论文解析 -- Db2 Event Store: A Purpose-Built IoT Database Engine (PVLDB 2020)
INTRODUCTION
The Needs of IoT systems
正对IoT系统的以下4点需求,高吞吐,有效存储,实时查询和高可用,当前的系统无法比较好的解决。
With the rapid proliferation(rapid increase in numbers) of connected devices (smart phones, vehicles, buildings, industrial machinery, etc.)
there has never been as great a need to persist data, and make it available for subsequent analytical processing, as quickly as possible.
Traditionally, the data storage and analytics needs of the Internet of Things (IoT) space have been serviced by relational databases, time series databases, or more recently, elements of the Hadoop ecosystem [1].
Unfortunately, none of these technologies were designed for the specific demands of Internet of Things use cases, which include:
• Extremely high-speed data ingestion:
It is not uncommon in IoT use cases to see data arriving at a rate of millions of data points per second.
As the data is typically machine generated, and not generated by humans, it arrives steadily around the clock, resulting in hundreds of billions of events per day.
• Efficient data storage:
Due to the large volume at which data is arriving, efficient storage is essential.
This requires that the system stores data in a highly compressed format, leverages cost effective storage (such as cloud-based object storage),
and ideally automates data retention through techniques such as Time to Live (TTL).
Moreover, since IoT datasets grow so rapidly, it is desirable to store the data in an open data format,
so that it can be directly queried by additional runtime engines and does not require migration should the system be replatformed in the future.
• Real-time, near real-time and deep analytics:
Persisting data is never the end goal.
IoT systems require that the data be made available as quickly as possible to both queries which are interested in a given data point (or collection of data points from a given sensor),
as well as more complex queries which leverage the full power of SQL.
Additionally, IoT data often feeds ML models, such as those used for predictive maintenance.
• Continuous Availability:
IoT data stores are fed by remote data sources, often with limited ability to store data locally.
As a result, in cases where the data store is unavailable for a prolonged period of time, remote data sources may overflow their local storage, resulting in data loss.
Similarly, queries being run on IoT systems are often critical to the business, and even a small interruption could result in significant financial impact [2].
To ensure a complete data history and consistent business insights, IoT systems must remain continuously available.
Related Work: Existing Technologies for IoT Workloads
Traditionally, relational database management systems (RDBMSes) have been used to handle the most challenging of data problems.
As a result, over the last four decades they have evolved from a focus on high speed transaction processing [3], to servicing high performance analytics [4] [5],
and more recently, hybrid transactional/analytical processing (HTAP) workloads [6], which require both fast transactions and analytics.
In this time, they have evolved from running on a single machine, to scaling out to tens or hundreds of machines to leverage both MPP techniques, and/or for high availability.
While this evolution has created shared data architectures that on the surface seem similar to what we propose in this paper [7] [8],
the leveraging of shared storage in these systems is principally for availability, and is not an attempt to leverage cheap and plentiful storage, as is required for IoT workloads.
Furthermore, the dependence on mutable data and strong consistency in most relational systems makes it difficult to leverage eventually consistent cloud-based object storage.
关系型数据库,虽然非常强大,从TP,AP到HTAP,但是由于他的通用性限制了在特定领域的使用,主要是in-place的更新和强一致性,限制了对于云对象存储的使用。
虽然近期出现一些云原生的关系数据库,但是仍然没有在IoT领域被广泛使用
While RDBMSes are unquestionably versatile(多才多艺的), their generalization prevents them from being ideal for several recently identified use cases [9], one of which is IoT workloads.
In IoT workloads, machine generated data is often produced at a rate of millions of events per second – orders of magnitude faster than human generated transactions.
For example, an IoT system producing 1M events/sec (a rate common in the IoT space) will generate more events in a single day than the total number of US stock market trades in a year [10].
This tremendous volume of arriving data plays against the strengths of traditional relational database systems whose WAL techniques favour transactional consistentcy at the expense of ingest performance.
Additionally, since traditional relational database systems update and delete in-place and require strong consistency,
they are not able to directly leverage cloud object storage - the most cost-effective way to store large volumes of data in the public cloud.
While recent cloud-native relational database systems are now able to leverage cloud object storage [11, Snowflake] [12, Redshift]
and have made a concerted (齐心协力的) effort to separate compute and storage to improve transactional availability [13, Aurora], they have not yet gained widespread adoption for IoT workloads.
时序库方案的局限
Over the last decade, time series databases have dramatically increased in popularity [14] and have become the repositories of choice for IoT data.
While time series databases are able to rapidly ingest data and store time series data efficiently, many of them, such as InfluxDB [15], Kdb+ [16], 不支持SQL,可用性无法保证
use a non-SQL compliant query language [17] [18], and struggle with true continuous availability [19].
There do exist time series databases which support SQL, such as TimescaleDB [20], however we show in section 3 that they have limitations in terms of ingest and query performance. 读写性能无法满足
Also, none of these time series databases leverages an open data format or can directly leverage object storage to efficiently handle the massive volume of data generated by IoT systems. 不支持开放格式,无法直接部署对象存储
Hadoop系统的问题,复杂度和成本较高
To counter the limitations of time series databases, a wave of Hadoop and open-source based systems, like Apache Druid [22], have been employed for high speed data use cases with some success [23] [24] [25].
These systems are typically architected according to the Lambda Architecture whereby(从而) one data store is used to persist data quickly (typically a time series database or KV store)
and provide near real-time analytics, while a second system is used for deep analytics [26].
The Lambda Architecture however, suffers from complexity (multiple systems to maintain), stores a non-trivial portion of the data in two places (resulting in higher storage costs),
and is difficult to query, as application designers have to understand which of the disparate systems to query for a given use case.
Furthermore, many of the systems, on which Lambda is built, struggle to achieve the required ingest speeds required for IoT workloads, without a significant hardware footprint [27].
有些类似的方案只是内部使用或没有清楚说明
More recently systems have emerged which are tackling(解决) similar requirements to those found in IoT systems.
Unfortunately, these newer systems are either restricted to internal use [28] or are opaque [29, 30].
ARCHITECTURE
Architectural overview
Db2 Event Store leverages a hybrid MPP shared nothing / shared disk cluster architecture .
The combination of shared nothing and shared disk architectures allows it to combine the linear scalability attributes of a traditional MPP shared nothing data store with the superior availability,
and cloud-native characteristics of a shared data system.
The system is constructed by combining a new cloud native storage layer with Db2’s existing BLU MPP columnar database engine [5].
Table data is physically divided into micro-partitions based on a user defined hash partitioning key, and stored on a reliable shared storage medium such as cloud object storage 按用户定义的key将表的数据分区,micro-partitions,并存储在共享存储上
(e.g. IBM Cloud Object Storage [32]) , a network attached storage device (such as IBM Cloud Block Storage [33]), or a cluster filesystem (such as Ceph [34] or IBM Spectrum Scale [35]).
The entire dataset is fully accessible by all compute nodes in the cluster, decoupling the storage from the compute and enabling each to be scaled independently.
Shared nothing架构,partition的leader的均匀分配和failover,commonsense
MPP shared nothing scale-out for ingest and query processing is achieved by logically dividing the leadership of micro-partitions across the available compute nodes, coordinated through the consistent meta-store Apache Zookeeper [36].
Each micro-partition is logically owned by one and only one compute node at any given point in time and any requests to read or write that micro-partition are executed via the owning compute node, enabling query and ingest parallelism across the cluster.
By ensuring a sufficiently large number of micro-partitions relative to the number of compute nodes the system ensures sufficient granularity in the data partitioning to allow an even distribution of data leadership across the compute nodes in the presence of node failures.
When handling node failures, the affected micro-partitions are logically reassigned amongst the remaining compute nodes that are replicas of the failed micro-partitions, substantially reducing the failover time compared to a model that requires data migration [37],
and allowing processing to continue with minimal disruption.
避免元数据单点,floating catalog,元数据其实是存在共享存储的,只是通过一个node暴露出来,所以failover会非常简单
To ensure that database metadata does not become a single point of failure and to maintain the desired continuous availability,
the system implements the concept of a “floating” catalog node where catalog information is stored on a reliable shared filesystem and exposed via a logical node that can be restarted on any of the compute servers in the event of a failure.
Fast ingest in this architecture is achieved through a combination of parallelism and optimized storage techniques.
The system implements a headless cluster architecture where all compute nodes play the dual role of head and data nodes. 无主节点,所有节点都可以数据写入
This allows ingest to be parallelized across the entire cluster and removes any potential for a head node ingest bottleneck.
Within the server, ingested records are mapped to specific micro-partitions by Db2’s MPP hash partitioning function and shipped to the owning members via Db2’s internal cluster communication infrastructure.
On the storage side, data is written into fast local storage (SSD or NVMe) devices present on each of the compute nodes, and it is further replicated and written to the local storage on at least two other compute nodes before acknowledging commits. 至少3副本完成写入
This ensures availability of the data in the event of a compute node failure.
The data is then asynchronously written to durable shared storage. 异步同步共享存储
This model allows the system to avoid any extra latency that might otherwise be incurred from the shared storage medium
(particularly in the case of high latency cloud object storage) and allows the architecture to efficiently accommodate both small and large inserts.
It should be noted that this model implies that micropartition leadership must be aligned with the replica locations,
but this affinity is also desirable as it has the beneficial side effect of enabling better data cache locality.
Ingested data can be optionally aged out of the system via a time-to-live (TTL) mechanism, configured at the table level. 自动过期
The ingested data is stored in an open data format (Apache Parquet [38]) which leverages a compressed PAX storage format
which can be efficiently utilized for analytics processing by Db2’s BLU columnar runtime engine.
The use of an immutable open data format also allows for the data to be queried directly by external runtime engines (e.g. Hive, Spark, Presto). 开放格式,Parquet,便于外部引擎分析
In order to support the cost and scalability benefits of cloud object storage,
which may not have strong consistency guarantees for modified data, the system leverages an append-only immutable storage model where data blocks are never re-written.
Synopsis(摘要) metadata information, which allows for data skipping during query processing, is automatically generated as part of the ingest process and is written in separate Parquet files,
allowing for synopsis data to be accessed and cached separately from the table data. 摘要,类似SMA,max,min是被存储在独立的Parquet文件,这样便于访问和cache
Indexing is also supported and is implemented as an UMZI index [39] leveraging an LSM-tree style format to adhere to the append-only requirement. 索引采用LSM Tree,异步生成
Indexes are generated asynchronously as part of the data sharing process to minimize the latency on ingest processing.
This also means that duplicate key elimination occurs during data sharing processing.
Db2 Event Store implements a first-writer-wins (FWW) semantic when ingesting into tables with primary keys defined.
FWW ensures that the first landed version of a row (where a distinct row is defined by its associated primary key)
is never replaced if in the future different versions of the same row (i.e. the primary key is the same) are ingested.
Db2 Event Store query processing is SQL based, and is enabled through Db2’s industrial grade Common SQL Engine (CSE)
which includes its cost-based SQL optimizer and BLU columnar runtime [4]. CBO的优化器和Columnar的Runtime
The Db2 CSE is integrated into the Db2 Event Store storage layer and allows for the ability to exploit Db2 Event Store’s synopsis-based data skipping as well as its indexes.
This integration allows Db2 Event Store to offer high speed analytics using parallel SQL processing, JDBC/ODBC connectivity, and full Db2 SQL compatibility.
Last but not least, efficient data access is achieved through a multi-tiered caching layer that caches frequently accessed data, synopsis and index blocks in-memory, 多层cache
and also on fast local storage on the compute nodes, in order to absorb latencies that would otherwise be incurred when exploiting cloud object.
Data format and meta-data
Leveraging an open data format - Apache Parquet
When choosing a data storage format, it was desirable to leverage one that was columnar organized, due to the performance advantages when processing analytics workloads.
In addition, it was highly desirable to utilize an open format, that would allow access by external readers and avoid data lock in.
In search for an open column organized format we decided on Apache Parquet [38], as it is widely adopted and supported by many readers (e.g. Spark, Hive, Presto [40]).
In addition, Apache Parquet is a self-describing format, which is accomplished by including the schema (column name and type) in each of the files.
Db2 Event Store uses Snappy [41] compression to reduce the storage footprint.
Snappy compression was chosen as it represented the best trade-off between storage size and ingest/query impact.
GZIP [42] and LZ4 [43] were also considered as options, but GZIP incurred a much higher overhead for both ingest and query performance,
and at the time of our initial evaluation LZ4 was new to the Parquet specification and did not have widespread adoption in some of the Parquet readers.
We plan to reinvestigate LZ4 compression now that it is more prevalent in the Parquet ecosystem.
As described above, the Db2 Event Store architecture leverages a micro-partitioned data model.
With this architecture the finest granularity of a table is a table micro-partition.
Parquet files belong to micro-partitions and thus a given Parquet file contains the data of exactly one table micro-partition. micro-partition和Parquet file对应,1对多
The Parquet files are immutable once written.
Each Parquet file for a table micropartition is assigned a monotonically increasing number, referred to as its tablet identifier.
The Db2 Event Store runtime engine and external readers use this to infer that higher tablet identifiers represent newer data.
The metadata for the Parquet files in shared storage is maintained in Apache Zookeeper.
This includes the high watermark tablet identifier of each micro-partition.
Within the Db2 Event Store engine, tuples are identified through a Tuple Sequence Number (TSN), an integer that may be used to locate a given tuple within a table.
A TSN in Db2 Event Store includes the tablet identifier, the zone (Pre-Shared vs Shared; when data is ingested it moves through several zones which are described in detail in section 2.3),
and the offset of the tuple within the Parquet file.
Writing and reading of Parquet files within the database engine is done using an open source C++ parquet library [44].
To minimize the amount of read IO we implemented a custom reader in the C++ parquet library that serves read requests from a local cache.
The local cache is discussed in more detail in Section 2.4 Multi-tiered caching.
Ensuring fast ingestion
One of the key design characteristics to allow Db2 Event Store to handle the fast ingestion rate common in IoT scenarios is that
it organizes the data in a table into multiple zones, and it evolves the data asynchronously from one zone to the next as the data ages.
As described in Section 2.1, the data is first ingested into fast local storage.
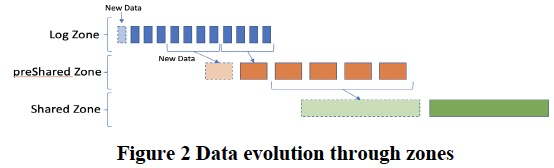
思路都大同小异,保证写入,Log Zone是最简单的,只是简单的写入多副本;后续的zone,转换格式便于存储,增加索引便于查询等
This is the first data zone called the Log Zone.
Data in this zone is replicated to remote nodes to ensure durability and high availability.
From the Log Zone, the data is moved to additional zones with the goal to persist it on cost effective shared storage, make it available to external readers, and most importantly, continuously optimize it for query performance.
There are two additional zones:
the data is first moved from the Log Zone to the Pre-Shared Zone, and then from the Pre-Shared Zone to the Shared Zone.
All of these zones are transparent to the end user, who sees a single view of the table without having to worry about the continuous evolution of the data through the zones.
All of these zones are immutable.
One critical design point is that the log is the database – the Log Zone is not just written to local storage to guarantee durability like in traditional database systems that implement write-ahead logging,
but is also directly utilized to service query results.
Figure 2 shows a high-level view of the zones and the evolution of the data from one to the next one.
Logging ingestion
Ingest processing starts with the Db2 Event Store client, which provides an API for asynchronous batch inserts. 提供异步batch插入增大吞吐
This client can connect to any of the nodes to perform ingest, and in the case of failures will automatically resubmit the batch insert to any of the other nodes.
The node that the client is connected to is referred to as the “ingest coordinator”. 写入需要有个master,来按照hash把数据分到各个micro-partitions上,后面就是典型的多副本同步的方案
The role of the node acting as a coordinator for the batch is to perform the hash partitioning of the batch into the corresponding micro-partitions,
and then direct the micro-partition batch to one of the micro-partition replicas.
When the micro-partition batch is received by a micro-partition replica it is placed in the Log Zone in the form of log buffers, that are persisted to local storage and replicated to multiple remote replicas,
each of which persist to local storage before acknowledging, to guarantee durability and availability.
Each micro-partition maintains its own set of replicas and the insert is only considered successful once it has been acknowledged by a quorum of replicas (R/2+1) for each micro-partition impacted.
By default, the replication factor R is 3.
Both replication and acknowledgements are batched to improve the efficiency of the replication and to guarantee both the persistence and availability of the ingested data.
This data is available for querying as soon as it is replicated to a quorum of nodes (i.e. before the data is enriched through synopsis or indexing).
To ensure high performance ingest, log data must be stored on fast local storage (SSD or NVMe devices) to ensure low latency for the only synchronous portion of the data persistence lifecycle.
Data enrichment
The Log Zone enables quick persistence and durability, but it is not optimal for querying.
As a result, recently ingested data must be moved to a more query friendly format as soon as possible and be enriched with additional data structures, like indexes and synopsis. enrich主要就是增加便于检索的结构,包含索引和摘要
This allows for more efficient querying, at the expense of the additional latency (in the order of seconds), which is sufficient for most IoT applications.
The next zone after the Log Zone is the Pre-Shared Zone, which is stored in shared storage. Pre-Shared Zone是Log Zone的下一个阶段,转换可以在任意副本上进行,一般是leader
The process of “sharing” a table micropartition can be done by any of the replicas, as all have a copy of all the log buffers,
but Db2 Event Store gives preference to the micro-partition leader, which can be re-assigned dynamically on failures or due to load re-balancing.
As an iteration of data persistence to the Pre-Shared Zone is completed, the transition point between zones, and the Pre-Shared Zone tablet metadata, is tracked in the consistent meta-store Apache Zookeeper.
This allows for a seamless transfer of leadership between nodes and enables consistency of the objects in shared storage.
Data that has been pre-shared is subsequently purged from the Log Zone, which is completed
when Log Zone readers are drained out from the already persisted area (queries that are reading this data from the Log Zone must complete before the data can be purged).
Moving data from the Log Zone to the Pre-Shared Zone is fast (typically on the order of seconds).
As a result, Parquet files written to the Pre-Shared Zone may be small, as each Pre-Share iteration can only consider the data written since the last Pre-Share iteration, Pre-Share的过程是比较频繁的,所以这个阶段的Parquet files很小,不利于查询
and therefore not optimally sized for query processing (where large files – on the order of 10s or 100s of MBs are ideal).
For this reason, once there is enough volume of data in the Pre-Shared Zone, the small files are consolidated to generate much larger Parquet files in what is called the Shared Zone.
Larger files enable more efficient query processing and better overall data compression so typical consolidated files are in the range of 64MB in size. 所以会把Pre-Share Merge成更大的文件,便于查询和压缩,Shared Zone
The Shared Zone is the final zone and so files remain there forever (or until the expiration time is reached if TTL is configured for the table).
Finally, to avoid having multiple copies of data, the Pre-Shared Zone is also purged, like the Log Zone, once a set of files from the Pre-Shared Zone have been written successfully to the Shared Zone,
the sharing state is registered in the consistent metastore, and the pre-shared files purge is initiated once they are drained of concurrent queries.
Persistence to cheap storage
The database engine was designed to exploit a storage hierarchy that includes memory, fast local storage within each node for fast persistence,
and finally cost-efficient storage to maintain the very large volume of data.
One of the challenges of supporting cost-efficient object stores is that their consistency guarantees vary.
For that reason, the files written by Db2 Event Store are never updated, 为了利用云对象存储,所以需要append-only;另外考虑性能,后面考虑多级缓存
and Apache Zookeeper is used as consistent data store to record the state of objects in the cost-efficient object store.
The other challenge of cost-efficient object stores is their performance,
and for this reason in Section 2.4 we discuss the multi-tiered caching, that significantly reduces the performance impact of accessing files in persistent storage.
Building Indexes and Synopsis
Providing an indexing structure for an IoT data store is challenging for multiple reasons.
First of all, at the rate of ingest that Db2 Event Store was designed to support, the volume of data grows rapidly.
As an example, for a 3-node cluster, at 1 million inserts per second per node, with 40-byte events, the volume grows by 3.5 PB/year or 9.5 TB/day of uncompressed data.
This volume of data is one of the motivating factors for supporting cost-efficient object storage, but this brings about new challenges:
dealing with eventual consistency, and the high latency reads and writes discussed above.
To get around the eventual consistency limitation of updates to object storage, index files must be written once, and never overwritten.
A final challenge is to provide a unified index structure that can index the data across the multi-zone architecture.
All of these requirements must be satisfied while still providing very fast index access for both range and point queries.
The index in Db2 Event Store is a multi-zone index, covering the Pre-Shared and Shared Zones. 索引只覆盖后面两个zone;在Pre-Shared Zone的阶段生成index
The index does not cover the Log Zone as it would require synchronous maintenance and maintaining the index synchronously would increase insert latency.
Furthermore, it is more efficient to maintain the index asynchronously when large amounts of data are moved to the Pre-Shared Zone,
which happens only seconds after being ingested into the Log Zone.
The index within a zone follows an LSM-like structure with both multiple runs and multiple levels, based on the UMZI index [39].
This kind of indexing structure is well suited for the high volume of writes, as it can be constantly re-optimized.
As the data pre-sharing is generating an Apache Parquet file from the data in the Log Zone,
it also generates the corresponding compressed index run (See Figure 3 Index Runs together with the pre-sharing processing).
Generating the index run at this time is also very efficient, as the complete run generation is done in memory, from the data in the Log Zone, which is also in memory.
With IoT data, duplicate values are relatively uncommon, and are typically the result of a sensor sending the same data value multiple times (often in close succession).
For this reason, duplicates are most commonly found in the recently ingested data, which is still resident in memory.
To ensure no duplicate data, when a new index run is being generated from the Log Zone, the system performs index lookups to ensure the primary key uniqueness is maintained. 去重
The system keeps the most recent index runs and an index synopsis for older runs in the local cache. 最新的数据保留index,老的数据保留synopsis(会记录pk的range)
The index synopsis data, which contains primary key ranges that for IoT systems always include a timestamp,
is particularly helpful in ensuring efficient primary key uniqueness lookups since the bulk of the data already loaded into the table will have older timestamp values.
Since the local cache is multi-level to exploit the storage hierarchy, the index runs are maintained both in memory and in the local SSD/NVMe devices,
and the most efficient look ups are for runs that are still in the inmemory level of the cache.
We will discuss the details of the multilevel cache management in Section 2.4.
In the same way that the data is evolved from the Pre-Shared to the Shared Zone, the index is also evolved, by merging multiple index runs into a single and much larger index run. 转换到Shared Zone的时候,需要把index进行merge
As the volume of data grows, and the number of runs grows, the performance of the index would degrade without merging as more runs must be consulted for each index lookup.
For this reason, the system maintains multiple levels of the index, continuously merging runs from one level into larger runs in the next level to reduce the number of overall runs.
As new runs are generated in the next level, the runs in the previous level are purged by a background garbage collection process, to reduce the storage cost.
All of this is done while still maintaining the consistency of the index, both for in-flight queries and in the persisted copy, so that the index can be rebuilt on restart.
Another important point to note is that all the runs from all levels are persisted to shared storage.
This is required as the micropartition assignment to nodes is dynamic, so the persistence of runs to shared storage is required to allow the transfer of micropartitions from one node to another.
When a micro-partition is reassigned, the database engine initiates a background process to warm up the local cache of the new micro-partition leader,
therefore enabling index access to reach top performance again as quickly as possible.
To enable data skipping in table scans, Db2 Event Store automatically creates and maintains an internal synopsis table for each user-created table. 维护Synopsis为了便于data skipping, Synopsis也是独立的Parquet文件格式
Similar to the data synopsis of Db2 BLU [4] and IBM Cloud SQL Query [49],
each row of the data synopsis table covers a range of rows of the corresponding user table and contains the minimum and maximum values of the columns over that row range.
Blocks of the data synopsis are also in Parquet format.
Note that the data synopsis, when applicable, is likely to be cached (see Section 2.4) as it is small and accessed fully in each table scan that qualifies for data skipping.
This data synopsis, which is distinct from the index synopsis, is populated as data are consolidated into the Shared Zone and so does not cover the data of the Pre-Shared and Log Zones. Data Synopsis仅仅覆盖Shared Zone
Maintaining data synopsis content for these zones would come at considerable additional cost (extra writes to shared storage) and would provide little value from data skipping given that the volume of data in these zones is small.
Multi-tiered caching
Traditionally modern high-performance DBMS systems either are in-memory, and thus rely on RAM for performance,
with resiliency coming from multi-node replication and a weak story on power outages (with either slow full cache rebuilds or worse yet, data loss),
or use high performance network storage like IBM Cloud Block Storage [33].
Given that cheap cloud Object Storage, on the order of $0.01 USD/GB/month [50] is high latency, and high-performance storage is generally at least 10X the cost of object storage,
the challenge is how to leverage inexpensive storage and still provide optimal performance.
The approach taken by Db2 Event Store is multi-tiered caching for both data and index objects,
that is able to leverage both memory and fast local storage to insulate(隔离) the system from the high-latencies of Object Storage.
Challenges of leveraging high-latency storage
Db2 Event Store employs many mechanisms to take full advantage of caching within its Cache Manager component.
• Multi-layered Caching:
To insulate the system from Object Storage latencies,
both local SSD/NVMe devices and RAM are used for caching of data block and index objects.
While utilizing a main memory cache is of course not new,
mixing it with SSD/NVMe and the introduction of an epoch-based lock free eviction technique does introduce novelty. 内存结合SSD/NVMe,并且epoch-based 无锁的eviction技术
• Directed Caching:
The multi-tiered caching offers several access methods as outlined above in Figure 4.
Data and index block construction creates the objects in both the cache and object storage.
Cache access may be directed based on request type to either RAM only, as is used by some short-lived index structures in the LSM tree,
or directed to local SSD/NVMe devices with optional placement in the RAM cache as well.
The cache manager also allows for non-RAM cached reads, utilizing only SSD/NVMe for which callers supply a private buffer
when it is known that retrieved content is unlikely to be re-used, such as for retrieval of data that will be rewritten soon into a more concise format
or data that is copied to data structures outside the cache manager (e.g. synopsis information for query acceleration).
Also, the caching tiers may be bypassed completely allowing direct cloud storage access when accessing potentially cold table data.
This is generally related to probabilistic caching described below.
• Probabilistic Caching:
To deal with a limited cache size as compared with the table or index data, the Cache Manager utilizes probabilistic techniques similar to those used in Db2 BLU [4].
These techniques avoid the cache flooding issue when high volume accesses like large table scans occur, but will still build up a cache of the hot objects over time.
The subsystem leverages statistics on the total sizes of the different table and index data for the objects being accessed,
and computes a probability of caching block requests relative to data used by a given query, and the total managed cache space. 基于概率的Caching,建立概率模型,避免每次都flooding cache,比如在scan的时候
The decision is performed by the block storage layer utilizing statistics maintained by the cache manager.
Making the decision upstream allows for taking into account semantic information like a priority for synopsis caching vs. traditional table data caching.
• Soft & Hard Limits:
The caching infrastructure uses a soft limit for memory while imposing a hard limit on non-volatile storage usage.
RAM based caching evictions (discussed below) happen generally in a relaxed fashion, 对于RAM的cache采用比较宽松的eviction策略,但是对于SSD采取严格的限制,why?内存释放更快?
engaging a background process at 100% of target utilization and attempting to bring memory utilization to 80% before resting again.
However, should the RAM target be found to exceed 125%, which may occur in a very busy system,
then a more aggressive eviction technique is utilized by performing immediate releases upon dereference(取消引用) of any memory objects.
For SSD/NVMe the Cache Manager provides extensions of space up to a requested target limit, but when that is reached, caching requests are blocked,
and the users of the subsystem will fall back to RAM only caching, or skip caching altogether depending on the use case.
• Epoch based eviction:
The eviction of both the RAM data and the SSD/NVMe data is managed by a lock free epoch-based technique that utilizes a small, on the order if 1 byte, epoch id.
This both saves metadata storage space and allows for quick scans with fewer TLB misses.
Atomic operations that obtain reference counts protect objects from going away at inopportune moments without the costs of mutex operations.
More detail on the LRU cache replacement algorithm is provided in the next section.
Batchwise-LRU Cache Replacement
Caching for a cloud-native database system such as Db2 Event Store introduces distinct challenges:
• Object sizes vary widely in Db2 Event Store, from small objects such as index run meta-data objects (small number of KBs) and the small data blocks of the most recently data in the Pre-Shared Zone,
to the large consolidated data blocks of the Shared Zone and the blocks of higher level runs of the index (both of which are on the order of 100 MBs). 需要cache的对象的大小是不固定的,差异很大,而传统的buffer pool或OS的cache是针对固定大小的小page设计的
Existing cache replacement algorithms, such as those used in traditional DBMS buffer pools and operating systems, are designed to handle small,
fixed-size pages and are reactive in nature, evicting a page on demand when a new page is needed.
Such page replacement methods are not well-suited to handling objects of widely varying sizes.
• Adaptive cache replacement algorithms, such as LRU, LRU-2 [51] and ARC [52], that are known to work well for a wide variety of workloads,
often require global locks at object access and/or eviction time. 传统的LRU,ARC等replacement算法都需要全局锁
Such global locks limit scalability in the presence of concurrent accesses.
To address these caching challenges, Db2 Event Store implements a batchwise-LRU eviction algorithm using epochs, that is scalable and works well for variable-sized objects.
Cache eviction in Db2 Event Store is done by background threads, with one thread for object eviction from cache-managed RAM and a second thread for eviction from cache persistent node-local storage.
Object eviction is triggered when cache usage for the given storage type reaches a configurable start threshold (e.g. 95%) and objects are evicted until usage is reduced to the stop threshold (e.g. 90%).
This pro-active eviction ensures that there is space in the cache at all times for objects of all sizes at the cost of a small loss of cache space (<10%).
Tracking of object accesses is done using epochs.
The epochs (which wrap over time) are much smaller than full timestamps, with only 1 byte needed to be able to evict in 1% of cache size increments. 描述一种无锁的基于epoch的eviction方法
The use of small epoch values minimizes the memory overhead for tracking object accesses.
In addition, for objects in persistent cache storage, the access epochs are recorded contiguously in an array in the object directory memory of the cache.
Contiguous storage and small epoch size enable the LRU objects to be identified efficiently via a scan for the purge epoch, which is the oldest active epoch in the system.
At eviction time, objects last accessed in the purge epoch are evicted until either none remain, or the target threshold is reached.
If more cache space is to be freed, the purge epoch is incremented, and objects last accessed in this epoch are evicted.
Given that there is a single background thread, no global lock is needed for eviction.
Epochs are implemented as atomics and as they are updated relatively infrequently, recording object accesses does not limit scalability.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号