《算法笔记》第十一章——动态规划 学习记录
动态规划是一种非常精妙的算法思想,它没有固定的写法、极其灵活,常常需要具体问题具体分析。和之前介绍的大部分算法不同,一开始就直接讨论动态规划的概念并不是很好的学习方式,反而先接触一些经典模型会有更好的效果。因此本章主要介绍一些动态规划的经典模型,并在其中穿插动态规划的概念,让读者慢慢接触动态规划。同时请读者不要畏惧,多训练、多思考、多总结是学习动态规划的重点。
什么是动态规划
动态规划(Dynamic Programming, DP)是一种用来解决一类最优化问题的算法思想。
简单来说,动态规划将一个复杂的问题分解成若干个子问题,通过综合子问题的最优解来得到原问题的最优解。需要注意的是,动态规划会将每个求解过的子问题的解记录下来,这样当下一次碰到同样的子问题时,就可以直接使用之前记录的结果,而不是重复计算。注意:虽然动态规划采用这种方式来提高计算效率,但不能说这种做法就是动态规划的核心(后面会说明这一一点)。
一般可以使用递归或者递推的写法来实现动态规划,其中递归写法在此处又称作记忆化搜索。
动态规划的递归写法
先来讲解递归写法。通过这部分内容的学习,读者应能理解动态规划是如何记录子问题的解,来避免下次遇到相同的子问题时的重复计算的。以斐波那契(Fibonacci)数列为例,斐波那契数列的定义为\(F_0=1,F_1=1,F_n=F_{n-1}+F_{n-2}(n≥2)\)。在4.3节是按下面的代码来计算的:
int F(int n) {
if(n == 0 || n == 1) return 1;
else return F(n-1)+F(n-2);
}
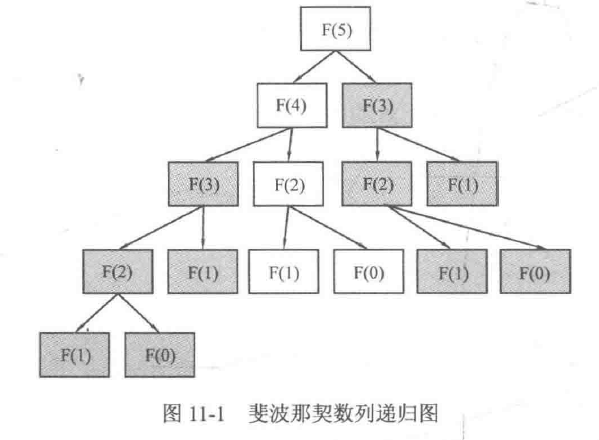
事实上,这个递归会涉及很多重复的计算。当n=5时,可以得到F(5) = F(4) + F(3), 接下来在计算F(4)时又会有F(4)= F(3) + F(2)。 这时候如果不采取措施,F(3)将会被计算两次。可以推知,如果n很大,重复计算的次数将难以想象。事实上,由于没有及时保存中间计算的结果,实际复杂度会高达\(O(2^n)\),即每次都会计算F(n-1)和F(n-2)这两个分支,基本不能承受n较大的情况。
为了避免重复计算,可以开一个一维数组dp,用以保存已经计算过的结果,其中dp[n]记录F(n)的结果,并用dp[n]=-1表示F(n)当前还没有被计算过。
然后就可以在递归当中判断dp[n]是否是-1: 如果不是-1, 说明已经计算过F(n),直接返回dp[n]就是结果;否则,按照递归式进行递归。代码如下:
int F(int n) {
if(n == 0 || n == 1) return 1;
if(dp[n] != -1) return dp[n];//已经计算过
else {
dp[n]=F(n-1)+F(n-2);//计算F(n),并保存至dp[n]
return dp[n];//返回F(n)的结果
}
}
这样就把已经计算过的内容记录了下来,于是当下次再碰到需要计算相同的内容时,就能直接使用上次计算的结果,这可以省去大半无效计算,而这也是记忆化搜索这个名字的由来。如图11-2所示,通过记忆化搜索,把复杂度从\(O(2^n)\)降到了\(O(n)\),也就是说,用一个\(O(n)\)空间的力量就让复杂度从指数级别降低到了线性级别。这是不是很令人振奋呢?
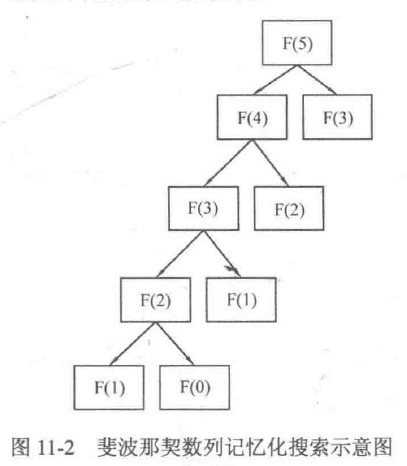
通过上面的例子可以引申出一个概念:如果一个问题可以被分解为若千个子问题,且这些子问题会重复出现,那么就称这个问题拥有重叠子问题(Overlapping Subproblems)。动态规划通过记录重叠子问题的解,来使下次碰到相同的子问题时直接使用之前记录的结果,
以此避免大量重复计算。因此,一个问题必须拥有重叠子问题,才能使用动态规划去解决。
动态规划的递推写法
以经典的数塔问题为例,如图11-3 所示,将一些数字排成数塔的形状,其中第一层有一个数字,第二层有两个数字....第n层有n个数字。现在要从第一层走到第n层,每次只能走向下一层连接的两个数字中的一个,问:最后将路径上所有数字相加后得到的和最大是多少?
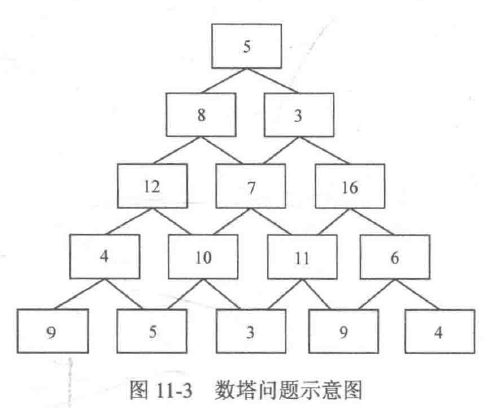
按照题目的描述,如果开一个二维数组f,其中f[i][i]存放第i层的第j个数字,那么就有f[1][1]=5, f[2][1]=8, f[2][2]=3, f[3][1]= 12, f[5][4]=9, f[5][5]=4。
此时,如果尝试穷举所有路径,然后记录路径上数字和的最大值,那么由于每层中的每个数字都会有两条分支路径,因此可以得到时间复杂度为\(O(2^n)\),这在n很大的情况下是不可接受的。那么,产生这么大复杂度的原因是什么?下面来分析一下。
开始,从第一层的5出发,按5→8→7的路线来到7,并枚举从7出发的到达最底层的所有路径。但是,之后当按5→3→7的路线再次来到7时,又会去枚举从7出发的到达最底层的所有路径,这就导致了从7出发的到达最底层的所有路径都被反复地访问,做了许多多余的计算。
事实上,可以在第一次枚举从7出发的到达最底层的所有路径时就把路径上能产生的最大和记录下来,这样当再次访问到7这个数字时就可以直接获取这个最大值,避免重复计算。
由上面的考虑,不妨令dp[i][i]表示从第i行第j个数字出发的到达最底层的所有路径中能得到的最大和,例如dp[3][2]就是图中的7到最底层的路径最大和。在定义这个数组之后,dp[1][1]就是最终想要的答案,现在想办法求出它。
注意到一个细节:如果要求出“从位置(1, 1)到达最底层的最大和”dp[1][1], 那么一定要先求出它的两个子问题“ 从位置(2, 1)到达最底层的最大和dp[2][1]”和“从位置(2, 2)到达最底层的最大和dp[2][2]", 即进行了一次决策:走数字5的左下还是右下。于是dp[1][1]就是dp[2][1]和dp[2][2]的较大值加上5。写成式子就是:
由此可以归纳得到这么一个信息:如果要求出dp[i][j],那么一定要先求出它的两个子问题“从位置(i + 1, j)到达最底层的最大和dp[i+ 1][j]” 和“从位置(i+ 1,j + 1)到达最底层的最大和dp[i+ 1][j+1]”,即进行了一次决策:走位置(i, j)的左下还是右下。于是dp[i][j]就是dp[i+1][j]和dp[i + 1]j+ 1]的较大值加上f[i][j]。写成式子就是:
把dp[i][i]称为问题的状态,而把上面的式子称作状态转移方程,它把状态dp[i][j]转移为dp[i+1][j]和dp[i+1][j+1]。可以发现,状态dp[i][j]只与第i + 1层的状态有关,而与其他层的状态无关,这样层号为i的状态就总是可以由层号为i+ 1的两个子状态得到。那么,如果总是将层号增大,什么时候会到头呢?可以发现,数塔的最后一层的dp值总是等于元素本身, 即\(dp[n][j] = f[n][j] (1≤j≤n)\),把这种可以直接确定其结果的部分称为边界,而动态规划的递推写法总是从这些边界出发,通过状态转移方程扩散到整个dp数组。
这样就可以从最底层各位置的dp值开始,不断往上求出每一层各位置的dp值,最后就会得到dp[1][1],即为想要的答案。
#include<iostream>
using namespace std;
const int N=510;
int a[N][N];
int f[N][N];
int n;
int main()
{
cin>>n;
for(int i=1;i<=n;i++)
for(int j=1;j<=i;j++)
cin>>a[i][j];
for(int i=1;i<=n;i++) f[n][i]=a[n][i];
for(int i=n-1;i>=1;i--)
for(int j=i;j>=1;j--)
f[i][j]=max(f[i+1][j],f[i+1][j+1])+a[i][j];
cout<<f[1][1]<<endl;
return 0;
}
\(j\)倒序或正序循环均可,因为第\(i+1\)层的状态在循环第\(i\)层时均已计算出。
显然,使用递归也可以实现上面的例子(即从dp[1][1]开始递归,直至到达边界时返回结果)。两者的区别在于:使用递推写法的计算方式是自底向上(Bottom-up Approach),即从边界开始,不断向上解决问题,直到解决了目标问题;而使用递归写法的计算方式是自顶向下(Top-down Approach),即从目标问题开始,将它分解成子问题的组合,直到分解至边界为止。
通过上面的例子再引申出一个概念:如果一个问题的最优解可以由其子问题的最优解有效地构造出来,那么称这个问题拥有最优子结构(Optimal Substructure)。 最优子结构保证了动态规划中原问题的最优解可以由子问题的最优解推导而来。因此,一个问题必须拥有最优子结构,才能使用动态规划去解决。例如数塔问题中,每一个位置的dp值都可以由它的两个子问题推导得到。
至此,重叠子问题和最优子结构的内容已介绍完毕。需要指出,一个问题必须拥有重叠子问题和最优子结构,才能使用动态规划去解决。下面指出这两个概念的区别:
- 分治与动态规划。
分治和动态规划都是将问题分解为子问题,然后合并子问题的解得到原问题的解。但是不同的是,分治法分解出的子问题是不重叠的,因此分治法解决的问题不拥有重叠子问题,而动态规划解决的问题拥有重叠子问题。
例如,归并排序和快速排序都是分别处理左序列和右序列,然后将左右序列的结果合并,过程中不出现重叠子问题,因此它们使用的都是分治法。另外,分治法解决的问题不一定是最优化问题,而动态规划解决的问题一定是最优化问题。
- 贪心与动态规划。
贪心和动态规划都要求原问题必须拥有最优子结构。二者的区别在于,贪心法采用的计算方式类似于上面介绍的“自顶向下”,但是并不等待子问题求解完毕后再选择使用哪一个,而是通过一种策略直接选择一个子问题去求解,没被选择的子问题就不去求解了,直接抛弃。
也就是说,它总是只在上一步选择的基础上继续选择,因此整个过程以一种单链的流水方式进行,显然这种所谓“最优选择”的正确性需要用归纳法证明。
例如对数塔问题而言,贪心法从最上层开始,每次选择左下和右下两个数字中较大的一个,一直到最底层得到最后结果,显然这不一定可以得到最优解。
而动态规划不管是采用自底向上还是自顶向下的计算方式,都是从边界开始向上得到目标问题的解。也就是说,它总是会考虑所有子问题,并选择继承能得到最优结果的那个,对暂时没被继承的子问题,由于重叠子问题的存在,后期可能会再次考虑它们,因此还有机会成为全局最优的一部分, 不需要放弃。
所以贪心是一种壮士断腕的决策,只要进行了选择,就不后悔;动态规划则要看哪个选择笑到了最后,暂时的领先说明不了什么。
最大连续子序列和
给定一个数字序列\(A_1,A_2,,A_n\),求\(i,j(1≤i≤j≤n)\),使得\(A_i+...+A_j\)最大,输出这个最大和。
这个问题如果暴力来做,枚举左端点和右端点(即枚举i, j)需要\(O(n^2)\)的复杂度,而计算A[i]+... +A[j]需要\(O(n)\)的复杂度,因此总复杂度为\(O(n^3)\)。就算采用记录前缀和的方法(预处理S[i]=A[0]+A[1]+...+A[i],这样A[i]+... +A[j]=S[j]- S[i -1])使计算的时间变为\(O(1)\),总复杂度仍然有\(O(n^2)\),这对n为\(10^5\)大小的题目来说是无法承受的。
下面介绍动态规划的做法,复杂度为\(O(n)\),读者会发现其实左端点的枚举是没有必要的。
步骤1:令状态dp[i]表示以A[i]作为末尾的连续序列的最大和(这里是说A[i]必须作为连续序列的末尾)。以样例为例:序列-2 11 -4 13 -5 -2, 下标分别记为0,1,2,3,4,5那么
dp[0]=-2;
dp[1]=11,
dp[2]=11+(-4)=7,
dp[3]=11+(-4)+13=20,
dp[4]=15(因为由dp数组的含义,A[4]=-5必须作为连续序列的结尾,于是最大和就是11+(-4)+13+(-5)=15,而不是20),dp[5]=11+(-4)+13+(-5)+(-2)=13.
通过设置这么一个dp数组,要求的最大和其实就是dp[0], d[1], dp[n-1]中的最大值(因为到底以哪个元素结尾未知),下面想办法求解dp数组。
步骤2:作如下考虑:因为dp[i]要求是必须以A[i]结尾的连续序列,那么只有两种情况:
- 这个最大和的连续序列只有一个元素,即以A[i]开始,以A[i]结尾。
- 这个最大和的连续序列有多个元素,即从前面某处A[p]开始(p<i),一直到A[i]结尾。
对第一种情况,最大和就是A[i]本身。
对第二种情况,最大和是dp[i- 1]+A[i],即A[p] +...+ A[i- 1]+ A[i]= dp[i- 1] + A[i]。
由于只有这两种情况,于是得到状态转移方程:
这个式子只和i与i之前的元素有关,且边界为dp[0]= A[0],由此从小到大枚举i,即可得到整个dp数组。接着输出dp[0], dp[1],... , dp[n - 1]中的最大值即为最大连续子序列的和。
只用\(O(n)\)的时间复杂度就解决了原先需要\(O(n^2)\)复杂度问题,就是动态规划的魅力。
此处顺便介绍无后效性的概念。状态的无后效性是指:当前状态记录了历史信息,一旦当前状态确定,就不会再改变,且未来的决策只能在已有的一一个或若千个状态的基础上进行,历史信息只能通过已有的状态去影响未来的决策。例如宇宙的历史可以看作一个关于时间的线性序列,对每一个时刻来说,宇宙的现状就是这个时刻的状态,显然宇宙过去的信息蕴含在当前状态中,并只能通过当前状态来影响下一个时刻的状态,因此从这个角度来说宇宙的关于时间的状态具有无后效性。而针对本节的问题来说,每次计算状态dp[i], 都只会涉及dp[i-1],而不直接用到dp[i- 1]蕴含的历史信息。
对动态规划可解的问题来说,总会有很多设计状态的方式,但并不是所有状态都具有无后效性,因此必须设计一个拥有无后效性的状态以及相应的状态转移方程,否则动态规划就没有办法得到正确结果。事实上,如何设计状态和状态转移方程,才是动态规划的核心,而它们也是动态规划最难的地方。
最长不下降子序列(LIS)
在一个数字序列中,找到一个最长的子序列(可以不连续),使得这个子序列是不下降(非递减)的。
例如,现有序列A={1,2,3,-1,-2,7,9} (下标从1开始),它的最长不下降子序列是{1,2,3,7,9},长度为5。另外,还有一些子序列是不下降子序列,比如{1,2,3}、 {-2,7,9}等,但都不是最长的。
对于这个问题,可以用最原始的办法来枚举每种情况,即对于每个元素有取和不取两种选择,然后判断序列是否为不下降序列。如果是不下降序列,则更新最大长度,直到枚举完所有情况并得到最大长度。但是很严峻的一个问题是,由于需要对每个元素都选择取或者不取,那么如果元素有n个,时间复杂度将高达\(O(2^n)\),这显然是不能承受的。
事实上这个枚举过程包含了大量重复计算。那么这些重复计算源自哪里呢?不妨先来看动态规划的解法,之后就会容易理解为什么会有重复计算产生了(下文中出现的LIS均指最长不下降子序列)。
令dp[i]表示以A[i]结尾的最长不下降子序列长度(和最大连续子序列和问题一样, 以A[i]结尾是强制的要求)。这样对A[i]来说就会有两种可能:
- 如果存在A[i]之前的元素Aj,使得A[j]≤A[i]且dp[j] + 1 > dp[i] (即把A[j]跟在以A[j]结尾的LIS后面时能比当前以A[i]结尾的LIS长度更长),那么就把A[i]跟在以A[j]结尾的LIS后面,形成一条更长的不下降子序列(令dp[i]=dp[j]+1)。
- 如果A[i]之前的元素都比A[j]大,那么A[i]就只好自己形成一条LIS,但是长度为1,即这个子序列里面只有一个A[i]。
最后以A[i]结尾的LIS长度就是①②中能形成的最大长度。
为了使这个过程看得更清晰,下面举一个更有意思的例子。
现有一个序列{1,5,-1,3},其中的元素分别记为A[1]、A[2]、A[3]、 A[4]。
假设已经知道以A[1]、A[2]、A[3]为结尾的最长不下降子序列分别为{1}、{1,5}、 {-1},长度分别为1、2、1。那么如何知道以A[4]结尾的最长不下降子序列及其长度呢?由于必须以A[4]结尾,因此考虑分别把A[4]加到前面以A[1]、A[2]、A[3]结尾的最长不下降子序列后面,看看能不能使以某个A[j](j=1, 2, 3)为结尾的最长不下降子序列变得更长。
A[4]:喂,A[1]。我可以站在你后面成为更长的LIS吗?
A[1]:我看看,你比我高,当然可以,这样我们组合的新的LIS {1,3}长度就是2了。
A[4]:喂,A[2]。 我可以站在你后面成为更长的LIS吗?
A[2]:你那么矮,那还是算了,我这里本来长度就有2了,你就算来了也不增加LIS长度。
A[4]:喂,A[3]。我可以站在你后面成为更长的LIS吗?
A[3]:你好高啊,当然可以了,站在我后面LIS {-1,3}长度就为2了。
这样比较之后,A[4]只有加入A[1]或A[3]后面才会形成新的LIS,长度为2。
当然还有一种情况, 比如{1, 2, 3, -4},A[4]无论加在前面哪个元素后面,A[1]、A[2]、A[3]都嫌他矮,都不能形成新的更长的LIS,只能是孤零零的一人成为以A[4]结尾的LIS:{-4}。由此可以写出状态转移方程:
上面的状态转移方程中隐含了边界:dp[i]= 1(1≤i≤n)。显然dp[i]只与小于i的j有关,因此只要让i从小到大遍历即可求出整个dp数组。
由于dp[i]表示的是以A[i]结尾的LIS长度,因此从整个dp数组中找出最大的那个才是要寻求的整个序列的LIS长度,整体复杂度为\(O(n^2)\)。
到此就可以想象究竟重复计算出现在哪里了:每次碰到子问题“以A[i]结尾的最长不下降子序列”时,都去重新遍历所有子序列,而不是直接记录这个子问题的结果。
const int N=1010;
int a[N];
int f[N];
int n;
int main()
{
cin>>n;
for(int i=0;i<n;i++) cin>>a[i];
int ans=0;
for(int i=0;i<n;i++)
{
f[i]=1;
for(int j=0;j<i;j++)
if(a[j] <= a[i])
f[i]=max(f[i],f[j]+1);
ans=max(ans,f[i]);
}
cout<<ans<<endl;
//system("pause");
return 0;
}
最长公共子序列(LCS)
给定两个字符串(或数字序列) A和B,求一个字符串,使得这个字符串是A和B的最长公共部分(子序列可以不连续)。
还是先来看暴力的解法:设字符串A和B的长度分别是n和m,那么对两个字符串中的每个字符,分别有选与不选两个决策,而得到两个子序列后,比较两个子序列是否相同又需要\(O(max(m,n))\),这样总复杂度就会达到\(O(2^{m+n} \times max(m,n))\),无法承受数据大的情况。
直接来看动态规划的做法(下文的LCS均指最长公共子序列)。
令dp[i][j]表示字符串A的i号位和字符串B的j号位之前的LCS长度(下标从1开始),如dp[4][5]表示“sads”与“admin”的LCS长度。那么可以根据A[i]和B[j]的情况,分为两种决策:
-
若A[i]= B[j],则字符串A与字符串B的LCS增加了1位,即有dp[i][i] = dp[i - 1][j- 1]+ 1。例如,样例中dp[4][6]表示 “sads” 与“admins” 的LCS长度,比较A[4]与B[6],发现两者都是's',因此dp[4][6]就等于dp[3][5]加1,即为3。
-
若A[i] != B[j],则字符串A的i号位和字符串B的j号位之前的LCS无法延长,因此dp[i][j]将会继承dp[i - 1][]与dp[i][j - 1]中的较大值,即有dp[i][j] = max {dp[i - 1][i], dp[i][j-1]}。
例如,样例中dp[3][3]表示“sad”与“adm”的LCS长度,我们比较A[3]与B[3],发现'd不等于'm',这样dp[3][3]无法再原先的基础上延长,因此继承自“sa”与“adm”的LCS、“ad”与“ad”的LCS中的较大值,即“sad”与“ad”的LCS长度-2。
由此可以得到状态转移方程:
边界: dp[i][0] = dp[0][j]= 0 (0≤i≤n, 0≤j≤m)这样状态dp[][i]只与其之前的状态有关,由边界出发就可以得到整个dp数组,最终dp[n][m]就是需要的答案,时间复杂度为\(O(nm)\)。
const int N=110;
char a[N],b[N];
int f[N][N];
int n,m;
int main()
{
while(cin>>a+1>>b+1)
{
n=strlen(a+1);
m=strlen(b+1);
for(int i=0;i<=n;i++) f[i][0]=0;
for(int j=0;j<=m;j++) f[0][j]=0;
for(int i=1;i<=n;i++)
for(int j=1;j<=m;j++)
if(a[i] == b[j])
f[i][j]=f[i-1][j-1]+1;
else
f[i][j]=max(f[i-1][j],f[i][j-1]);
cout<<f[n][m]<<endl;
}
//system("pause");
return 0;
}
最长回文子串
给出一个字符串S,求S的最长回文子串的长度。
还是先看暴力解法:枚举子串的两个端点i和j,判断在[i, j]区间内的子串是否回文。从复杂度上来看,枚举端点需要\(O(n^2)\),判断回文需要\(O(n)\),因此总复杂度是\(O(n^3)\)。终于碰到一个暴力复杂度不是指数级别的问题了!但是\(O(n^3)\)的复杂度在n很大的情况依旧不够看。
可能会有读者想把这个问题转换为最长公共子序列(LCS)问题来求解:把字符串S倒过来变成字符串T,然后对S和T进行LCS模型求解,得到的结果就是需要的答案。而事实上这种做法是错误的,因为一旦S中同时存在一个子串和它的倒序,那么答案就会出错。
例如字符串S= "ABCDZJUDCBA",将其倒过来之后会变成T = "ABCDUJZDCBA",这样得到最长公共子串为"ABCD",长度为4,而事实上S的最长回文子串长度为1。因此这样的做法是不行的。
接下来介绍动态规划的方法,使用动态规划可以达到更优的\(O(n^2)\)复杂度,而最长回文子串有很多种使用动态规划的方法,这里介绍其中最容易理解的一种。
令dp[i][i]表示S[i]至S[j]所表示的子串是否是回文子串,是则为1,不是为0。这样根S[i]是否等于S[j],可以把转移情况分为两类:
-
若S[i] == S[j],那么只要S[i+1]至S[j-1]是回文子串,S[i]至S[j]就是回文子串;如果S[i+1]至S[j-1]不是回文子串,则S[i]至S[j]也不是回文子串。
-
若S[j] != S[j],那么S[i]至S[j]一定不是回文子串。
由此可以写出状态转移方程:
边界:dp[i][i]=1,dp[i][i+1] = (S[i]==S[i+1])?1:0。
到这里还有一个问题没有解决,那就是如果按照i和j从小到大的顺序来枚举子串的两个端点,然后更新dp[i][i],会无法保证dp[i+ 1][j- 1]已经被计算过,从而无法得到正确的dp[i][j]。
如图11-4所示,先固定i = 0,然后枚举j从2开始。当求解dp[0][2]时,将会转换为dp[1][1],而dp[1][1]是在初始化中得到的;当求解dp[0][3]时,将会转换为dp[1][2],而dp[1][2]也是在初始化中得到的;当求解dp[0][4]时,将会转换为dp[1][3],但是dp[1][3]并不是已经计算过的值,因此无法状态转移。事实上,无论对i和j的枚举顺序做何调整,都无法调和这个矛盾,因此必须想办法寻找新的枚举方式。
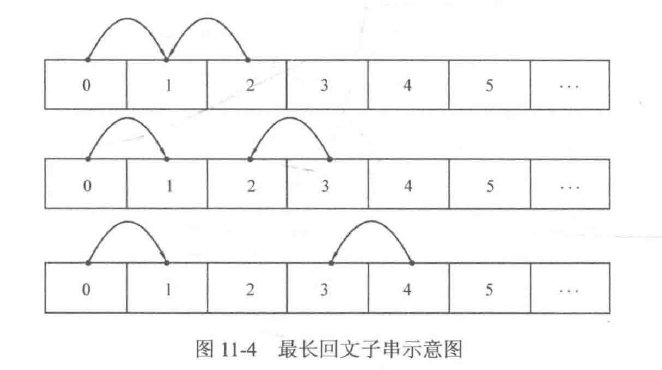
根据递推写法从边界出发的原理,注意到边界表示的是长度为1和2的子串,且每次转移时都对子串的长度减了1,因此不妨考虑按子串的长度和子串的初始位置进行枚举,即第一遍将长度为3的子串的dp值全部求出,第二遍通过第一遍结果计算出长度为4的子串的dp值....这样就可以避免状态无法转移的问题。如图11-5所示,可以先枚举子串长度L (注意: L是可以取到整个字符串的长度S.len()的),再枚举左端点i,这样右端点i+ L-1也可以直接得到。

class Solution {
static const int N=1010;
bool f[N][N];
public:
string longestPalindrome(string s) {
int n=s.size();
int ans=0;
int l=0;
for(int i=n-1;i>=0;i--)
for(int j=i;j<n;j++)
{
if(i == j) f[i][j]=true;
else if(i+1 == j) f[i][j]=(s[i] == s[j]);
else f[i][j]=f[i+1][j-1] && (s[i] == s[j]);
if(f[i][j] && j-i+1 > ans)
{
ans=j-i+1;
l=i;
}
}
return s.substr(l,ans);
}
};
至此,最长回文子串问题的动态规划方法已经介绍完毕。除此之外,最长回文子串问题还有一些其他做法,例如在12.1节中将会使用二分+字符串hash的做法,复杂度为\(O(nlogn)\)。
不过最优秀的当属复杂度为\(O(n)\)的Manachet算法,这个就不在此介绍了。
DAG最长路
DAG就是有向无环图,并且已经讨论了如何求解DAG中的最长路,也就是所谓的“关键路径”。但是求解关键路径的做法对初学者来说确实有些复杂,而DAG上的最长路或者最短路问题又是特别重要的一类问题,很多问题都可以转换成求解DAG上的最长或最短路径问题,因此有必要介绍一下 更简便的方法,也就是使用本节介绍的方法。由于DAG最长路和最短路的思想是一致的,因此下面以最长路为例。
本节着重解决两个问题:
①求整个DAG中的最长路径(即不固定起点跟终点)。
②固定终点,求DAG的最长路径。
先讨论第一个问题:给定一个有向无环图,怎样求解整个图的所有路径中权值之和最大的那条。
针对这个问题,令dp[i]表示从i号顶点出发能获得的最长路径长度,这样所有dp[i]的最大值就是整个DAG的最长路径长度。
那么怎样求解dp数组呢?注意到dp[i]表示从i号顶点出发能获得的最长路径长度,如果从i号顶点出发能直接到达顶点\(j_1、j_2、\cdots、j_k\),而\(dp[j_1]、dp[j_2]、\cdots 、dp[j_k]\)均已知,那么就有
显然,根据上面的思路,需要按照逆拓扑序列的顺序来求解dp数组。
但是有没有不求出逆拓扑序列也能计算dp数组的方法呢?当然有,那就是递归。
int DP(int i)
{
if(dp[i] > 0) return dp[i];
for(int j=0;j<n;j++)
if(g[i][j] != INF}
dp[i]=max(dp[i],DP(j)+g[i][j]);
return dp[i];
}
由于从出度为0的顶点出发的最长路径长度为0,因此边界为这些顶点的dp值为0。但具体实现中不妨对整个dp数组初始化为0,这样dp函数当前访问的顶点i的出度为0时就会返回dp[i] = 0 (以此作为dp的边界),而出度不是0的顶点则会递归求解,递归过程中遇到已经计算过的顶点则直接返回对应的dp值,于是从程序逻辑上按照了逆拓扑序列的顺序进
行。
回忆在Djkstra算法中是如何求解最短路径的。开了个int 型数组pre,来记录每个顶点的前驱,每当发现更短的路径时对pre进行修改。事实上,可以把这种想法应用于求解最长路径上一开一个int型choice数组记录最长路径上顶点的后继顶点,这样就可以像Dijkstra算法中那样来求解最长路径了,只不过由于choice数组存放的是后继顶点,因此使用
迭代即可(当然使用递归也是可以的),如下面的代码所示。如果最终可能有多条最长路径,将choice数组改为vector类型的数组即可(也就是Dijkstra算法中有多条最短路径时的做法。
void printPath(int i)
{
printf("%d",i);
while(choice[i] != -1)
{
i=choice[i];
printf("->%d",i);
}
}
对一般的动态规划问题而言,如果需要得到具体的最优方案,可以采用类似的方法,即记录每次决策所选择的策略,然后在dp数组计算完毕后根据具体情况进行递归或者迭代来获取方案。
提出这样一个问题:如果DAG中有多条最长路径,如何选取字典序最小的那条?很简单,只需要让遍历i的邻接点的顺序从小到大即可(事实上,上面的代码自动实现了这个功能)。
至此,都是令dp[i]表示从i号顶点出发能获得的最长路径长度。那么,如果令dp[i]表示以i号顶点结尾能获得的最长路径长度,又会有什么结果呢?可以想象,只要把求解公式变为\(dp[i]= \max (dp[j]+ length[j \rightarrow i]|(j,i) \in E)\)(相应的求解顺序变为拓扑序),就可以同样得到最长路径长度,也可以设置choice数组求出具体方案。
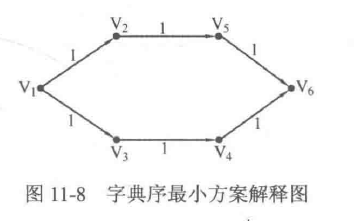
但却不能直接得到字典序最小的方案,这是为什么呢?举个很简单的例子,如图11-8所示,如果令dp[i]表示从i号顶点出发能获得的最长路径长度,且dp[2]和dp[3]已经计算得到,那么计算dp[1]的时候只需要从V2和V3中选择字典序较小的V2即可;而如果令dp[i]表示以i号顶点结尾能获得的最长路径长度,且dp[4]和dp[5]已经计算得到,那么计算dp[6]时如果选择了字典序较小的V4,则会导致错误的选择结果:理论上应当是Vi→V2→Vs的字典序最小,可是却选择了Vi→V3→V4。显然,由于字典序的大小总是先根据序列中较前的部分来判断,因此序列中越靠前的顶点,其dp值应当越后计算(对一般的序列型动态规划问题也是如此)。
在上面讨论的基础上,接下来讨论本节开头的第二个问题:固定终点,求DAG的最长路径长度。
有了上面的经验,应当能很容易想到这个延伸问题的解决方案。假设规定的终点为T,那么可以令dp[i]表示从i号顶点出发到达终点T能获得的最长路径长度。同样的,如果从i号顶点出发能直接到达顶点\(j_1、j_2、\cdots 、j_k\),而\(dp[j_1]、dp[j_2] \cdots dp[j_k]\)均已知,那么就有\(dp[i]= \max (dp[i]+ length[i \rightarrow j]|(i,j) \in E)\)。
可以发现,这个式子和第一个问题的式子是一样的一但如果仅仅是这样,显然无法体现出dp数组的含义中增加的“到达终点T”的描述。那么这两个问题的区别应当体现在哪里呢?没错,边界。在第一个问题中没有固定终点,因此所有出度为0的顶点的dp值为0是边界;但是在这个问题中固定了终点,因此边界应当为dp[T]=0。
那么可不可以像之前的做法那样,对整个dp数组都赋值为0呢?不行,此处会有一点问题。由于从某些顶点出发可能无法到达终点T(例如出度为0的顶点),因此如果按之前的做法会得到错误的结果(例如出度为0的顶点会得到0),这从含义上来说是不对的。
合适的做法是初始化dp数组为一个负的大数,来保证“无法到达终点”的含义得以表达(即-INF);然后设置一个vis数组表示顶点是否已经被计算。
int DP(int i)
{
if(vis[i]) return dp[i];
vis[i]=true;
for(int j=0;j<n;j++)
if(g[i][j] != INF}
dp[i]=max(dp[i],DP(j)+g[i][j]);
return dp[i];
}
至于如何记录方案以及如何选择字典序最小的方案,均与第一个问题相同,此处不再赘述。读者需要思考,如果令dp[i]表示以i号顶点结尾能获得的最长路径长度,应当如何处理?
事实上这样设置dp[]会变得更容易解决问题,并且dp[T]就是结果,只不过仍然不方便处理字典序最小的情况。
至此,DAG最长路的两个关键问题都已经解决,最短路的做法与之完全相同,留给读者思考。那么具体什么场景可以应用到呢?除了关键路径求解以外,可以把一些问题转换为DAG的最长路,例如经典的矩形嵌套问题。
矩形嵌套问题:给出n个矩阵的长和宽,定义矩形的嵌套关系为:如果有两个矩形A和B,其中矩形A的长和宽分别为a、b,矩形B的长和宽分别为c、d,且满足a<c、b<d,或a<d、b<c,则称矩形A可以嵌套于矩形B内。现在要求一个矩形序列,使得这个序列中任意两个相邻的矩形都满足前面的矩形可以嵌套于后一个矩形内,且序列的长度最长。如果有多个这样的最长序列,选择矩形编号序列的字典序最小的那个。
这个例子就是典型的DAG最长路问题,在很多教材中都会介绍。将每个矩形都看成一个顶点,并将嵌套关系视为顶点之间的有向边,边权均为1,于是就可以转换为DAG最长路问题。
背包问题
背包问题是一类经典的动态规划问题,它非常灵活、变体多样,需要仔细体会。本书只介绍两类最简单的背包问题: 01 背包问题和完全背包问题,而这两种背包中,又以01背包为重。
多阶段动态规划问题
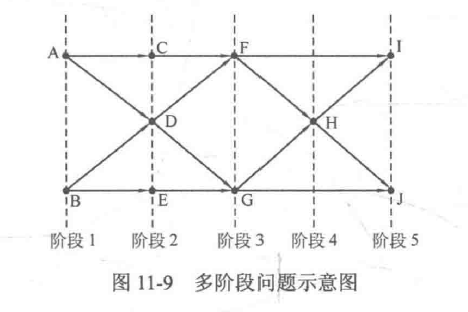
有一类动态规划可解的问题,它可以描述成若千个有序的阶段,且每个阶段的状态只和上一个阶段的状态有关,一般把这类问题称为多阶段动态规划问题。
如图11-9所示,该问题被分为了5个阶段,其中状态F属于阶段3,它由状态2的状态C和状态D推得。显然,对这种问题,只需要从第一个问题开始,按照阶段的顺序解决每个阶段中状态的计算,就可以得到最后一个阶段中的状态的解。这对设计状态的具体含义是很有帮助的,01背包问题就是这样一个例子。
动态规划是如何避免重复计算的问题在01背包问题中非常明显。在一开始暴力枚举每件物品放或者不放入背包时,其实忽略了一个特性:第i件物品放或者不放而产生的最大值是完全可以由前面i- 1件物品的最大值来决定的,而暴力做法无视了这一点。
另外,01背包中的每个物品都可以看作一个阶段,这个阶段中的状态有dp[i][0] ~ dp[i][V],它们均由上一个阶段的状态得到。事实上,对能够划分阶段的问题来说,都可以尝试把阶段作为状态的一维,这可以使我们更方便地得到满足无后效性的状态。
从中也可以得到这么一个技巧,如果当前设计的状态不满足无后效性,那么不妨把状态进行升维,即增加一维或若干维来表示相应的信息,这样可能就能满足无后效性了。
总结
(1)最大连续子序列和
令dp[i]表示以A[i]作为末尾的连续序列的最大和。
(2)最长不下降子序列(LIS)
令dp[i]表示以A[i]结尾的最长不下降子序列长度。
(3)最长公共子序列(LCS)
令dp[i][j]表示字符串A的i号位和字符串B的j号位之前的LCS长度。
(4)最长回文子串
令dp[i][i]表示S[i]至S[j]所表示的子串是否是回文子串。
(5)数塔DP
令dp[i][j]表示从第i行第j个数字出发的到达最底层的所有路径上所能得到的最大和。
(6) DAG最长路
令dp[i]表示从i号顶点出发能获得的最长路径长度
先看(1) ~ (4),这4个都是关于序列或字符串的问题(特别说明: 一般来说,“子序列”可以不连续,“子串”必须连续)。可以注意到,(1) (2)设计状态的方法都是“令dp[i]表示以A[i]为结尾的XXX”,其中XXX即为原问题的描述,然后分析A[i]的情况来进行状态转移。
而(3)(4)由于原问题本身就有二维性质,因此使用了“令dp[i][j]表示i号位和j号位之间XXX”的状态设计方式,其中XXX为原问题的描述(最长回文子串中的状态和原问题有关;当然,最长回文子串的状态也可以设计成“令dp[]i]表示S[i]至S[j]的区间的最长回文子串长度”,并且可解)。这就给了我们一些启发:
当题目与序列或字符串(记为A)有关时,可以考虑把状态设计成下面两种形式,然后根据端点特点去考虑状态转移方程。
- 令dp[i表示以A[i]结尾(或开头)的XXX。
- 令dp[ilj]表示A[i]至A[j]区间的XXX.
其中XXX均为原问题的表述。
接着来看(5) ~ (6),可以发现它们的状态设计都包含了某种“方向”的意思。如数塔DP中设计为丛点(i, j)出发到达最底层的最大和,DAG最长路中设计为丛i号顶点出发的最长路。
在每一维的含义设置完毕之后,dp数组的含义就可以设置成“令dp数组表示恰好为i,(或前i)、恰好为j (或前j) ...的XXX”,其中XXX为原问题的描述。接下来就可以通过端点的特点去考虑状态转移方程。
最后需要说明的是,在大多数的情况下,都可以把动态规划可解的问题看作一个有向无环图(DAG),图中的结点就是状态,边就是状态转移的方向,求解问题的顺序就是按照DAG的拓扑序进行求解。从这个角度可以辅助理解动态规划,建议读者能结合讲解过的几个动态规划模型予以理解。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号