论文解析 -- The Snowflake Elastic Data Warehouse
摘要
We live in the golden age of distributed computing.
(背景,云平台和Saas)Public cloud platforms now offer virtually unlimited compute and storage resources on demand.
At the same time, the Software-as-a-Service (SaaS) model brings enterprise-class systems to users who previously could not afford such systems due to their cost and complexity.
(问题,传统数仓针对固定资源,固定负载,当前背景下,这些都是变化的)Alas, traditional data warehousing systems are struggling to fit into this new environment.
For one thing, they have been designed for fixed resources and are thus unable to leverage the cloud's elasticity.
For another thing, their dependence on complex ETL pipelines and physical tuning is at odds with the flxibility and freshness requirements of the cloud's new types of semi-structured data and rapidly evolving workloads.
(提出snowflake,什么snowflake)We decided a fundamental redesign was in order.
Our mission was to build an enterprise-ready data warehousing solution for the cloud. The result is the Snowake Elastic Data Warehouse, or \Snowake" for short.
Snowake is a multi-tenant, transactional, secure, highly scalable and elastic system with full SQL support and built-in extensions for semi-structured and schema-less data.
The system is offered as a pay-as-you-go service in the Amazon cloud. Users upload their data to the cloud and can immediately manage and query it using familiar tools and interfaces.
(开发运行情况)Implementation began in late 2012 and Snowake has been generally available since June 2015.
Today, Snowake is used in production by a growing number of small and large organizations alike.
The system runs several million queries per day over multiple petabytes of data.
(论文的大体结构)In this paper, we describe the design of Snowake and its novel multi-cluster, shared-data architecture.
The paper highlights some of the key features of Snowake: extreme elasticity and availability, semi-structured and schema-less data, time travel, and end-to-end security.
It concludes with lessons learned and an outlook on ongoing work.
INTRODUCTION
(云计算的背景)The advent of the cloud marks a move away from software delivery and execution on local servers, and toward shared data centers and software-as-a-service solutions hosted by platform providers such as Amazon, Google, or Microsoft.
The shared infrastructure of the cloud promises increased economies of scale, extreme scalability and availability, and a pay-as-you-go cost model that adapts to unpredictable usage demands.
(从两个方面,谈传统数仓技术无法适应云计算的要求)But these advantages can only be captured if the software itself is able to scale elastically over the pool of commodity resources that is the cloud.
Traditional data warehousing solutions pre-date the cloud. They were designed to run on small, static clusters of well-behaved machines, making them a poor architectural fit.
But not only the platform has changed. Data has changed as well.
It used to be the case that most of the data in a data warehouse came from sources within the organization: transactional systems, enterprise resource planning (ERP) applications, customer relationship management (CRM) applications, and the like.
The structure, volume, and rate of the data were all fairly predictable and well known.
But with the cloud, a signicant and rapidly growing share of data comes from less controllable or external sources: application logs, web applications, mobile devices, social media, sensor data (Internet of Things).
In addition to the growing volume, this data frequently arrives in schema-less, semi-structured formats [3].
(大数据平台也不能满足需求)Traditional data warehousing solutions are struggling with this new data.
These solutions depend on deep ETL pipelines and physical tuning that fundamentally assume predictable, slow-moving, and easily categorized data from largely internal sources.
In response to these shortcomings, parts of the data warehousing community have turned to "Big Data" platforms such as Hadoop or Spark [8, 11].
While these are indispensable tools for data center-scale processing tasks, and the open source community continues to make big improvements
such as the Stinger Initiative [48], they still lack much of the effciency and feature set of established data warehousing technology.
But most importantly, they require signicant engineering effort to roll out and use [16].
We believe that there is a large class of use cases and workloads which can benefit from the economics, elasticity, and service aspects of the cloud, but which are not well served by either traditional data warehousing technology or by Big Data platforms.
(所以我们提出snowflake)So we decided to build a completely new data warehousing system speci cally for the cloud.
The system is called the Snowflake Elastic Data Warehouse, or "Snowake".
In contrast to many other systems in the cloud data management space, Snowake is not based on Hadoop, PostgreSQL or the like.
The processing engine and most of the other parts have been developed from scratch.
(sf具备的主要的features)The key features of Snowake are as follows.
Pure Software-as-a-Service (SaaS) Experience Users need not buy machines, hire database administrators, or install software.
Users either already have their data in the cloud, or they upload (or mail [14]) it.
They can then immediately manipulate and query their data using Snowake's graphical interface or standardized interfaces such as ODBC.
In contrast to other Database-as-a-Service (DBaaS) offerings, Snowake's service aspect extends to the whole user experience.
There are no tuning knobs, no physical design, no storage grooming tasks on the part of users.
Relational Snowake has comprehensive support for ANSI SQL and ACID transactions.
Most users are able to migrate existing workloads with little to no changes.
Semi-Structured Snowake offers built-in functions and SQL extensions for traversing, attening, and nesting of semi-structured data, with support for popular formats such as JSON and Avro.
Automatic schema discovery and columnar storage make operations on schema-less, semi-structured data nearly as fast as over plain relational data, without any user effort.
Elastic Storage and compute resources can be scaled independently and seamlessly, without impact on data availability or performance of concurrent queries.
Highly Available Snowake tolerates node, cluster, and even full data center failures.
There is no downtime during software or hardware upgrades.
Durable Snowake is designed for extreme durability with extra safeguards against accidental data loss: cloning, undrop, and cross-region backups.
Cost-effcient Snowake is highly compute-ecient and all table data is compressed.
Users pay only for what storage and compute resources they actually use.
Secure All data including temporary les and network traffic is encrypted end-to-end.
No user data is ever exposed to the cloud platform.
Additionally, role-based access control gives users the ability to exercise negrained access control on the SQL level.
(再次说明运行情况,和abstract中类似)Snowake currently runs on the Amazon cloud (Amazon Web Services, AWS), but we may port it to other cloud platforms in the future.
At the time of writing, Snow executes millions of queries per day over multiple petabytes of data, serving a rapidly growing number of small and large organizations from various domains.
Outline.
The paper is structured as follows.
Section 2 explains the key design choice behind Snowake: separation of storage and compute.
Section 3 presents the resulting multi-cluster, shared-data architecture.
Section 4 highlights differentiating features: continuous availability, semi-structured and schema-less data, time travel and cloning, and end-to-end security.
Section 5 discusses related work.
Section 6 concludes the paper with lessons learned and an outlook on ongoing work.
STORAGE VERSUS COMPUTE
(谈主流的Shared-nothing架构)Shared-nothing architectures have become the dominant system architecture in high-performance data warehousing, for two main reasons: scalability and commodity hardware.
In a shared-nothing architecture, every query processor node has its own local disks.
Tables are horizontally partitioned across nodes and each node is only responsible for the rows on its local disks.
This design scales well for star-schema queries, because very little bandwidth is required to join a small (broadcast) dimension table with a large (partitioned) fact table.
And because there is little contention for shared data structures or hardware resources, there is no need for expensive, custom hardware [25].
In a pure shared-nothing architecture, every node has the same responsibilities and runs on the same hardware.
This approach results in elegant software that is easy to reason about, with all the nice secondary effects.
(Shared-nothing的主要问题)A pure shared-nothing architecture has an important drawback though: it tightly couples compute resources and storage resources, which leads to problems in certain scenarios.
Heterogeneous Workload While the hardware is homogeneous, the workload typically is not.
A system configuration that is ideal for bulk loading (high I/O band-width, light compute) is a poor fit for complex queries (low I/O bandwidth, heavy compute) and vice versa.
Consequently, the hardware conguration needs to be a trade-off with low average utilization.
Membership Changes If the set of nodes changes; either as a result of node failures, or because the user chooses to resize the system; large amounts of data need to be reshuffled.
Since the very same nodes are responsible for both data shuffling and query processing, a signicant performance impact can be observed, limiting elasticity and availability.
Online Upgrade While the effects of small membership changes can be mitigated to some degree using replication, software and hardware upgrades eventually affect every node in the system.
Implementing online upgrades such that one node after another is upgraded without any system downtime is possible in principle, but is made very hard by the fact that everything is tightly coupled and expected to be homogeneous.
(为何这些问题在云环境下更为突出和重要)In an on-premise environment, these issues can usually be tolerated.
The workload may be heterogeneous, but there is little one can do if there is only a small, fixed pool of nodes on which to run.
Upgrades of nodes are rare, and so are node failures and system resizing.
The situation is very different in the cloud. Platforms such as Amazon EC2 feature many different node types [4].
Taking advantage of them is simply a matter of bringing the data to the right type of node.
At the same time, node failures are more frequent and performance can vary dramatically, even among nodes of the same type [45].
Membership changes are thus not an exception, they are the norm. And finally, there are strong incentives to enable online upgrades and elastic scaling.
Online upgrades dramatically shorten the software development cycle and increase availability.
Elastic scaling further increases availability and allows users to match resource consumption to their momentary needs.
(因为这些,提出计算存储分离的架构)For these reasons and others, Snowake separates storage and compute.
The two aspects are handled by two loosely coupled, independently scalable services.
Compute is provided through Snowake's (proprietary) shared-nothing engine. Storage is provided through Amazon S3 [5], though in principle any type of blob store would suce (Azure Blob Storage [18, 36], Google Cloud Storage [20]).
To reduce network traffic between compute nodes and storage nodes, each compute node caches some table data on local disk.
An added benefit of this solution is that local disk space is not spent on replicating the whole base data, which may be very large and mostly cold (rarely accessed).
Instead, local disk is used exclusively for temporary data and caches, both of which are hot (suggesting the use of high-performance storage devices such as SSDs).
So, once the caches are warm, performance approaches or even exceeds that of a pure shared-nothing system.
We call this novel architecture the multi-cluster, shared-data architecture.
开篇说的是,Shared-nothing当前已经是主流的架构,需要用自身的local disks来存储数据,Tables被水平划分到各个partitions上
这种架构,比较适合star-schema,即事实表外只有一层维表,这样join会比较简单,可以把维表广播,避免大量的数据传输
这个架构的主要问题就是,计算和存储没有分离
带来的问题,他说了几点,我的理解主要是,
首先资源利用会不合理,因为存储和计算任意资源不足,都需要增加节点,而且各个节点上很容易产生热点,热点打散比较麻烦,因为需要分割数据
最关键的是,这个架构在每个node上都有状态,存在本地磁盘,需要保证一致性
扩缩容非常的麻烦,有可能需要迁移数据和分割数据,这个成本非常的高
这篇文章的主要的思想,就是做了计算和存储分离
数据直接放到S3上,
那么本地磁盘仅仅用于cache
ARCHITECTURE
(架构概述,简单介绍3个layers)Snowake is designed to be an enterprise-ready service.
Besides offering high degrees of usability and interoperability, enterprise-readiness means high availability.
To this end(为此), Snowake is a service-oriented architecture composed of highly fault tolerant and independently scalable services.
These services communicate through RESTful interfaces and fall into three architectural layers:
Data Storage This layer uses Amazon S3 to store table data and query results.
Virtual Warehouses The "muscle" of the system.
This layer handles query execution within elastic clusters of virtual machines, called virtual warehouses.
Cloud Services The "brain" of the system.
This layer is a collection of services that manage virtual warehouses, queries, transactions, and all the metadata that goes around that:
database schemas, access control information, encryption keys, usage statistics and so forth.
Figure 1 illustrates the three architectural layers of Snowake and their principal components.
Snowflake整体的架构分3层,
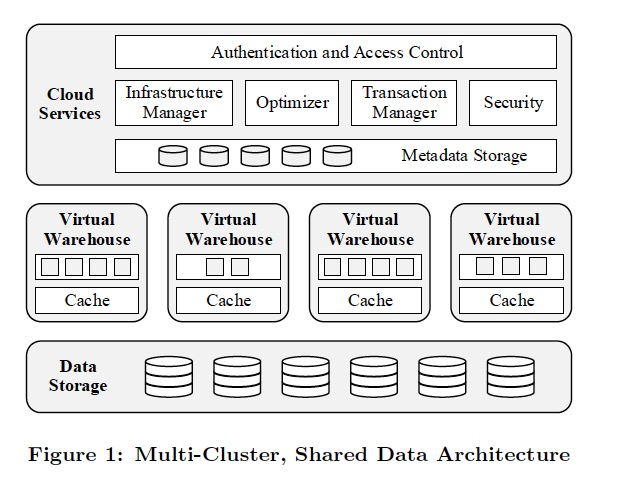
Data Strorage
(为何选择S3,而不是直接开发)Amazon Web Services (AWS) have been chosen as the initial platform for Snowake for two main reasons.
First, AWS is the most mature offering in the cloud platform market. Second (and related to the rst point), AWS oers the largest pool of potential users.
The next choice was then between using S3 or developing our own storage service based on HDFS or similar [46].
We spent some time experimenting with S3 and found that while its performance could vary, its usability, high availability, and strong durability guarantees were hard to beat.
So rather than developing our own storage service, we instead decided to invest our energy into local caching and skew resilience techniques in the Virtual Warehouses layer.
数据主存储用的是S3,会有更高的延迟,更大cpu消耗,尤其是用https的时候
而且S3是对象存储,无法append,当然读的时候是可以读部分数据
(使用S3的问题)Compared to local storage, S3 naturally has a much higher access latency and there is a higher CPU overhead associated with every single I/O request, especially if HTTPS connections are used.
But more importantly, S3 is a blob store with a relatively simple HTTP(S)-based PUT/GET/DELETE interface. Objects i.e. files can only be (over-)written in full. It is not even possible to append data to the end of a le.
In fact, the exact size of a le needs to be announced up-front in the PUT request. S3 does, however, support GET requests for parts (ranges) of a file.
Snowflake把table分成large immutable files,列存格式,高压缩,有header
但没解释如何解决append的问题,高延迟的问题
S3还会作为临时存储放中间结果
Meta是放在KV里面,这部分属于管控
These properties had a strong influence on Snowflake‘s table file format and concurrency control scheme (cf. Section 3.3.2).
Tables are horizontally partitioned into large, immutable files which are equivalent to blocks or pages in a traditional database system.
Within each file, the values of each attribute or column are grouped together and heavily compressed, a well-known scheme called PAX or hybrid columnar in the literature [2].
Each table le has a header which, among other metadata, contains the offsets of each column within the file.
Because S3 allows GET requests over parts of files, queries only need to download the file headers and those columns they are interested in.
Snowake uses S3 not only for table data. It also uses S3 to store temp data generated by query operators (e.g. massive joins) once local disk space is exhausted, as well as for large query results.
Spilling temp data to S3 allows the system to compute arbitrarily large queries without out-of-memory or out-of-disk errors.
Storing query results in S3 enables new forms of client interactions and simplies query processing, since it removes the need for server-side cursors found in traditional database systems.
Metadata such as catalog objects, which table consists of which S3 files, statistics, locks, transaction logs, etc. is stored in a scalable, transactional key-value store, which is part of the Cloud Services layer.
Virtual Warehouses
计算节点,因为存储分离出去了,所以这里纯粹的计算节点
用EC2组成cluster,作为一个VW,用户只能感知到VW,不知道底下有多少ec2的worker node
这里为了便于用户理解,规格直接用类似T-shirt的,X,XXL,很形象

VM是无状态的,纯计算资源
所以这样设计就很简单了,快速扩缩容,failover
用户可以有多个VM,但是底下针对一个相同的存储,VM之间资源是隔离的,所以可以做到不同的query间不干扰
Worker只有在真正查询的时候,才会启动查询进程

为了降低读取S3的延时,在本地磁盘对读取过的文件做了cache,会cache header和读取过的column的数据,这里就采用的比较简单LRU策略
为了让cache更有效,要保证需要读取相同数据的query被分发到相同的worker node,所以这里采用一致性hash来分发query
这里一致性hash是lazy的,意思就是不会搬数据,因为本身cache,所以无所谓,变了就重新建cache,老的等LRU过期
由于Worker是纯计算节点,数据都在S3,所以他处理skew,数据倾斜问题就非常简单,我做完了,可以帮peer做他没有做完的;如果是share-nothing就比较麻烦了,数据倾斜是很讨厌的问题

ExecutionEngine
There is little value in being able to execute a query over 1,000 nodes if another system can do it in the same time using 10 such nodes.
So while scalability is prime, per-node effciency is just as important.
We wanted to give users the best price/performance of any database-as-a-service offering on the market, so we decided to implement our own state-of-the-art SQL execution engine.
The engine we have built is columnar, vectorized, and push-based.
高效的执行引擎,
基于Columnar,可以更好的利用CPU和SIMD
向量化,不会物化中间结果,采用pipiline的方式,参考MonetDB的设计
Push,operator间通过push,streaming的方式

Cloud Services
管控服务,
多租户共用,每个service都是长生命周期和shared,保证高可用和可扩展
Virtual warehouses are ephemeral, user-specific resources.
In contrast, the Cloud Services layer is heavily multi-tenant.
Each service of this layer, access control, query optimizer, transaction manager, and others, is long-lived and shared across many users.
Multi-tenancy improves utilization and reduces administrative overhead, which allows for better economies of scale than in traditional architectures where every user has a completely private system incarnation.
Each service is replicated for high availability and scalability.
Consequently, the failure of individual service nodes does not cause data loss or loss of availability, though some running queries may fail (and be transparently re-executed).
查询管理和优化
所有查询都需要通过CloudService,并会在这完成parsing,optimization的阶段
这里优化用的是Top-down Cascades的方式
由于Snowflake没有index,而且把一些优化放到了执行阶段,比如join数据的分布,所以搜索空间大大降低,同时提升了优化的稳定性
其实说白了,弱化了查询优化部分,把部分工作放到执行引擎中
然后后面就是典型的MPP的过程,把执行计划下发到各个workers,并监控和统计执行状况

并发控制
通过Snapshot Isolation来实现事务机制
这里SI是通过MVCC实现的,这是一个自然的选择,对于S3只能整个替换files,每个table version对应于哪些file,由在kv中的metadata管理

Pruning
传统的数据库,通过索引来检索数据,这里说索引的问题,比如随机读写,overload重,需要显式创建
所以对于AP场景,一般不会选择建B tree这样的索引,而选择顺序扫描数据,所以才有pruning的问题
如果要高效的pruning,需要知道这块数据到底需不需要扫描,是否可以跳过,所以会在header中加上很多的统计,min,max等
(index的问题)Limiting access only to data that is relevant to a given query is one of the most important aspects of query processing.
Historically, data access in databases was limited through the use of indices, in the form of B+-trees or similar data structures.
While this approach proved highly effective for transaction processing, it raises multiple problems for systems like Snowake.
First, it relies heavily on random access, which is a problem both due to the storage medium (S3) and the data format (compressed files).
Second, maintaining indices significantly increases the volume of data and data loading time.
Finally, the user needs to explicitly create the indices, which would go very much against the pure service approach of Snowake.
Even with the aid of tuning advisors, maintaining indices can be a complex, expensive, and risky process.
(提出Pruning方法)An alternative technique has recently gained popularity for large-scale data processing: min-max based pruning, also known as small materialized aggregates [38], zone maps [29], and data skipping [49].
Here, the system maintains the data distribution information for a given chunk of data (set of records, le, block etc.), in particular minimum and maximum values within the chunk.
Depending on the query predicates, these values can be used to determine that a given chunk of data might not be needed for a given query.
For example, imagine files f1 and f2 contain values 3..5 and 4..6 respectively, in some column x.
Then, if a query has a predicate WHERE x >= 6, we know that only f2 needs to be accessed.
Unlike traditional indices, this metadata is usually orders of magnitude smaller than the actual data, resulting in a small storage overhead and fast access.
Pruning nicely matches the design principles of Snowflake: it does not rely on user input; it scales well; and it is easy to maintain.
What is more, it works well for sequential access of large chunks of data, and it adds little overhead to loading, query optimization, and query execution times.
Snowake keeps pruning-related metadata for every individual table file.
The metadata not only covers plain relational columns, but also a selection of auto-detected columns inside of semi-structured data, see Section 4.3.2.
During optimization, the metadata is checked against the query predicates to reduce (“prune") the set of input files for query execution.
The optimizer performs pruning not only for simple base-value predicates, but also for more complex expressions such as WEEKDAY(orderdate) IN (6, 7).
Besides this static pruning, Snowake also performs dynamic pruning during execution.
For example, as part of hash join processing, Snowake collects statistics on the distribution of join keys in the build-side records.
This information is then pushed to the probe side and used to filter and possibly skip entire files on the probe side.
This is in addition to other well-known techniques such as bloom joins [40].
FEATURE HIGHLIGHTS
(上面主要的架构介绍完了,后面介绍些新颖的features)
Snowake offers many features expected from a relational data warehouse: comprehensive SQL support, ACID transactions, standard interfaces, stability and security, customer support, and strong performance and scalability.
Additionally, it introduces a number of other valuable features rarely or never-before seen in related systems.
This section presents a few of these features that we consider technical differentiators.
Pure Software-as-a-Service Experience
Snowake supports standard database interfaces (JDBC, ODBC, Python PEP-0249) and works with various third-party tools and services such as Tableau, Informatica, or Looker.
(WebUI的作用)However, it also provides the possibility to interact with the system using nothing but a web browser. A web UI may seem like a trivial thing, but it quickly proved itself to be a critical differentiator.
The web UI makes it very easy to access Snowake from any location and environment, dramatically reducing the complexity of bootstrapping and using the system.
With a lot of data already in the cloud, it allowed many users to just point Snowake at their data and query away, without downloading any software.
As may be expected, the UI allows not only SQL operations, but also gives access to the database catalog, user and system management, monitoring, usage information, and so forth.
We continuously expand the UI functionality, working on aspects such as online collaboration, user feedback and support, and others.
(易用性)But our focus on ease-of-use and service experience does not stop at the user interface; it extends to every aspect of the system architecture.
There are no failure modes, no tuning knobs, no physical design, no storage grooming tasks. It is all about the data and the queries.
Continuous Availability
In the past, data warehousing solutions were well-hidden back-end systems, isolated from most of the world.
In such environments, downtimes, both planned (software upgrades or administrative tasks) and unplanned (failures)|usually did not have a large impact on operations.
But as data analysis became critical to more and more business tasks, continuous availability became an important requirement for any data warehouse.
This trend mirrors the expectations on modern SaaS systems, most of which are always-on, customer-facing applications with no (planned) downtime.
Snowake offers continuous availability that meets these expectations.
The two main technical features in this regard are fault resilience and online upgrades.
Fault Resilience
Snowake tolerates individual and correlated node failures at all levels of the architecture, shown in Figure 2.
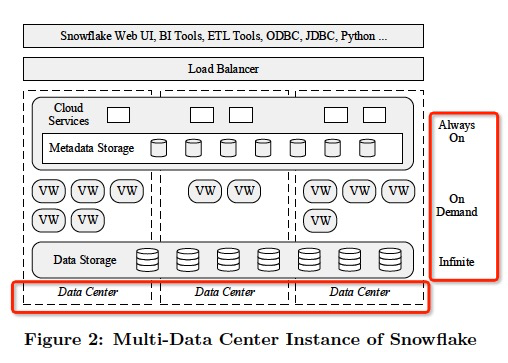
The Data Storage layer of Snowake today is S3, which is replicated across multiple data centers called "availability zones" or AZs in Amazon terminology.
Replication across AZs allows S3 to handle full AZ failures, and to guarantee 99:99% data availability and 99:999999999% durability.
Matching S3's architecture, Snowake's metadata store is also distributed and replicated across multiple AZs.
If a node fails, other nodes can pick up the activities without much impact on end users.
The remaining services of the Cloud Services layer consist of stateless nodes in multiple AZs, with a load balancer distributing user requests between them.
It follows that a single node failure or even a full AZ failure causes no system-wide impact, possibly some failed queries for users currently connected to a failed node.
These users will be redirected to a different node for their next query.
In contrast, VirtualWarehouses (VWs) are not distributed across AZs. This choice is for performance reasons.
High network throughput is critical for distributed query execution, and network throughput is signicantly higher within the same AZ.
If one of the worker nodes fails during query execution, the query fails but is transparently re-executed, either with the node immediately replaced, or with a temporarily reduced number of nodes.
To accelerate node replacement, Snowake maintains a small pool of standby nodes. (These nodes are also used for fast VWprovisioning.)
If an entire AZ becomes unavailable though, all queries running on a given VW of that AZ will fail, and the user needs to actively re-provision the VW in a different AZ.
With full-AZ failures being truly catastrophic and exceedingly rare events, we today accept this one scenario of partial system unavailability, but hope to address it in the future.
Online Upgrade
Snowake provides continuous availability not only when failures occur, but also during software upgrades.
The system is designed to allow multiple versions of the various services to be deployed side-by-side, both Cloud Services components and virtual warehouses.
This is made possible by the fact that all services are effectively stateless.
All hard state is kept in a transactional key-value store and is accessed through a mapping layer which takes care of metadata versioning and schema evolution.
Whenever we change the metadata schema, we ensure backward compatibility with the previous version.
To perform a software upgrade, Snowake first deploys the new version of the service alongside the previous version.
User accounts are then progressively switched to the new version, at every which point all new queries issued by the respective user are directed to the new version.
All queries that were executing against the previous version are allowed to run to completion.
Once all queries and users have finished using the previous version, all services of that version are terminated and decommissioned.
Figure 3 shows a snapshot of an ongoing upgrade process.
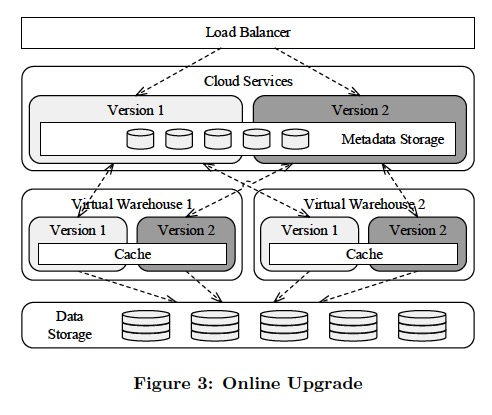
There are two versions of Snowake running side-by-side, version 1 (light) and version 2 (dark). There are two versions of a single incarnation of Cloud Services, controlling two virtual warehouses (VWs), each having two versions.
The load balancer directs incoming calls to the appropriate version of Cloud Services. The Cloud Services of one version only talk to VWs of a matching version.
As mentioned previously, both versions of Cloud Services share the same metadata store.
What is more, VWs of different versions are able to share the same worker nodes and their respective caches.
Consequently, there is no need to repopulate the caches after an upgrade.
The entire process is transparent to the user with no downtime or performance degradation.
Online upgrade also has had a tremendous effect on our speed of development, and on how we handle critical bugs at Snowake.
At the time of writing, we upgrade all services once per week.
That means we release features and improvements on a weekly basis.
To ensure the upgrade process goes smoothly, both upgrade and downgrade are continuously tested in a special pre-production incarnation of Snow.
In those rare cases where we find a critical bug in our production incarnation (not necessarily during an upgrade), we can very quickly downgrade to the previous version, or implement a fix and perform an out-of-schedule upgrade.
This process is not as scary as it may sound, because we continuously test and exercise the upgrade/downgrade mechanism. It is highly automated and hardened at this point.
RELATEDWORK
Cloud-based Parallel Database Systems.
(和redshift对比,shared-nothing和shared-data架构对比,pure service 易用性)
Amazon has a number of DBaaS products with Amazon Redshift being the data warehousing product among these.
Having evolved from the parallel database system ParAccel, Redshift was arguably the first real data warehouse system offered as a service [30].
Redshift uses a classic shared-nothing architecture. Thus, while being scalable, adding or removing compute resources requires data redistribution.
In contrast, Snowake's multi-cluster, shared data architecture allows users to instantly scale up, scale down, (天然的scale能力)
or even pause compute independently from storage without data movement, including the ability to integrate data across isolated compute resources.
Also, following a pure service principle, Snowake requires no physical tuning, data grooming, manual gathering of table statistics, or table vacuuming on the part of users.
Although Redshift can ingest semi-structured data such as JSON as a VARCHAR, Snowake has native support for semi-structured data, including important optimizations such as columnar storage.
(和Google BigQuery进行对比,BigQuery是数仓所以只支持SQL-like,并且append-only,SF支持TP的ACID,和半结构化)
Google's Cloud Platform offers a fully managed query service known as BigQuery [44], which is the public implementation of Dremel [34].
The BigQuery service lets users run queries on terabytes of data at impressive speeds, parallelized across thousands of nodes.
One of the inspirations for Snowake was BigQuery's support for JSON and nested data, which we find necessary for a modern analytics platform.
But while BigQuery offers a SQL-like language, it has some fundamental deviations from the ANSI SQL syntax and semantics, making it tricky to use with SQL-based products.
Also, BigQuery tables are append-only and require schemas.
In comparison, Snowake oers full DML (insert, update, delete, merge), ACID transactions, and does not require schema denitions for semi-structured data.
(和Azure DW对比)
Microsoft SQL Data Warehouse (Azure SQL DW) is a recent addition to the Azure cloud platform and services based on SQL Server and its Analytics Platform System (APS) appliance [35, 37].
Similar to Snowake, it separates storage from compute. Computational resources can be scaled through data warehouse units (DWUs).
The degree of concurrency is capped though. For any data warehouse, the maximum number of concurrently executing queries is 32 [47].
Snowake, in contrast, allows fully independent scaling of concurrent workloads via virtual warehouses. Snowake users are also released from the burden of choosing appropriate distribution keys and other administrative tasks.
And while Azure SQL DW does support queries over non-relational data via PolyBase [24], it does not have built-in support for semi-structured data comparable to Snow VARIANT type and related optimizations.
Document Stores and Big Data.
Document stores such as MongoDB [39], Couchbase Server [23], and Apache Cassandra [6], have become increasingly popular among application developers in recent years, because of the scalability, simplicity, and schema exibility they offer.
However, one challenge that has resulted from the simple key-value and CRUD (create, read, update, and delete) API of these systems is the diffculty to express more complex queries.
In response, we have seen the emergence of several SQL-like query languages such as N1QL [22] for Couchbase or CQL [19] for Apache Cassandra.
Additionally, many "Big Data" engines now support queries over nested data, for example Apache Hive [9], Apache Spark [11], Apache Drill [7], Cloudera Impala [21], and Facebook Presto [43].
We believe that this shows a real need for complex analytics over schema-less and semi-structured data, and our semi-structured data support is inspired by many of these systems.
Using schema inference, optimistic conversions, and columnar storage, Snowake combines the exibility of these systems with the storage effciency and execution speed of a relational, column-oriented database.
LESSONS LEARNED AND OUTLOOK
(在Hadoop的大背景下,坚持关系型数据库)When Snowake was founded in 2012, the database world was fully focused on SQL on Hadoop, with over a dozen systems appearing within a short time span.
At that time, the decision to work in a completely different direction, to build a "classic"data warehouse system for the cloud, seemed a contrarian and risky move.
After 3 years of development we are condent that it was the right one.
Hadoop has not replaced RDBMSs; it has complemented them. People still want a relational database, but one that is more effcient, flexible, and better suited for the cloud.
(Shared-data,Saas)Snowake has met our hopes of what a system built for the cloud can provide to both its users and its authors.
The elasticity of the multi-cluster, shared data architecture has changed how users approach their data processing tasks.
The SaaS model not only has made it easy for users to try out and adopt the system, but has also dramatically helped our development and testing.
With a single production version and online upgrades, we are able to release new features, provide improvements, and x problems much faster than we would possibly be able to do under a traditional development model.
(半结构化支持)While we had hoped that the semi-structured extensions would prove useful, we were surprised by the speed of adoption.
We discovered a very popular model, where organizations would use Hadoop for two things: for storing JSON, and for converting it to a format that can be loaded into an RDBMS.
By providing a system that can effciently store and process semi-structured data as-is, with a powerful SQL interface on top, we found Snowake replacing not only traditional database systems, but also Hadoop clusters.
(Lessons)It was not a painless journey of course. While our team has over 100 years of database-development expertise combined, we did make avoidable mistakes along the way,
including overly simplistic early implementations of some relational operators, not incorporating all datatypes early on in the engine, not early-enough focus on resource management, postponing work on comprehensive date and time functionality etc.
Also, our continuous focus on avoiding tuning knobs raised a series of engineering challenges, ultimately bringing about many exciting technical solutions.
As a result, today, Snowake has only one tuning parameter: how much performance the user wants (and is willing to pay for).
(天然的性能优势)While Snowake's performance is already very competitive, especially considering the no-tuning aspect, we know of many optimizations that we have not had the time for yet.
Somewhat unexpected though, core performance turned out to be almost never an issue for our users.
The reason is that elastic compute via virtual warehouses can offer the performance boost occasionally needed. That made us focus our development eorts on other aspects of the system.
(多租户)The biggest technical challenges we face are related to the SaaS and multi-tenancy aspects of the system.
Building a metadata layer that can support hundreds of users concurrently was a very challenging and complex task.
Handling various types of node failures, network failures, and supporting services is a never-ending fight.
Security has been and will continue to be a big topic: protecting the system and the users' data from external attacks, the users themselves, and our internal users as well.
Maintaining a live system of hundreds of nodes running millions of queries per day, while bringing a lot of satisfaction, requires a highly integrated approach to development, operations, and support.
(Future)Snowake users continue to throw increasingly bigger and more complex problems at the system, influencing its evolution.
We are currently working on improving the data access performance by providing additional metadata structures and data re-organization tasks, with a focus on minimal to no user interaction.
We continue to improve and extend core query processing functionality, both for standard SQL and semi-relational extensions.
We plan to further improve the skew handling and load balancing strategies, whose importance increases along with the scale of our users' workloads.
We work on solutions simplifying workload management to the users, making the system even more elastic. And we work on integration with external systems, including issues such as high-frequency data loading.
The biggest future challenge for Snowake is the transition to a full self-service model, where users can sign up and interact with the system without our involvement at any phase.
It will bring a lot of security, performance, and support challenges. We are looking forward to them.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号