物理内存的访问(翻译)
2014-09-16 11:35 付哲 阅读(905) 评论(1) 收藏 举报尝试理解复杂的系统时,你经常能通过去掉抽象层而直接看底层中学到很多东西。本着这种情况,我们从最简单最基本的层面看内存和I/O端口:处理器和总线间的接口。这些细节构成了更高层的概念,如Core i7对线程同步的需求。当然,作为一名程序员,我会忽略掉只有电子工程的人才会关心的东西(电路结构)。再看一下我们的朋友Core2:
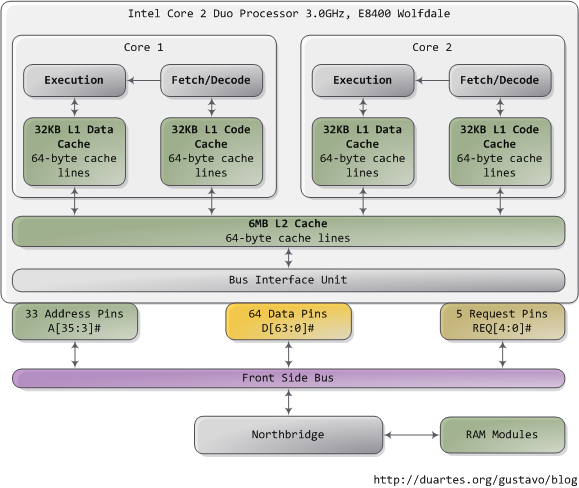
一颗Core2有775根管脚,其中有一半只供电,不用于数据传输。一旦你将这些管脚按功能分好组,处理器的物理接口看起来惊人的简单。上图显示了与内存或I/O操作有关的关键管脚:地址线、数据管脚和请求管脚。这些操作是作为前端总线(FSB)事务的一部分存在的。前端总线事务分为5个阶段:仲裁、请求、解码、回应和数据。纵观各阶段,FSB的各组件发挥着不同的作用,又称为代理。通常代理就是全部处理器加上北桥芯片。
这里我们只关注请求阶段,该阶段的请求代理(通常是处理器)会输出2个包。下面是第1个包里最重要的一些位,它们通过地址和请求管脚输出:
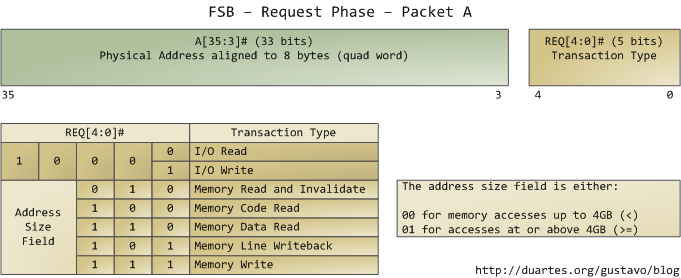
地址线输出事务的起始物理内存地址。这个地址需要33位,但它占据的却是3-35位(而不是0-32位),0-2位都是0。于是我们得到了一个36位的地址,按8字节对齐,可以寻址64GB的物理内存。这就是Pentium Pro的场景。请求管脚指定了事务被初始化成什么类型。对于I/O请求,地址线指定了一个I/O端口,而不是内存地址。在输出完第一个包后,相同的管脚会在接下来的总线周期内传输第2个包:
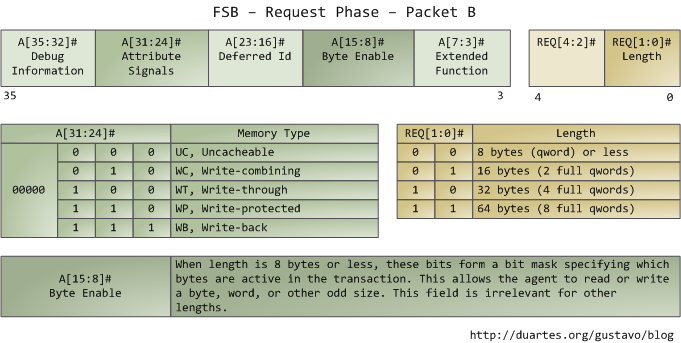
特征信号(attribute signal)很有趣:它们反映了Intel处理器中的5种内存缓存行为。请求代码将特征信号放到FSB上,这样其它处理器就知道这个事务会如何影响它们的缓存,以及内存控制器(北桥)该表现成什么样。处理器主要通过查看内核维护的页表来决定指定内存区域的类型。
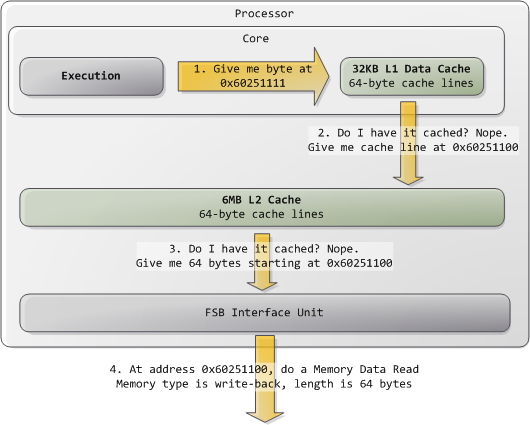
通常来说内核会将所有RAM内存视为写回(write-back)模式,目的是达到最佳性能。写回模式下内存访问的单位是缓存线(cache line),在Core 2上是64字节。程序读内存中的1个字节,处理器也会将整个缓存线的内容载入到L2和L1缓存中。当程序写内存时,处理器只修改缓存中对应的缓存线,而不会直接修改主存。随后在需要将修改后的内容写回主存时,每个缓存线会被一次写回。所以大多数请求的长度域都是11,代表64位。下面是读不在缓存中的数据的一个示例:
Intel机器上一些物理内存区段被映射为设备,像硬盘和网卡。驱动程序就可以直接读写内存来与它们的设备通信。内核在页表中将这些内存区标记为不可缓存。对不可缓存的内存区的访问会被完全复制到总线上(而不会访问缓存)。这种场景中我们可以读写任意大小的数据(不受缓存线的限制)。参见上面的packet B。
上面讨论的基本原理有许多实际影响。例如:
- 性能敏感的程序应该将总是同时访问的数据放到相同的缓存线中。一旦缓存线被载入缓存,后续的读会更快,也能避免额外的RAM访问。
- 落入单个缓存线的任何内存访问都保证是原子的(假设是写回模式)。特别是不跨缓存线的32位和64位操作都是原子的。
- 所有代理共享前端总线,因此它们在开始一个事务前要对总线的所有权进行裁决。此外,每个代理都要监听所有事务,来保证缓存一致性。因此在更多核的机器上总线竞争变成了一个很严重的问题。Core i7的解决方案是处理器直接访问内存,互相之间进行点对点的通信,而不是广播。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号