《算法笔记》——第九章 并查集 学习记录
并查集是一种维护集合的数据结构,它的名字中“并”“查”“集”分别取自Union(合并)、Find (查找)、Set (集合)这了3个单词。也就是说,并查集支持下面两个操作:
- 合并:合并两个集合。
- 查找:判断两个元素是否在-一个集合。
那么并查集是用什么实现的呢?其实就是用一个数组:
int father[N];
其中,fahter[i]表示元素i的父亲结点,而父亲结点本身也是这个集合内的元素(1≤i≤N)。例如father[1] = 2就表示元素1的父亲结点是元素2,以这种父系关系来表示元素所属的集合。另外,如果father[i]=i,则说明元素i是该集合的根结点,但对同一个集合来说只存在一个根结点,且将其作为所属集合的标识。
举个例子,下面给出了图9-37的father数组情况。
father[1]=1;
father[2]=1;
father[3]=2;
father[4]=2;
father[5]=5;
father[6]=5;
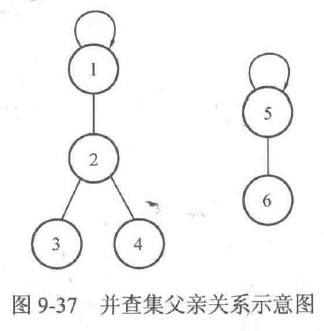
在图9-37中,father[1]=1 说明元素1的父亲结点是自己,即元素1是集合的根结点。father[2]=1说明元素2的父亲结点是元素1,father[3]=2和father[4] =2说明元素3和元素4的父亲结点都是元素2,这样元素1、2、3、4就在同一个集合当中。father[5] = 5和father[6]=5则说明5和6是以5为根结点的集合。这样就得到了两个不同的集合。
并查集的基本操作
总体来说,并查集的使用需要先初始化father数组,然后再根据需要进行查找或合并的操作。
初始化
一开始,每个元素都是独立的一个集合,因此需要令所有father[i]等于i。
查找
由于规定同一个集合中只存在一个根结点,因此查找操作就是对给定的结点寻找其根结点的过程。实现的方式可以是递推或是递归,但是其思路都是一样的,即反复寻找父亲结点,直到找到根结点(即father[i]==i的结点)。
递推的代码:
int find(int x)
{
while(x != father[x])
x=father[x];
return x;
}
递归来实现:
int find(int x)
{
if(x == father[x]) return x;
else return find(father[x]);
}
合并
合并是指把两个集合合并成一个集合,题目中一般给出两个元素,要求把这两个元素所在的集合合并。具体实现上一般是先判断两个元素是否属于同一个集合,只有当两个元素属于不同集合时才合并,而合并的过程一般是把其中一个集合的根结点的父亲指向另一个集合的根结点。
这里需要注意的是,很多初学者会直接把其中一个元素的父亲设为另一个元素,即直接令father[a]= b来进行合并,这并不能实现将集合合并的效果。例如,将上面例子中的father[4]设为6,或是把father[6]设为4,就不能实现集合合并的效果,如图9-39所示。
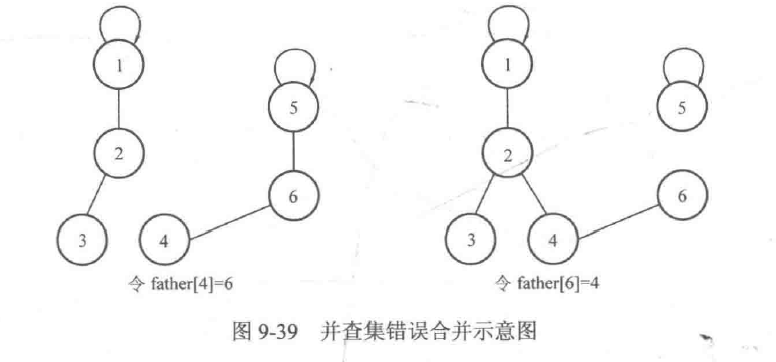
最后说明并查集的一个性质。在合并的过程中,只对两个不同的集合进行合并,如果两个元素在相同的集合中,那么就不会对它们进行操作。这就保证了在同一个集合中一定不会产生环,即并查集产生的每一个集合都是一棵树。
路径压缩
上面讲解的并查集查找函数是没有经过优化的,在极端情况下效率较低。现在来考虑一种情况,即题目给出的元素数量很多并且形成一条链,那么这个查找函数的效率就会非常低。
如图9-40所示,总共有\(10^5\)个元素形成一条链,那么假设要进行\(10^5\)次查询,且每次查询都查询最后面的结点的根结点,那么每次都要花费\(10^5\)的计算量查找,这显然无法承受。
那应该如何去优化查询操作呢?
由于findFather函数的目的就是查找根结点,例如下面这个例子:
father[1]=1;
father[2]=1;
father[3]=2;
father[4]=3;
因此,如果只是为了查找根结点,那么完全可以想办法把操作等价地变成:
father[1]=1;
father[2]=1;
father[3]=1;
father[4]=1;
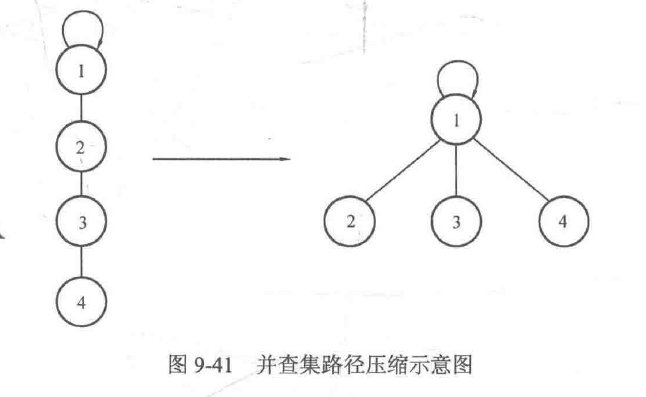
这样相当于把当前查询结点的路径上的所有结点的父亲都指向根结点,查找的时候就不需要一直回溯去找父亲了,查询的复杂度可以降为\(O(1)\)。
那么,如何实现这种转换呢?回忆之前查找函数findFather(的查找过程,可以知道是从给定结点不断获得其父亲结点而最终到达根结点的。
因此转换的过程可以概括为如下两个步骤:
①按原先的写法获得x的根结点r。
②重新从x开始走一遍寻找根结点的过程,把路径上经过的所有结点的父亲全部改为根结点r。
由于涉及一些复杂的数学推导,读者可以把路径压缩后的并查集查找函数均摊效率认为是一个几乎为\(O(1)\)的操作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号