
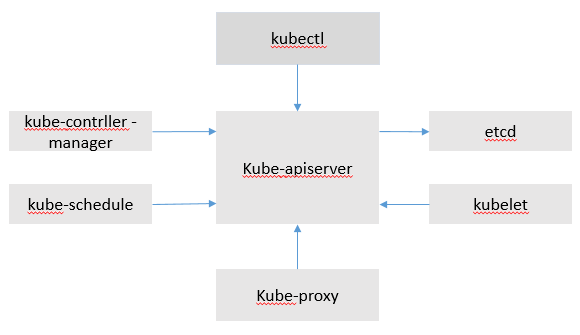
kubernetes核心组件kube-proxy
一. kube-proxy 和 service
kube-proxy是Kubernetes的核心组件,部署在每个Node节点上,它是实现Kubernetes Service的通信与负载均衡机制的重要组件; kube-proxy负责为Pod创建代理服务,从apiserver获取所有server信息,并根据server信息创建代理服务,实现server到Pod的请求路由和转发,从而实现K8s层级的虚拟转发网络。
在k8s中,提供相同服务的一组pod可以抽象成一个service,通过service提供的统一入口对外提供服务,每个service都有一个虚拟IP地址(VIP)和端口号供客户端访问。kube-proxy存在于各个node节点上,主要用于Service功能的实现,具体来说,就是实现集群内的客户端pod访问service,或者是集群外的主机通过NodePort等方式访问service。在当前版本的k8s中,kube-proxy默认使用的是iptables模式,通过各个node节点上的iptables规则来实现service的负载均衡,但是随着service数量的增大,iptables模式由于线性查找匹配、全量更新等特点,其性能会显著下降。从k8s的1.8版本开始,kube-proxy引入了IPVS模式,IPVS模式与iptables同样基于Netfilter,但是采用的hash表,因此当service数量达到一定规模时,hash查表的速度优势就会显现出来,从而提高service的服务性能。
kube-proxy负责为Service提供cluster内部的服务发现和负载均衡,它运行在每个Node计算节点上,负责Pod网络代理, 它会定时从etcd服务获取到service信息来做相应的策略,维护网络规则和四层负载均衡工作。在K8s集群中微服务的负载均衡是由Kube-proxy实现的,它是K8s集群内部的负载均衡器,也是一个分布式代理服务器,在K8s的每个节点上都有一个,这一设计体现了它的伸缩性优势,需要访问服务的节点越多,提供负载均衡能力的Kube-proxy就越多,高可用节点也随之增多。
service是一组pod的服务抽象,相当于一组pod的LB,负责将请求分发给对应的pod。service会为这个LB提供一个IP,一般称为cluster IP。kube-proxy的作用主要是负责service的实现,具体来说,就是实现了内部从pod到service和外部的从node port向service的访问。
简单来说:
-> kube-proxy其实就是管理service的访问入口,包括集群内Pod到Service的访问和集群外访问service。
-> kube-proxy管理sevice的Endpoints,该service对外暴露一个Virtual IP,也成为Cluster IP, 集群内通过访问这个Cluster IP:Port就能访问到集群内对应的serivce下的Pod。
-> service是通过Selector选择的一组Pods的服务抽象,其实就是一个微服务,提供了服务的LB和反向代理的能力,而kube-proxy的主要作用就是负责service的实现。
-> service另外一个重要作用是,一个服务后端的Pods可能会随着生存灭亡而发生IP的改变,service的出现,给服务提供了一个固定的IP,而无视后端Endpoint的变化。
举个例子,比如现在有podA,podB,podC和serviceAB。serviceAB是podA,podB的服务抽象(service)。那么kube-proxy的作用就是可以将pod(不管是podA,podB或者podC)向serviceAB的请求,进行转发到service所代表的一个具体pod(podA或者podB)上。请求的分配方法一般分配是采用轮询方法进行分配。另外,kubernetes还提供了一种在node节点上暴露一个端口,从而提供从外部访问service的方式。比如这里使用这样的一个manifest来创建service
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
apiVersion: v1kind: Servicemetadata: labels: name: mysql role: service name: mysql-servicespec: ports: - port: 3306 targetPort: 3306 nodePort: 30964 type: NodePort selector: mysql-service: "true" |
上面配置的含义是在node上暴露出30964端口。当访问node上的30964端口时,其请求会转发到service对应的cluster IP的3306端口,并进一步转发到pod的3306端口。
Service, Endpoints与Pod的关系

Kube-proxy进程获取每个Service的Endpoints,实现Service的负载均衡功能
Service的负载均衡转发规则
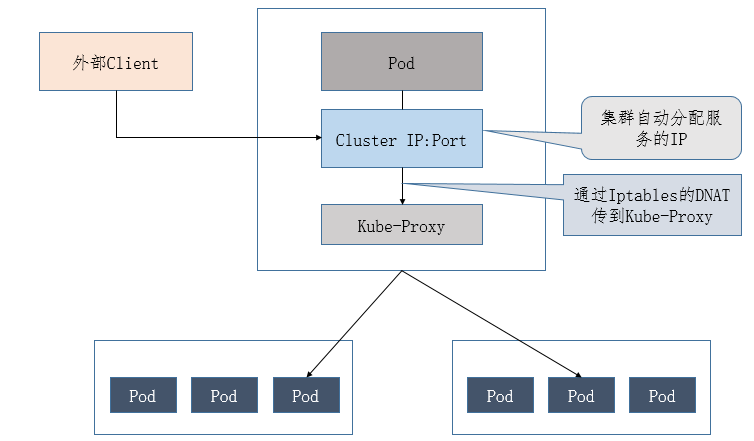
访问Service的请求,不论是Cluster IP+TargetPort的方式;还是用Node节点IP+NodePort的方式,都被Node节点的Iptables规则重定向到Kube-proxy监听Service服务代理端口。kube-proxy接收到Service的访问请求后,根据负载策略,转发到后端的Pod。
二. kubernetes服务发现
Kubernetes提供了两种方式进行服务发现, 即环境变量和DNS, 简单说明如下:
1) 环境变量: 当你创建一个Pod的时候,kubelet会在该Pod中注入集群内所有Service的相关环境变量。需要注意: 要想一个Pod中注入某个Service的环境变量,则必须Service要先比该Pod创建。这一点,几乎使得这种方式进行服务发现不可用。比如,一个ServiceName为redis-master的Service,对应的ClusterIP:Port为172.16.50.11:6379,则其对应的环境变量为:
|
1
2
3
4
5
6
7
|
REDIS_MASTER_SERVICE_HOST=172.16.50.11REDIS_MASTER_SERVICE_PORT=6379REDIS_MASTER_PORT=tcp://172.16.50.11:6379REDIS_MASTER_PORT_6379_TCP=tcp://172.16.50.11:6379REDIS_MASTER_PORT_6379_TCP_PROTO=tcpREDIS_MASTER_PORT_6379_TCP_PORT=6379REDIS_MASTER_PORT_6379_TCP_ADDR=172.16.50.11 |
2) DNS:这是k8s官方强烈推荐的方式!!! 可以通过cluster add-on方式轻松的创建KubeDNS来对集群内的Service进行服务发现。
三. kubernetes发布(暴露)服务
kubernetes原生的,一个Service的ServiceType决定了其发布服务的方式。
-> ClusterIP:这是k8s默认的ServiceType。通过集群内的ClusterIP在内部发布服务。
-> NodePort:这种方式是常用的,用来对集群外暴露Service,你可以通过访问集群内的每个NodeIP:NodePort的方式,访问到对应Service后端的Endpoint。
-> LoadBalancer: 这也是用来对集群外暴露服务的,不同的是这需要Cloud Provider的支持,比如AWS等。
-> ExternalName:这个也是在集群内发布服务用的,需要借助KubeDNS(version >= 1.7)的支持,就是用KubeDNS将该service和ExternalName做一个Map,KubeDNS返回一个CNAME记录。
四. kube-proxy 工作原理 (userspace, iptables, ipvs)
kube-proxy当前实现了三种代理模式:userspace, iptables, ipvs。其中userspace
mode是v1.0及之前版本的默认模式,从v1.1版本中开始增加了iptables
mode,在v1.2版本中正式替代userspace模式成为默认模式。也就是说kubernetes在v1.2版本之前是默认模式,
v1.2版本之后默认模式是iptables。
1) userspace mode: userspace是在用户空间,通过kube-proxy来实现service的代理服务, 其原理如下:
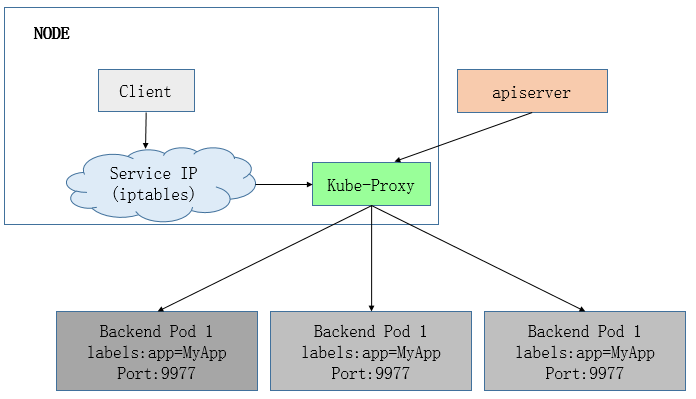
可见,userspace这种mode最大的问题是,service的请求会先从用户空间进入内核iptables,然后再回到用户空间,由kube-proxy完成后端Endpoints的选择和代理工作,这样流量从用户空间进出内核带来的性能损耗是不可接受的。这也是k8s v1.0及之前版本中对kube-proxy质疑最大的一点,因此社区就开始研究iptables mode.
userspace这种模式下,kube-proxy 持续监听 Service 以及 Endpoints 对象的变化;对每个 Service,它都为其在本地节点开放一个端口,作为其服务代理端口;发往该端口的请求会采用一定的策略转发给与该服务对应的后端 Pod 实体。kube-proxy 同时会在本地节点设置 iptables 规则,配置一个 Virtual IP,把发往 Virtual IP 的请求重定向到与该 Virtual IP 对应的服务代理端口上。其工作流程大体如下:
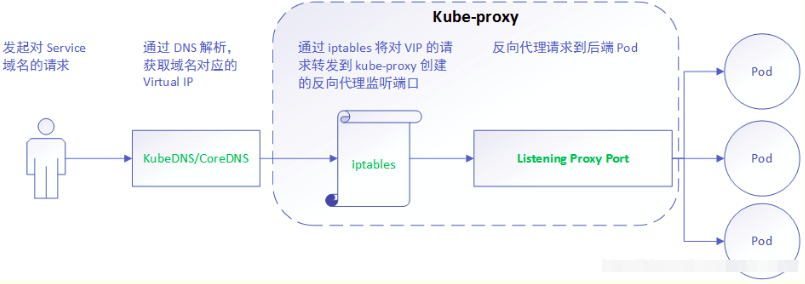
由此分析: 该模式请求在到达 iptables 进行处理时就会进入内核,而 kube-proxy 监听则是在用户态, 请求就形成了从用户态到内核态再返回到用户态的传递过程, 一定程度降低了服务性能。
2) iptables mode, 该模式完全利用内核iptables来实现service的代理和LB, 这是K8s在v1.2及之后版本默认模式. 工作原理如下:
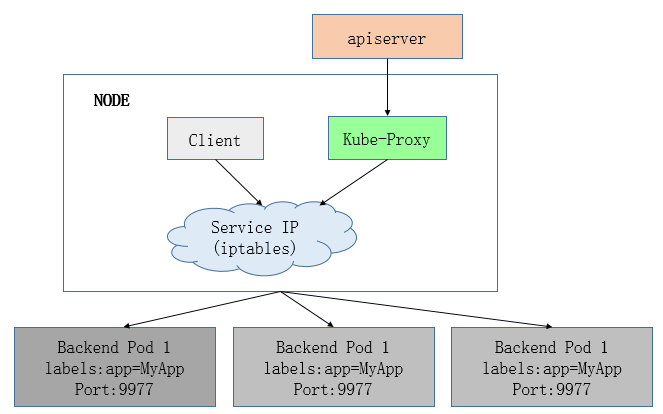
iptables mode因为使用iptable NAT来完成转发,也存在不可忽视的性能损耗。另外,如果集群中存在上万的Service/Endpoint,那么Node上的iptables rules将会非常庞大,性能还会再打折扣。这也导致目前大部分企业用k8s上生产时,都不会直接用kube-proxy作为服务代理,而是通过自己开发或者通过Ingress Controller来集成HAProxy, Nginx来代替kube-proxy。
iptables 模式与 userspace 相同,kube-proxy 持续监听 Service 以及 Endpoints 对象的变化;但它并不在本地节点开启反向代理服务,而是把反向代理全部交给 iptables 来实现;即 iptables 直接将对 VIP 的请求转发给后端 Pod,通过 iptables 设置转发策略。其工作流程大体如下:
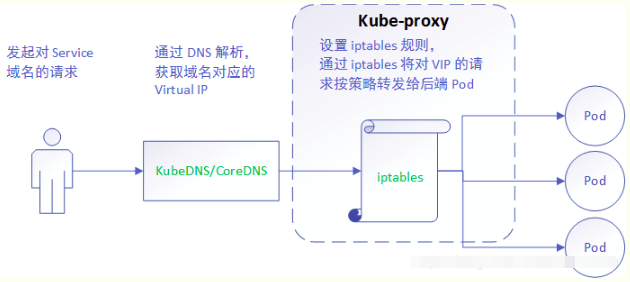
由此分析: 该模式相比 userspace 模式,克服了请求在用户态-内核态反复传递的问题,性能上有所提升,但使用 iptables NAT 来完成转发,存在不可忽视的性能损耗,而且在大规模场景下,iptables 规则的条目会十分巨大,性能上还要再打折扣。
iptables的方式则是利用了linux的iptables的nat转发进行实现:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
apiVersion: v1kind: Servicemetadata: labels: name: mysql role: service name: mysql-servicespec: ports: - port: 3306 targetPort: 3306 nodePort: 30964 type: NodePort selector: mysql-service: "true" |
mysql-service对应的nodePort暴露出来的端口为30964,对应的cluster IP(10.254.162.44)的端口为3306,进一步对应于后端的pod的端口为3306。 mysql-service后端代理了两个pod,ip分别是192.168.125.129和192.168.125.131, 这里先来看一下iptables:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
$iptables -S -t nat...-A PREROUTING -m comment --comment "kubernetes service portals" -j KUBE-SERVICES-A OUTPUT -m comment --comment "kubernetes service portals" -j KUBE-SERVICES-A POSTROUTING -m comment --comment "kubernetes postrouting rules" -j KUBE-POSTROUTING-A KUBE-MARK-MASQ -j MARK --set-xmark 0x4000/0x4000-A KUBE-NODEPORTS -p tcp -m comment --comment "default/mysql-service:" -m tcp --dport 30964 -j KUBE-MARK-MASQ-A KUBE-NODEPORTS -p tcp -m comment --comment "default/mysql-service:" -m tcp --dport 30964 -j KUBE-SVC-67RL4FN6JRUPOJYM-A KUBE-SEP-ID6YWIT3F6WNZ47P -s 192.168.125.129/32 -m comment --comment "default/mysql-service:" -j KUBE-MARK-MASQ-A KUBE-SEP-ID6YWIT3F6WNZ47P -p tcp -m comment --comment "default/mysql-service:" -m tcp -j DNAT --to-destination 192.168.125.129:3306-A KUBE-SEP-IN2YML2VIFH5RO2T -s 192.168.125.131/32 -m comment --comment "default/mysql-service:" -j KUBE-MARK-MASQ-A KUBE-SEP-IN2YML2VIFH5RO2T -p tcp -m comment --comment "default/mysql-service:" -m tcp -j DNAT --to-destination 192.168.125.131:3306-A KUBE-SERVICES -d 10.254.162.44/32 -p tcp -m comment --comment "default/mysql-service: cluster IP" -m tcp --dport 3306 -j KUBE-SVC-67RL4FN6JRUPOJYM-A KUBE-SERVICES -m comment --comment "kubernetes service nodeports; NOTE: this must be the last rule in this chain" -m addrtype --dst-type LOCAL -j KUBE-NODEPORTS-A KUBE-SVC-67RL4FN6JRUPOJYM -m comment --comment "default/mysql-service:" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-ID6YWIT3F6WNZ47P-A KUBE-SVC-67RL4FN6JRUPOJYM -m comment --comment "default/mysql-service:" -j KUBE-SEP-IN2YML2VIFH5RO2T |
首先如果是通过node的30964端口访问,则会进入到以下链:
|
1
2
|
-A KUBE-NODEPORTS -p tcp -m comment --comment "default/mysql-service:" -m tcp --dport 30964 -j KUBE-MARK-MASQ-A KUBE-NODEPORTS -p tcp -m comment --comment "default/mysql-service:" -m tcp --dport 30964 -j KUBE-SVC-67RL4FN6JRUPOJYM |
然后进一步跳转到KUBE-SVC-67RL4FN6JRUPOJYM的链:
|
1
2
|
-A KUBE-SVC-67RL4FN6JRUPOJYM -m comment --comment "default/mysql-service:" -m statistic --mode random --probability 0.50000000000 -j KUBE-SEP-ID6YWIT3F6WNZ47P-A KUBE-SVC-67RL4FN6JRUPOJYM -m comment --comment "default/mysql-service:" -j KUBE-SEP-IN2YML2VIFH5RO2T |
这里利用了iptables的–probability的特性,使连接有50%的概率进入到KUBE-SEP-ID6YWIT3F6WNZ47P链,50%的概率进入到KUBE-SEP-IN2YML2VIFH5RO2T链。 KUBE-SEP-ID6YWIT3F6WNZ47P的链的具体作用就是将请求通过DNAT发送到192.168.125.129的3306端口:
|
1
2
|
-A KUBE-SEP-ID6YWIT3F6WNZ47P -s 192.168.125.129/32 -m comment --comment "default/mysql-service:" -j KUBE-MARK-MASQ-A KUBE-SEP-ID6YWIT3F6WNZ47P -p tcp -m comment --comment "default/mysql-service:" -m tcp -j DNAT --to-destination 192.168.125.129:3306 |
同理KUBE-SEP-IN2YML2VIFH5RO2T的作用是通过DNAT发送到192.168.125.131的3306端口:
|
1
2
|
-A KUBE-SEP-IN2YML2VIFH5RO2T -s 192.168.125.131/32 -m comment --comment "default/mysql-service:" -j KUBE-MARK-MASQ-A KUBE-SEP-IN2YML2VIFH5RO2T -p tcp -m comment --comment "default/mysql-service:" -m tcp -j DNAT --to-destination 192.168.125.131:3306 |
分析完nodePort的工作方式,接下里说一下clusterIP的访问方式。 对于直接访问cluster IP(10.254.162.44)的3306端口会直接跳转到KUBE-SVC-67RL4FN6JRUPOJYM
|
1
|
-A KUBE-SERVICES -d 10.254.162.44/32 -p tcp -m comment --comment "default/mysql-service: cluster IP" -m tcp --dport 3306 -j KUBE-SVC-67RL4FN6JRUPOJYM |
接下来的跳转方式同NodePort方式。
3) ipvs mode. 在kubernetes 1.8以上的版本中,对于kube-proxy组件增加了除iptables模式和用户模式之外还支持ipvs模式。kube-proxy ipvs 是基于 NAT 实现的,通过ipvs的NAT模式,对访问k8s service的请求进行虚IP到POD IP的转发。当创建一个 service 后,kubernetes 会在每个节点上创建一个网卡,同时帮你将 Service IP(VIP) 绑定上,此时相当于每个 Node 都是一个 ds,而其他任何 Node 上的 Pod,甚至是宿主机服务(比如 kube-apiserver 的 6443)都可能成为 rs;
与iptables、userspace 模式一样,kube-proxy 依然监听Service以及Endpoints对象的变化, 不过它并不创建反向代理, 也不创建大量的 iptables 规则, 而是通过netlink 创建ipvs规则,并使用k8s Service与Endpoints信息,对所在节点的ipvs规则进行定期同步; netlink 与 iptables 底层都是基于 netfilter 钩子,但是 netlink 由于采用了 hash table 而且直接工作在内核态,在性能上比 iptables 更优。其工作流程大体如下:
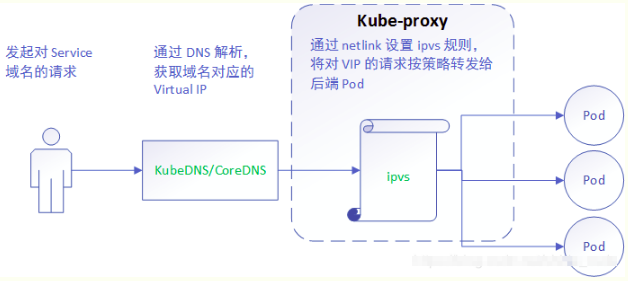
由此分析:ipvs 是目前 kube-proxy 所支持的最新代理模式,相比使用 iptables,使用 ipvs 具有更高的性能。
Endpoint访问外部服务
k8s访问集群外独立的服务最好的方式是采用Endpoint方式,以mysql服务为例:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
1)创建mysql-service.yaml[root@kevin~]# vim mysql-service.yamlapiVersion: v1kind: Servicemetadata: name: mysql-kevinspec: ports: - port: 33062) 创建mysql-endpoints.yaml[root@kevin~]# vim mysql-endpoints.yamlkind: EndpointsapiVersion: v1metadata: name: mysql-kevin namespace: defaultsubsets: - addresses: - ip: 172.16.60.55 ports: - port: 33063) 测试连接数据库[root@kevin~]# kubectl exec -it mysql-client-h7jk8 bashbash-4.1# mysql -hmysql-kevin -u user -pEnter password:.........mysql> 4) 查看这个service[root@kevin~]# kubectl describe svc mysql-kevinName: mysql-kevinNamespace: defaultLabels: <none>Annotations: <none>Selector: <none>Type: ClusterIPIP: 10.254.125.157Port: <unset> 3306/TCPEndpoints: 172.16.60.55:3306Session Affinity: NoneEvents: <none> |
下面简单说kube-proxy是如何实现一个请求经过层层转发最后落到某个pod上的整个过程,这个请求可能来自pod也可能来自外部。
-> kube-proxy为集群提供service功能,相同功能的pods对外抽象为service,service可以实现反向代理和服务发现。可以分为iptables模式和userspace模式。具体有iptables实现
-> 在反向代理方面,kube-proxy默认使用rr算法实现客户端流量分发到后端的pod
k8s的service和endpoine是如何关联和相互影响的?
-> api-server创建service对象,与service绑定的pod地址:称之为endpoints
-> 服务发现方面:kube-proxy监控service后端endpoint的动态变化,并且维护service和endpoint的映射关系
一个经典pod的完整生命周期
-> Pending
-> Running
-> Succeeded
-> Failed
关系流程图如下:
K8S Endpoint一会消失一会出现的问题
在使用K8s集群时遇到的问题:发现某个service的后端endpoint一会显示有后端,一会显示没有。显示没有后端,意味着后端的address被判定为notready。
经过排查确定原因:
kubelet在准备上报信息时,需要收集容器、镜像等的信息。虽然kubelet默认是10秒上报一次,但是实际的上报周期约为20~50秒。而kube-controller-manager判断node上报心跳超时的时间为40秒。所以会有一定概率超时。一旦超时,kube-controller会将该node上的所有pod的conditions中type是Ready的字典中的status置为False。
解决办法:
较为简单的方案是在kube-controller上配置这个超时时间node-monitor-grace-period长一些。建议配置为60 ~ 120s。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号