CMU15-445 POJECT#3 - QUERY EXECUTION
排序
sql中的排序用于ORDER BY、DISTINCT等语句;
如果被排序的数据能够全部放在内存中,则直接进行排序即可;但如果数据无法全部放入内存中,我们需要使用分而治之的策略;
- 把数据分成能够适配内存大小的块,然后进行排序,然后放回内存;
- 将块合并成一个更大的有序块(可以使用两两merge)
时间复杂度:1+floor(log2N)
I/O次数:2N*(number(块个数))
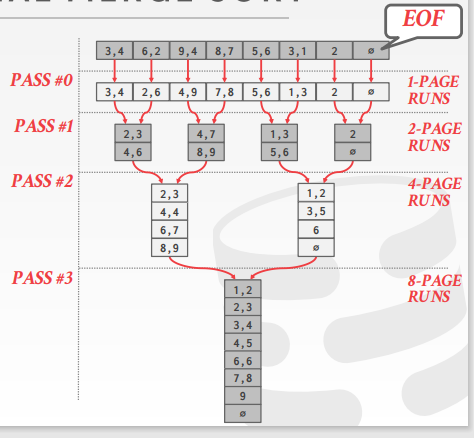
可使用B+树进行排序;
聚簇索引:将数据存储和索引放在一起、并且是按照一定的顺序组织的,找到索引也就找到了数据,数据的物理存放顺序与索引顺序是一致的,即:只要索引是相邻的,那么对应的数据一定也是相邻的存放在磁盘上的。
非聚簇索引:叶子节点不存储数据,存储的是数据行地址,也就是说根据索引查找到数据行的位置再去磁盘查找数据,这就有点类似一本书的目录,比如要找到第三章第一节,那就现在目录里面查找,找到对应的页码后再去对应的页码看文章。
聚合
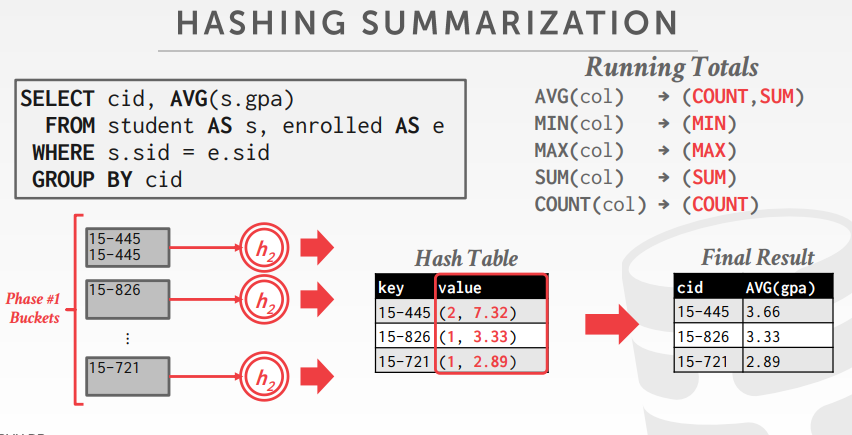
如果数据能够放入内存中,直接进行哈希聚合即可;如果无法放入内存中,则也需要使用分而治之的策略:
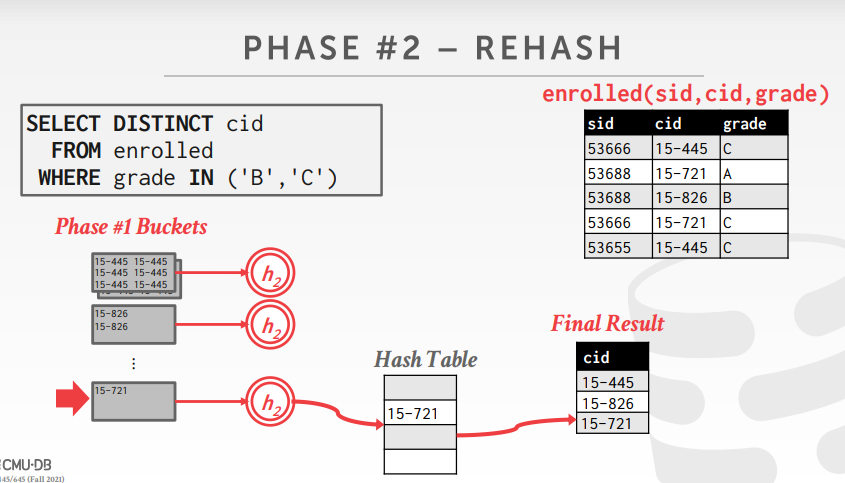
- partition:将元组们根据hash键值划分为若干部分,每个部分有一页或更多页组成,且有相同的哈希值;

- rehash:对磁盘上的每一个分区,将其读入内存中并根据新的哈希函数建立哈希表,然后遍历哈希表中的每个桶并取出匹配的元组,此外,我们还需要存储一些运行时的值;
连接(Join)
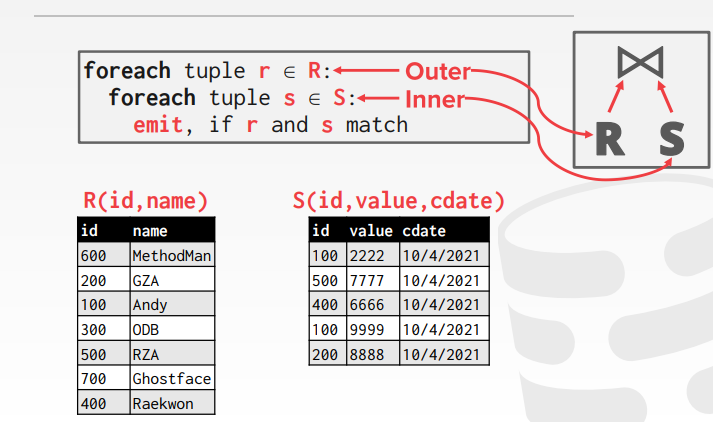
嵌套循环连接
1. 愚蠢版
每条数据就需要访问让另一个表中的所有数据进入磁盘一次;
2. 分块版
(磁盘访问次数少,对于每个块R,他只访问S一次)

3. 索引版
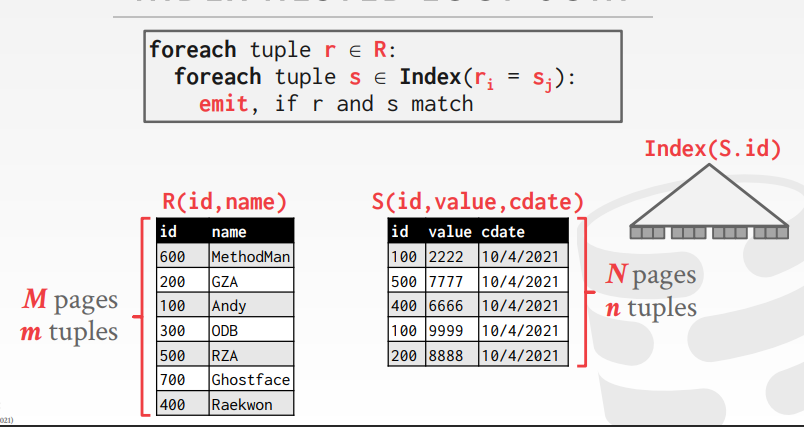
SORT-MERGE连接(输出结果是有序的)
(类比两个有序链表合并的过程)
sort R,S on join keys
cursorR ← Rsorted, cursorS ← Ssorted
while cursorR and cursorS:
if cursorR > cursorS:
increment cursorS
if cursorR < cursorS:
increment cursorR
elif cursorR and cursorS match:
emit
increment cursor
哈希连接
- 建表:扫描外表并根据要连接的属性建立哈希表;
- 检索:扫描内表,使用同样的哈希函数,讲得到的值去哈希表中比对,并找到匹配项;
build hash table HTR for R
foreach tuple s ∈ S
output, if h1(s) ∈ HTR
对于检索过程可以进行优化,创建Bloom Filter(布隆过滤器)
- 对于v[n],给定若干个哈希函数h1, h2, h3 ... hk, 和一个位图b[t](每一位初始化为0)
- 对于v中的每一个元素,计算h1(v[i])%t, h2(v[i])%t, ... , hk(v[i])%t, 可以得到k个数,在位图上将每个数对应的位置为1;
- 这样,如果需要判断一个元素是否位于v[n]中,他只需要计算所有的哈希函数,并判断结果在位图上是否有一位为0,若有一位为0,则该元素一定不在v中;否则,他有可能位于v中。

查询执行
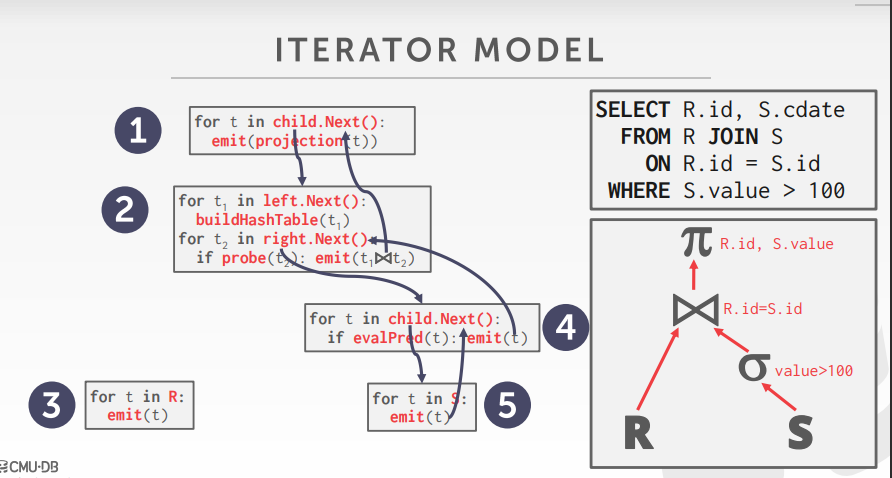
代码实现
这一部分的难点主要在于梳理各个已有类的关系上,实现部分的难度较小。首先介绍一些关键类;
ExecutorContext:包含一些运行上下文信息,主要有transaction(当前运行的事务)、catalog(目录,记录当前系统总所有的表和目录)、bpm(缓存池管理器)、txn_mgr(事务管理器,记录系统中全部的事务,并提供事务的开始、提交、结束等接口)、lock_mgr(锁管理器,事务在请求锁时会向其询问,锁管理器来判断是否给锁)
ExecutorFactory:工厂模式,根据参数来生成不同类型的执行器executor,如:
switch (plan->GetType()) {
// Create a new sequential scan executor
case PlanType::SeqScan: {
return std::make_unique<SeqScanExecutor>(exec_ctx, dynamic_cast<const SeqScanPlanNode *>(plan));
}
// Create a new index scan executor
case PlanType::IndexScan: {
return std::make_unique<IndexScanExecutor>(exec_ctx, dynamic_cast<const IndexScanPlanNode *>(plan));
}
// Create a new insert executor
case PlanType::Insert: {
auto insert_plan = dynamic_cast<const InsertPlanNode *>(plan);
auto child_executor =
insert_plan->IsRawInsert() ? nullptr : ExecutorFactory::CreateExecutor(exec_ctx, insert_plan->GetChildPlan());
return std::make_unique<InsertExecutor>(exec_ctx, insert_plan, std::move(child_executor));
}
}
Executor: 有不同类型的执行器,是本项目需要实现的地方,包含两个接口:Init()和Next();
AbstractPlanNode:是所有plan node的基类,plan node是树形结构(参照Iterator model),每个plan node代表一类对表的操作,如全表扫描、连接、聚合等,并记录有实现这些操作所需要的表信息和一些特定的接口(如获取内外子表等)
AbstractExpression:是所有Expression的基类,也是树形结构,Expression顾名思义,记录有各种对元组操作的表达式,用于规定一次查询中每个executor具体对数据如何处理,如:
// 通过这个类可以规定应该如何做比较操作
class ComparisonExpression : public AbstractExpression {
public:
/** Creates a new comparison expression representing (left comp_type right). */
ComparisonExpression(const AbstractExpression *left, const AbstractExpression *right, ComparisonType comp_type)
: AbstractExpression({left, right}, TypeId::BOOLEAN), comp_type_{comp_type} {}
Value Evaluate(const Tuple *tuple, const Schema *schema) const override {
Value lhs = GetChildAt(0)->Evaluate(tuple, schema);
Value rhs = GetChildAt(1)->Evaluate(tuple, schema);
return ValueFactory::GetBooleanValue(PerformComparison(lhs, rhs));
}
Value EvaluateJoin(const Tuple *left_tuple, const Schema *left_schema, const Tuple *right_tuple,
const Schema *right_schema) const override {
Value lhs = GetChildAt(0)->EvaluateJoin(left_tuple, left_schema, right_tuple, right_schema);
Value rhs = GetChildAt(1)->EvaluateJoin(left_tuple, left_schema, right_tuple, right_schema);
return ValueFactory::GetBooleanValue(PerformComparison(lhs, rhs));
}
Value EvaluateAggregate(const std::vector<Value> &group_bys, const std::vector<Value> &aggregates) const override {
Value lhs = GetChildAt(0)->EvaluateAggregate(group_bys, aggregates);
Value rhs = GetChildAt(1)->EvaluateAggregate(group_bys, aggregates);
return ValueFactory::GetBooleanValue(PerformComparison(lhs, rhs));
}
private:
CmpBool PerformComparison(const Value &lhs, const Value &rhs) const {
switch (comp_type_) {
case ComparisonType::Equal:
return lhs.CompareEquals(rhs);
case ComparisonType::NotEqual:
return lhs.CompareNotEquals(rhs);
case ComparisonType::LessThan:
return lhs.CompareLessThan(rhs);
case ComparisonType::LessThanOrEqual:
return lhs.CompareLessThanEquals(rhs);
case ComparisonType::GreaterThan:
return lhs.CompareGreaterThan(rhs);
case ComparisonType::GreaterThanOrEqual:
return lhs.CompareGreaterThanEquals(rhs);
default:
BUSTUB_ASSERT(false, "Unsupported comparison type.");
}
}
std::vector<const AbstractExpression *> children_;
ComparisonType comp_type_;
};
Value:定义了一些数据库中使用到的数据类型;
Tuple:元组,即数据库中的一行,
RID:记录标识符,主要有两个字段page_id和slot_num,可以通过RID找到数据的物理位置;
Column:记录了列的名称,数据类型、数据长度等
``Schema: 主要有
std::vector<Column> columns_,每次查询时,需要返回哪几列数据也通过这个字段给与;
实现
思路
思路很简单,在init()时将指针指到表首,每次调用next()时,执行对应的数据处理,需要调用子操作(plan node)就从子操作中获取数据,处理后将指针加一,最后返回处理后的tuple和rid;
难点
- 处理结果应该是哪些字段,应该从哪里获取;例如在hash join的时候,需要将两个元组合为一个,这时候应该从两个元组中取出哪些字段,以及最后生成哪些字段,由于类的关系比较绕,所以会比较困难;
- 对于事务,如果一次事务回滚需要重新进行某项查询时,需要通过init重置executor,确保可以重新处理一遍。
bloom filter
class BitMap {
public:
BitMap() : size_(0) {}
explicit BitMap(size_t size) : size_(0) { array_.resize((size >> 5) + 1); }
bool IsSet(size_t num) {
size_t loc = num >> 5;
size_t off = num % 32;
return (array_[loc] & (1 << off)) != 0;
}
bool Set(size_t num) {
size_t loc = num >> 5;
size_t off = num % 32;
if ((array_[loc] & (1 << off)) != 0) {
return false;
}
array_[loc] |= (1 << off);
size_++;
return true;
}
bool ReSet(size_t num) {
size_t loc = num >> 5;
size_t off = num % 32;
if ((array_[loc] & (1 << off)) != 0) {
array_[loc] ^= (1 << off);
size_--;
return true;
}
return false;
}
private:
std::vector<size_t> array_;
size_t size_{0};
};
class BloomFilter {
public:
BloomFilter() = default;
explicit BloomFilter(size_t size) : capacity_(size), bitmap_(capacity_) {}
void Init(size_t size) {
capacity_ = size;
bitmap_ = BitMap(capacity_);
}
void SetValue(const Value &val);
bool IsContain(const Value &val);
private:
// 各类哈希函数
size_t BKDRHash(const char *str, size_t length);
size_t SDBMHash(const char *str, size_t length);
size_t RSHash(const char *str, size_t length);
size_t APHash(const char *str, size_t length);
size_t JSHash(const char *str, size_t length);
size_t capacity_;
BitMap bitmap_;
};
void BloomFilter::SetValue(const Value &val) {
const char *ptr = reinterpret_cast<const char *>(&val);
size_t length = sizeof(val);
bitmap_.Set(BKDRHash(ptr, length) % capacity_);
bitmap_.Set(SDBMHash(ptr, length) % capacity_);
bitmap_.Set(RSHash(ptr, length) % capacity_);
bitmap_.Set(APHash(ptr, length) % capacity_);
bitmap_.Set(JSHash(ptr, length) % capacity_);
}
bool BloomFilter::IsContain(const Value &val) {
const char *ptr = reinterpret_cast<const char *>(&val);
size_t length = sizeof(val);
if (!bitmap_.IsSet(BKDRHash(ptr, length) % capacity_)) {
return false;
}
if (!bitmap_.IsSet(SDBMHash(ptr, length) % capacity_)) {
return false;
}
if (!bitmap_.IsSet(RSHash(ptr, length) % capacity_)) {
return false;
}
if (!bitmap_.IsSet(APHash(ptr, length) % capacity_)) {
return false;
}
if (!bitmap_.IsSet(JSHash(ptr, length) % capacity_)) {
return false;
}
return true;
}
size_t BloomFilter::BKDRHash(const char *str, size_t length) {
size_t hash = 0;
for (size_t i = 0; i < length; ++i) {
hash = hash * 131 + str[i];
}
return hash;
}
size_t BloomFilter::SDBMHash(const char *str, size_t length) {
size_t hash = 0;
for (size_t i = 0; i < length; ++i) {
hash = 65599 * hash + str[i];
}
return hash;
}
size_t BloomFilter::RSHash(const char *str, size_t length) {
size_t hash = 0;
size_t magic = 63689;
for (size_t i = 0; i < length; ++i) {
hash = hash * magic + str[i];
magic *= 378551;
}
return hash;
}
size_t BloomFilter::APHash(const char *str, size_t length) {
size_t hash = 0;
for (size_t i = 0; i < length; ++i) {
if ((i & 1) == 0) {
hash ^= ((hash << 7) ^ str[i] ^ (hash >> 3));
} else {
hash ^= (~((hash << 11) ^ str[i] ^ (hash >> 5)));
}
}
return hash;
}
size_t BloomFilter::JSHash(const char *str, size_t length) {
if (length == 0) {
return 0;
}
size_t hash = 1315423911;
for (size_t i = 0; i < length; ++i) {
hash ^= ((hash << 5) + str[i] + (hash >> 2));
}
return hash;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号