Presto: SQL on Everything
Presto是FB开源出来的实时分析引擎,可以federated的从多种数据源去读取数据,做联合查询,支持实时Interactive BI或bath ETL的需求


从其问题域来看,基本是和spark是重合的,那么两者区别是什么?
https://stackoverflow.com/questions/50014017/why-presto-is-faster-than-spark-sql


这两个答案说的比较清楚,
所以可以看出,Presto并没有什么创新的东西,对于Spark而言,主要是做减法,降低overhead,提升性能
所以Presto更偏实时一些,更适用于MPP的场景,较为简单的SQL
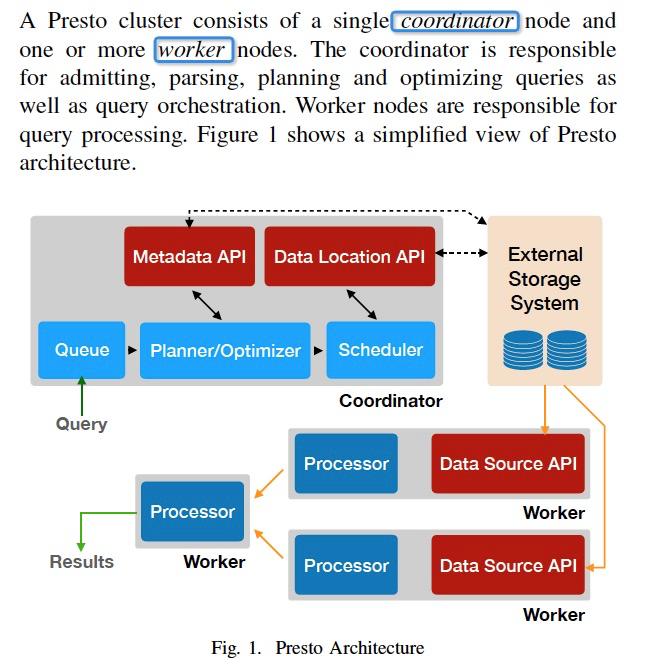
Presto的架构和查询流程,都是典型的MPP方式
特点是,执行都是pipeline的方式,所有中间数据和状态都放在内存中,这样比spark那样落盘,再读出的方式要快

查询过程,
首先是parsing,并形成逻辑计划,
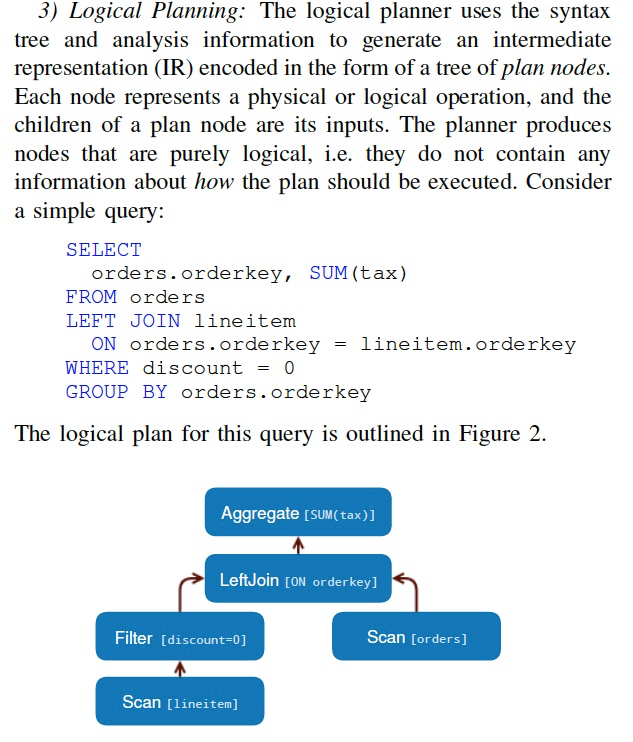
接着是查询优化,和生成物理执行计划
Presto的查询优化没啥创新的
需要注意的是,
首先他也有stage的概念,和spark一样,stage里面可以直接local完成的,所以上面的逻辑计划,
被分成5个stage,stage之间需要shuffle,做过流系统的都知道,一旦shuffle,性能就不行了,对cpu,网络,buffer的消耗都很大
Inter-node,节点间的并行,通过在不同的worker上并行相同的task,处理不同的数据split

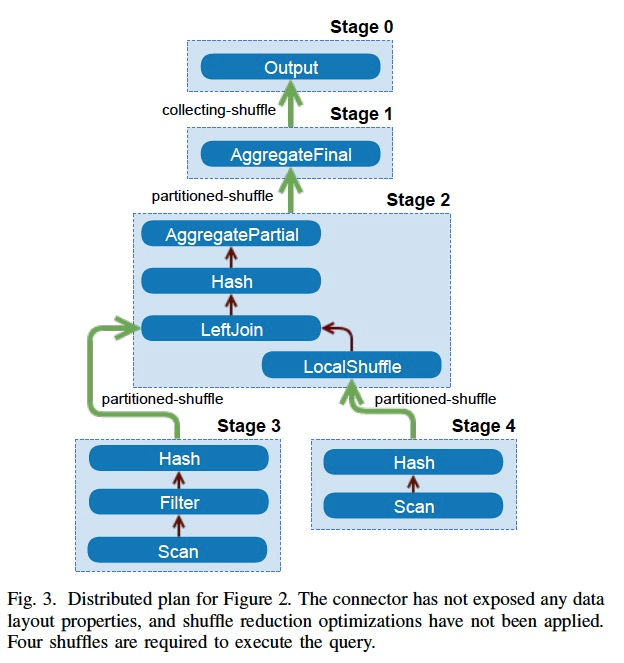
所以思路一定是要尽量减少shuffle,思路也比较直观,比如做join,如果相同join id的数据都在一个节点,就不用shuffle
这个就叫,Data Layout Properties,数据分布

还有,Node Properties,根据node的属性来,减少不必要的shuffle,合并stage


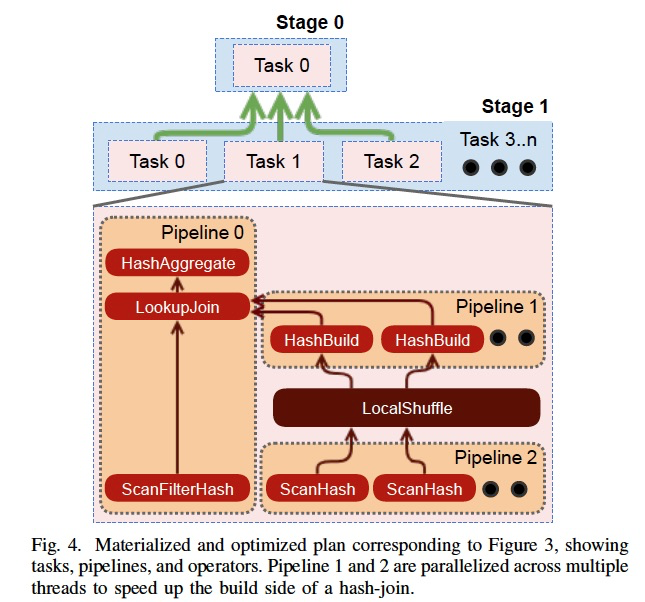
再者,看看Intra-node,节点内的并行,通过thread,这个应该是Presto的特点,可以大大提升查询性能
右图可以看出,在pipeline1,pipeline2中加了很多并发的thread来并行的做

计划生成完后,就是调度,
Coordinator将plan stages以可执行tasks,分发到各个workers上去,task一个执行单元
Task中又包含很多pipelines,pipeline由operators组成

调度分为3种,
Stage调度,可以all in,或分阶段
all in,延迟会小,但会耗费更多的资源

Task Scheduling,

Split Scheduling
最终还要给各个leaf stage分配splits,因为leaf stage必须要被分配splits后才能启动
presto这里的优化,先只会enumerate一小批的splits,分配给各个task,不会一下把所有的splits都捞出来分配,优点下面也说了


调度完,最后就是执行
Query Execution
开始执行,driver loop开始pass split
这里产生page的概念,source从split读出的结构就是pages,Operator的输入输出也是pages,类似spark中的RDD
从右图可以看出,page是一种以column方式组织的结构,便于AP


第二步是shuffle,
presto是延迟优先的,所以shuffle的中间结果不能落盘,放在memory buffer里面
其他worker通过Http Long-Polling的方式来拉数据
同时要监控,output和input的buffer的使用情况,来调整并发,避免内存占用过高
output buffer太大了,让写并发降一些,如果input buffer太大,让读并发降些,这样也会触发前面的写并发的反压

最后是把结果写出,
写吞吐如果要高,多开写并发,但是写并发高,对存储的要求就比较高,
比如对于S3,每个并发都需要写一个文件,会导致很多小文件,查询起来就很麻烦
Presto采用的是adaptive来决定写并发


 浙公网安备 33010602011771号
浙公网安备 33010602011771号