Elasticsearch 核心技术与实战 学习笔记
分片的设定
对于生产环境中分片的设定,需要提前做好容量规划
-
分片数设置过小
- 导致后续无法增加节点实现水品扩展
- 单个分片的数据量太大,导致数据重新分配耗时
-
分片数设置过大,7.0开始,默认主分片设置成1,解决了 over—sharding的问题
- 影响搜索结果的相关性打分,影响统计结果的准确性
- 单个节点上过多的分片,会导致资源浪费,同时也会影响性能
倒排索引
Elasticsearch 的 JSON文档中的每个字段,都有自己的倒排索引可以指定对某些字段不做索引。
- 优点:节省存储空间
- 缺点:字段无法被搜索
搜索的相关性
搜索是用户和搜索引擎的对话。
用户关心的是搜索结果的相关性。
- 是否可以找到所有相关的内容
- 有多少不相关的内容被返回了
- 文档的打分是否合理
- 结合业务需求,平衡结果排名
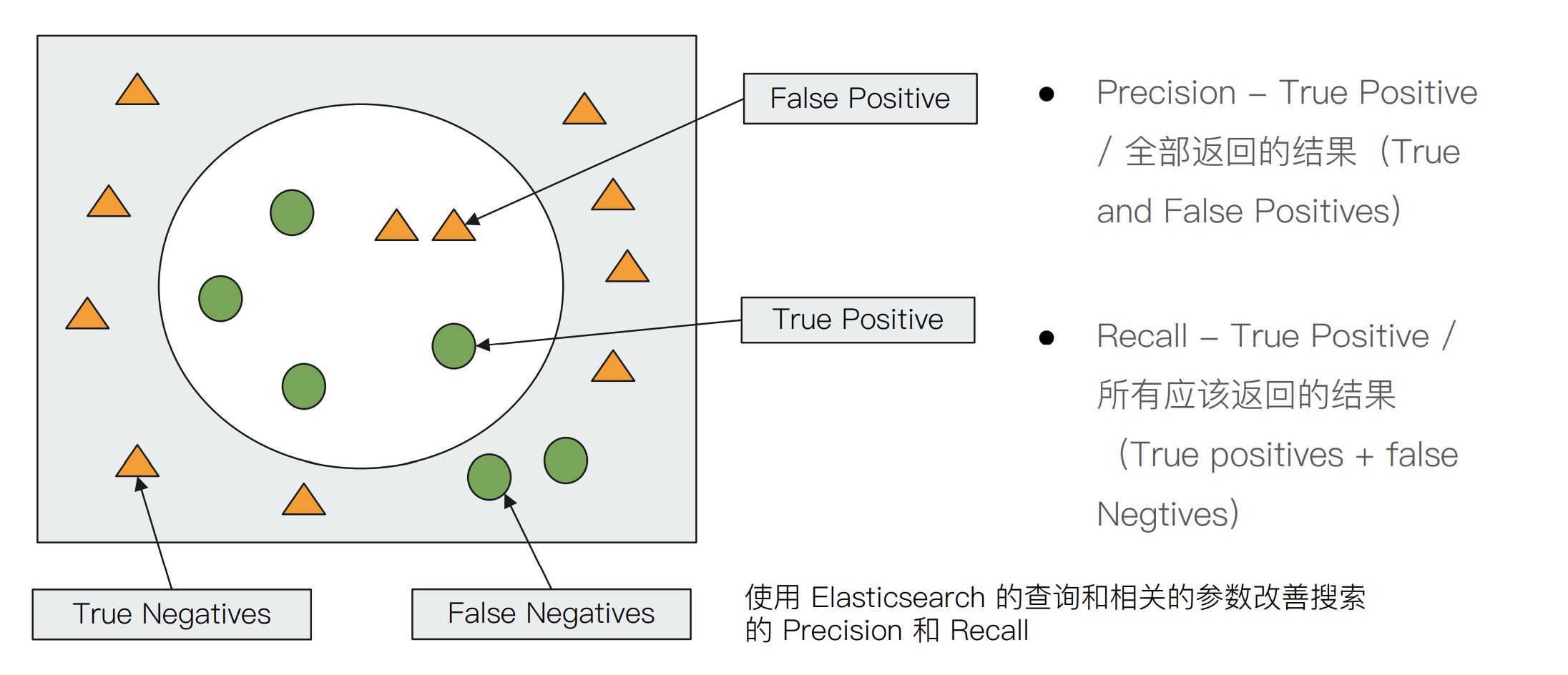
衡量相关性
- Precision(查准率)— 尽可能返回较少的无关文档
- Recall(查全率)— 尽量返回较多的相关文档
- Ranking — 是否能够按照相关度进行排序?
能否更改Mapping的字段类型
- 新增加字段
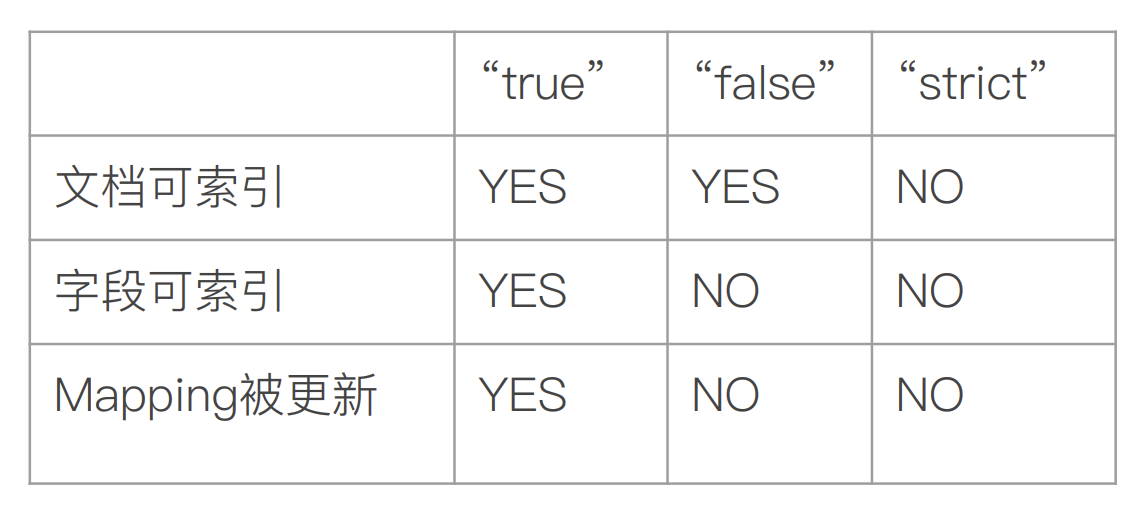
- Dynamic设为true时,一旦有新增字段的文档写入, Mapping也同时被更新
- Dynamic设为false, Mapping不会被更新,新增字段的数据无法被索引(无法被搜索),但是信息会出现在_source中
- Dynamic设置成Strict,文档写入失败
- 对已有字段,一旦已经有数据写入,就不再支持修改字段定义
- Lucene实现的倒排索引,一旦生成后,就不允许修改如果希望改变字段类型,必须Reindex API,重建索引
如果修改了字段的数据类型,会导致已被索引的数据无法被搜索。但是如果是增加新的字段,就不会有这样的影响。
控制Dynamic Mapping
- 当 dynamic被设置成false时候,存在新增字段的数据写入,该数据可以被索引,但是新增字段被丢弃。
- 当设置成Strict 模式时候,数据写入直接出错。
自定义Mapping的建议
为了减少输入的工作量,减少出错概率,可以依照以下步骤
- 创建一个临时的index,写入一些样本数据
- 通过访问 Mapping API获得该临时文件的动态 Mapping 定义
- 修改后用,使用该配置创建你的索引
- 删除临时索引
Index Options
四种不同级别的 Index Options 配置,可以控制倒排索引记录的内容
- docs - 记录 doc id O
- freqs - 记录 doc id和 term frequencies O
- positions - 记录 doc id/term frequencies /term position O
- offsets - doc id/ term frequencies / term posistion / character offects
Text 类型默认记录 postions,其他默认为 docs。记录内容越多,占用存储空间越大
Index Template
Index Templates - 帮助你设定Mappings和Settings,并按照一定的规则, 自动匹配到新创建的索引之上。
- 模版仅在一个索引被新创建时,才会产生作用。
- 修改模版不会影响已创建的索引。
- 你可以设定多个索引模版,这些设置会被“merge”在一起你可以指定“order”的数值,控制“merging”的过程。
当一个索引被新创建时:
- 应用 Elasticsearch 默认的 settings 和 mappings
- 应用order数值低的Index Template 中的设定
- 应用order高的 Index Template 中的设定,之前的设定会被覆盖
- 应用创建索引时,用户所指定的Settings和Mappings,并覆盖之前模版中的设定
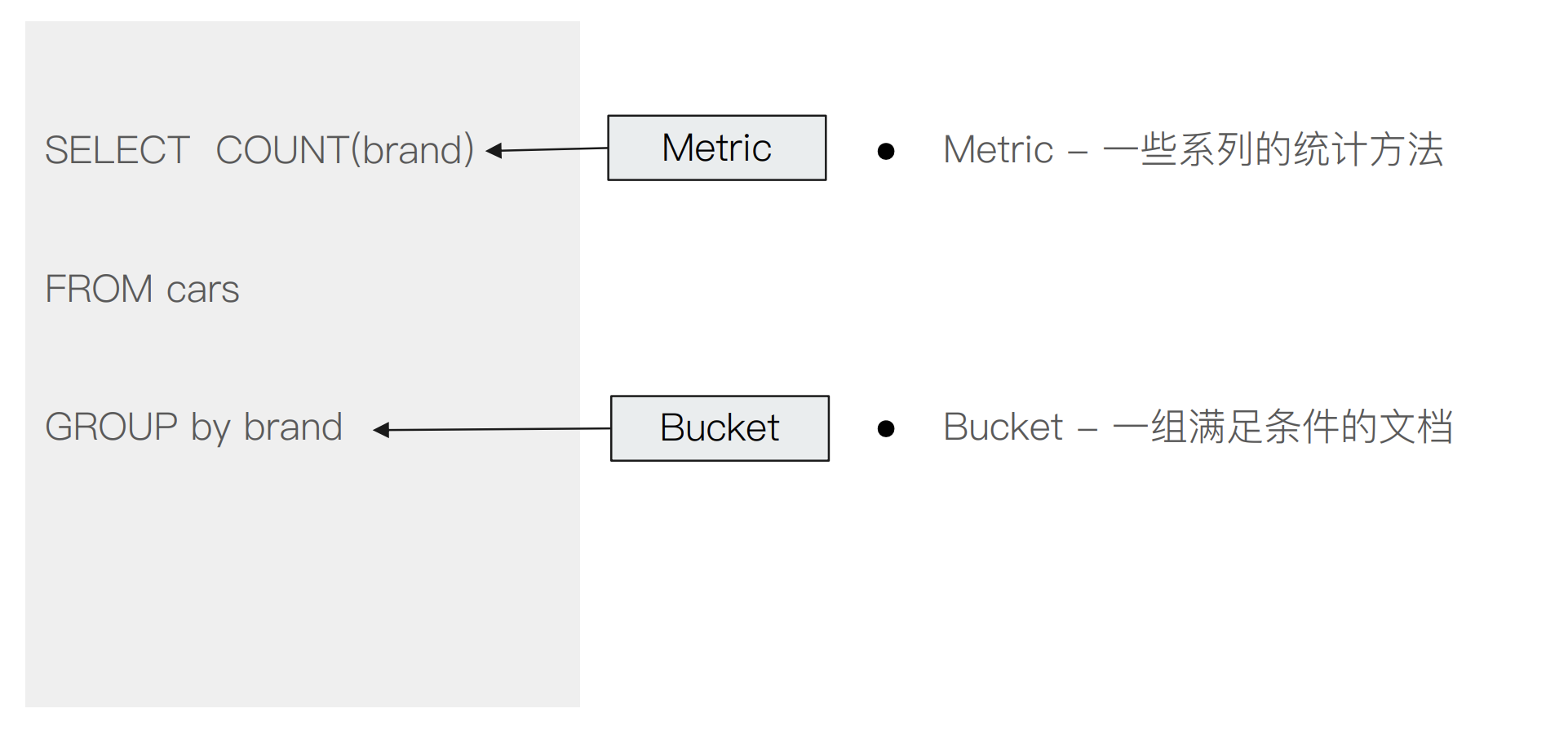
Bucket & Metric

 浙公网安备 33010602011771号
浙公网安备 33010602011771号