
MongoDB补充知识
文档操作的补充
涉及到数据的嵌套查找 支持直接点键或者索引
db.t1.deleteOne({'addr.counytry':'Japan'})
db.t1.deleteOne({'hobby.1':'tea'})
.键.索引.索引.键 可以无限制往下点点点
用户权限管理
涉及到用户权限相关 引号推荐全部使用双引号
mongodb针对用户权限的创建,数据可以保存在不同的数据库下之后再登录的时候只需要自己指定账户数据来源于哪个数
据库即可但是管理员用户数据一般情况下推荐保存到admin库下而普通用户任意库都可以,我们为了便于管理可以再test库下创建
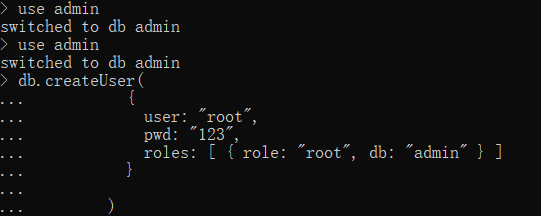
管理员账户需要在admin数据库下创建
1.切换到admin数据库下
use admin
2.创建账户并且赋予权限
db.createUser(
{
user: "root",
pwd: "123",
roles: [ { role: "root", db: "admin" } ]
}
)
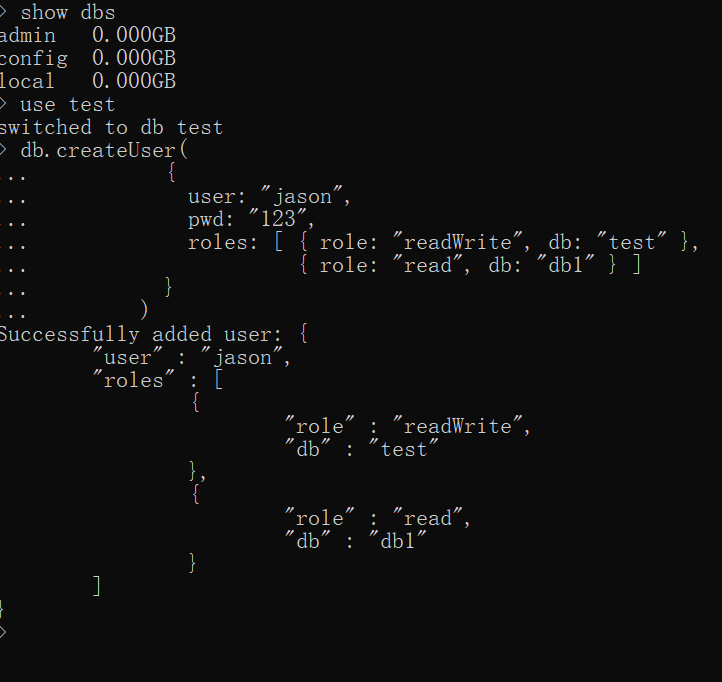
其他用户在test数据库下面创建
1.切换到test数据库下
use test
2.创建账户并赋予权限
db.createUser(
{
user: "jason",
pwd: "123",
roles: [ { role: "readWrite", db: "test" },
{ role: "read", db: "db1" } ]
}
)
最好使用管理员打开cmd操作下列命令
先停止服务
net stop mongodb
在移除服务
MongoDB --remove
再次添加
mongod --bind_ip 0.0.0.0 --port 27017 --
logpath E:\MongoDB\Server\5.0\log\mongod.log
--logappend --dbpath
E:\MongoDB\Server\5.0\data --serviceName "MongoDB"
--serviceDisplayName "MongoDB" --install --auth
再次启动
net start MongoDB
两种验证方式
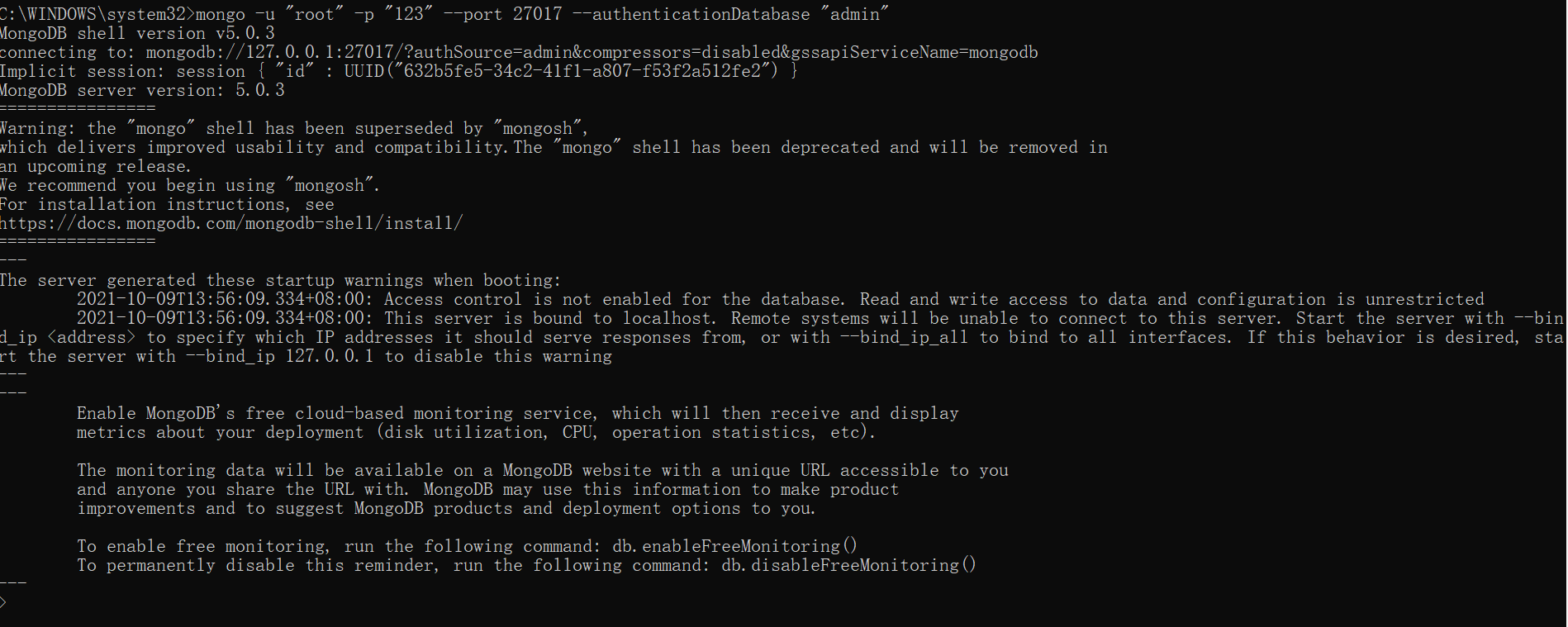
1.直接在登陆的时候验证
mongo -u "root" -p "123" --port 27017 --authenticationDatabase "admin"
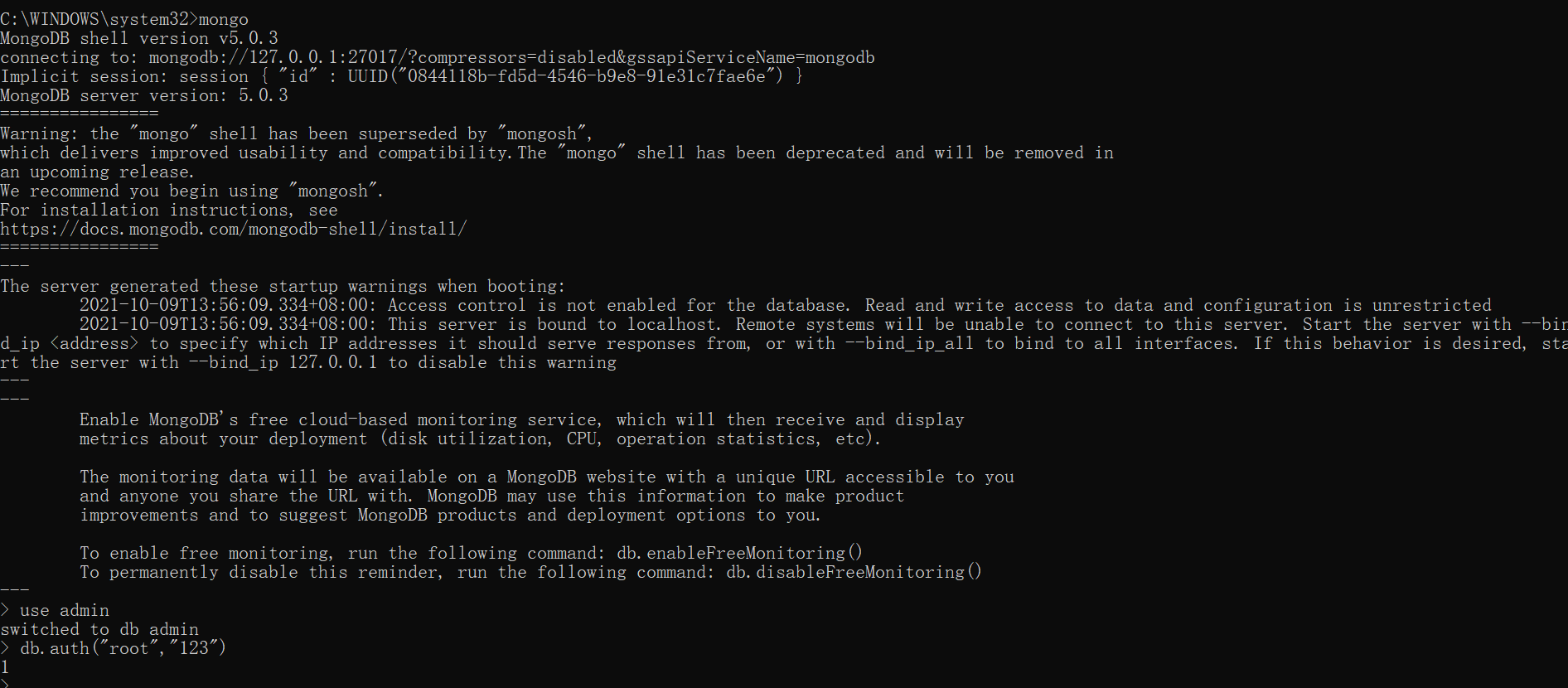
2.进入之后验证
mongo
use admin
db.auth("root","123")
在公司里面所有的数据库都会有权限管理
数据准备
针对数据的主键值 不知道会默认创建知道了则使用指定的
插入单条
user0={
"name":"jason",
"age":10,
'hobbies':['music','read','dancing'],
'addr':{
'country':'China',
'city':'BJ'
}
}
db.user.insert(user0)
插入多条
user1={
"_id":1,
"name":"ax",
"age":10,
'hobbies':['music','read','dancing'],
'addr':{
'country':'China',
'city':'weifang'
}
}
user2={
"_id":2,
"name":"wi",
"age":20,
'hobbies':['music','read','run'],
'addr':{
'country':'China',
'city':'hebei'
}
}
user3={
"_id":3,
"name":"yo",
"age":30,
'hobbies':['music','drink'],
'addr':{
'country':'China',
'city':'heibei'
}
}
user4={
"_id":4,
"name":"jg",
"age":40,
'hobbies':['music','read','dancing','tea'],
'addr':{
'country':'China',
'city':'BJ'
}
}
user5={
"_id":5,
"name":"jn",
"age":50,
'hobbies':['music','read',],
'addr':{
'country':'China',
'city':'henan'
}
}
db.user.insertMany([user1,user2,user3,user4,user5])
NoSQL诀窍
在一开始不熟练的情况下 可以先写出SQl语句 之后对比着拼接出NoSQL语句
查询
并且在书写mongodb查询语句的时候,我们可以先使用MySQL的SQL语句
然后参考SQL语句再书写mongodb语句(相当于将MySQL语句翻译成mongodb)
查询指定字段
select name,age from db1.user where id=3;
db.user.find(
{'_id':3},
{'_id':0,'name':1,'age':1}
)
0表示不要,1表示要
针对主键字段 _id如果不指定默认是必拿的
普通字段不写就表示不拿
比较运算符
SQL:=,!=,>,<,>=,<=
MongoDB:{key:value}代表什么等于什么,
"$ne","$gt","$lt","$gte","$lte"
#1、select * from db1.user where name = "jason";
db.user.find({'name':'jason'})
#2、select * from db1.user where name != "jason";
db.user.find({'name':{"$ne":'jason'}})
#3、select * from db1.user where id > 2;
db.user.find({'_id':{'$gt':2}})
#4、select * from db1.user where id < 3;
db.user.find({'_id':{'$lt':3}})
#5、select * from db1.user where id >= 2;
db.user.find({"_id":{"$gte":2,}})
#6、select * from db1.user where id <= 2;
db.user.find({"_id":{"$lte":2}})
逻辑运算符
# SQL:and,or,not
# MongoDB:字典中逗号分隔的多个条件是and关系"$or"的条件放到[]内 "$not"取反
#1、select * from db1.user where id >= 2 and id < 4;
db.user.find({'_id':{"$gte":2,"$lt":4}})
#2、select * from db1.user where id >= 2 and age < 40;
db.user.find({"_id":{"$gte":2},"age":{"$lt":40}})
#3、select * from db1.user where id >= 5 or name = "ax";
db.user.find({
"$or":[
{'_id':{"$gte":5}},
{"name":"ax"}
]
})
"""取反操作了解一下即可"""
#4、select * from db1.user where id % 2=1;
db.user.find({'_id':{"$mod":[2,1]}})
#5、上题,取反
db.user.find({'_id':{"$not":{"$mod":[2,1]}}})
成员运算
# SQL:in,not in
# MongoDB:"$in","$nin"
#1、select * from db1.user where age in (20,30,31);
db.user.find({"age":{"$in":[20,30,31]}})
#2、select * from db1.user where name not in ('ax','yo');
db.user.find({"name":{"$nin":['ax','yo']}})
#3、select * from db1.user where age in (20,30,31) or name!='jason';
db.user.find({
'$or':[
{'age':{'$in':[20,30,31]}},
{'name':{'$ne':'jason'}}
]
})
正则匹配
用一些符号的组合取文本中筛选出符合条件的数据
# SQL: regexp 正则
# MongoDB: /正则表达/i
#1、select * from db1.user where name regexp '^j.*?(g|n)$';
db.user.find({'name':/^j.*?(g|n)$/i})
范围/模糊查询
find({查询条件},{筛选字段})
MySQL
关键字 like
关键符号
% 匹配任意个数的任意字符
_ 匹配单个个数的任意字符
MongoDB:
通过句点符
$all
1.查看有dancing爱好的人
db.user.find({'hobbies':'dancing'}) # 默认就是范围查询
2.查看机油dancing爱好又有tea爱好的人
db.user.find({
'hobbies':{
"$all":['dancing','tea']
}
})
3.查看第四个爱好为tea的人
db.user.find({"hobbies.3":'tea'})
4.查看所有人最后两个爱好
db.user.find({},{'_id':0,'name':1,'hobbies':{"$slice":-2}})
5.查看所有人前面两个爱好
db.user.find({},{'_id':0,'name':1,'hobbies':{"$slice":2}})
6.查看所有人中间的第2个到第3个爱好
db.user.find({},{"_id":0,"name":1,'hobbies':{"$slice":[1,2]}})
排序
MySQL:
关键字 order by
升序 降序 asc desc
MongoDB
关键字 sort
升序 降序 1 -1
排序:1代表升序,-1代表降序
# select * from db.user order by age asc;
db.user.find().sort({"age":1})
# select * from db.user order by age desc,_id asc
db.user.find().sort({"age":-1,'_id':1})
分页(用来限制查询的条数)
MySQL
关键字 limit
分页 5,5
MongoDB
关键字 limit
分页 skip
分页:limit代表去取多少个document,skip代表跳过前多少个document
# select * from db.user limit 2,1
db.user.find().sort({'age':1}).limit(1).skip(2)
补充知识
获取数量
db.user.count({'age':{"$gt":30}})
--或者
db.user.find({'age':{"$gt":30}}).count()
{'key':null} 匹配key的值为null或者没有这个key的数据
db.t2.insert({'a':10,'b':111})
db.t2.insert({'a':20})
db.t2.insert({'b':null})
> db.t2.find({"b":null})
{ "_id" : ObjectId("5a5cc2a7c1b4645aad959e5a"), "a" : 20 }
{ "_id" : ObjectId("5a5cc2a8c1b4645aad959e5b"), "b" : null }
查找所有
db.user.find() #等同于db.user.find({})
查找一个,与find用法一致,只是只取匹配成功的第一个
db.user.findOne({"_id":{"$gt":3}})
数据准备2
from pymongo import MongoClient import datetime client=MongoClient('mongodb://root:123@localhost:27017') table=client['db1']['emp'] # table.drop() l=[ ('jason','male',18,'20170301','老男孩驻沙河办事处外交大使',7300.33,401,1), #以下是教学部 ('ax','male',78,'20150302','teacher',1000000.31,401,1), ('wxx','male',81,'20130305','teacher',8300,401,1), ('yh','male',73,'20140701','teacher',3500,401,1), ('lz','male',28,'20121101','teacher',2100,401,1), ('jly','female',18,'20110211','teacher',9000,401,1), ('jx','male',18,'19000301','teacher',30000,401,1), ('成龙','male',48,'20101111','teacher',10000,401,1), ('歪歪','female',48,'20150311','sale',3000.13,402,2),#以下是销售部门 ('丫丫','female',38,'20101101','sale',2000.35,402,2), ('丁丁','female',18,'20110312','sale',1000.37,402,2), ('星星','female',18,'20160513','sale',3000.29,402,2), ('格格','female',28,'20170127','sale',4000.33,402,2), ('张野','male',28,'20160311','operation',10000.13,403,3), #以下是运营部门 ('程咬金','male',18,'19970312','operation',20000,403,3), ('程咬银','female',18,'20130311','operation',19000,403,3), ('程咬铜','male',18,'20150411','operation',18000,403,3), ('程咬铁','female',18,'20140512','operation',17000,403,3) ] for n,item in enumerate(l): d={ "_id":n, 'name':item[0], 'sex':item[1], 'age':item[2], 'hire_date':datetime.datetime.strptime(item[3],'%Y%m%d'), 'post':item[4], 'salary':item[5] } table.save(d)
分组查询
按照部门分组
db.emp.aggregate({'$group':{'_id':'$post'}})
按照年龄分组
db.emp.aggregate({'$group':{'_id':'$age'}})
求每个部门的平均年龄
db.emp.aggregate({ '$group':{ '_id':'$post', '平均年龄':{'$avg':'$age'} } })
求每个部门的最高薪资与最低薪资
db.emp.aggregate({ '$group':{ '_id':'$post', '最高薪资':{'$max':'$salary'}, '最低薪资':{'$min':'$salary'} } })
查询岗位名以及各岗位的员工姓名
# SQL语句:select post,group_concat(name) from emp group by post;
db.emp.aggregate({
"$group":{"_id":"$post","names":{"$push":"$name"}}
})
# 6.select * from db1.emp where id > 3 group by post;
db.emp.aggregate(
{"$match":{"_id":{"$gt":3}}}, # 分组之前筛选数据
{"$group":{"_id":"$post"}}
)
# 7.select * from db1.emp where id > 3 group by post having avg(salary) > 10000;
db.emp.aggregate(
{"$match":{"_id":{"$gt":3}}}, # 出现在$group上面就是where
{"$group":{"_id":"$post",'avg_salary':{"$avg":"$salary"}}},
{"$match":{"avg_salary":{"$gt":10000}}} # 出现在$group下面就是having
)
课堂练习
尽量先写SQL再写NoSQL
1. 查询岗位名以及各岗位内的员工姓名
2. 查询岗位名以及各岗位内包含的员工个数
3. 查询公司内男员工和女员工的个数
4. 查询岗位名以及各岗位的平均薪资、最高薪资、最低薪资
5. 查询男员工与男员工的平均薪资,女员工与女员工的平均薪资
6. 查询各岗位内包含的员工个数小于2的岗位名、岗位内包含员工名字、个数
7. 查询各岗位平均薪资大于10000的岗位名、平均工资
8. 查询各岗位平均薪资大于10000且小于20000的岗位名、平均工资
9. 查询所有员工信息,先按照age升序排序,如果age相同则按照hire_date降序排序
10. 查询各岗位平均薪资大于10000的岗位名、平均工资,结果按平均薪资升序排列
11. 查询各岗位平均薪资大于10000的岗位名、平均工资,结果按平均薪资降序排列,取前1个
# 如果你是看了答案的 那么请写出SQL语句

 浙公网安备 33010602011771号
浙公网安备 33010602011771号