
随笔写一个简单的爬虫
目标:爬取damai网上即将上演的信息
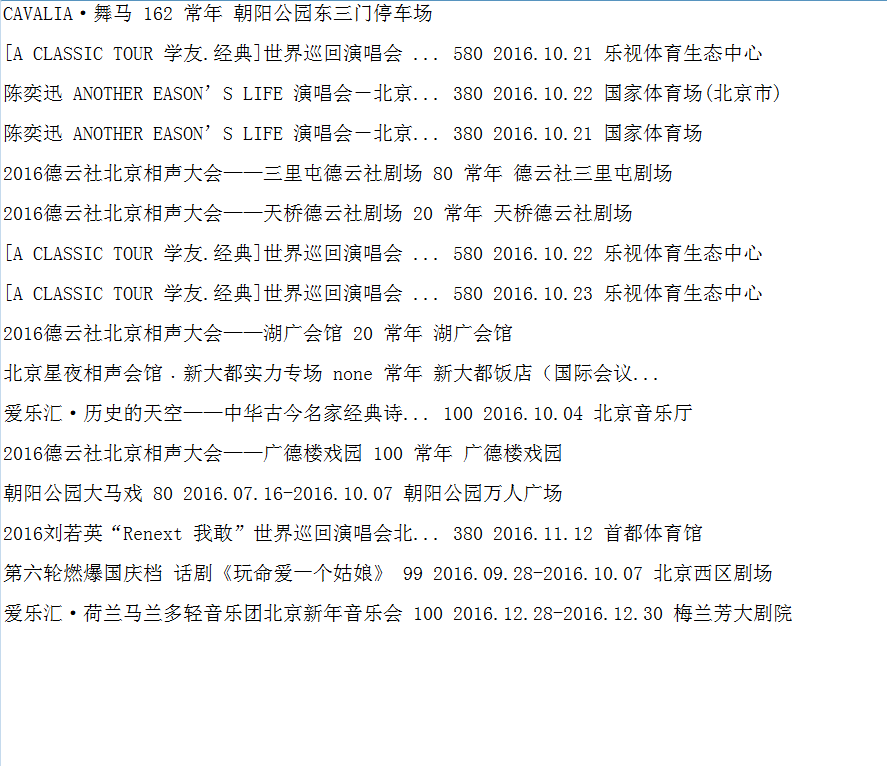
1 #!/usr/bin/python 2 # -*- coding: utf-8 -*- 3 4 import requests, re 5 from bs4 import BeautifulSoup 6 7 DOWNLOAD_URL = "http://www.damai.cn/bj/" 8 9 #获取url页面内容 10 def download_page(url): 11 headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ' 12 'Chrome/51.0.2704.63 Safari/537.36'} 13 data = requests.get(url, headers = headers).content 14 return data 15 #解析html 16 def x_page(url): 17 soup = BeautifulSoup(url, 'html.parser') 18 li_lst = soup.find('div', class_='index-con').next_sibling.next_sibling.find_all('li') 19 titles = [i.find('dt').find('a').string for i in li_lst] 20 prices = map(lambda x: x.find('p',class_='price').find('strong').text if x.find('p',class_='price').find('strong') is not None else 'none',li_lst) 21 time = [i.find('p',class_='time').string for i in li_lst] 22 places = [i.find('p',class_='place').string for i in li_lst] 23 return titles,prices,time,places 24 25 if __name__ == '__main__': 26 url = download_page(DOWNLOAD_URL) 27 titles, prices, time, places = x_page(url) 28 info_lst = zip(titles,prices,time,places) 29 #写入文件 30 with open('damai.txt','w+') as f: 31 for j in info_lst: 32 f.write(' '.join(j)+'\r\n\r\n')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号