
爬取豆瓣电影TOP250
一.主题式网络主题式网络爬虫设计方案
1.主题式网络爬虫名称:爬取豆瓣电影 Top 250 数据
2.主题式网络爬虫爬取的内容:爬取电影排名,电影评分,电影打分,电影评价人数
3.主题式网络爬虫设计方案概述:分析网页源代码,找出数据所在的标签,通过爬虫读取数据存入excel,对数据清洗分析
二、主题页面的结构特征分析
1.主题页面的结构和特征分析:
# <span property="v:itemreviewed">肖申克的救赎 The Shawshank Redemption</span>
# <a href="/celebrity/1047973/" rel="v:directedBy">弗兰克·德拉邦特</a>
# <a href="/celebrity/1054521/" rel="v:starring">蒂姆·罗宾斯</a>
2.Htmls页面解析:
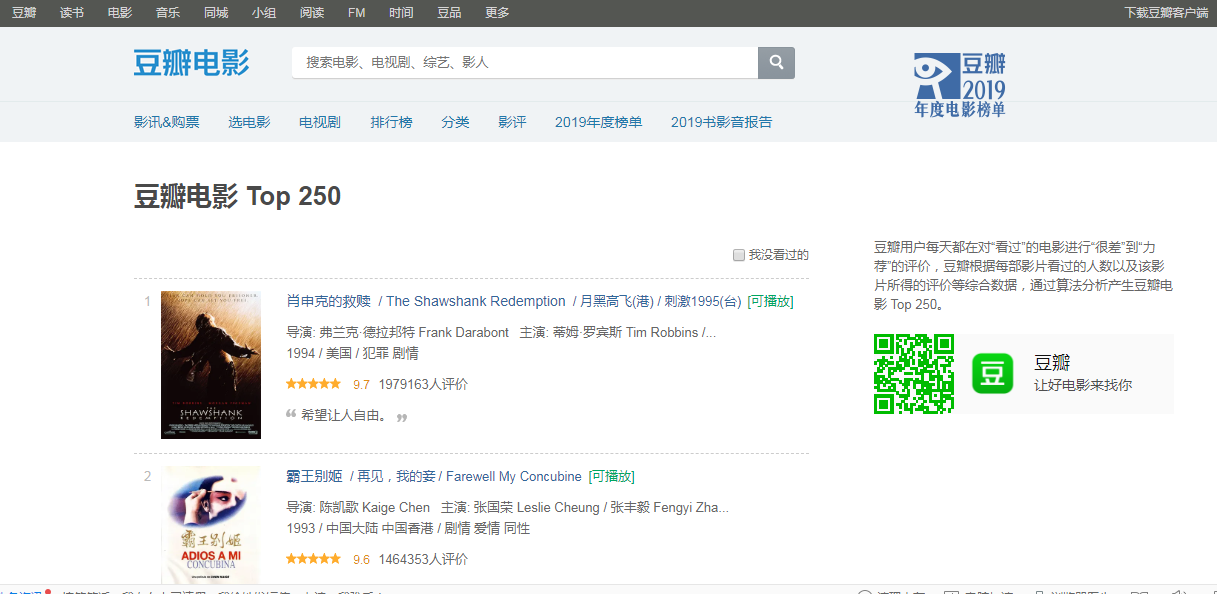
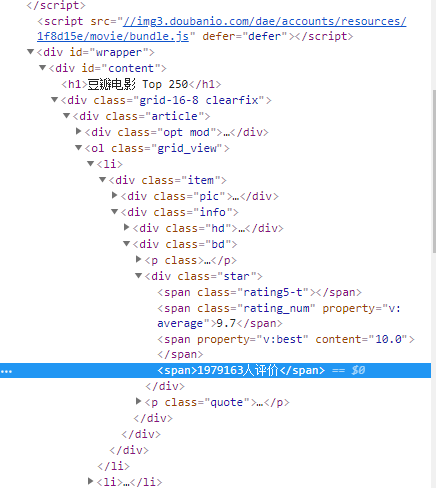
3.节点标签:爬取数据都分布在标签'<ol class="grid_view">'里,电影名标签为'span.title',电影星级标签'span.rating5-t',电影评分标签为'span.rating_num'及电影评价人数
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
1.数据爬取与采集(20)
2.对数据进行清洗和处理(10)
3.文本分析
import requests
from bs4 import BeautifulSoup
import pandas as pd
#构造分页数字列表
page_index = range(0, 250, 25)
list(page_indexs)
def download_all_htmls():
"""
下载所有列表页面的HTML,用于后续的分析
"""
htmls = []
for idx in page_indexs:
url = f"https://movie.douban.com/top250?start={idx}&filter="
print("craw html:",url)
r = requests.get(url)
if r.status_code !=200:
raise Exception("error")
htmls.append(r.text)
return htmls
#执行爬取
htmls = dowmload_all_htmls()
html[0]
def parse_single_html(html):
soup = beautifulSoup(html,'html.parser')
article_items = (
soup.find("div",class_="article")
.find("ol",class_="grid_view")
.find_all("div",class_="item")
)
datas = []
for article_item in article_items:
rank = article_item.find("div",class_="pic").find("em").get_text()
info = article_item.find("div",class_="info")
title = info.find("div",class_="hd").find("span",class_="title").get_text()
stars = (
info.find("div",class_="bd")
.find("div",class_="star")
.find_all("span")
)
rating_star = stars[0]["class"][0]
rating_num = stars[1].get_text()
comment = stars[3].get_text()
datas.append({
"rank":rank,
"title":title,
"rating_star":rating_star.replace("rating","").replace("-t","")
"rating_num":rating_num,
"comments":comments.replace("人评价","")
})
return datas
import pprint
pprint.pprint(parse_single_html(htmls[0]))
#执行所有的HTML页面的解析
all_datas = []
for html in htmls:
all_datas.extend(parse_single_html(html))
all_datas
#检查长度
len(all_datas)
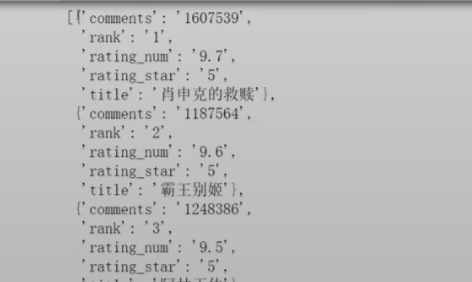
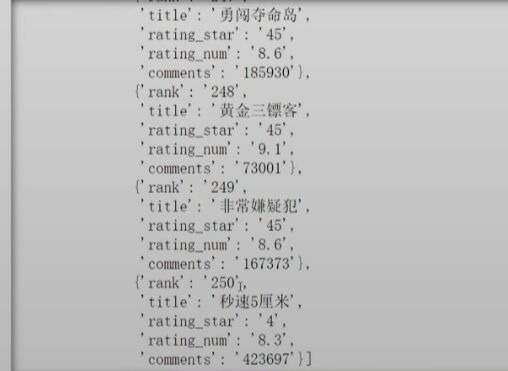
df = pd.DataFrame(all_datas)
df.head()
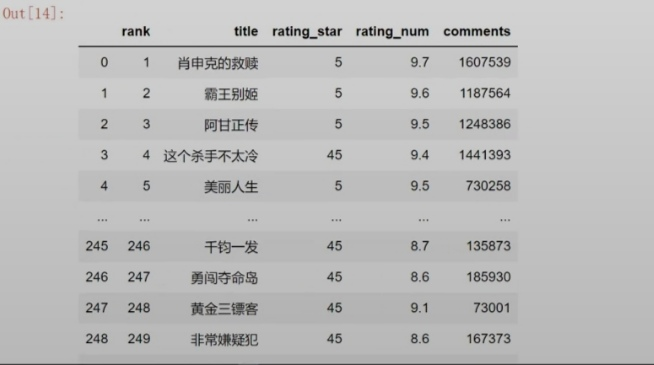
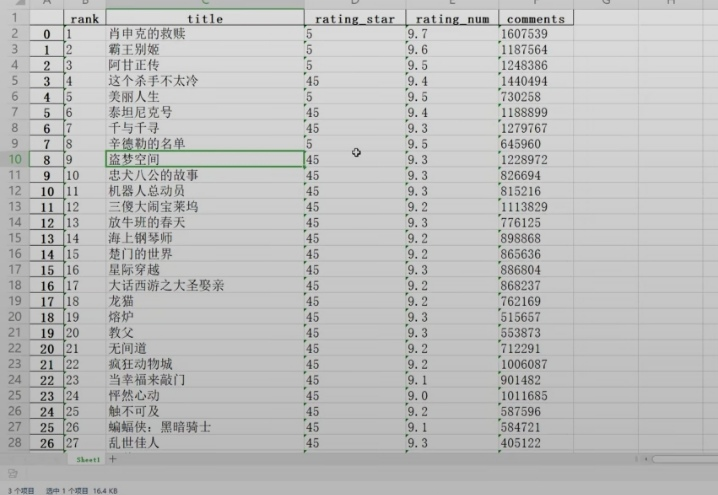
df.to_excel("豆瓣电影TOP250.xlsx")
4 .数据分析与可视化:
对数据进行分析
X = df.drop("电影名",axis=1)
predict_model = LinearRegression()
predict_model.fit(X,df['评分'])
print("回归系数为:",predict_model.coef_)
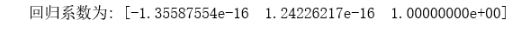
# 绘制散点图
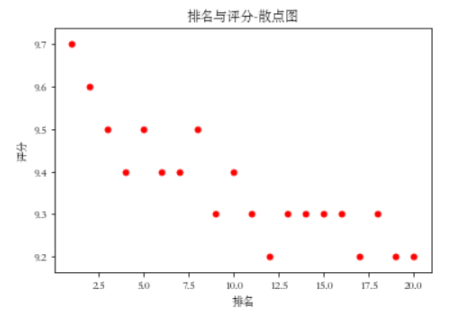
def Scatter_point():
plt.scatter(df.排名, df.评分, color='red', s=25, marker="o")
plt.xlabel("排名")
plt.ylabel("评分")
plt.title("排名与评分-散点图")
plt.show()
Scatter_point()
#线性图
sns.lmplot(x='score',y='Numbers',data=df)
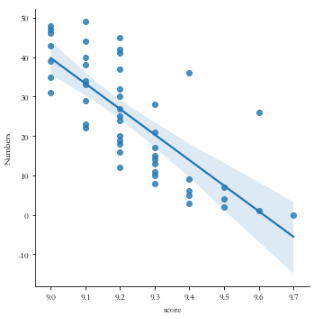
#绘制分布图
sns.jointplot(x="排名",y='评分',data = df, kind='reg')
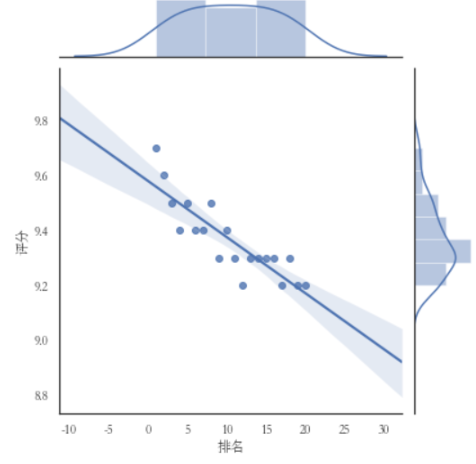
5.根据数据之间的关系,分析两个变量之间的相关系数,画出散点图,并建立变量之间的回归方程(一元或多元)(10分)。
#绘制一元一次回归方程
def main():
colnames = ["排名", "电影名", "评分", "评价人数"]
df = pd.read_csv('豆瓣电影排名评分数据.csv',skiprows=1,names=colnames)
X = df.排名
Y = df.评分
def func(p, x):
k, b = p
return k * x + b
def error_func(p, x, y):
return func(p,x)-y
p0 = [0,0]
Para = leastsq(error_func, p0, args = (X, Y))
k, b = Para[0]
print("k=",k,"b=",b)
plt.figure(figsize=(10,6))
plt.scatter(X,Y,color="green",label=u"评分分布",linewidth=2)
x=np.linspace(0,30,20)
y=k*x+b
plt.plot(x,y,color="red",label=u"回归方程直线",linewidth=2)
plt.title("电影排名和评分关系图")
plt.xlabel('排名')
plt.ylabel('评分')
plt.legend()
plt.show()
main()
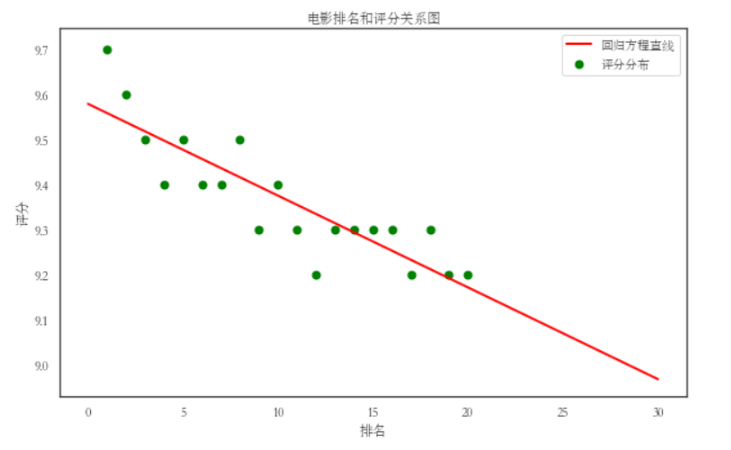
7.将以上各部分的代码汇总,附上完整程序代码:
import requests
from bs4 import BeautifulSoup
import pandas as pd
#构造分页数字列表
page_index = range(0, 250, 25)
list(page_indexs)
def download_all_htmls():
"""
下载所有列表页面的HTML,用于后续的分析
"""
htmls = []
for idx in page_indexs:
url = f"https://movie.douban.com/top250?start={idx}&filter="
print("craw html:",url)
r = requests.get(url)
if r.status_code !=200:
raise Exception("error")
htmls.append(r.text)
return htmls
#执行爬取
htmls = dowmload_all_htmls()
html[0]
def parse_single_html(html):
soup = beautifulSoup(html,'html.parser')
article_items = (
soup.find("div",class_="article")
.find("ol",class_="grid_view")
.find_all("div",class_="item")
)
datas = []
for article_item in article_items:
rank = article_item.find("div",class_="pic").find("em").get_text()
info = article_item.find("div",class_="info")
title = info.find("div",class_="hd").find("span",class_="title").get_text()
stars = (
info.find("div",class_="bd")
.find("div",class_="star")
.find_all("span")
)
rating_star = stars[0]["class"][0]
rating_num = stars[1].get_text()
comment = stars[3].get_text()
datas.append({
"rank":rank,
"title":title,
"rating_star":rating_star.replace("rating","").replace("-t","")
"rating_num":rating_num,
"comments":comments.replace("人评价","")
})
return datas
import pprint
pprint.pprint(parse_single_html(htmls[0]))
#执行所有的HTML页面的解析
all_datas = []
for html in htmls:
all_datas.extend(parse_single_html(html))
all_datas
#检查长度
len(all_datas)
df = pd.DataFrame(all_datas)
df.head()
df.to_excel("豆瓣电影TOP250.xlsx")
X = df.drop("电影名",axis=1)
predict_model = LinearRegression()
predict_model.fit(X,df['评分'])
print("回归系数为:",predict_model.coef_)
def Scatter_point():
plt.scatter(df.排名, df.评分, color='red', s=25, marker="o")
plt.xlabel("排名")
plt.ylabel("评分")
plt.title("排名与评分-散点图")
plt.show()
Scatter_point()
#线性图
sns.lmplot(x='score',y='Numbers',data=df)
#绘制分布图
sns.jointplot(x="排名",y='评分',data = df, kind='reg')
#绘制一元一次回归方程
def main():
colnames = ["排名", "电影名", "评分", "评价人数"]
df = pd.read_csv('豆瓣电影排名评分数据.csv',skiprows=1,names=colnames)
X = df.排名
Y = df.评分
def func(p, x):
k, b = p
return k * x + b
def error_func(p, x, y):
return func(p,x)-y
p0 = [0,0]
Para = leastsq(error_func, p0, args = (X, Y))
k, b = Para[0]
print("k=",k,"b=",b)
plt.figure(figsize=(10,6))
plt.scatter(X,Y,color="green",label=u"评分分布",linewidth=2)
x=np.linspace(0,30,20)
y=k*x+b
plt.plot(x,y,color="red",label=u"回归方程直线",linewidth=2)
plt.title("电影排名和评分关系图")
plt.xlabel('排名')
plt.ylabel('评分')
plt.legend()
plt.show()
四、结论(10分)
1.结论:通过这次Python作业让我能够更熟悉的去掌握爬虫,对数据网页进行分析,可视化能够更加直观的去了解到数据。
2.小结:做了作业才知道自己有这么多不足,听完课后不去实操是很难发现自己的漏洞,听课听懂了但是不自己去动手,过了几天也不会操作,那不是正在意义上的学会。最后通过这次作业发现自己有太多的不足 课后积极弥补希望今后在老师的带领下继续前进。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号