0109 redis数据库的配置与使用
昨日回顾
1、接口编辑
1)设计数据库
2)分析业务逻辑
3)配置路由层
4)完成视图(简单逻辑,直接在视图中完成,复杂逻辑,交给序列化组件完成)
5)序列化组件(序列化与反序列化字段,是否要(重|自)定义字段,设置局部全局钩子,考虑是否重写create和update方法)
2、django缓存
from django.core.cache import cache (memcache|redis)
cache.set(k, v, e)
cache.get(k)
3、vue-cookies
$cookies = vue-cookies
$cookies.set(k, v, e)
$cookies.get(k)
$cookies.remove(k)
-- 前台数据库:cookie、sessionStorage、localStorage
4、前后台交互
$axios({
url: '',
method: '',
params: {},
data: {},
headers: {},
}).then(response=>{}).catch(error=>{})
5、注销
前台丢弃token(登录的标识)
Redis
下载地址:
- windows版本
- [其他版本](
1. Redis简介
redis 就是一个数据库,不过与传统数据库不同的是 redis 的数据是存在内存中的,所以存写速度非常快,因此 redis 被广泛应用于缓存方向。另外,redis 也经常用来做分布式锁。redis 提供了多种数据类型来支持不同的业务场景。除此之外,redis 支持事务 、持久化、LUA脚本、LRU驱动事件、多种集群方案。
1.1 为什么要用 redis /为什么要用缓存
主要从“高性能”和“高并发”这两点来看待这个问题。
高性能:
假如用户第一次访问数据库中的某些数据。这个过程会比较慢,因为是从硬盘上读取的。将该用户访问的数据存在数缓存中,这样下一次再访问这些数据的时候就可以直接从缓存中获取了。操作缓存就是直接操作内存,所以速度相当快。如果数据库中的对应数据改变的之后,同步改变缓存中相应的数据即可!

image
高并发:
直接操作缓存能够承受的请求是远远大于直接访问数据库的,所以我们可以考虑把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不用经过数据库。

image
1.2 为什么要用 redis 而不用 map/guava 做缓存?
缓存分为本地缓存和分布式缓存。以 Java 为例,使用自带的 map 或者 guava 实现的是本地缓存,最主要的特点是轻量以及快速,生命周期随着 jvm 的销毁而结束,并且在多实例的情况下,每个实例都需要各自保存一份缓存,缓存不具有一致性。
使用 redis 或 memcached 之类的称为分布式缓存,在多实例的情况下,各实例共用一份缓存数据,缓存具有一致性。缺点是需要保持 redis 或 memcached服务的高可用,整个程序架构上较为复杂。
1.3 redis 和 memcached 的区别
对于 redis 和 memcached 的区别有下面四点。
- redis支持更丰富的数据类型(支持更复杂的应用场景):Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,zset,hash等数据结构的存储。memcache支持简单的数据类型,String。
- Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用,而Memecache把数据全部存在内存之中。
- 集群模式:memcached没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;但是 redis 目前是原生支持 cluster 模式的.
- Memcached是多线程,非阻塞IO复用的网络模型;Redis使用单线程的多路 IO 复用模型。

redis 和 memcached 的区别
2.Redis内存数据库
硬盘:
MySQL MongoDB
内存:
memcachedb Redis
2.1 redis介绍
1 redis安装
"""
1、官网下载:安装包或是绿色面安装
2、安装并配置环境变量
"""
2 redis VS mysql
"""
redis: 内存数据库(读写快)、非关系型(操作数据方便、数据固定)
mysql: 硬盘数据库(数据持久化)、关系型(操作数据间关系、可以不同组合)
大量访问的临时数据,才有redis数据库更优
"""
3 redis VS memcache
"""
redis: 操作字符串、列表、字典、无序集合、有序集合 | 支持数据持久化(数据丢失可以找回(默认持久化,主动持久化save)、可以将数据同步给mysql) | 高并发支持
memcache: 操作字符串 | 不支持数据持久化 | 并发量小
"""
2.2 Redis操作
1 连接数据库
-h ip地址 -p 端口号 -n 数据库编号 -a 密码
"""
1)默认连接:-h默认127.0.0.1,-p默认6379,-n默认0,-a默认无
>: redis-cli
2)完整连接:
>: redis-cli -h ip地址 -p 端口号 -n 数据库编号 -a 密码
3)先连接,后输入密码
>: redis-cli -h ip地址 -p 端口号 -n 数据库编号
>: auth 密码
关闭服务
redis-cli shutdown
"""
2 启动服务
前提:前往一个方便管理redis持久化文件的路径再启动服务:dump.rdb
* 1)前台启动服务
> : redis-server
* 2)后台启动服务
>: redis-server --service-start
* 3)配置文件启动服务
>: redis-server 配置文件的绝对路径
>: redis-server --service-start 配置文件的绝对路径
>> eg>: redis-server --service-start D:/redis/redis.conf
####
3 密码管理
"""
1)提倡在配置文件中配置,采用配置文件启动
requirepass
2)当服务启动后,并且连入数据库,可以再改当前服务的密码(服务重启,密码重置)
config set requirepass 新密码
3)连入数据库,查看当前服务密码密码
config get requirepass
"""
4 关闭服务
"""
1)在没有连接进数据库时执行
>: redis-cli shutdown
2)连接进数据库后执行
>: shutdown
"""
5 切换数据库
"""
1)在连入数据库后执行
>: select 数据库编号
"""
6 数据持久化
"""
1)配置文件默认配置
save 900 1 # 超过900秒有1个键值对操作,会自动调用save完成数据持久化
save 300 10 # 超过300秒有10个键值对操作,会自动调用save完成数据持久化
save 60 10000 # 超过60秒有10000个键值对操作,会自动调用save完成数据持久化
2)安全机制
# 当redis服务不可控宕机,会默认调用一下save完成数据持久化
3)主动持久化
>: save # 连入数据库时,主动调用save完成数据持久化
注:数据持久化默认保存文件 dump.rdb,保存路径默认为启动redis服务的当前路径
"""
2.3 Redis数据类型
"""
数据操作:字符串、列表、哈希(字典)、无序集合、有序(排序)集合
有序集合:游戏排行榜
"""
字符串
# 设置
set key value (例如: set name reese)
# 获取value值
get key (例如: get name)
# key是唯一的,不能用同一个key,否则会覆盖
# 设置多个值
mset k1 v1 k2 v2 ...
# 获取多个值
mget k1 k2 ...
# 给key设置过期时间
setex key exp value
# 将 key 所储存的值加上增量 increment 。
incrby key increment
- 查看过期时间
127.0.0.1:6379> ttl name
(integer) -1
# -1代表永久, -2代表不存在
- 设置过期时间
# 给已存在的key设置过期时间
expire key seconds (例子:expire name 10)
# 设置key的同时,设置过期时间
set key value ex seconds (例如: set name reese ex 20)
或者
setex key seconds value (例如: setex name 20 cwz)
- 追加
# 给已有的value值,添加新的值
append key value
- 设置/获取多个
# 设置多个string
mset key value key value ...
例如:
mset user cwz password 123
# 获取多个
mget key key key ...
例子:
mget user password
- key操作
# 查看所有的key值
keys *
# 删除
del key
# 查看key是否存在,存在返回1,不存在返回0
exists key
# 查看key类型
type key
- 运算
set num 1 # 自动识别,字符串里面的整数
incr num # 加1
decr num # 减1
incrby num 50 # 增加多个
descby num 50 # 减少多个
列表
栈:先进后出
队列:先进先出
rpush key value1 value2 ...
lpush key value1 value2 ...
lrange key bindex eindex
lindex key index
lpop key | rpop key
linsert key before|after old_value new_value
- 设置
# 左添加 栈 先进后出
127.0.0.1:6379> lpush my_list 1 2 3 4 5 6
(integer) 6
# 右添加 队列 先进先出
rpush my_list 7 8
- 查看
查看所有:
127.0.0.1:6379> lrange my_list 0 -1
1) "6"
2) "5"
3) "4"
4) "3"
5) "2"
6) "1"
- 获得list的元素个数
llen my_list
- 查看特定索引位置的元素
lindex my_list 2
- 删除
lpop my_list # 删除左边第一个
rpop my_list # 删除右边第一个
lrem my_list 1 5 # 表示从左往右删除1个5
lrem my_list 0 5 # 表示删除所有的5
lrem my_list -2 5 # 表示从右往左删除2个5
哈希
是一个string类型的field和value的映射表,特别适合用于存储对象
hash的key必须是唯一的
Key : (field:value)
- 设置
hset key field value
# 例子:
hset users name xxx
- 获取
hget key field
# 例子:
hget users name
- 删除
hdel key field
# 例子:
hdel users name
- 设置多个
hmset user name yyy age 19 sex male
- 获取多个
hmget user name age sex
- 获取全部field value
hgetall user
- 获取所有的field
hkeys user
- 获取所有的value
hvals user
- 获取field个数
hlen key
- 获取field类型
type key
:
hset key field value
hget key field
hmset key field1 value1 field2 value2 ...
hmget key field1 field2
hkeys key
hvals key
hdel key field
集合
- 设置
sadd my_set 1 2 3 4 5 6
- 获取
smembers key
- 删除
# srem指定删除
srem key members
# spop随即删除
spop key
- 移动一个集合的值到另一个集合
smove oldkey newkey members
例子:
smove my_set1 my_set2 3
- 判断集合存在某个值
sismember key value
- 交集
sinter key1 key2 ...
# 把key1 key2的交集合并到newkey
sinterstore newkey key1 key2
- 并集
sunion key1 key2 ...
# 把key1 key2的并集合并到newkey
sunionstore newkey key1 key2
- 差集
sdiff key1 key2 ...
# 把key1 key2的差集合并到newkey
sdiffstore newkey key1 key2
- 获取集合个数
scard key
- 随机返回一个数据
srandmember key
:
sadd key member1 member2 ...
sdiff key1 key2 ...
sdiffstore newkey key1 key2 ...
sinter key1 key2 ...
sunion key1 key2 ...
smembers key
spop key
有序集合
- 设置
zadd key score member (权,权重,顺序)
例子:
127.0.0.1:6379> zadd my_zset1 1 1 2 2 3 3 4 4 5 5 6 6
127.0.0.1:6379> zrange my_zset1 0 -1
1) "1"
2) "2"
3) "3"
4) "4"
5) "5"
6) "6"
- 查询获取
# zrange 正序
zrange my_zset1 0 -1
# zrevrange 倒序
zrevrange my_zset1 0 -1
- 删除
zrem my_zset1 2
- 索引
# zrank 正序
zrank key member
# zrevrank 反序
zrevrank key member
- zcard 查看有序集合元素数
zcard key
- zrangebyscore 返回集合中score在给定区间的元素
# zrange my_zset 0 -1 withscores
zrangebyscore my_zset 2 3 withscores
# 返回了score在2~3区间的元素
- zcount 返回集合中在定区间的数量
zount key min max
例子
zount my_zset 2 3
- zscore 查看score(权重)值
zscore key member
例子
zscore my_zset 3
- zremrangebyrank 删除集合中排名在定区间中的元素
# zrange my_zset 0 -1 withscores
zrerangebyrank my_zset 1 3
- zremrangebyscore 删除集合中score在给定区间的元素
# zrange my_zset 0 -1 withscores
zremrangebyscore my_zset 1 3
:
zadd key grade1 member1 grade2 member2 ...
zincrby key grade member
zrange key start end
zrevrange key start end
2.4 python使用redis
安装
>: pip3 install redis
直接使用
import redis
r = redis.Redis(host='127.0.0.1', port=6379, db=1, password=None, decode_responses=True)
连接池使用
import redis
pool = redis.ConnectionPool(host='127.0.0.1', port=6379, db=1, max_connections=100, password=None, decode_responses=True)
r = redis.Redis(connection_pool=pool)
缓存使用:要额外安装 django-redis
# 1.将缓存存储位置配置到redis中:settings.py
CACHES = {
"default": {
"BACKEND": "django_redis.cache.RedisCache",
"LOCATION": "redis://127.0.0.1:6379/0",
"OPTIONS": {
"CLIENT_CLASS": "django_redis.client.DefaultClient",
"CONNECTION_POOL_KWARGS": {"max_connections": 100},
"DECODE_RESPONSES": True,
"PSAAWORD": "",
}
}
}
# 2.操作cache模块直接操作缓存:views.py
from django.core.cache import cache # 结合配置文件实现插拔式
# 存放token,可以直接设置过期时间
cache.set('token', 'header.payload.signature', 300)
# 取出token
token = cache.get('token')
一些操作:
rdb.expire('user_name', 20) # 添加过期时间
rdb.ttl('user_name') # 在python中不能查看
rdb.mset(a=1, b=2) # 设置多个
rdb.incr('num',222) # 后面直接加参数为数量,如果不加参数,默认加1
rdb.lrem('list_1', 3, 0) # 要删的数量在后面,删除的元素在前面
rdb.hmset('user', {'name':'neo', 'age':19}) # key单独写出,后面用字典方式添加
Django项目中会用redis
# Django项目中使用redis
import redis
# 连接池的使用
pool = redis.ConnectionPool(max_connections=100,decode_responses=True)
rdb = redis.Redis(connection_pool=pool)
from libs import tx_sms
# 获取验证码
code = tx_sms.get_sms_code()
# 保存redis中并设置过期时间
rdb.setex('sms', 300, code)
# 在项目中,过多需要缓存的不是简单数据,而是对象,比如model类型对象
from user.models import User
user_query = User.objects.all()
# print(user_query)
# 1.原生的redis不能直接操作对象
# rdb.setex('user_query',300, user_query) # 报错
# 2.原生的django的cache缓存具有缺点
# 3.使用Django.redis进行保存
# 需要安装django.redis并且在settings中设置
from django.core.cache import cache
cache.set('user_query',user_query,300)
print(cache.get('user_query'))
3.接口缓存
后台接口是提供数据库数据的,IO操作慢,可以将数据存储在缓存中,接口数据从缓存中调
一般将大量访问(数据时效性要求不是很苛刻)的接口建立缓存
接口缓存思想:数据先走缓存,有直接返回,没有走数据库(同步到缓存)
模式
Django 缓存模式的使用(主要针对RestFul设计模式的项目)
有三种模式:
- 全站使用缓存模式(整个项目每个接口都会使用缓存,缺点:所以接口都无法实时性获取数据)
- 单独视图缓存模式(单个接口使用缓存)
- 局部视图缓存模式
第一种:实现方式:
必须在 settings中设置 缓存中间件
MIDDLEWARE = [
'django.middleware.cache.UpdateCacheMiddleware',
。。。其他中间件。。。
'django.middleware.cache.FetchFromCacheMiddleware',
]
但是伴随的缺点就是 没有设置 缓存的接口默认都会有600秒的缓存,如下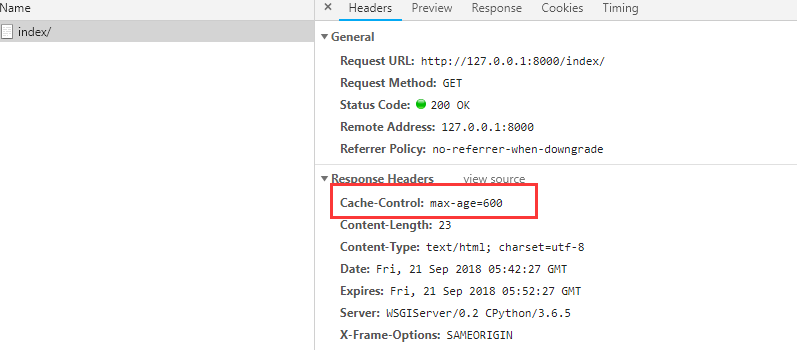
无论清缓存还是换浏览器,因为缓存都是放在服务端的。
这就导致 那些不需要设置缓存,要求数据实时性较高的接口无法及时返回最新数据。
所以:
如果需要使用
from django.views.decorators.cache import cache_page, cache_control
from django.views.decorators.vary import vary_on_headers
@cache_control,@vary_on_headers,@vary_on_cookie
这些装饰器,就必须需要 缓存中间件,但是这样会导致其他接口都会有缓存600秒,需要慎重考虑使用
第二种:
[ ](javascript:void(0)😉
](javascript:void(0)😉
from django.views.decorators.cache import cache_page
@cache_page(10)
def cac(request):
.......
[](javascript:void(0)😉
这种方式只针对一个接口使用缓存(个人倾向于使用此方式)
第三种:
涉及到模板的使用(具体没有研究过):
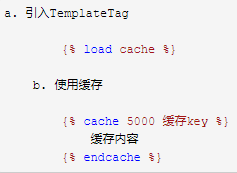
轮播图接口缓存
from rest_framework.viewsets import GenericViewSet
from rest_framework import mixins
from django.conf import settings
from utils.response import APIResponse
from . import models, serializers
from rest_framework.response import Response
from django.core.cache import cache
class BannerListViewSet(mixins.ListModelMixin, GenericViewSet):
queryset = models.Banner.objects.filter(is_delete=False, is_show=True).order_by('-orders').all()[:settings.BANNER_COUNT]
serializer_class = serializers.BannerModelSerializer
# 自定义响应结果的格式
# def list(self, request, *args, **kwargs):
# response = super().list(request, *args, **kwargs)
# return APIResponse(results=response.data)
# 接口缓存
def list(self, request, *args, **kwargs):
# 先获取缓存
data = cache.get('banner_cache')
# 如果没有响应缓存,就走数据库
if not data:
print('走了数据库')
response = super().list(request, *args, **kwargs)
# 并设置缓存
cache.set('banner_cache', response.data) # 不设置过期时间,缓存的更新在后台异步更新(celery异步框架)
return response
return Response(data)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号