estimate the join size.
This work considers the case of two tables (or data streams) without filters.
The basic idea of them is:
(1) building the sketch (a vector or matrix) on the join attribute, while ignoring all the other attributes,
(2) estimating the join size based on the multiplication of the vectors or matrices.
These methods only support the equi-join and join on single column.
其他的一些方法,但是没有太好的效果
As shown in [94 ], a possible method introducing one filter in sketch is to build an imaginary table which only consists of the join value of tuples which satisfy the filter.
However, this makes the estimation drastically worse.
Skimmed sketch [24 ] is based on the idea of bifocal sampling [23 ] to estimate the join size.
However, it requires knowing frequencies of the most frequent join attribute values.
Recent work [6 ] on join size estimation introduces the sketch to record the degree of a value.
Other Techniques
TuG [82] is a graph-based synopsis. 基于图的摘要,性能无法用于大数据集,无法跨表
The node of TuG represents a set of tuples from the same table or a set of values for the same attribute.
The edge represents the join relationship between different tables or between attributes and values.
The authors adopt a three-step algorithm to construct TuG and introduce the histogram to summarize the value distribution in a node.
When a new query comes, the selectivity is estimated by traversing TuG.
The construction process is quite time-consuming and cannot be used in a large dataset.
Without the relationship between different tables, TuG cannot be built.
Sampling‑Based Methods (基于采样的方法)
采样方式主要用于摘要方式无法应对的,多表问题;由于采样数据集比较小,比较容易得到CE,所以问题就变成如何得到有代表性的sample
Synopsis-based methods are quite difficult to capture the correlation between different tables.
Some researchers try to use a specific sampling strategy to collect a set of samples (tuples) from tables, and then run the (sub)query over samples to estimate the cardinality.
As long as the distribution of the obtained samples is close to the original data, the cardinality estimation is believable.
Thus, lots of work have been proposed to design a good sampling approach, from independent sampling to correlated sampling technique.
Sampling-based methods also are summarized in [10].
After 2011, there are numerous studies that utilize the sampling techniques.
Different with [10], we mainly summarize the new work.
Moreover, we review the work according to their publishing time and present the relationship between them, i.e., which shortages of the previous work the later work tries to overcome.
Haas分析,对于equi-join,如果join keys有索引,结合索引的page-level sampling是最好的方式,如果无索引,page-level cross-product sampling最有效
Haas et al. [30] analyze the six different fixed-step (a predefined sample size) sampling methods for the equi-join queries.
They conclude that if there are some indexes built on join keys, page-level sampling combining the index is the best way.
Otherwise, the page-level cross-product sampling is the most efficient way.
Then, the authors extend the fixedstep methods to fixed-precision procedures.
双焦点采样,先把每个表的join列的values分别分到sparse和density两个组,这个要没有index会很低效
对于都是density,采用cross sampling就可以,我理解就是cross join的结果集上采样;而对于有sparse的情况,直接采样很可能采集不到,所以需要基于index
这个方法主要是为了,应对sparse值对于sampling准确率的影响
Ganguly et al. [23 ] introduce bifocal sampling(双焦点采样) to estimate the size of an equi-join.
They classify values of the join attribute in each relation into two groups, sparse (s ) and dense (d ) based on their frequencies.
Thus, the join type between tuples can be s–s , s–d , d–s , and d–d .
The authors first adopt t_cross sampling [30 ] to estimate the join size of d–d ,
then adopt t_index to estimate the join size of the remaining cases, and finally add all the estimation as the join size estimation.
However, it needs an extra pass to determine the frequencies of different values and needs indexes to estimate the join size for s–s , s–d , and d–s .
Without indexes, the process is time-consuming.
End-Biased对于每个表的join列,会抽样一个高频value的表,抽样的过程中用到了hash,如果v的个数超过T一定会被采样,但是小于也会一定概率会被采样到,并且越接近T概率越大,很巧妙的样子
然后后面就根据这个抽象表进行估计;只能用于equi-join,不能有其他的filter;和双焦点有点相似,不同是双焦点利用index采样
End-biased sampling [15 ] stores the (v, fv) if fv ≥ T, where v is a value in the join attribute domain, fv is the number of tuples with value v, and T is a defined threshold.
It applies a hash function h(v) ∶ v ↦ [0, 1] . If h(v) ≤fv/T, it stores (v, fv) or not.
Different tables adopt the same hash function to correlate their sampling decisions for tuples with low frequencies.
Then, the join size can be estimated using stored (v, fv) pairs.
However, it only supports equi-join on two tables and cannot handle other filter conditions.
Notice, end-bias sampling is quite similar to bifocal sampling.
The difference is: the former uses a hash function to sample correlated tuples and the latter uses the indexes.
Both of them require an extra pass through the data to compute the frequencies of the join attribute values.
CS2提出一个多表join的sampling的方法,correlated sampling, 关联采样,不同于独立采样,一般多表join都会采用关联采样。
基本思路,在join graph找到source table,然后做sampling S1,然后顺着join graph的edge寻找下一个表进行sampling S2,这时必须保证S2中的值是可以和S1进行join的。这样才是有效sampling。
这个方法,显然比较耗时间,也需要耗费大量的空间
Yu et al. [105 ] introduce correlated sampling as a part of CS2 algorithm.
They (1) choose one of the tables in a join graph as the source table R1 , (2) use a random sampling method to obtain sample set S1 for R1 (mark R1 as visited),
(3) follow an unvisited edge < Ri, Rj> ( Ri is visited) in the join graph and collect the tuples from Rj which are joinable with tuples in Si as Sj ,
and (4) estimate the join size over the samples.
To support the query without source tables, they propose a reverse estimator, which tracks to the source tables to estimate the join size.
However, due to the walking through the join graph many times, it is time-consuming without indexes.
Furthermore, it requires an unpredictable large space to store the samples.
前面提到的bifocal和end-biased都是需要先知道表中有多少值,和每个值的出现频率,这个要求其实不太现实的,因为如果要知道这些,很多时候需要扫表。
本文提出一个不需要先验知识的关联sampling的方法
这里的sample也是用hash,和end-biased几乎一样,但是这里用的n是sample size,这是个固定值和value无关;这样的采样基本随机和hash函数相关,不会对高频的value有biased
并且他是采用出整个tuple形成sample,这样就可以简单的应对filter和多表join的问题;
这个方法在大部分情况下,比t-cross,独立伯努利采样效果要好,但是对于高频value效果较差,这是很显然的;
Vengerov et al. [94 ] propose a correlated sampling method without the prior knowledge of frequencies of join attributes, like in [15 , 23 ].
A tuple with join value v is included in the sample set if h(v) < p, where p = n/T, h(v) is a hash function similar in [15 ], n is the sample size, and T is the table size.
Then, we can use obtained samples to estimate the join size and handle specified filter conditions.
Furthermore, the authors extend the method into more tables join and complex join conditions.
In most cases, the correlated sampling has lower variance than independent Bernoulli sampling (t_cross ),
but when the values of many join attributes occur with large frequencies, the Bernoulli sampling is better.
One possible solution the authors propose is to adopt a one-pass algorithm to detect the values with high frequencies, which is back to the method in [15 ].
两级采样,第一级用correlated采样value,第二级用独立伯努利采样value对应的tuples
Through experiments, Chen and Yi [9 ] conclude that there does not exist one sampling method suitable for all cases.
They propose a two-level sampling method, which is based on the independent Bernoulli sampling, end-bias sampling [15 ], and correlated sampling [94 ]. 综合多种采样方式
Level-one sampling samples a value v from join attribute domain into value set (V ), if h(v) < pv.
h is a hash function similar to [15 ], pv is a defined probability for value v.
Before level-two sampling, they sample a random tuple, called the sentry(哨兵), for every v in V into tuple set.
Level-two sampling samples tuples with value v ( v ∈ V ) with probability q.
Then, we can estimate the join size by using the tuple samples.
Obviously, the first level is a correlated sampling and the second level is independent Bernoulli sampling.
The authors analyze how to set the pv and q according to different join types and the frequencies of values in join attributes.
通用化上述采样,提出一种新的correlated采样方法,CSDL,2020的论文
Wang and Chan [95 ] extend [9 ] to a more general framework in terms of five parameters.
Based on the new framework, they propose a new class of correlated sampling methods, called CSDL, which is based on the discrete learning algorithm.
A variant of CSDL, CSDL-Opt has outperformed [9 ] when the samples are small or join value density is small.
在线sampling用于纠正plan,reoptimization
Wu et al. [99 ] adopt the online sampling to correct the possible errors in the plan generated by the optimizers.
Learning‑Based Methods
Due to the capability of the learning-based methods, many researchers have introduced a learning-based model to capture the distribution and correlations of data.
We classify them into: (1) supervised methods, (2) unsupervised methods (Table 1).
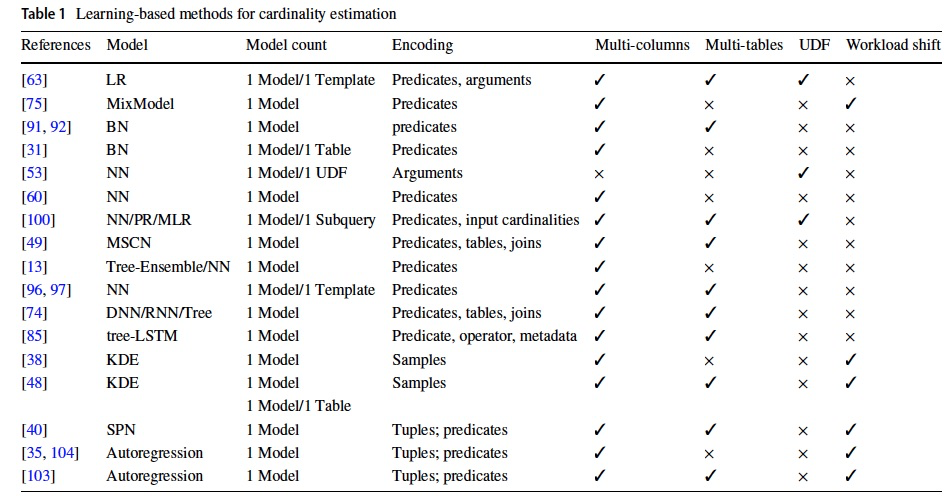
Supervised Methods
黑盒的,query-based,将query模板化,对每一种模板学习查询结果大小的分布
Malik et al. [63] group queries into templates and adopt machine learning techniques (e.g., linear regression model, tree models)
to learn the distribution of query result sizes for each family.
The features used in it include query attributes, constants, operators, aggregates, and arguments to UDFs.
仍然是基于query based的,47,57,83是query feedback的Histogram构建,这里用uniform mixture models来代替Histogram给数据建模,2020年的论文
Park et al. [75] propose a model, QuickSel, in query driven paradigm, which is similar to [47, 57, 83], to estimate the selectivity of one query.
Instead of adopting the histograms, QuickSel introduces the uniform mixture models to represent the distribution of the data.
They train the model by minimizing the mean squared error between the mixture model and a uniform distribution.
下面两个是用贝叶斯网络,将涉及多个列的复杂统计,拆分成多个小的,单维或两维的统计
Tzoumas et al. [91, 92] build a Bayesian network and decompose the complex statistics over multiple attributes into small one-/two-dimensional statistics,
which means the model captures dependencies between two relations at most.
They build the histograms for these small dimensional statistics and adopt a dynamic programming to calculate the selectivity for the new queries.
Different with previous method [25], it can handle more general joins and has a more efficient construction algorithm because of capturing smaller dependencies.
However, the authors do not verify their method with multiple tables join and in large dataset.
Moreover, constructing the two-dimensional statistics with attributes from different tables needs the join operation.
Halford et al. [31 ] also introduce a method based on Bayesian network.
To construct the model quickly, they only factorize the distribution of attributes inside each relation and use the previous assumptions for joins.
However, they do not present how well their method compared with [91 , 92 ].
用两层的NN来解决UDF的CE,这是之前的方法都无法解决的
Lakshmi and Zhou [53 ] first introduce the NN into the cardinality estimation of user defined function (UDF),
which the histograms and other statistics cannot support.
They design a two-layer neural network (NN) and employ the back propagation to update the model.
Liu et al. [60 ] formalize a selectivity function, Sel ∶ R2N ↦ R, (l1, u1,…, ln, un) ↦ c ,
where N is the number of attributes, li and ui is the lower and upper bound on ith attribute for a query.
They employ a 3-layer NN to learn the selectivity function.
To support > and <, they add 2N small NNs to produce li and ui .
针对大量重复出现和重叠的查询,提取出重叠部分的模板,学习这部分的CE
Wu et al. [100 ] use a learning-based method for workload in shared clouds, where the queries are often recurring and overlapping in nature.
They first extract overlapping subgraph templates in multiple query graphs.
Then, they learn the cardinality models for those sub-graph templates.
2019年慕尼黑的论文,利用卷积网络预估关联Join的CE,将查询的tables,joins,predicts分别表示成一个两层的NN。
再把这3个NN级联接入最终的输出网络
Kipf et al. [49 ] introduce the multi-set convolutional network (MSCN) model to estimate the cardinality of correlated joins.
They represent a query as a collection of a set of tables T, joins J, and predicts P and build the separate 2-layer NN for each of them.
Then, the outputs of three NNs are concatenated(级联) after the averaging operation and fed into the final output network.
Deep sketch [50 ] is built on [49 ] and is a wrapper of it.
微软19年的论文,将CE看成回归问题,采用NN和组合树的轻量模型
创新是,会将原来的Histogram和领域知识加入特征进行训练,可以更好的应对数据集上的更新
Dutt et al. [13 ] formalize the estimation as a function similar to [60 ], and they consider it as a regression problem.
They adopt two different approaches for the regression problem, NN-based methods and tree-based ensembles.
Different with [60 ], the authors also use histograms and domain knowledge (e.g., AVI, EBO, and MinSel) as the extra features in the models, which improve the estimation accuracy.
Due to the domain knowledge quickly updated when the data distribution changes, the model is robust to the updates on the datasets.
这篇19年的paper认为对于一个库训练单一的NN,过于庞大。
所以他们对于每个查询模板,build一个local模型,多层感知器,多层网络的一种,来预估CE。
Woltmann et al. [96 ] think building a single NN, called global model, over the entire database schema has the sparse encoding and needs numerous samples to train the model.
Thus, they build different models, called local models, for different query templates.
Every local model adopts multi-layer perceptrons (MLP) to produce the cardinality estimation.
To collect the true cardinality, many sample queries are issued during the training process, which is time-consuming.
Furthermore, Woltmann et al. [97 ] introduce the method of pre-aggregating the base data using the data cube concept and execute the example queries over this pre-aggregated data.
这篇19年paper创新的使用RNN来建模查询
查询变成左深树后,可以看成是一系列有序的operator,每一层接收上一个operator产生的输出和本层的operator的encoding作为输入,确实有点道理
Ortiz et al. [74 ] empirically analyze various of deep learning approaches used in cardinality estimation,
including deep neural network (DNN) and recurrent neural network (RNN).
The DNN model is similar with [96 ]. To adopt RNN model, the authors focus on left-deep plans and model a query as a series of actions.
Every action represents an operation (i.e., selection or join).
In each timestamp t, the model receives two inputs: xt , the encoding of t th of operation, and ht−1 , the generated hidden state from timestamp t − 1,
which can be regarded as the encoding of a subquery and captures the important details about the intermediate results.
基于tree-LSTM模型的CE
Sun and Li [85 ] introduce a tree-LSTM model to learn a representation of an operator
and add an estimation layer upon the tree-LSTM model to estimate the cardinality and cost simultaneously.
Unsupervised Methods
KDE的方式,核密度估计,效果取决于kernel和bandwidth的选择
无参数学习方法,预估的代价很高,需要保留完整的sample集合
Heimel et al. [38] introduce the Kernel Density Estimator (KDE) into estimating the selectivity on single table with multiple predicates.
They first adopt the Gaussian Kernel and the bandwidth obtained by a certain rule to construct the initial KDE,
and then, they use the history queries to choose the optimal bandwidth by minimize the estimation error using initial KDE.
To support the shifts in workload and dataset, they update the bandwidth after each incoming query
and design the new sample maintenance method for insert-only workload and updates/deletions workload.
Furthermore, in Kiefer et al. [48] extend the method into estimating the selectivity of join.
They design two different models: single model over the join samples and the models over the base tables,
which does not need the join operation and estimates the selectivity of join with the independent assumption.
19年论文利用深度自回归模型,对n维tuples的条件密度进行建模;
可以知道多个谓词条件同时出现的概率,用以来预估CE
Yang et al. [104 ] propose a model called Naru, which adopts the deep autoregressive model to produce n conditional densities ̂ P(xix<i) on a set of n-dimensional tuples.
Then, they estimate the selectivity using the product rule:
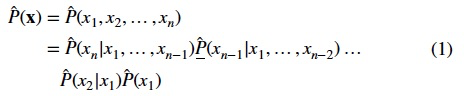
To support range conditions, they introduce a progressive sampling method by sampling points from more meaningful region according to the trained autoregressive model,
which is robust to the skewed data. Furthermore, they adopt the wildcard-skipping to handle wildcard condition.
20年的论文,主要也是使用自回归和adaptive sampling,和上篇比在性能上有提升
Hasan et al. [35 ] also adopt the deep autoregressive models and introduce an adaptive sampling method to support range queries.
Compared with the Naru, the authors adopt the binary encoding method and the sampling process runs parallelly,
which leads the model is smaller than Naru and makes the inference faster.
Besides, it can incorporate with the workload by assigning the tuples with weights according to the workload when defining the cross-entropy loss function.
DeepDB,data-based的建模方式,利用Relational Sum Product Network (RSPN)对于单表进行建模
Hilprecht et al. [40 ] introduce the Relational Sum Product Network (RSPN) to capture the distribution of single attributes and the joint probability distribution.
They focus on Tree-SPNs, where one leaf is the approximation of a single attribute,
and the internal node is Sum node (splitting the rows into clusters) or Product node (splitting the columns of one cluster).
To support cardinality estimation of join, they build the RSPN over the join results.
Yang et al. [103 ] extend their previous work, Naru, to support joins.
They build an autoregressive model over the full outer join of all tables.
They introduce the lossless column factorization for large-cardinality columns and employ the join count table to support any queries on the subset of tables.
Our Insights
Summaries
Histogram,2000年前提出,主常用的方式,近些年主要的工作集中在,如何更快的构建和提升准确率。
它的主要问题只能用于单列,多列的空间膨胀太大,不适用于跨表
The basic histogram types (e.g., equi-width, equi-depth, d-dimensional) have been introduced before 2000.
Recent studies mainly focus on how to quickly construct the histograms and to improve the accuracy of them.
Updating the histograms by query feedback is a good approach to improve the quality of histograms.
However, there are still two limitations in the histograms:
(1) the storage size increases dramatically when building a d-dimensional histograms;
(2) histograms cannot capture the correlation between attributes from different tables.
If building a histogram for the attributes from different tables, the join operation is required, like in [91, 92 ] and it is difficult to update this histogram.
Sketch方法缺乏通用性,无法单独使用
Sketch can be used to estimate the distinct count of an attribute or the cardinality of equi-join results.
However, it cannot support more general cases well, e.g., join with filters.
Synopsis based methods cannot estimate the size of final or intermediate relations when one or both of the child relations is an intermediate relation.
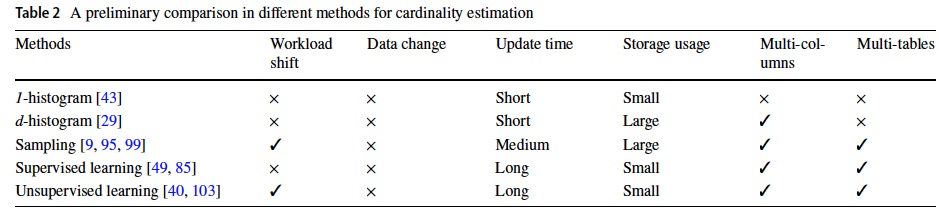
Sampling是一种相对比较好的方法,可以解决多表关联的问题;但有数据更新的问题,需要增量更新sampling
Sampling方法的问题主要是,当数据比较大的时候,存放sampling的空间和获取合理sampling的时间耗费和难度
Sampling is a good approach to capture the correlations between different tables.
However, when the tuples in tables have been updated, the samples may become out-of-date.
Sampling-based methods also suffer from the storage used to store the samples and the time used to retrieve the samples, especially when the original data is numerous.
Furthermore, current sampling methods only support the equi-join.
supervised的方法,大多是query-based,只能适配一种workload
The supervised learning methods are mostly query-driven, which means the model is trained for a specific workload.
If the workload shifts, the model needs to be retrained.
unsupervised的方法,一般是data-based,对于workload shift更加robust
Thus, the data-driven (unsupervised learning) approaches come out, which still can estimate the cardinality even if the workload shifts.
As shown in [104 ] (Section 6.3), Naru is robust to workload shift, while MSCN and KDE are sensitive to the training queries.
但无法哪一种方法,对于data change都缺乏好的兼容,往往需要retrained
Moreover, both of the supervised and unsupervised learning methods suffer from the data change.
As presented in [103 ] (Section 7.6) and [85 ] (Section 7.5), both of them are sensitive to data change and the models will be updated in an incremental mode or retrained from scratch. However, they only consider that new tuples are appended into one table and there does not exist delete or update operation.
总结成下面的图,
对于Workload shift,只有Sampling和Unsupervised Learning可以handle
对于data change,没有可以解决的方案
对于跨表,Sampling和Learning的方式都可以解决
Possible Future Directions
There are several possible directions as follows:
(1) Learning-based methods
learning based方法都是这两年出现的,能用于实际系统的,都是一些轻量的模型,但是准确率不是很好;
复杂的系统,训练成本过高,所以如何更加有效的训练和如何和数据库系统integration都是需要考虑的问题
Many studies on cardinality estimation are learning-based methods in last two years.
The learning-based models currently integrated a real system are the light model or one model for one (sub-)query graph [13, 100],
which can be trained and updated quickly. However, the accuracy and generality of these models are limited.
More complex models (achieve a better accuracy) still suffer from the long training time and update time.
Training time is influenced by the hardware. For example, it only takes several minutes in [103], while it is 13h in [85] using a GPU with relatively poor performance.
A database instance, especially in the cloud environment, is in a resource-constrained environment.
How to train the model efficiently should be considered.
The interaction between the models and the optimizer also needs to be considered, which should not be with too much overhead on the database systems [13].
对于data change的问题是否有更好的解决,active learning?
As presented above, current proposed methods for data change cannot handle delete or update operation.
A possible method is to adopt the idea of active learning to update the model [62].
(2) Hybrid methods
Query based的方法效果比较好,但是对workload敏感,data based虽然对workload不敏感,但是准确度不太行。
所以两者如何结合是一个方向
之前query-feedback Histogram其实就是这个方向的一种尝试
query-feedback对于datachange是否可以有所帮助?
Query-driven methods are sensitive to workload.
Although data-driven methods can support more queries, it may not achieve the best accuracy for all queries.
How to combine two methods in these two different catalogs is a possible direction.
Actually, the previous query-feedback histogram is an instance of this case.
Another interesting thing is that utilizing the query feedback information will help the model be aware of the data change.
(3) Experimental Study
缺乏实际系统的实验和验证
Although many methods have been proposed, it lacks of experimental studies to verify these methods.
Different methods have different characteristics as shown in Table 2 .
It is crucial to conduct a comprehensive experimental study for proposed methods.
We think the following aspects should be included:
(1) is it easy to integrate the method into a real database system;
(2) what is the performance of the method under different workload patterns (e.g., static or dynamic workload, OLTP or OLAP) and different data scales and distributions;
(3) researchers should pay attention to the trade-off between storage usage and accuracy of candidate estimation and the trade-off between efficiency of model update and the accuracy.
Cost Model
In this section, we present the researches proposed to solve the limitations in the cost model.
We classify the methods into three groups:
(1) improving the capability of the existed cost model,
(2) building a new cost model,
and (3) predicting the query performance.
We include the work on the single query performance prediction, because the cost used in the optimizer is the metric for performance.
These methods are possibly integrated into the cost-based optimizer and replace the cost model to estimation the cost of a (sub)plan, like in [67].
However, we do not considerthe query performance prediction under concurrent context (e.g., [108]). 查询性能预测时,不考虑并行查询环境
On the one hand, the concurrent queries existing during the optimization may be quite different with queries during the execution process.
On the other hand, it also needs to collect more information than the model predicting the performance of a single query.
We list the representative work of in the cost model in Fig. 3.
Quality Improvement of Existing Cost Model
底下3篇Paper主要针对如何estimate UDF的cost,基本思路都是用不同的值跑这个UDF,然后建模
建模的方式,有树结构的多维Histogram,动态四叉树,KNN
Several studies try to estimate the cost of UDF [3, 36, 37].
Boulos and Ono [3] execute the UDF several times with different input values, collect the different costs, and then use these costs to build a multi-dimensional histogram.
The histogram is stored in a tree structure. When estimating the UDF with specific parameters,
traverse the tree top-down to get the estimated cost to locate the leaf with similar parameters with inputs.
However, this method needs to know the upper and lower bounds of every parameter and it cannot solve the complex relation between input parameters and the costs.
Unlike the static histogram used in [3], He et al. [36] introduce a dynamic quadtree-based approach(动态四叉树) to store the UDF execution information.
When a query is executed, the actual cost of executing the UDF is used to update the cost model.
He et al. [37] introduce a memory-limited K-nearest neighbors (MLKNN) method.
They design a data structure, called PData, to store the execution cost and a multidimensional index
used for fast retrieval k nearest PData for a given query point (parameter in UDF) and fast insertion of new PData.
提出一个内存数据库中hash join的cost model,基本思路是cost和operation的数目成正比,不同operation的权值不同。
Liu and Blanas [59 ] introduce a cost model for hashbased join for main-memory database.
They model the response time of a query as being proportional(成比例的) to the number of operations weighted by the costs of four basic access patterns.
They first adopt the microbenchmarks to get the cost of each access pattern and then model the cost of sequential scan, hash join, hash join with different orders by the basic access patterns.
在cost模型考虑到计费问题,针对云服务的特点
Most of the previous cost models only consider the execution cost, which may be not reasonable in the cloud environments.
The users of the cloud database systems care about the economic cost.
Karampaglis et al. [46 ] first propose a bi-objective query cost model, which is used to derive running time and monetary cost together in the multi-cloud environment.
They model the execution time based on the method in [98 ].
For economic cost estimation, they first model the charging policies and estimate the monetary cost by combining the policy and time estimation.
Cost Model Alternatives
CM其实就是一个cost function,这个正好是NN擅长的地方,所以提出一系列NN-based的cost model。
The cost model is a function mapping the (sub)plan with annotated information to a scalar (cost).
Because a neural network on data primarily approximates the unknown underlying mapping function from inputs to outputs,
most of the methods used to replace the origin cost model are learningbased, especially NN-based.
Boulos et al. [4] firstly introduce the neural network for cost evaluation.
They design two different models: a single large neural network for every query type and a single small neural network for every operator.
In the first model, they also train another model to classify a query in a certain type.
The output of the first model is the cost of a (sub)plan, while the second model needs to add up the outputs from small models to get the cost.
Sun and Li [85] adopt a tree-LSTM model to learn the presentation of an operator and add an estimation layer upon the tree-LSTM model to estimate the cost of the query plan.
20年的论文,一个大数据系统中提出的learning-based的代价模型,会训练大量的模型去predict公共子查询的cost
Due to the difficulty in collecting statistics and the needs of picking the resources in big data systems, particularly in modern cloud data services,
Siddiqui et al. [81] propose a learning-based cost model and integrate it into the optimizer of SCOPE [7].
They build large number of small models to predict the costs of common (sub)queries, which are extracted from the workload history.
The features encoded into the models are quite similar with [100].
Moreover, to support resource-aware query planning, they add number of partitions allocated to the operator into the features.
In order to improve the coverage of the models, they introduce operator-input models and operator-subgraphApprox models
and employ a meta-ensemble model to combine the models above as the final model.
Query Performance Prediction
The performance of the one query mainly refers to the latency.
Wu et al. [98] adopt an offline profiling to calibrate(校准) the coefficients in the cost model under a specific hardware and software conditions.
Then, they adopt the sampling method to obtain the true cardinalities of the physical operators to predict the execution times.
Ganapathi et al. [22 ] adopt the kernel canonical correlation analysis (KCCA) into the resource estimation, e.g., CPU time.
They only model the plan level information, e.g., the number of each physical operator type and their cardinality, which is too vulnerable(易受影响).
To estimate the resources (CPU time and logical I/O times),
Li et al. [56 ] train a boosted regression tree for every operator in the database and the consumption of the plan is the sum of the operators’.
To make the model more robust, they train a separate scaling function for every operator
and combine scaling functions with the regression models to handle the cases when the data distribution, size, or queries’ parameters are quite different with the training data.
Different with [22 ], this is an operator-level model.
Akdere et al. [2 ] propose the learning-based models to predict the query performance.
They first design a plan-level model if the workload is known in advance and an operator-level model.
Considering the plan-level model makes highly accurate prediction and the operator-level generalizes well,
for queries with low operator-level prediction accuracy,
they train models for specific query subplans using plan-level modeling and compose both types of models to predict the performance of the entire plan.
However, the models adopted are linear.
Marcus and Papaemmanouil [66 ] introduce a plan-structure neural network to predict the query’s latency.
They design a small neural network, called neural unit, for every logic operator and any instance of the same logic operator shares the same network.
Then, these neural units are combined into a tree shape according to the plan tree.
The output of one neural unit consists of two parts, the latency of current operator and the information sent to its parent node.
The latency of the root neural unit of a plan is the plan’s latency.
Neo [67 ] is a learning-based query optimizer, which introduces a neural network, called value network, to estimate the latency of (sub)plan.
The query-level encoding (join graph and columns with predicts) is fed through several full-connected layers
and then concatenated with the plan level encoding, which is a tree vector to represent the physical plan.
Next, the concatenated vector is fed into a tree convolution and another several full-connected layers to predict the latency of the input physical plan.
Our Insights
Summaries
这些提升现有cost model的方法,提示我们,每次产生新的operator时,都要考虑如何衡量他们的cost,如何融入现有的优化过程中。
The methods trying to improve the existing cost model focus on different aspects, e.g., UDFs, hash join in main memory.
These studies leave us an important lesson:
when introducing a new logical or physical operator, or re-implementing the existing physical operators,
we should consider how to add them into the optimization process and design the corresponding cost estimation formulas for them (e.g., [54 , 70 ]).
学习的方法
Leaning-based methods adopt the model to capture the complex relationship between cost and the factors,
while the traditional cost model is defined as a certain formula by the database experts.
The NN-based methods used to predict the performance, estimate cost, and estimate cardinality in Sect. 3.3.1 are quite similar in the features and models selection.
For example, Sun and Li [85 ] use the same model to estimate the cost and cardinality and Neo[67 ] uses the latency (performance) of (sub)plan as the cost.
A model, which is able to capture the data itself, operator level information, and subplan information, can predict the cost accurately.
For example, the work [85 ], one of the state-of-the-art methods, adopts the tree-LSTM model to capture the information mentioned above.
However, all of them are supervised methods. If the workload shifts or the data is updated the models need to be retrained from the scratch.
Possible Future Directions
云环境下的新的Cost模型;学习型的cost model如何落地
There are two possible directions as follows:
(1) Cloud database systems
The users of the cloud database systems need to meet their latency or throughput at the lowest price.
Integrating the economic cost of running queries into the cost model is a possible direction.
It is interesting to consider these related information into the cost model.
For example, Siddiqui et al. [81] consider the number of container into their cost model.
(2) Learning-based methods
Learning-based methods to estimate the cost also suffer from the same problems with methods in cardinality estimation (Sect. 3.4.2).
The model that has been adopted in a real system is a light model [81].
The trade-off between accuracy and training time is still a problem.
The possible solutions adopted in cardinality estimation also can be used in the cost model.
Plan Enumeration
In this section, we present the researches published to handle the problems in plan enumeration.
We classify the work on plan enumeration into two groups: non-learning methods and learning-based methods.
Non‑Learning Methods
Steinbrunn et al. [84] proposed a representative survey for selecting an optimal join orders.
Thus, we mainly focus on the researches after 1997.
Dynamic Programming
比较早期的DP方法,但是采用generate and test的方式,需要不停的check子图的连通性和是否包含,所以性能比较差
Selinger et al. [79] propose a dynamic programming algorithm to select the optimal join order for a given conjunctive query.
They generate the plan in the order of increasing size and restrict the search space to left-deep trees, which significantly speeds up the optimization.
Vance and Maier [93] propose a dynamic programming algorithm to find the optimal join order by considering different partial table sets.
They use it to generate the optimal bushy tree join trees containing cross-products.
Selinger et al. and Vance and Maier [79, 93] are generate-and-test paradigm
and most of the operations are used to check whether the subgraphs are connected and two subgraphs are combinative.
Thus, none of them meet the lower bound in [73].
基于Graph的DP算法,上来就先找出connected子图,不用老是去判断是否连通和包含,性能大幅提升。
并后续文章进行了泛化,解决非inner join和多表join的问题。
Moerkotte and Neumann [68] propose a graph-based Dynamic programming algorithm.
They first introduce a graph-based method to generate the connected subgraph.
Thus, it does not need to check out the connection and combinations and perform more efficiently.
Then, they adopt DP over them for the generation of optimal bushy tree without cross-products.
Moerkotte and Neumann [69] extend the method in [68] to deal with non-inner joins and a more generalized graph, hyper graph,
where join predicates can involve more than two relations.
Top‑Down Strategies
TDMinCutLazy是首先提出Top-down的方式进行join enumeration的,采用minimal cuts划分join图,但是划分出来的join不一定valid,任然是generate and test的方式,比较低效
最大的特点是基于cost bounding预测和累加的剪枝,可以避免DP的暴力穷举
TDMinCutLazy is the first efficient top-down join enumeration algorithm proposed by DeHaan and Tompa [12].
They utilize the idea of minimal cuts to partition a join graph and introduce two different pruning strategies,
predicted cost bounding and accumulated cost bounding into top-down partitioning search, which can avoid exhaustive enumeration.
Top-down method is almost as efficient as dynamic programming and has other tempting properties, e.g., pruning and interesting order.
TDMinCutBranch采用新的graph-based enumeration策略,可以保证只产生valid的join,这样效率大大提升。
TDMinCutConservative更容易实现,进一步提升了执行效率;并且后续论文提出一个通用framework将问题泛化。
Fender and Moerkotte [17] propose an alternative top-down join enumeration strategy (TDMinCutBranch).
TDMinCutBranch introduces a graph-based enumeration strategy which only generates the valid join,
i.e., cross-product free partitions, unlike TDMinCutLazy which adopts a generate-and-test approach.
In the following year, Fender et al. [20] propose another top-down enumeration strategy TDMinCutConservative
which is easier to implement and gives better runtime performance in comparison to TDMinCutBranch.
Furthermore, Fender and Moerkotte [18, 19] present a general framework to handle non-inner joins and a more generalized graph, hyper graph for top-down join enumeration.
RS-Graph, a new join transformation rule based on top-down join enumeration, is presented in [80] to efficiently generate the space of cross-product free join trees.
Large Queries
对于大查询,总体的思路都是采用贪婪,启发或随机,获取局部最优
GOO典型的贪婪,在Join graph上挑join产生结果最小的先做,逐步叠加
For large queries, Greedy Operator Ordering [16] builds the bushy join trees bottom-up by adding the most profitable (with the smallest intermediate join size) joins first.
增量DP是结合贪婪和DP,避免贪婪所造成的局限
有两种增量的方式,所谓增量意思是从k=1开始逐渐增加
IDP1,对于每个K先用DP找出best,然后把这部分固定住,repeat,就是把多表join,变成不断两表join
IDP2,先用greedy算法找出join tree,然后再用DP基于这个join tree找出best plan,然后repeat
To support large queries, Kossmann and Stocker [51] propose two different incremental dynamic programming methods, IDP-1 and IDP-2.
With a given size k, IDP-1 runs the algorithm in [79] to construct the cheapest plan with that size and then regards it as a base relation, and repeats the process.
With a given size k, in every iteration, IDP-2 first performs a greedy algorithm to construct the join tree with k tables
and then runs DP on the generated join tree to produce the optimal plan, regards the plan as a base relation, and then repeats the process.
两阶段,也是结合贪婪和DP,先用贪婪启发简化graph,然后再用DP
Neumann [71] proposes a two-stage algorithm:
first, it performs the query simplification to restrict the query graph by the greedy heuristic until the graph becomes tractable for DP,
and then, it runs a DP algorithm to find the optimal join orders for the simplified the join graph.
Enumerate-rank-merge是对于启发式方法的泛化和扩展
Bruno et al. [5] introduce enumerate-rank-merge framework which generalizes and extends the previous heuristics [16, 86].
The enumeration step considers the bushy trees.
The ranking step is used to evaluate the best join pair each step, which adopts the min-size metric. The merging step constructs the selected join pair.
Adaptive的方法,就是把查询分类,大中小,采用不同的优化方式
Neumann and Radke [72] divide the queries into three types: small queries, medium, and large queries according to their query graph type and the number of tables.
Then, they adopt DP to solve small queries, restrict the DP by linearizing the search space for medium queries, and use the idea in [51] for large queries.
Others
Trummer and Koch [89] transform the join ordering problem into a mixed integer linear program to minimize the cost of the plan
and adopt the existing the MILP solvers to obtain a linear join tree (left-deep tree).
To satisfy the linear properties in MILP, they approximate the cost of scan and join operations via linear functions.
20年的Sigmod论文,讨论AP中的n元join问题
Most of existed OLAP systems mainly focus on start/snowfake join queries (PK-FK join relation) and generate the left-deep binary join tree.
When handling FK-FK joins, like in TPC-DS (snowstorm schema), they inccur a large number of intermediate results.
Nam et al. [70 ] introduce a new n-ary join operator, which extends the plan space.
They define the core graph to represent the FK-FK joins in the join graph and adopt the n-ary join operator to process it.
They design a new cost model for this operator and integrate it into an existed OLAP systems.
Learning‑Based Methods
学习方法,都是基于强化学习
state是当前的查询子树,action是合并两个子树,reward是最终的执行耗时,只有最终reward,没有中间reward
All learning-based methods adopt the reinforcement learning (DL).
In RL, an agent interacts with environment by actions and rewards.
At each step t , the agent uses a policy to choose an action at according to the current state st and transitions to a new state st+1 .
Then, the environment applies the action at and returns a reward rt to the agent.
The goal of RL is to learn a policy , a function that automatically takes an action based on the current state, with the maximum long-term reward.
In join order selection, state is the current sub-trees, and action is to combine two sub-trees, like in Fig. 4.
The reward of intermediate action is 0, and the reward of the last action is the cost or latency of the query.
ReJoin [65] adopts the deep reinforcement learning (DRL), which has widely been adopted in other areas, e.g., influence maximization [87], to identify the optimal join orders.
State in DRL represents the current subtrees. Each action will combine two subtrees together into a single tree.
It uses cost obtained from the cost model in optimizer as the reward.
ReJoin encodes the tree structure of (sub)plan, join predicates, and selection predicates in state.
Different with [65], Heitz and Stockinger [39] create a matrix to represent a table or a subquery in each row and adopt the cost model in [55] to quickly obtain the cost of one query.
DQ[52] is also a DRL-based method. It uses one-hot vectors to encode the visible attributes in the (sub)query.
DQ also encodes the choice of physical operator by adding another one-hot vector.
When training the model, DQ first uses the cost observed from the cost model of the optimizer and then fine-tunes the model with true running time.
Yu et al. [106] adopt DRL and tree-LSTM together for join order selection.
Different with the previous methods [39, 52, 65], tree-LSTM can capture more the structure information of the query tree.
Similar with [52], they also use cost to train the model and then switch to running time as feedback for fine-tuning.
Notice, they also discuss how to handle the changes in the database schema, e.g., adding/deleting the tables/columns.
SkinnerDB [90 ] adopts the UCT, a reinforcement learning algorithm, and learns from the current query,
while the previous learning-based join order methods are learning from previous queries.
It divides the execution of one query into many small slices where different small slices may choose the different join order
and learn from the previous execution slices.
Our Insights
Summaries
Top-down相对于DP看着更好些,毕竟有剪枝的逻辑
The non-learning based studies focus on improving the efficiency and the ability (to handle the more general join cases) of the existing approaches.
Compared with dynamic programming approach, the top-down strategy is tempting(诱人的) due to the better extensibility, e.g., adding new transformation rules, branch-and-bound pruning.
Both of them have been implemented in many database systems.
对于学习的方法,如果落地是个大问题
Compared with the non-leaning methods, learning-based approaches have a fast planning time.
All learning-based methods employ reinforcement learning.
The main differences between them are:
(1) choosing which information as the state and how to encode them,
(2) adopting which models.
A more complicated model with more related information can achieve better performance.
The state-of-theart method [106] adopts a tree-LSTM model similar with [85] to generate the representation of a subplan.
Due to the inaccuracy in the cost model, it can improve the quality of model by using the latency to fine-tune the model.
Although current state-of-the-art method [106] outperforms the non-learning based methods as shown in their experiments,
how to integrate the learning-based method into the real system must be solved.
Possible Future Directions
There are two possible directions as follows:
(1) Handle large queries 对于大查询的top-down的方式
All methods proposed to handle large queries are DP-based methods in the bottom-up manner.
A question is remaining: how to make the top-down search strategy support the large queries.
Besides, the state-of-art method for large queries [72] cannot support the general join cases.
(2) Learning-based methods
Current leaned methods only focus on the PK-FK join and the join type is inner join.
How to handle the other join cases is a possible direction.
None of the proposed methods have discussed how to integrate them into a real system.
In their experiments, they implement the method as a separate component to get the right join order, and then send to the database.
The database still needs to optimize it to get the final physical plan.
If a query has subquery, they may interact multiple times.
The reinforcement learning methods are trained in a certain environment, which refers to a certain database in the join order selection problem.
How to handle the changes in the table schemas and data is also a possible direction.


 浙公网安备 33010602011771号
浙公网安备 33010602011771号