
排序算法python实现
先列出一些算法复杂度的标识符号的意思, 最常用的是O,表示算法的上届,如 2n2 = O(n2 ), 而且有可能是渐进紧确的, 意思是g(n)乘上一个常数系数是可以等于f(n)的,就是所谓的a<=b。而o的区别就是非渐进紧确的,如2n = o(n2 ), o(n2 )确实可以作为2n的上届, 不过比较大, 就是所谓的a
其他符号表示了下届,和非渐进紧确的下届, a>=b, a>b
还有既是上届也是下届, 就是a=b
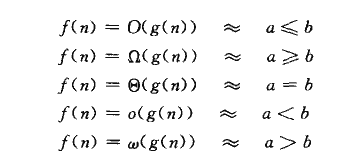
Bubble Sort
冒泡排序效率是最低的, 对于list中任意一点, 都必须遍历其后所有元素以找到最小元素, 这个耗费是n
所以对于完整的冒泡算法, 对list中n个点, 算法复杂度就是n2
1 def bubbleSort(data):
2 if len(data) < 2: return data
3 for i in range(0, len(data)-1):
4 m = i
5 for j in range(i+1, len(data)):
6 if data[m] > data[j]: m =j
7
8 if m != i:
9 data[i], data[m] = data[m], data[i]
10 return data
Insert Sort
对于插入的任一个元素, 最差情况是需要遍历它之前的所有元素, 才能找到插入位置. 但这个是最差情况, 一般不需要.
所以他的复杂度同样是n2 , 但对于普通的排序, 效率要高于冒泡
1 def insertSort(data):
2 if len(data) < 2: return data
3 for i in range(1,len(data)):
4 print data
5 key = data[i]
6 j = i-1
7 while j >= 0 and key < data[j]:
8 data[j+1] = data[j]
9 j = j-1
10 data[j+1]= key
11 return data
Merge Sort
这个算法是基于二分法的递归算法, 把二分递归的过程图形化, 会形成一个递归树(对分析表示分治算法的递归式的复杂度时,递归树方法好用形象). 树高为logn, 对于树的每一层进行并归操作, 可以看出每层并归的耗费最大是n, 所以算法复杂度就是nlogn. Merge Sort的缺点就是, 它不是inplace的, 需要耗费和输入同样大小的数据空间.
1 def mergeSort(data):
2 length = len(data)
3 if length < 2: return data
4 l = data[:length/2]
5 r = data[length/2:]
6
7 outL = mergeSort(l)
8 outR = mergeSort(r)
9
10 return merge(outL, outR)
11
12 def merge(l,r):
13 print l,r
14 data = []
15 while len(l)>0 and len(r)>0:
16 if l[0] > r[0]:
17 data.append(l.pop(0))
18 else:
19 data.append(r.pop(0))
20
21 if len(l) >0:
22 data.extend(l)
23 else:
24 data.extend(r)
25 return data
Heap Sort
堆排序首先是建堆, 建堆就是对所有非叶子节点进行堆化操作, 堆化的最大耗费是logn, 所以建堆的最大耗费是nlogn, 但是其实大部分的节点的高都远远没有logn, 这个可以计算出实际的最大耗费只有n.
最后排序的耗费n-1次堆化操作, 所以整个的复杂度为nlogn.
堆排序复杂度达到nlogn, 而且是inplace算法.
1 def heapSort(input):
2 output = []
3 buildHeap(input)
4 print input
5 while input:
6 i = len(input)-1
7 input[0],input[i] = input[i],input[0]
8 output.append(input.pop())
9 if input:
10 maxHeapify(input,0)
11 return output
12
13 def maxHeapify(input, i):
14 if i <0:
15 return
16 left = 2*i+1 # because the i from 0, not 1
17 right = 2*i+2
18 largest = i
19 length = len(input)
20 if left < length:
21 if input[i]< input[left]: largest = left
22 if right < length:
23 if input[largest]< input[right]: largest = right
24 if largest != i:
25 input[i], input[largest] = input[largest], input[i]
26 maxHeapify(input,largest)
27
28 def buildHeap(input):
29 length = len(input)
30 if length < 2: return
31 nonLeaf = length/2
32 for i in range(nonLeaf,-1,-1):
33 maxHeapify(input,i)
Quick Sort
快排在最差的情况下,即对于已经排好序的序列, 每次划分都是0和n-1, 这样的算法复杂度为n2 .这种情况下如果表示成递归树, 树高为n, 每层partition的耗费是n,所以复杂度为n*n
而在最好情况下就是, 序列为对称的, 每次为折半划分, 这个情况和并归排序一样, 耗费为nlogn
而在平均情况下, 可以证明是接近最好情况的, 即复杂度为nlogn,原因是任何一种按常数比例进行的划分都会产生深度为lgn的递归树
1 def partition(data, p, r):
2 i = p-1
3 cmp = data[r]
4 for j in range(p,r):
5 if data[j] < cmp:
6 i = i+1
7 if i <> j: data[i],data[j] = data[j],data[i]
8
9 if (i+1) <> r: data[i+1],data[r] = data[r],data[i+1]
10 return i+1
11 def randomPartition(data, p, r):
12 import random
13 i = random.randint(p,r)
14 data[i], data[r] = data[r], data[i]
15 return partition(data, p, r)
16
17 def quickSort(data, p, r):
18 if p < r:
19 q = partition(data, p, r)
20 #q = randomPartition(data, p, r)
21 quickSort(data, p, q-1)
22 quickSort(data, q+1, r)
其他排序问题
对于普通的排序算法, 即比较排序算法, 复杂度的下限为nlogn, 不可能比这个更少
对于这个的理解是, 比较排序可以被抽象为决策树, 对于n个元素可能的排列为n!个, 所以树的叶子节点有n!个, 对于一个高h的树, 叶子节点最多有2h 个, 所以可以算出h的下限为nlogn
而对于比较排序而言, 任意两个元素的顺序都要通过一次比较来完成, 所以下限为需要两两比较的次数
如果要突破这个下限, 就必须基于某种假设, 而不可能是通用的比较算法.
比如计数排序, 假设输入由一个小范围内(小于k)的整数构成, 那排序方法很简单, 建立一个长度为k的数组A, 遍历输入, 并把输入i放入相应的A[i]中. 排序只要O(n)
如果是桶排序, 假设输入为均匀分布[0,1), 由一个随机过程产生. 把[0,1)区域均匀划分为n个子区域, 称为桶, 然后把输入分布到各个桶中. 用于输入是均匀分布的, 每个桶中的输入一定很少, 那么先在桶内排序, 然后把各个桶中的元素列出来即可.

