结合中断上下文切换和进程上下文切换分析Linux内核的一般执行过程
作业要求:结合中断上下文切换和进程上下文切换分析Linux内核一般执行过程
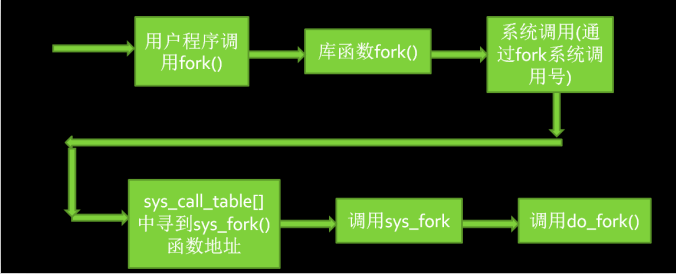
- 以fork和execve系统调用为例分析中断上下文的切换
- 分析execve系统调用中断上下文的特殊之处
- 分析fork子进程启动执行时进程上下文的特殊之处
- 以系统调用作为特殊的中断,结合中断上下文切换和进程上下文切换分析Linux系统的一般执行过程
Linux 是一个多任务操作系统,它支持远大于 CPU 数量的任务同时运行。当然,这些任务实际上并不是真的在同时运行,而是因为系统在很短的时间内,将 CPU 轮流分配给它们,造成多任务同时运行的错觉。而在每个任务运行前,CPU 都需要知道任务从哪里加载、又从哪里开始运行,也就是说,需要系统事先帮它设置好CPU 寄存器和程序计数器。CPU 寄存器和程序计数器就是 CPU 上下文,因为它们都是 CPU 在运行任何任务前,必须的依赖环境。
一、CPU 上下文切换
CPU 上下文切换就是先把前一个任务的 CPU 上下文(也就是 CPU 寄存器和程序计数器)保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务。
而这些保存下来的上下文,会存储在系统内核中,并在任务重新调度执行时再次加载进来。这样就能保证任务原来的状态不受影响,让任务看起来还是连续运行。
CPU 上下文切换根据任务的不同,可以分为以下三种类型 : 进程上下文切换 - 线程上下文切换 - 中断上下文切换
程序在执行过程中通常有用户态和内核态两种状态,CPU对处于内核态根据上下文环境进一步细分,因此有了下面三种状态:
(1)内核态,运行于进程上下文,内核代表进程运行于内核空间。
(2)内核态,运行于中断上下文,内核代表硬件运行于内核空间。
(3)用户态,运行于用户空间
1.1 进程上下文切换
Linux按照特权等级,把进程的运行空间分为内核空间和用户空间,分别对应着下图中,CPU特权等级的Ring 0 和Ring 3
- 内核空间(Ring 0)具有最高权限,可以直接访问所有资源
- 用户空间(Ring 3) 只能访问受限资源,不能直接访问内存等硬件设备,必须通过系统调用陷入到内核中,才能访问这些特权资源
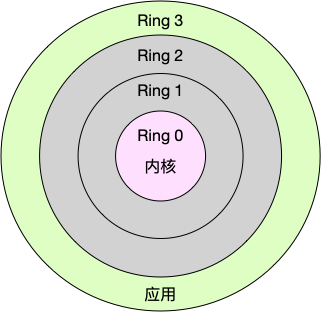
换个角度看,也就是说,进程既可以在用户空间运行,又可以在内核空间运行(从用户态到内核态的转变,需要通过系统调用来完成,系统调用实质上是一种特殊的中断,由用户程序触发,之前提到的中断是由硬件触发)。进程在用户空间运行时,被称为进程的用户态,而陷入内核空间的时候,被称为进程的内核态。
主要注意的是:
- 进程上下文切换,是指从一个进程切换到另一个进程运行
- 而系统调用过程中一直是同一个进程在运行
系统调用过程通常称为特权模式切换,而不是上下文切换。当进程调用系统调用或者发生中断时,CPU从用户模式(用户态)切换成内核模式(内核态),此时,无论是系统调用程序还是中断服务程序,都处于当前进程的上下文中,并没有发生进程上下文切换。当系统调用或中断处理程序返回时,CPU要从内核模式切换回用户模式,此时会执行操作系统的调用程序。如果发现就需队列中有比当前进程更高的优先级的进程,则会发生进程切换:当前进程信息被保存,切换到就绪队列中的那个高优先级进程;否则,直接返回当前进程的用户模式,不会发生上下文切换。

进程的上下文不仅包括了虚拟内存、栈、全局变量等用户空间的资源,还包括了内核堆栈、寄存器等内核空间的状态。因此进程的上下文切换就比系统调用时多了一步:在保存当前进程的内核状态和CPU寄存器之前,需要先把该进程的虚拟内存、栈等保存下来;而加载下一进程的内核态后,还需要刷新进程的虚拟内存和用户栈。模式切换与进程切换比较起来,容易很多,而且节省时间,因为模式切换最主要的任务只是切换进程寄存器上下文的切换。
1.2 中断上下文切换
为了快速响应硬件的事件,中断处理会打断进程的正常调度和执行,转而调用中断处理程序,响应设备事件。而在打断其他进程时,就需要将进程当前的状态保存下来,这样在中断结束后,进程仍然可以从原来的状态恢复运行
跟进程上下文不同,中断上下文切换并不涉及到进程的用户态。所以,即便中断过程打断了一个正处于用户态的进程,也不需要保存和恢复这个进程的虚拟内存、全局变量等用户态资源。中断上下文,其实只包括内核态中断服务程序执行所必需的状态,包括CPU寄存器、内核堆栈、硬件中断参数等。
对同一个CPU来说,中断处理比进程拥有更高的优先级,所以中断上下文切换并不会与进程上下文切换同时发生。同样道理,由于中断会打断正常进程的调度和执行,所以大部分中断处理程序都短小精悍,以便尽可能快的执行结束。
1.3 线程上下文切换
线程与进程最大的区别在于,线程是调度的基本单位,而进程则是资源拥有的基本单位。说白了,所谓内核中的任务调度,实际上的调度对象是线程;而进程只是给线程提供了虚拟内存、全局变量等资源。
线程的上下文切换其实就可以分为两种情况:
- 第一种:前后两个线程属于不同进程。此时,因为资源不共享,所以切换过程就跟进程上下文切换是一样
- 第二种:前后两个线程属于同一个进程。此时,因为虚拟内存是共享的,所以在切换时,虚拟内存这些资源就保持不动,只需要切换线程的私有数据、寄存器等不共享的数据。
到这里你应该也发现了,虽然同为上下文切换,但同进程内的线程切换,要比多进程间的切换消耗更少的资源,而这,也正是多线程代替多进程的一个优势。
二、中断上下文的切换的一般流程(以系统调用为例)
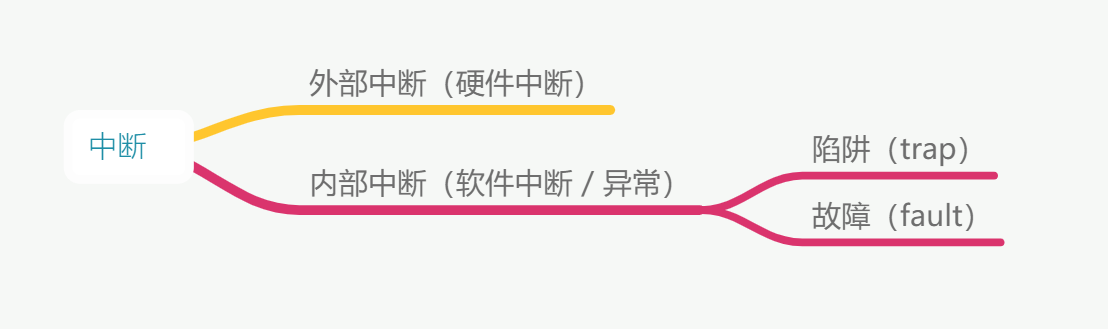
中断分外部中断(硬件中断)和内部中断(软件中断),内部中断又称为异常(Exception),异常又分为故障(fault)和陷阱(trap)。 系统调用就是利用陷阱(trap)这种软件中断方式主动从用户态进入内核态的。
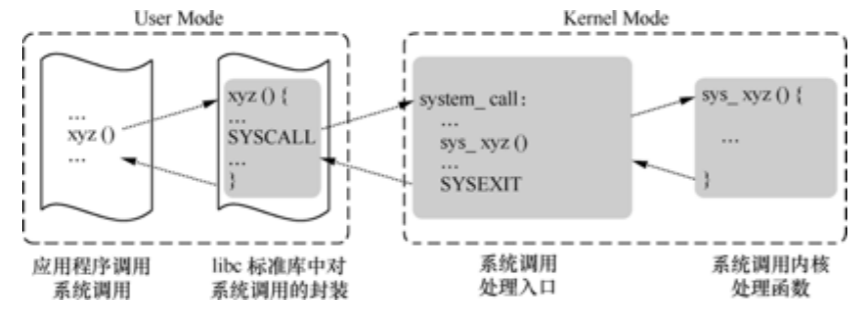
系统调用层次:用户程序------>C库(即API):INT 0x80 ----->system_call------->系统调用服务例程-------->内核程序
- 应用程序代码调用 xyz(),该函数是一个包装系统调用的库函数;
- 库函数 xyz() 负责准备向内核传递的参数,并触发软中断以切换到内核;
- CPU 被软中断打断后,执行中断处理函数,即系统调用处理函数(system_call);
- 系统调用处理函数调用系统调用服务例程(sys_xyz ),真正开始处理该系统调用。
在Linux中通过执行int $0x80或syscall指令来触发系统调用的执行,其中这条int $0x80汇编指令是产生中断向量为128的编程异常(trap)。
当用户态进程调用一个系统调用时,CPU切换到内核态并开始执行 system_call(entry_INT80_32或entry_SYSCALL_64)汇编代码,其 中根据系统调用号调用对应的内核处理函数。
内核实现了很多不同的系统调用,用户态进程 必须指明需要执行哪个系统调用,这需要使用EAX寄存器传递一个名 为系统调用号的参数。除了系统调用号外,系统调用也可能需要传递 参数。在32位x86体系结构下普通的函数调用是通过将参数压栈的方式传递的。
系统调用从用户 态切换到内核态,在用户态和内核态这两种执行模式下使用的是不同的堆栈,即进程的用户态堆栈和进程的内核态堆栈,传递参数方法无法通过参数压栈的方式,而是通过寄存器 传递参数的方式。寄存器传递参数的个数是有限制的,而且每个参数的长度不能超过寄存 器的长度,32位x86体系结构下寄存器的长度最大32位。除了EAX用于传递系统调用号 外,参数按顺序赋值给EBX、ECX、EDX、ESI、EDI、EBP,参数的个数不能超过6个, 即上述6个寄存器。如果超过6个就把某一个寄存器作为指针,指向内存,就可以通过内 存来传递更多的参数。
触发系统调用后的大致流程:
正在运行的用户态进程X
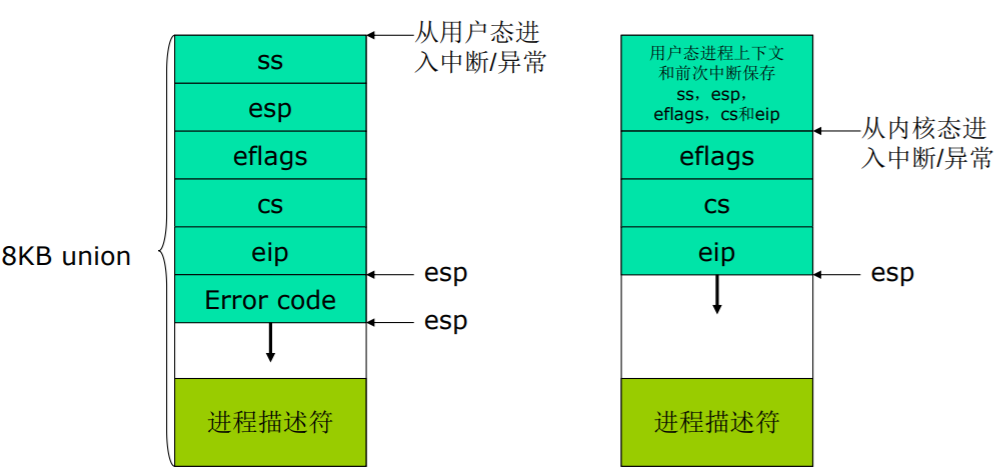
发生中断(包括异常、系统调用等),CPU完成以下动作
- save cs:eip/ss:esp/eflags:当前CPU上下文压入进程X的内核堆栈
- load cs:eip(entry of a specific ISR) and ss:esp(point to kernel stack):加载当前进程内核堆栈相关信息,跳转到中断处理程序,即中断执行路径的起点
SAVE_ALL,保存现场,此时完成了中断上下文切换,即从进程X的用户态到进程X的内核态
中断处理过程中或中断返回前调用了schedule函数,其中的switch_to做了关键的进程上下文切换。将当前进程X的内核堆栈切换到进程调度算法选出来的next进程 (本例假定为进程Y)的内核堆栈,并完成了进程上下文所需的EIP等寄存器状态切换。详细过程见前述内容
标号1,即前述3.18.6内核的swtich_to代码第50行“”1:\t“ ”(地址为switch_to中的“$1f”),之后开始运行进程Y(这里进程Y曾经通过以上步骤被切换出去,因此可以 从标号1继续执行)
restore_all,恢复现场,与(3)中保存现场相对应。注意这⾥是进程Y的中断处理过程中,而(3)中保存现场是在进程X的中断处理过程中,因为内核堆栈从进程X 切换到进程Y了
iret - pop cs:eip/ss:esp/eflags,从Y进程的内核堆栈中弹出(2)中硬件完成的压栈内容。此时完成了中断上下文的切换,即从进程Y的内核态返回到进程Y的用户态
继续运行用户态进程Y
中断进入详细过程:
确定与中断或者异常关联的向量i(0~255)
读idtr寄存器指向的IDT表中的第i项 3,从gdtr寄存器获得GDT的基地址,并在GDT中查找, 以读取IDT表项中的段选择符所标识的段描述符
从gdtr寄存器获得GDT的基地址,并在GDT中查找, 以读取IDT表项中的段选择符所标识的段描述符
确定中断是由授权的发生源发出的
检查是否发生了特权级的变化,一般指是否由 用户态陷入了内核态。
如果是由用户态陷入了内核态,控制单元必须开 始使用与新的特权级相关的堆栈
- 读tr寄存器,访问运行进程的tss段
- 用与新特权级相关的栈段和栈指针装载ss和esp寄存器。这些值可以在进程的tss段中找到
- 在新的栈中保存ss和esp以前的值,这些值指明了与 旧特权级相关的栈的逻辑地址
若发生的是故障,用引起异常的指令地址修改cs 和eip寄存器的值,以使得这条指令在异常处理结 束后能被再次执行
在栈中保存eflags、cs和eip的内容
如果异常产生一个硬件出错码,则将它保存在栈 中
装载cs和eip寄存器,其值分别是IDT表中第i项门 描述符的段选择符和偏移量字段。这对寄存器值 给出中断或者异常处理程序的第一条指定的逻辑 地址
中断返回详细过程:中断/异常处理完后,相应的处理程序会 执行一条iret汇编指令,这条汇编指令让 CPU控制单元做如下事情:
用保存在栈中的值装载cs、eip和eflags寄存器。如果一个硬件出错码曾被压入栈中, 那么弹出这个硬件出错码
检查处理程序的特权级是否等于cs中最低 两位的值(这意味着进程在被中断的时候是 运行在内核态还是用户态)。若是,iret终止 执行;否则,转入3
从栈中装载ss和esp寄存器。这步意味着返 回到与旧特权级相关的栈
检查ds、es、fs和gs段寄存器的内容,如 果其中一个寄存器包含的选择符是一个段描 述符,并且特权级比当前特权级高,则清除 相应的寄存器。这么做是防止怀有恶意的用 户程序利用这些寄存器访问内核空间
三、fork子进程启动执行时进程上下文的特殊之处
首先看一段程序及其执行的结果来了解fork函数的作用:
#include <unistd.h>
#include <stdio.h>
int main()
{
int pid = fork();
if (pid == -1)
return -1;
if (pid)
{
printf("I am father, my pid is %d\n", getpid());
return 0;
}
else
{
printf("I am child, my pid is %d\n", getpid());
return 0;
}
}
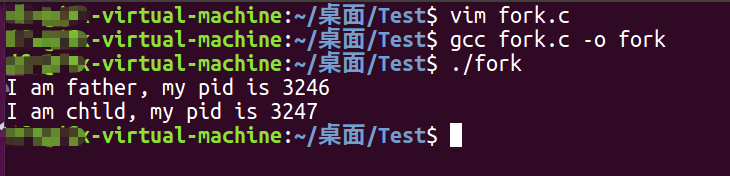
看到这个结果是不是很奇怪,为什么if的分支执行到了,else的分支也执行到了。这明显不符合程序执行最基本的原理。这个放到后面再来解释,先来了解一下fork这个函数:
pid_t fork();上面是fork函数的原型,它有三个返回值
- 该进程为父进程时,返回子进程的pid
- 该进程为子进程时,返回0
- fork执行失败,返回-1
fork的作用是克隆进程,也就是将原先的一个进程再克隆出一个来,克隆出的这个进程就是原进程的子进程,这个子进程和其他的进程没有什么区别,同样拥有自己的独立的地址空间。不同的是子进程是在fork返回之后才开始执行的,就像一把叉子一样,执行fork之后,父子进程就分道扬镳了,所以fork这个名字就很形象,叉子的意思。fork给父进程返回子进程pid,给其拷贝出来的子进程返回0,这也是他的特点之一,一次调用,两次返回,所以与一般的系统调用处理流程也必定不同。
Linux下用于创建进程的API有三个fork,vfork和clone,这三个函数分别是通过系统调用sys_fork,sys_vfork以及sys_clone实现的(目前讨论的都是基于x86架构的)。而且这三个系统调用,都是通过do_fork来实现的,只是传入了不同的参数。所以我们可以得出结论:所有的子进程是在do_fork实现创建和调用的。下面我们就来整理一下整个进程的在用户态到内核态的过程是怎么样的。fork系统调用如下:
do_fork的代码如下(linux3.18.6):
long do_fork(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr)
{
struct task_struct *p;
int trace = 0;
long nr;
/*
* Determine whether and which event to report to ptracer. When
* called from kernel_thread or CLONE_UNTRACED is explicitly
* requested, no event is reported; otherwise, report if the event
* for the type of forking is enabled.
*/
if (!(clone_flags & CLONE_UNTRACED)) {
if (clone_flags & CLONE_VFORK)
trace = PTRACE_EVENT_VFORK;
else if ((clone_flags & CSIGNAL) != SIGCHLD)
trace = PTRACE_EVENT_CLONE;
else
trace = PTRACE_EVENT_FORK;
if (likely(!ptrace_event_enabled(current, trace)))
trace = 0;
}
p = copy_process(clone_flags, stack_start, stack_size,
child_tidptr, NULL, trace);
/*
* Do this prior waking up the new thread - the thread pointer
* might get invalid after that point, if the thread exits quickly.
*/
if (!IS_ERR(p)) {
struct completion vfork;
struct pid *pid;
trace_sched_process_fork(current, p);
pid = get_task_pid(p, PIDTYPE_PID);
nr = pid_vnr(pid);
if (clone_flags & CLONE_PARENT_SETTID)
put_user(nr, parent_tidptr);
if (clone_flags & CLONE_VFORK) {
p->vfork_done = &vfork;
init_completion(&vfork);
get_task_struct(p);
}
wake_up_new_task(p);
/* forking complete and child started to run, tell ptracer */
if (unlikely(trace))
ptrace_event_pid(trace, pid);
if (clone_flags & CLONE_VFORK) {
if (!wait_for_vfork_done(p, &vfork))
ptrace_event_pid(PTRACE_EVENT_VFORK_DONE, pid);
}
put_pid(pid);
} else {
nr = PTR_ERR(p);
}
return nr;
}
整个创建新进程是由copy_process()这个函数实现的,copy_process()做的主要工作如下:
1. 复制一个PCB——task_struct
p = dup_task_struct(current);
复制当前进程的PCB描述符task_struct。我们在进入到该函数dup_task_struct体内就可以看到这个pcb是如何复制的。主要的赋值函数是
err = arch_dup_task_struct(tsk, orig); //赋值操作
...
tsk = alloc_task_struct_node(node);
ti = alloc_thread_info_node(tsk, node);
tsk->stack = ti;
setup_thread_stack(tsk, orig); //这里只是复制thread_info,而非复制内核堆栈
然而我们再 往dup_task_struct(current)函数往下看,后面是大量的修改进程的内容,也就是对复制过来的东西修改为子进程所拥有的数据。也就是初始化一个子进程,在copy_process()函数有一个非常重要的函数copy_thread,部分代码如下:
struct pt_regs *childregs = task_pt_regs(p);
struct task_struct *tsk;
int err;
p->thread.sp = (unsigned long) childregs;
p->thread.sp0 = (unsigned long) (childregs+1);
memset(p->thread.ptrace_bps, 0, sizeof(p->thread.ptrace_bps));
if (unlikely(p->flags & PF_KTHREAD)) {
/* kernel thread */
memset(childregs, 0, sizeof(struct pt_regs));
p->thread.ip = (unsigned long) ret_from_kernel_thread;
task_user_gs(p) = __KERNEL_STACK_CANARY;
childregs->ds = __USER_DS;
childregs->es = __USER_DS;
childregs->fs = __KERNEL_PERCPU;
childregs->bx = sp; /* function */
childregs->bp = arg;
childregs->orig_ax = -1;
childregs->cs = __KERNEL_CS | get_kernel_rpl();
childregs->flags = X86_EFLAGS_IF | X86_EFLAGS_FIXED;
p->thread.io_bitmap_ptr = NULL;
return 0;
}
*childregs = *current_pt_regs(); //拷贝父进程的内核堆栈栈底,也就是已有的内核堆栈数据的拷贝
childregs->ax = 0; //给eax赋值为0,因为子进程返回的是0,系统调用是通过eax返回的,
if (sp)
childregs->sp = sp; //修改栈顶
p->thread.ip = (unsigned long) ret_from_fork; //给ip赋值,这就是子进程执行的起点
从用户态的代码看fork();函数返回了两次,即在父子进程中各返回一次,父进程从系统调用中返回比较容易理解,子进程从系统调用中返回,那它在系统调用处理过程中的哪里开始执行的呢?这就涉及子进程的内核堆栈数据状态和task_struct中thread记录的sp和ip的一致性问题,这是在哪里设定的?copy_thread in copy_process
struct pt_regs *childregs = task_pt_regs(p);
*childregs = *current_pt_regs(); //复制内核堆栈栈底
childregs->ax = 0; //为什么子进程的fork返回0,这里就是原因!
p->thread.sp = (unsigned long) childregs; //调度到子进程时的内核栈顶
p->thread.ip = (unsigned long) ret_from_fork; //调度到子进程时的第一条指令地址
上面赋值复制的内核堆栈并不是父进程的所有内核堆栈的内容,那复制的是哪些部分呢?我们可以看上面代码的第一句,其中复制的内容就是pt_regs里面的内容。里面的代码如下:
struct pt_regs {
long ebx;
long ecx;
long edx;
long esi;
long edi;
long ebp;
long eax;
int xds;
int xes;
int xfs;
int xgs;
long orig_eax;
long eip;
int xcs;
long eflags;
long esp;
int xss;
};
父进程堆栈复制给子进程的就是上面那些参数。从copy_thread中我们就已经得出堆栈复制和子进程开始执行的起始地方。总结一下:linux创建一个新的进程是从复制开始的,在系统内核里首先是将父进程的进程控制块PCB进行拷贝,然后再根据自己的情况修改相应的参数,获取自己的进程号,再开始执行。内核中主要通过do_fork()实现,复制进程主要是靠copy_process()完成的,整个过程实现如下:
p = dup_task_struct(current);为新进程创建一个内核栈、thread_iofo和task_struct,这里完全copy父进程的内容,所以到目前为止,父进程和子进程是没有任何区别的- 为新进程在其内存上建立内核堆栈
- 对子进程task_struct任务结构体中部分变量进行初始化设置,检查所有的进程数目是否已经超出了系统规定的最大进程数,如果没有的话,那么就开始设置进程描诉符中的初始值,从这开始,父进程和子进程就开始区别开了。
- 父进程的有关信息复制给子进程,建立共享关系
- 设置子进程的状态为不可被TASK_UNINTERRUPTIBLE,从而保证这个进程现在不能被投入运行,因为还有很多的标志位、数据等没有被设置
- 复制标志位(falgs成员)以及权限位(PE_SUPERPRIV)和其他的一些标志
- 调用get_pid()给子进程获取一个有效的并且是唯一的进程标识符PID
return ret_from_fork;返回一个指向子进程的指针,开始执行
总结来说,进程的创建过程大致是父进程通过fork系统调用进入内核_ do_fork函数,如下图所示复制进程描述符及相关进程资源(采用写时复制技术)、分配子进程的內核堆栈并对內核堆栈和 thread等进程关键上下文进行初始化,最后将子进程放入就绪队列,fork系统调用返回;而子进程则在被调度执行时根据设置的內核堆栈和thread等进程关键上下文开始执行。

四、execve系统调用中断上下文的特殊之处
首先看两段程序及其执行的结果来了解execve函数的作用:
/* execve.c */
#include <unistd.h>
#include <stdlib.h>
char *buf [] = {"/bin/sh", NULL};
void main(){
execve("/bin/sh", buf, 0);
exit(0);
}
/* execve2.c */
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main(int argc, char * argv[])
{
int pid;
/* fork another process */
pid = fork();
if (pid < 0)
{
/* error occurred */
fprintf(stderr, "Fork Failed!");
exit(-1);
}
else if (pid == 0)
{
/* child process */
execlp("/bin/ls", "ls", NULL);
}
else
{
/* parent process */
/* parent will wait for the child to complete*/
wait(NULL);
printf("Child Complete!\n");
exit(0);
}
}

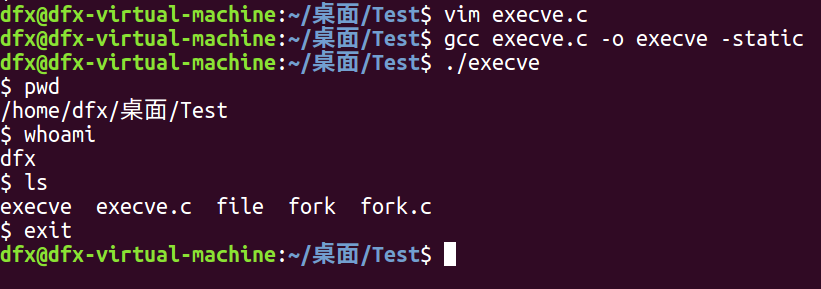
execve2.c简化了的Shell程 序执行ls命令的过程。首先fork一个子进程,pid为0的分支是将来的子进程要执行的,在子进程里调用 execlp来加载可执行程序ls。子进程通过execlp加载可执行程序时按如图所示的结构重新布局用户态堆栈,可以看到用户态堆栈的栈顶就是main函数调用堆栈框架,这就是程序的main函数起点的执行环境。
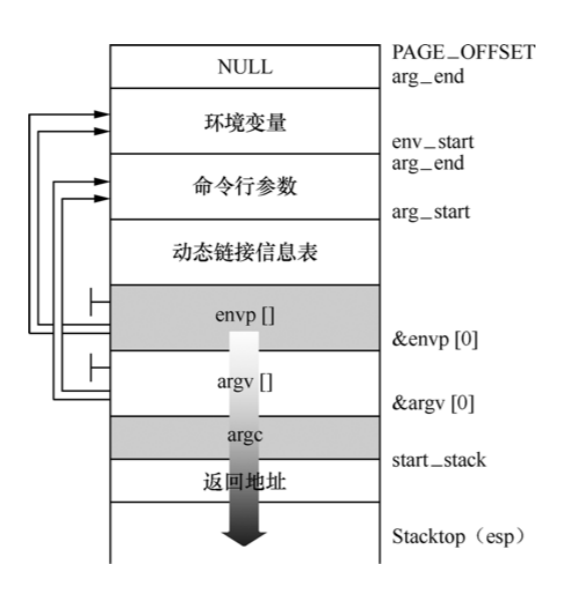
在布局一个新的用户态堆栈时,实际上是把命令行参数内容和环境变量的内容通过指针的方式传到系统调用内核处理函数,再创建一个新的用户态堆栈时会把这些char *argcv[]和char *envp[]等复制到用户态堆栈中,来初始化这个新的可执行程序的执行上下文环境。所以新 的程序可以从main函数开始把对应的参数接收过来,然后执行
在调用execve系统调用时,当前的执行环境是从父进程复制过来的, execve系统调用加载完新的可执行程序之后已经覆盖了原来父进程的上下文环境。execve 系统调用在内核中帮我们重新布局了新的用户态执行环境。
正常的一个系统调用都是陷入内核态,再返回到用户态,然后继续执行系统调用后的下一条指令。上文讲到,fork和其他系统调用不同之处是它在陷入内核态之后有两次返回,第一次返回到原来的父进程的位 置继续向下执行,这和其他的系统调用是一样的。在子进程中fork也返回了一次,会返回到一个特定的点——ret_from_fork,通过内核构造的堆栈环境,它可以正常系统调用返回到用户态,所以它 稍微特殊一点。同样,execve也比较特殊。当前的可执行程序在执行,执行到execve系统调用时陷入内核态,在内核里面用do_execve加载可执行文件,把当前进程的可执行程序给覆盖掉。当execve系统调用返回时,返回的已经不是原来的那个可执行程序了,而是新的可执行程序。execve返回的是新的可执行程序执行的起点,静态链接的可执行文件也就是main函数的大致位置,动态链接的可执行文件还需 要ld链接好动态链接库再从main函数开始执行。
Linux系统一般会提供了execl、execlp、execle、execv、execvp和execve等6个用以加载执行 一个可执行文件的库函数,这些库函数统称为exec函数,差异在于对命令行参数和环境变量参数 的传递方式不同。exec函数都是通过execve系统调用进入内核,对应的系统调用内核处理函数为 sys_execve或__x64_sys_execve,它们都是通过调用do_execve来具体执行加载可执行文件的 ⼯作。
整体的调用关系为sys_execve() / x64_sys_execve ==> do_execve() ==> do_execveat_common() ==> do_execve_file ==> exec_binprm() ==> search_binary_handler() ==> load_elf_binary() ==> start_thread()。
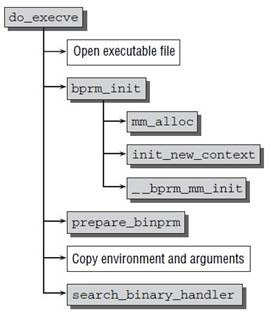
execve执行后具体处理过程:
检查看可执行文件的类型:当进入
execve()系统调用之后,Linux 内核就开始进行真正的装载工作。在内核中,execve()系统调用相应的入口是sys_execve()。sys_execve()进行一些参数的检查复制之后,调用do_execve()。do_execve()会首先查找被执行的文件,如果找到文件,则读取文件的前 128 个字节。
为什么要先读取文件的前 128 个字节?这是因为Linux支持的可执行文件不止 ELF 一种,还包括 a.out、Java 程序、以#!开头的脚本程序。do_execve()通过读取前 128 个字节来判断文件的格式。每种可执行文件格式的开头几个字节都是很特殊的,尤其是前4个字节,被称为 魔数(Magic Number)。搜索匹配装载处理过程:当
do_execve()读取了128个字节的文件头部之后,调用search_binary_handle()去搜索和匹配合适的可执行文件装载处理过程。Linux 中所有被支持的可执行文件格式都有相应的装载处理过程,search_binary_handler()会通过判断头部的魔术确定文件的格式,并且调用相应的装载处理过程。常见的可执行程序及其装载处理过程的对应关系如下所示.
- ELF 可执行文件:
load_elf_binary()- a.out 可执行文件:
load_aout_binary()- 可执行脚本程序:
load_script()装载执行可执行文件
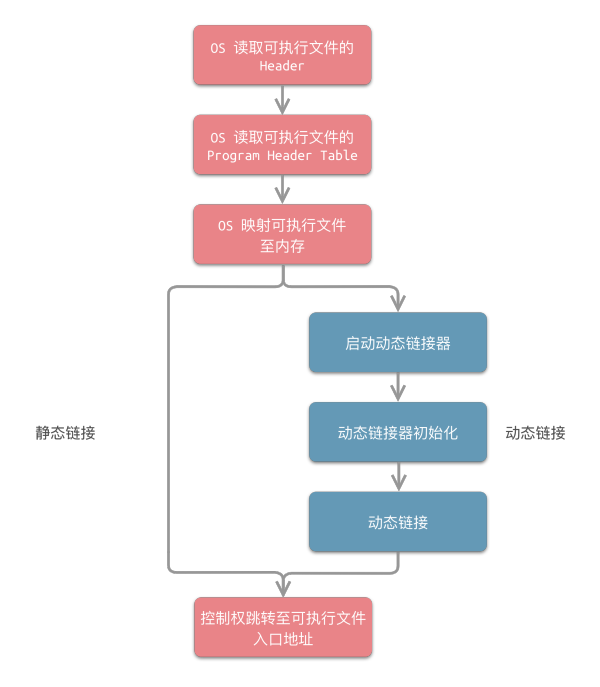
以 ELF 的装载处理过程load_elf_binary()为例,其所包含的步骤如下图所示:
- 操作系统读取可执行文件 ELF 的
Header,检查文件的有效性。- 操作系统读取可执行文件 ELF的
Program Header Table中读取每个Segment的虚拟地址、文件地址、属性等。- 操作系统根据
Program Header Table将可执行文件 ELF 映射至内存。- 如果是静态链接的情况,则直接跳转至第 7 步;如果是动态链接的情况,操作系统将查找
.interp节,找到 动态链接器(Dynamic Linker) 的位置,并启动动态链接器。在 Linux 下,动态链接器ld.so是一个共享对象,操作系统同样通过映射的方式将它加载到进程的地址空间。操作系统在加载完后,将控制权交给动态链接器的入口。- 动态链接器获得控制权后,开始执行一系列初始化操作。
- 动态链接器根据当前的环境参数,对可执行文件进行动态链接工作。
- 控制权被转交到可执行文件的入口地址,程序开始正式执行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号