逻辑回归(Logistic Regression)
一、Sigmod函数
线性回归的假设函数:,但在分类问题中需要求输入范围在(0,1),则需要为分类问题寻找另外假设函数。
Sigmod函数式:
,函数值域(0,1)
函数图像
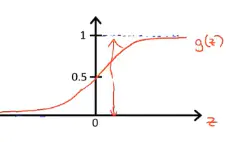
该函数具有很强的鲁棒性,并且将函数的输入范围(∞,-∞)映射到了输出的(0,1)之间且具有概率意义。将一个样本输入到我们学习到的函数中,输出0.7,意思就是这个样本有70%的概率是正例,1-70%就是30%的概率为负例。
所以将线性回归假设函数替换Sigmod函数自变量得:
,
表示预测为正例的概率,
,则
表示预测为负例的概率。
二、逻辑回归损失函数
单样本预测正确的概率:
此时我们需要一组𝜽,使所有样本预测正确的概率最大。根据最大似然估计,最大化似然函数求参数。
似然函数:
则:
为方便计算,似然函数两边同时取对数,可得:
通常我们习惯最小化损失函数,所以在前面加上符号可得交叉熵损失函数:
是关于
的高阶可导连续凸函数,根据梯度下降求解。
三、总结
逻辑回归属于广义的线性模型,并通过极大似然估计推导交叉熵损失函数,我们得到的参数值是所有样本被预测正确的概率最大时的参数值,因为所有样本被预测正确的概率更加依赖于多数类别的分类正确与否,然而实际业务情况中,我们常常其实更关注的是少数类别的分类正确情况。
所以认为逻辑回归对正负例样本不均衡比较敏感。
由于通常当y > 0.5 时,判定为正例,否则为负例,y代表正例的可能性,几率 y/1-y 反映正例可能性与负例可能性的比值,阈值为0.5表明分类器默认认为真实正反例可能性相同,即y/1-y > 1时,预测为正例。
但当存在类别不平衡时,m+为正例样本数,m-为负例样本数,我们应该认为分类器的预测几率高于观测几率应判定为正例,即 y/1-y > m+ / m-,则预测为正例,即是类别不平衡学习的基本策略-‘再缩放’。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号