0219 请求上下文解析与g对象
请求上下文解析
简介
请求上下文
在flask 0.9版本之前,flask中只有“请求上下文”的概念。那什么是请求上下文呢?
我们先回忆一下在写flask程序的时候,经常会碰到直接调用像current_app、request、session、g等变量。这些变量看起来似乎是全局变量,但是实质上这些变量并不是真正意义上的全局变量。如果将这些变量设置为全局变量,试想一下,多个线程同时请求程序访问这些变量时势必会相互影响。但是如果不设置为全局变量,那在编写代码时每次都要显式地传递这些变量也是一件非常令人头疼的事情,而且还容易出错。
为了解决这些问题,flask设计时采取线程隔离的思路,也就是说在一次请求的一个线程中可以将其设置为全局变量,但是仅限于请求的这个线程内部,不同线程通过“线程标识符”来区别。这样就不会影响到其他线程的请求。flask实现线程隔离主要是使用werkzeug中的两个类:Local和LocalProxy,这里不再赘述,可以去看看werkzeug的源码了解一下实现过程。
实现线程隔离后,为了在一个线程中更加方便使用这些变量,flask中还有一种堆栈的数据结构(通过werkzeug的LocalStack实现),可以处理这些变量,但是并不直接处理这些变量。假如有一个程序得到一个请求,那么flask会将这个请求的所有相关信息进行打包,打包形成的东西就是处理请求的一个环境。flask将这种环境称为“请求上下文”(request context),之后flask会将这个请求上下文对象放到堆栈中。
这样,请求发生时,我们一般都会指向堆栈中的“请求上下文”对象,这样可以通过请求上下文获取相关对象并直接访问,例如current_app、request、session、g。还可以通过调用对象的方法或者属性获取其他信息,例如request.method。等请求结束后,请求上下文会被销毁,堆栈重新等待新的请求上下文对象被放入。
应用上下文
应用上下文的概念是在flask 0.9中增加的。
既然flask通过线程隔离的方式,将一些变量设置为线程内的“全局”可用。由于请求上下文中包含有当前应用相关的信息,那也就是说可以通过调用current_app就可以获取请求所在的正确应用而不会导致混淆。那为什么需要增加一个应用上下文的概念呢?
对于单应用单请求来说,使用“请求上下文”确实就可以了。然而,Flask的设计理念之一就是多应用的支持。当在一个应用的请求上下文环境中,需要嵌套处理另一个应用的相关操作时(这种情况更多的是用于测试或者在console中对多个应用进行相关处理),“请求上下文”显然就不能很好地解决问题了,因为魔法current_app无法确定当前处理的到底是哪个应用。如何让请求找到“正确”的应用呢?我们可能会想到,可以再增加一个请求上下文环境,并将其推入栈中。由于两个上下文环境的运行是独立的,不会相互干扰,所以通过调用栈顶对象的app属性或者调用current_app(current_app一直指向栈顶的对象)也可以获得当前上下文环境正在处理哪个应用。这种办法在一定程度上可行,但是如果说对第二个应用的处理不涉及到相关请求,那也就无从谈起“请求上下文”,更不可能建立请求上下文环境了。
为了应对这个问题,Flask中将应用相关的信息单独拿出来,形成一个“应用上下文”对象。这个对象可以和“请求上下文”一起使用,也可以单独拿出来使用。不过有一点需要注意的是:在创建“请求上下文”时一定要创建一个“应用上下文”对象。有了“应用上下文”对象,便可以很容易地确定当前处理哪个应用,这就是魔法current_app。在0.1版本中,current_app是对_request_ctx_stack.top.app的引用,而在0.9版本中current_app是对_app_ctx_stack.top.app的引用。其中_request_ctx_stack和_app_ctx_stack分别是存储请求上下文和应用上下文的栈。
这里举一个多应用的例子:
假设有两个Flask应用:app1和app2。我们假定一种情形:在请求访问app1时,先要对app2进行一些操作,之后再处理app1内的请求。以下是一些分析过程:
- 请求访问app1时,app1会生成一个请求上下文对象,并且使用with语句产生一个请求上下文环境。请求处理的所有过程都会在这个上下文环境中进行。当进入这个上下文环境时,Flask会将请求上下文对象推入_request_ctx_stack这个栈中,并且生成一个对应的应用上下文对象,将其推入_app_ctx_stack栈中。_app_ctx_stack栈顶指向的是app1;
- 当在app1的请求上下文环境中需要对app2进行操作时,为了和app1的相关操作隔离开来,可以使用with语句建立一个app2的应用上下文环境。在这个过程中,会新建一个应用上下文对象,并将其推入_app_ctx_stack栈中。_app_ctx_stack栈顶指向的是app2;
- 当退出app2的应用上下文环境,重新进入app1的请求上下文环境时,_app_ctx_stack栈会销毁app2的应用上下文对象,它的栈顶指向的是app1。
通过以上一个假象的例子,我们始终可以使用current_app来表示当前处理的Flask应用。
什么是上下文
上下文 : 相当于一个容器,保存了Flask程序运行过程中的一些信息.在计算机中,相对于进程而言,上下文就是进程执行时的环境.
Flask提供了两种上下文,一种是应用上下文(Application Context),一种是请求上下文(Request Context)。
通俗地解释一下application context与request context:
-
application指的就是当你调用
app = Flask(__name__)创建的这个对象app; -
request 指的是每次http请求发生时,WSGI server(比如gunicorn)调
Flask.__call__()之后,在Flask对象内部创建的Request对象; -
application 表示用于响应WSGI请求的应用本身,request 表示每次http请求;
-
application的生命周期大于request,一个application存活期间,可能发生多次http请求,所以,也就会有多个request
请求上下文(request context )
request,和session都是请求上下文对象
request 封装了HTTP请求的内容,针对的是http请求,request对象只有在上下文的生命周期内才有效,离开了请求的生命周期,其上下文环境就不存在了
也就无法获取request对象了.
session 用来记录请求回话中的信息,针对的用户信息
Flask中有四种请求hook,分别是@before_first_request @before_request @after_request @teardown_request
全局变量
from flask import request
@app.route('/')
def index():
user_agent = request.headers.get('User-Agent')
return '<p>Your browser is %s</p>' % user_agent```
如同上面的代码一样,在每个请求上下文的函数中我们都可以访问request对象,然而request对象却并不是全局的,因为当我们随便声明一个函数的时候,比如:
def handle_request():
print 'handle request'
print request.url
if __name__=='__main__':
handle_request()
此时运行就会产生
RuntimeError: working outside of request context。
因此可知,Flask的request对象只有在其上下文的生命周期内才有效,离开了请求的生命周期,其上下文环境不存在了,也就无法获取request对象了。而上面所说的四种请求hook函数,会挂载在生命周期的不同阶段,因此在其内部都可以访问request对象。
可以使用Flask的内部方法request_context()来构建一个请求上下文
from werkzeug.test import EnvironBuilder
ctx = app.request_context(EnvironBuilder('/','http://localhost/').get_environ())
ctx.push()
try:
print request.url
finally:
ctx.pop()
对于Flask Web应用来说,每个请求就是一个独立的线程。请求之间的信息要完全隔离,避免冲突,这就需要使用到Thread Local。
Thread Local
对象是保存状态的地方,在Python中,一个对象的状态都被保存在对象携带的一个字典中,**Thread Local **则是一种特殊的对象,它的“状态”对线程隔离 —— 也就是说每个线程对一个 Thread Local 对象的修改都不会影响其他线程。这种对象的实现原理也非常简单,只要以线程的 ID 来保存多份状态字典即可,就像按照门牌号隔开的一格一格的信箱。
在Python中获取Thread Local最简单的方式是threading.local()
>>> import threading
>>> storage = threading.local()
>>> storage.foo = 1
>>> print(storage.foo)
1
>>> class AnotherThread(threading.Thread):
... def run(self):
... storage.foo = 2
... print(storage.foo) # 这这个线程里已经修改了
>>>
>>> another = AnotherThread()
>>> another.start()
2
>>> print(storage.foo) # 但是在主线程里并没有修改
1
因此只要有Thread Local对象,就能让同一个对象在多个线程下做到状态隔离。
Flask是一个基于WerkZeug实现的框架,因此Flask的App Context和Request Context是基于WerkZeug的Local Stack的实现。这两种上下文对象类定义在flask.ctx中,ctx.push会将当前的上下文对象压栈压入flask._request_ctx_stack中,这个_request_ctx_stack同样也是个Thread Local对象,也就是在每个线程中都不一样,上下文压入栈后,再次请求的时候都是通过_request_ctx_stack.top在栈的顶端取,所取到的永远是属于自己线程的对象,这样不同线程之间的上下文就做到了隔离。请求结束后,线程退出,ThreadLocal本地变量也随即销毁,然后调用ctx.pop()弹出上下文对象并回收内存。
应用上下文 (application context)
current_app : 表示当前运行程序文件的程序事例,可以通过current_app.name打印当前应用程序实例的名字
g : 处理请求时,用于临时储存的对象,每次请求都会重置
1 当调用app = Flask(name)的时候,创建了程序应用对象
2 request在每次http请求发生时,WSGI server调用Flask.__call++();然后在flask内部创建flask对象
3 app的生命周期大于request和g,一个app存活期间,可能发生多次 http请求,所以会有多个request,g
4 最终传入视图函数,通过return,redirect,和render_template生成response对象,返回给客户端
从一个Flask App读入配置并且启动开始,就进入了App Context,在其中我们可以配置文件,打开资源文 件,通过路由规则反向URL
从一个 Flask App 读入配置并启动开始,就进入了 App Context,在其中我们可以访问配置文件、打开资源文件、通过路由规则反向构造 URL。可以看下面一段代码:
from flask import Flask, current_app
app = Flask('__name__')
@app.route('/')
def index():
return 'Hello, %s!' % current_app.name
current_app是一个本地代理,它的类型是werkzeug.local. LocalProxy,它所代理的即是我们的app对象,也就是说current_app == LocalProxy(app)。使用current_app是因为它也是一个ThreadLocal变量,对它的改动不会影响到其他线程。可以通过current_app._get_current_object()方法来获取app对象。current_app只能在请求线程里存在,因此它的生命周期也是在应用上下文里,离开了应用上下文也就无法使用。
app = Flask('__name__')
print current_app.name
同样会报错:
RuntimeError: working outside of application context
和请求上下文一样,同样可以手动创建应用上下文:
with app.app_context():
print current_app.name
这里的with语句和 with open() as f一样,是Python提供的语法糖,可以为提供上下文环境省略简化一部分工作。这里就简化了其压栈和出栈操作,请求线程创建时,Flask会创建应用上下文对象,并将其压入flask._app_ctx_stack的栈中,然后在线程退出前将其从栈里弹出。
应用上下文也提供了装饰器来修饰hook函数,@teardown_request,它会在上下文生命周期结束前,也就是_app_ctc_stack出栈前被调用,可以用下面的代码调用验证:
@app.teardown_appcontext
def teardown_db(exception):
print 'teardown application'
思考部分
- 既然在 Web 应用运行时里,应用上下文 和 请求上下文 都是 Thread Local 的,那么为什么还要独立二者?
- 既然在Web应用运行时中,一个线程同时只处理一个请求,那么 _req_ctx_stack和 _app_ctx_stack肯定都是只有一个栈顶元素的。那么为什么还要用“栈”这种结构?
- App和Request是怎么关联起来的?
查阅资料后发现第一个问题是因为设计初衷是为了能让两个以上的Flask应用共存在一个WSGI应用中,这样在请求中,需要通过应用上下文来获取当前请求的应用信息。
而第二个问题则是需要考虑在非Web Runtime的环境中使用的时候,在多个App的时候,无论有多少个App,只要主动去Push它的app context,context stack就会累积起来,这样,栈顶永远是当前操作的 App Context。当一个 App Context 结束的时候,相应的栈顶元素也随之出栈。如果在执行过程中抛出了异常,对应的 App Context 中注册的 teardown函数被传入带有异常信息的参数。
这么一来就解释了这两个问题,在这种单线程运行环境中,只有栈结构才能保存多个 Context 并在其中定位出哪个才是“当前”。而离线脚本只需要 App 关联的上下文,不需要构造出请求,所以 App Context 也应该和 Request Context 分离。
第三个问题
可以参考一下源码看一下Flask是怎么实现的请求上下文:
# 代码摘选自flask 0.5 中的ctx.py文件,
class _RequestContext(object):
def __init__(self, app, environ):
self.app = app
self.request = app.request_class(environ)
self.session = app.open_session(self.request)
self.g = _RequestGlobals()
Flask中的使用_RequestContext的方法如下:
class Flask(object):
def request_context(self, environ):
return _RequestContext(self, environ)
在Flask类中,每次请求都会调用这个request_context函数。这个函数则会创建一个_RequestContext对象,该对象需要接收WerkZeug中的environ对象作为参数。这个对象在创建时,会把Flask实例本身作为实参传进去,所以虽然每次http请求都创建一个_RequestContext对象,但是每次创建的时候传入的都是同一个Flask对象,因此:
由同一个Flask对象相应请求创建的_RequestContext对象的app成员变量都共享一个application
通过Flask对象中创建_RequestContext对象,并将Flask自身作为参数传入的方式实现了多个request context对应一个application context。
然后可以看self.request = app.request_class(environ)这句
由于app成员变量是app = Flask(name) 这个对象,所以app.request_class就是Flask.request_class,而在Flask类的定义中:
request_class = Request
class Request(RequestBase):
....
所以self.request = app.request_class(environ)实际上是创建了一个Request对象。由于一个http请求对应一个_RequestContext对象的创建,而每个_RequestContext对象的创建对应一个Request对象的创建,所以,每个http请求对应一个Request对象。
因此
application 就是指app = Flask(name)对象
request 就是对应每次http 请求创建的Request对象
Flask通过_RequestContext将App与Request关联起来
flask的源码实现
首先说请求上下文管理的设计思路:
当开启多线程或者协程去执行这个程序的时候,就需要对每个访问对象包装自己的数据,这样就不会发生数据的冲突,那么要怎么才能规避这个问题呢??
* 利用threading.local的知识,根据相似的实现原理,设计这个上下文管理机制;
* 首先写一个Local类,这个类中封装两个属性一个的属性值是一个空的字典,这个空字典的设计是这样的:字典中的键是当先执行的线程或者协程的id值,然后值是一个空的列表;
*另一个是get_ident方法名,这个方法是获取可以获取到线程或者协程的id;这个的内部是将协程的模块名改成:get_ident了,所以你如果开的是线程就获取线程的id,如果是协程就获取协程的id;
* 然后就是这个类中的实现方法了,有一个__setattr__方法,这个方法的作用主要是增加给__storage__这个字典中增加值的,__getattr__这个方法时获取这当前这线程或者协程值对应的id去__storage__获取对应的id的那个列表;
* 还有一个清空当前线程或者协程保存的数据__release_local__,
flask想要实现的是多线程下取值的正确,我们自己利用线程local实现简单的,但是flask实现要更复杂,获取当前请求的所有数据(environ)以及当前的实例化的app.
他怎么做到请求过来保证存取正确的?具体代码是如何实现的呢?
启动文件
from flask import Flask
app = Flask(__name__)
if __name__ == '__main__':
app.run() # 就是执行 app.__call__ 方法
这是整个flask的源码:
基于wsgi协议,environ就是关于请求的所有数据
def wsgi_app(self, environ, start_response):
ctx = self.request_context(environ)
error = None
try:
try:
#就把ctx放到了Local对象里面了
ctx.push()
#请求扩展以及响应函数
response = self.full_dispatch_request()
except Exception as e:
error = e
response = self.handle_exception(e)
except: # noqa: B001
error = sys.exc_info()[1]
raise
return response(environ, start_response)
finally:
if self.should_ignore_error(error):
error = None
ctx.auto_pop(error)
请求上下文
压栈
ctx = self.request_context(environ)
实现请求上下文相关,将当前app与请求相关传入,得到对象ctx
将environ传入request_context()方法中
1.1 RequestContext(self, environ) :self是当前的app,environ是请求相关的
1.2 RequestContext(self, environ)执行的结果是:RequestContext类的对象,该对象中包含了请求相关和当前的app
1.3 所以这个ctx就是RequestContext的对象。
源码:
def request_context(self, environ):
return RequestContext(self, environ)
ctx.push()
实现了请求上下文的压栈操作: 就是将ctx放到Locl对象中以这样的形式存储storage[ident][stack] = [ctx,]
当前ctx是RequestContext的对象,那就是执行RequestContext的对象的push方法
2.1 ctx.push方法中有一个 _request_ctx_stack.push(self)
这个self是ctx, 那就是把ctx,传递给_request_ctx_stack
2.2 _request_ctx_stack是什么?
--》 LocalStack的对象
`LocalStack` 是基于 `Local` 实现的栈结构。如果说 `Local` 提供了多线程或者多协程隔离的属性访问,那么 `LocalStack` 就提供了隔离的栈访问。下面是它的实现代码,可以看到它提供了 `push`、`pop` 和 `top` 方法。
2.3 _request_ctx_stack.push方法是什么?
看源码:
# obj就是_request_ctx_stack.push(self),传过来的self,也就是ctx
def push(self, obj):
rv = getattr(self._local, "stack", None)
if rv is None:
#storage["线程或者协程的id"][stack] = []
self._local.stack = rv = []
# storage["线程或者协程的id"][stack] = [ctx,]
rv.append(obj)
return rv
2.3.1 在2.3的代码中self._local.stack做了什么?
我们发现self._local是Local对象,所以self._local就执行Local对象的__setattr__:代码如下:
def __setattr__(self, name, value):
# 获取线程或协程id
ident = self.__ident_func__()
storage = self.__storage__
try:
#name = stack 赋值存储压栈
storage[ident][name] = value
except KeyError:
storage[ident] = {name: value}
对2的总结:就是将ctx放到Locl对象中以这样的形式存储storage[ident][stack] = [ctx,]
请求扩展
response = self.full_dispatch_request()
这里面是所有请求扩展以及真正的响应函数
源码如下
def full_dispatch_request(self):
self.try_trigger_before_first_request_functions()
try:
request_started.send(self)
rv = self.preprocess_request()
#如果请求扩展中的,请求之前的所有函数,如果没有返回值,就会执行下面的,
#下面的是:请求路由中的函数
if rv is None:
rv = self.dispatch_request()
except Exception as e:
rv = self.handle_user_exception(e)
return self.finalize_request(rv)
解析
实现befor_first_request
3.1 self.try_trigger_before_first_request_functions():
这是在执行请求扩展中的befor_first_request钩子,它是如何判断项目启动后只执行里面方法一次的呢?
答:它是通过self._got_first_request变量来判断的,初始值为False,一旦执行过该函数,在函数的末尾将self._got_first_request设置成True
源码如下:
def try_trigger_before_first_request_functions(self):
if self._got_first_request:
return
with self._before_request_lock:
if self._got_first_request:
return
#这里去循环第一次执行的函数,请求扩展的里面
for func in self.before_first_request_funcs:
func()
self._got_first_request = True
实现befor_request
3.2 rv = self.preprocess_request()
这里执行的是befor_request的函数,
源码如下:
def preprocess_request(self):
bp = _request_ctx_stack.top.request.blueprint
funcs = self.url_value_preprocessors.get(None, ())
if bp is not None and bp in self.url_value_preprocessors:
funcs = chain(funcs, self.url_value_preprocessors[bp])
for func in funcs:
func(request.endpoint, request.view_args)
#请求之前的要做的事情,请求之前的请求扩展
funcs = self.before_request_funcs.get(None, ())
if bp is not None and bp in self.before_request_funcs:
funcs = chain(funcs, self.before_request_funcs[bp])
for func in funcs:
rv = func()
if rv is not None:
return rv
解析
3.2.1 funcs = self.before_request_funcs.get(None, ())
这里是获取所有注册进来的befor_request
3.2.2 下面的代码可以看出:
如果befor_before_request函数有一个有返回值,那后面的函数都不执行,
并且把返回值给 rv = self.preprocess_request()的rv
for func in funcs:
rv = func()
if rv is not None:
return rv
判断响应函数的返回值
3.3 if rv is None: //这个rv是3.2中befor_reuqest返回的,如果没有返回值才会执行rv = self.dispatch_request();有返回值不会执行
rv = self.dispatch_request() //这是真正的响应函数
通过这个代码:我们知道,如果befor_request有返回值,就不会执行真正的响应函数
实现after_request
3.4 return self.finalize_request(rv): 个rv是3.2或者3.3的返回值
源码如下:
def finalize_request(self, rv, from_error_handler=False):
response = self.make_response(rv)
try:
#这里执行的是执行完请求视图后,after_request的请求
response = self.process_response(response)
request_finished.send(self, response=response)
except Exception:
if not from_error_handler:
raise
self.logger.exception(
"Request finalizing failed with an error while handling an error"
)
return response
解析
3.4.1 response = self.process_response(response):这里做after_request请求扩展的
源码如下:
def process_response(self, response):
ctx = _request_ctx_stack.top
bp = ctx.request.blueprint
funcs = ctx._after_request_functions
if bp is not None and bp in self.after_request_funcs:
funcs = chain(funcs, reversed(self.after_request_funcs[bp]))
if None in self.after_request_funcs:
funcs = chain(funcs, reversed(self.after_request_funcs[None]))
for handler in funcs:
response = handler(response)
if not self.session_interface.is_null_session(ctx.session):
self.session_interface.save_session(self, ctx.session, response)
return response
在上述代码中有两行代码:
if None in self.after_request_funcs:
#funcs是所有after_request的函数列表,并用reversed做了反转
#这个我们就知道,在after_request为什么先注册的后执行
funcs = chain(funcs, reversed(self.after_request_funcs[None]))
for handler in funcs:
#在这里知道after_request的函数必须接收这个response,并且要做返回
response = handler(response)
出栈
4. 我们知道3中就可以调用request属性了,那它怎么做到呢?当我们在3中的任意一个位置,都能调用request或者其他的。比如我们request.methons,它是如果找到当前请求的request呢
LocalProxy
4.1 当我们调用request.methods的时候,我们先要看看rquest是什么?
看源码我们知道:request = LocalProxy(partial(_lookup_req_object, "request"))也就说是LocalProxy对象
4.2 当我们调用request.methons就会返回属性methons属性给我们,但是我们在LocalProxy根本就没有methons属性,那我们想到,既然没有这个属性,那一定会走__getattr__
LocalProxy的__getattr__源码如下:
def __getattr__(self, name):
if name == "__members__":
return dir(self._get_current_object())
return getattr(self._get_current_object(), name)
上述代码中name,就是我们要找的methons属性,那它是从self._get_current_object()通过反射那拿去的
从下面的分析中我们知道self._get_current_object() 就是request。
4.2.1 self._get_current_object()的返回值是什么?通过下面的源码我们可以看到就self.__local()执行结果
源码:
def _get_current_object(self):
if not hasattr(self.__local, "__release_local__"):
return self.__local()
try:
return getattr(self.__local, self.__name__)
except AttributeError:
raise RuntimeError("no object bound to %s" % self.__name__)
4.2.1.1 self.__local()的执行结果是什么?我们先搞清楚self.__local是什么?
我们发现self.__local是通过LocalProxy的如下初始化得到的:
def __init__(self, local, name=None):
object.__setattr__(self, "_LocalProxy__local", local)
那我们可以知道 self.__local就是4.1 中 LocalProxy(partial(_lookup_req_object, "request"))的参数,
也就 partial(_lookup_req_object, "request")偏函数
4.2.1.2 我们现在知道self.__local是 partial(_lookup_req_object, "request")
那 self.__local()就是 partial(_lookup_req_object, "request")()执行
4.2.1.3 partial(_lookup_req_objec,"request")相当于给_lookup_req_objec函数传递了一个"request"参数
_lookup_req_objec的源码如下:
def _lookup_req_object(name): #name 为 "request"
#到Local中把ctx取出来了
# top就是压栈存储的数据栈区
top = _request_ctx_stack.top
if top is None:
raise RuntimeError(_request_ctx_err_msg)
#cxt中取request,把request反射回去了
return getattr(top, name)
''' 我们从 4.2.1.3得知:top就是ctx,getattr(top, name)就是从ctx中找request,并且返回
那 4.2.1.2中self.__local执行的结果就是request'''
4.2.1.3.1 上述代码中 _request_ctx_stack.top 的源码如下:
@property
def top(self):
try:
#返回了一开始进去的ctx对象 (出栈时总是最新添加的)
return self._local.stack[-1]
except (AttributeError, IndexError):
return None
self._local也是Local对象.stack就是在执行__getattr__
# 根据name进行出栈操作
代码如下:
def __getattr__(self, name):
try:
return self.__storage__[self.__ident_func__()][name] # get_ident
except KeyError:
raise AttributeError(name)
这样_request_ctx_stack.top的到的结果就ctx,那 4.2.1.3 中的 top = _request_ctx_stack.top;top就是ctx
g对象的使用
简介
- 在flask中,有一个专门用来存储用户信息的g对象,g的全称的为global。
- g对象在一次请求中的所有的代码的地方,都是可以使用的。
使用
1.创建一个utils.py文件,用于测试除主文件以外的g对象的使用
utils.py
#encoding: utf-8
from flask import g
def login_log():
print u'当前登录用户是:%s' % g.username
def login_ip():
print u'当前登录用户的IP是:%s' % g.ip
2.在主文件中调用utils.py中的函数
#encoding: utf-8
from flask import Flask,g,request,render_template
from utils import login_log,login_ip
app = Flask(__name__)
@app.route('/')
def hello_world():
return 'Hello World!'
@app.route('/login/',methods=['GET', 'POST'])
def login():
if request.method == 'GET':
return render_template('login.html')
else:
username = request.form.get('username')
password = request.form.get('password')
g.username = username
g.ip = password
login_log()
login_ip()
return u'恭喜登录成功!'
if __name__ == '__main__':
app.run()
测试:
现在在浏览器里面,访问两次服务器,效果如下:
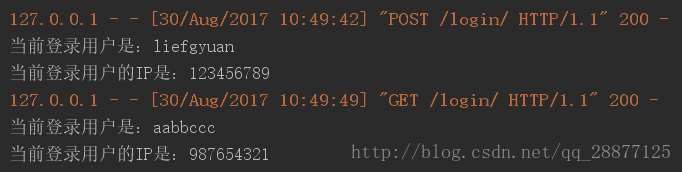
出处:https://blog.csdn.net/qq_28877125/article/details/77683720
g对象和session的区别
在我看来,最大的区别是,session对象是可以跨request的,只要session还未失效,不同的request的请求会获取到同一个session,但是g对象不是,g对象不需要管过期时间,请求一次就g对象就改变了一次,或者重新赋值了一次。
flask-script
Flask-Script是一个让你的命令行支持自定义命令的工具,它为Flask程序添加一个命令行解释器。可以让我们的程序从命令行直接执行相应的程序。
通过使用Flask-Script扩展,我们可以在Flask服务器启动的时候,通过命令行的方式传入参数。而不仅仅通过app.run()方法中传参,比如我们可以通过python hello.py runserver –host ip地址,告诉服务器在哪个网络接口监听来自客户端的连接。默认情况下,服务器只监听来自服务器所在计算机发起的连接,即localhost连接。
我们可以通过python hello.py runserver --help来查看参数。
使用
安装
$ pip install flask-script
命令行执行Manager
import MyApp
# 导入 Flask-Script 中的 Manager
from flask_script import Manager
# 让app支持 Manager
manager = Manager(app)
if __name__ == '__main__':
#app.run()
# 替换原有的app.run(),然后大功告成了
manager.run()
# 也可以在终端中输入
# python 文件名.py runserver -h -p
自定义命令Command
Flask-Script还可以为当前应用添加脚本命令
# 导入 Flask-Script 中的 Manager
from flask_script import Manager
# 让app支持 Manager
manager = Manager(app) # type:Manager
@manager.command
def DragonFire(arg):
print(arg)
if __name__ == '__main__':
#app.run()
# 替换原有的app.run(),然后大功告成了
manager.run()
python manager.py DragonFire 666
`python manager.py 函数名 传入参数`
长指令
@manager.opation("-短指令","--长指令",dest="变量名")
# 导入 Flask-Script 中的 Manager
from flask_script import Manager
# 让app支持 Manager
manager = Manager(app) # type:Manager
@manager.command
def DragonFire(arg):
print(arg)
@manager.option("-n","--name",dest="name")
@manager.option("-s","--say",dest="say")
def talk(name,say):
print(f"{name}你可真{say}")
if __name__ == '__main__':
#app.run()
# 替换原有的app.run(),然后大功告成了
manager.run()
python manager.py talk -n 名字 -s 描述
python manager.py talk --name DragonFire --say NB-Class
打印
- 名字你可真描述
- DragonFire你可真NB-Class

 浙公网安备 33010602011771号
浙公网安备 33010602011771号