博客园开博记录
从CSDN来博客园开个博
Cao, W., Gao, Y., Lin, B., Feng, X., Xie, Y., Lou, X., & Wang, P. (2018, May). Tcprt: Instrument and diagnostic analysis system for service quality of cloud databases at massive scale in real-time. In Proceedings of the 2018 International Conference on Management of Data (pp. 615-627).
Zhang, J., Wu, S., Tan, Z., Chen, G., Cheng, Z., Cao, W., ... & Feng, X. (2019). S3: a scalable in-memory skip-list index for key-value store. Proceedings of the VLDB Endowment, 12(12), 2183-2194.
Cao, W., Gao, Y., Li, F., Wang, S., Lin, B., Xu, K., ... & Zhang, G. (2020, June). Timon: A Timestamped Event Database for Efficient Telemetry Data Processing and Analytics. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data (pp. 739-753).
Chen, W., Chen, L., Xie, Y., Cao, W., Gao, Y., & Feng, X. (2020, April). Multi-range attentive bicomponent graph convolutional network for traffic forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 34, No. 04, pp. 3529-3536).
Cao, W., Feng, X., Liang, B., Zhang, T., Gao, Y., Zhang, Y., & Li, F. (2021, June). LogStore: A Cloud-Native and Multi-Tenant Log Database. In Proceedings of the 2021 International Conference on Management of Data (pp. 2464-2476).
(2021 TSC). YISHAN: Managing Large-scale Cloud Database Instances via Machine Learning.
Timon
Blind Write VS. Read-Modify-Write
out-of-order events不用进行RMW,直接blind write
幂等保证Exactly Once
对于At-least Once的系统Kafka,记录每个Partition的latest offset,避免重复存储
数据模型
如图,
一组一同采集的metric,metricSet,具有一个时间戳,等同于row
一个metricSet的collection,称为StreamSet ,具有一个uuid,比如对于某一个主机发送的指标组,就用一个uuid标识
以uuid为标准,匹配一组TagSet,即一个StreamSet可以附加一组特殊的属性
TagSet单独存储,作为元数据,存储在本地的rocksDB中

SEDA (Staged Event Driven Architecture)
Windows聚合和Late数据的处理
首先,数据写入时,有两个MemTable,其中一个是为了late数据的
为何要单独分出一个late的,因为late的会破坏连续性,不便于后续用数组来存储数据
这里之所以有late的说法,就需要参考dataflow里面对于窗口的解释
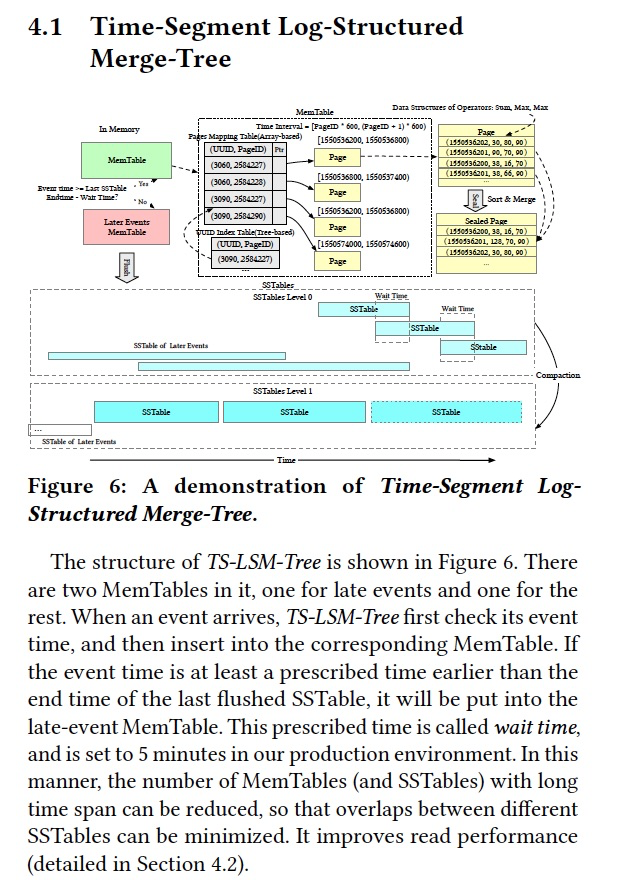
然后提出一个page的概念,600条records,一个UUID至少对应于一个page,一个page中的数据属于一个UUID,因为后面以page为维度要聚合
一个page写满,就会排序并聚合,这个取决于时间戳的精度,如果是秒级精度就按秒级聚合,聚合的算子定义的时候可以指定
这里sealed page的实现用数组,这样避免search的代价,因为根据数组的下标就可以直接找到相应的时间,
所以这里甚至不用事先排序,直接乱序插入即可,插入的过程本身就是排序的过程
有个问题是如果这里的时间是sparse的,那么数组中就会有很多的空洞,下面也说如果太过sparse那么就暂时不seal,多等一会,但这毕竟不是根本的解决方法。
这也是为何还需要一个late的内存表,
这里又有一个假设,就是写入的数据是在时间上dense的,这个对于监控数据而言是成立的

SSTable的存储结构
内存中的数据会定期的flush成SSTable,内存中的page对应于block
一个SSTable中包含很多block,按时间戳排序,并且没有overlap,这样可以精准查询,因为late单独存,所以没有overlap
这里在一个SSTable中,对每一个UUID会建立一个时间的线段树索引,即按时间维度聚合,便于long time span的查询

SSTable由如下组成,
首先是MetaZone,元数据,比如时间戳范围,这个meta非常小,所以可以将所有的meta都放在内存中
再者是所谓的bucket和collision,其实就是一个序列化的hash table,记录每个UUID的数据的时间戳范围和offset;
这个hash table也是用array来实现的,避免二分search;用uuid的hash找到index,如果冲突则使用64byte指向其他collided的UUID
最后是DataZone,这个是按UUID分开的,先存一个时间的线段树索引,接着是一堆的blocks


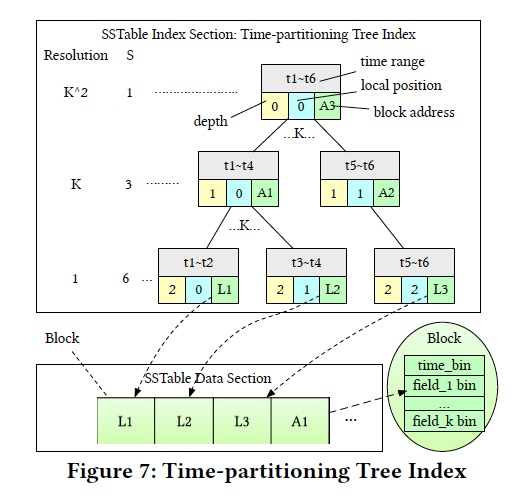
时间线段树
可以记录不同时间粒度的聚合数据,
这里做的优化是,这个线段树是用数组存储的,知道depth和local position,就可以计算出在数组的中的index

领域定位是数据领域,对于大数据,数据库,分布式领域的核心理论和论文有广度的技术积累。
不太区分数据库和大数据,现在本身数据库和大数据的技术也在融合,比如湖仓,HTAP。
从底层的存储,中间的计算平台,查询引擎,到上层的数据应用,到可观测和AIOPS系统都有一定深度的研究和工程经验。
- 底层存储,主要研发时序和日志存储,内部使用,部署1000+物理机,数据量PB级别(云原生oss)两篇SigMOD,20,21
- 计算平台,离线,在线,湖仓都研究过,对于实时计算有很深入的研究
源码研究,storm,kafka,spark,flink源码研究
托管运维,托管运维kafka和Flink集群,kafka,单机8块盘,sata,8个kafka节点,48节点,6台物理机,最小部署8个节点;上千节点;flink,单集群320core,几万core
丰富实时应用研发经验,主要秒级性能,审计日志,每日100TB流量,上千的job数;通用ETL,动态Pipeline管理,维表方案等
实时计算探讨两个方向,数据一致性和开发效率,运维效率;一致性,lambda,kappa,at-least once
- 可观测性,AIOPS体现建设,数据库整体的数据链路,监控,诊断体系建立,18年SIGMOD
资源管理;稳定性,降本增效(混布共池,错峰调度)
离线调度,负载预测,移山
秒级serverless
异常管理
主动,异常预测,硬件故障,磁盘,相对线性关系
被动,
异常检测,无监督,离群点,聚类,降维,时序自回归,天象诊断
根因定位,基于指标组合关联关系的异常变化来定位
云原生,解耦合,利用云的特性,低成本,高扩展性
当前解耦主要是存储,本地盘(无法扩展),云盘(贵),对象存储(性价比高)kv,move和list慢,用meta,解耦文件路径与分区关系
解耦合cache,冷启动,缓存失效;元数据缓存(meta),中间结果缓存,sf的多层次缓存,alluxio
sata 150M/s; SSD 0.5~1GB/s; 本地内存 几十GB/s ; remote内存,取决于网络,25Gb=3GB
预算,druid,kylin,空间换时间,物化视图,doris
- hadoop,湖仓
传统仓,schema on write,hive;湖,rawdata,通过etl生成仓;
云原生湖,S3,对象存储,计算存储分离,针对kv对象存储,跨key一致性,性能,提出湖仓deltalake
湖仓技术,临时方案,非必须,用于替代流式系统和数仓,数据湖,但在每一方面都比较平庸
htap在大数据领域的探索,支持crud,timeline
hive无论怎样,仍然是mapreduce系统,所以他对增量不敏感;hudi本质是ap系统,mpp,列存
也可以将hudi表映射成hive外表,然后用大数据系统,hive,spark,flink去做增量分析,这点上Hudi在hadoop生态中的位置,就像Kafka在流式计算中的位置
规模,托管运维kafka和Flink集群,集群数,单集群节点数
kafka,单机8块盘,sata,8个kafka节点,48节点,6台物理机,最小部署8个节点;上千节点
flink,单集群320core,几万core
job规模,上千job,单job,48cu
平台构建,
通用ETL,业务可在后台注册各自的Parse Schema、Transform Schema、API Schema,灵活地配置指标格式、计算规则、元数据补全与展示逻辑等内容。业务无缝接入、无需额外改造
按业务Business,Region划分Pipeline,互相隔离。 基于配置中心的Pipline路由管理,通过配置实现主备Pipeline切换和各种切流操作
基于批量预热、异步刷新等优化措施,支持超大规模的维表匹配能力。
VLDB'20 Magnet: 领英Spark Shuffle解决方案,https://zhuanlan.zhihu.com/p/397391514
EMR shuffle service,https://www.sohu.com/a/436931403_612370
流式shuffle来解决离线shuffle的问题,kafka
Flink2022,最新动态,https://developer.aliyun.com/article/1092732?spm=a2c6h.26396819.creator-center.12.6a073e18Ov4Xzs
Paimon 创新的结合了 湖存储 + LSM + 列式格式 (ORC, Parquet),为湖存储带来大规模实时更新能力,Paimon 的 LSM 的文件组织结构如下:https://www.modb.pro/db/620805
Flink Checkpointing 时间的主要因素有以下几点:
- Checkpoint Barrier 流动和对齐的速度;
- 将状态快照持久化到非易失性高可用存储(例如 S3)上所需要的时间。
https://www.jianshu.com/p/b9083d91ae27https://www.cnblogs.com/pengblog2020/p/12161716.html
Generic Log-Based Incremental Checkpointing
https://developer.aliyun.com/article/937543?spm=a2c6h.26396819.creator-center.18.6a073e18qLUo4Q
状态管理,高效状态数据的分裂和合并,rescale能力,keyset
kubeedge,云边一体,https://zhuanlan.zhihu.com/p/350335104
mindspore,https://github.com/mindspore-ai/mindspore
两层决策算法,
端上基于时间窗口规则触发
本机二层业务决策弹升策略,跨进程
cpu_usage>0.8 total_session>0.95
memory_usage>0.8 && innodb_buffer_pool_use_ratio>0.9 && innodb_buffer_pool_read_hint<0.5
cpu_usage<0.5 && memory_usage<0.5 && total_session<0.5
基本弹升弹降
快速弹升,缓慢弹降
步长计算,naive逻辑,增加多少cu可以达到target负载,按照0.5 cu取整,
增加系数f控制弹升速度(0.1 -1),0.1就是弹升计算步长的十分之一
本地弹升弹降
通过CGroup修改资源量,cpu,memory,Io由于ecs盘独占,或是共享存储,意义不大
Docker或K8S容器本身,也是通过封装CGroup进行资源限制
中心化能力
冷CU调度,qps等指标判断,实例长时间低负载运行,按主机维度排名
启停,固定时间内(可配置,24小时)无流量的实例,假停,容器不释放;查询来拉起(分钟级别,用户需容忍)
Warm RO,拉起RO需要几分钟,预测读请求导致资源cpu持续上升,预先拉起RO
采用 15min 大小的滑动窗口,通过Lowess 序列平滑算法将序列平滑,
探测最近最长的线性序列,超过10秒,根据线性回归去预测未来3分钟的时间序列,超过80%,触发弹升
主动弹升,STL周期分解,拆分出trend、season、residual三部分,根据residual来判断是否满足周期性,根据trend和season两部分来计算预测值
https://db.cs.cmu.edu/papers/2017/p1009-van-aken.pdf
https://github.com/cmu-db/ottertune
https://github.com/cmu-db/noisepage
https://cloud.tencent.com/developer/news/832151
Self-Driving Database Management Systems
负载预测,类型,ap,tp,什么样的语句,多大的量
资源预测,使用多少资源,serverless,
物理设计,index,物化视图,行列存
数据设计,如何sharding,分区键;冷热分离
运行时,SQL查询计划,调参
https://ottertune.com/blog/external-vs-internal-automatic-database-tuning/
An external ML approach is when the tuning algorithm can only observe the target’s inputs and outputs in its decision making process; the algorithm has no knowledge of the system’s internal structure, design, or implementation.
In the context of database tuning, an external tuning tool interacts with the DBMS only through its standard APIs (e.g., SQL) and monitoring services (e.g., Amazon CloudWatch).
In other words, an external ML approach does not require changes to the DBMS’s source code, nor does it need the user to install custom extensions.
OtterTune is an external tuning service; it uses the target DBMS’s standard interfaces (SQL)
An internal ML approach is when the DBMS has automatic tuning components tightly integrated into its internal architecture.
Such integration requires the system developers to add “hooks” in the DBMS’s source code to retrieve telemetry data and modify its behavior.
With the former, these changes could allow the tuning algorithms to collect information about the system’s runtime behavior and low-level hardware measurements, such as the number of CPU cycles used to insert a single record into an index. The algorithms could then control the system’s behavior in ways that are not possible through existing APIs. For example, the tuning algorithm could make adjustments to the DBMS at the session-level to affect how the system executes individual transactions or queries. Such fine-grained control is not possible by humans and is not feasible with existing approaches today.
Oracle Autonomous Database, Oracle’s MySQL Heatwave Autopilot, Huawei’s OpenGauss, and our work with CMU’s NoisePage
https://fxjwind.github.io/resume/
https://github.com/fxjwind/resume/blob/gh-pages/index.html
https://www.bocionline.com/tc/home/index.shtml
