

pivot与unpivot数据旋转
MS在其sqlserver2005中提供了关键字pivot与unpivot来旋转数据。pivot译为:轴,支点,绕着轴旋转。通过pivot可以实现将行数据转换为列,顾明思议unpivot就是执行相反的操作将列数据转换为行数据,当然这里的相反其实并不是完全的相反。看上去所谓的行转列,列转行挺抽象的,还是以具体实例来说明吧。
这里我们将会用到一个学生成绩表score(只为演示不考虑完整性)
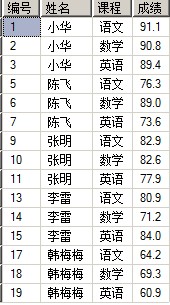
1、pivot是一种将行数据转换为列数据的技术。
对应上面学生成绩表,现在我们看到的是每个学生的各科成绩都通过一行来记录,现在假如我们希望对每个学生的成绩都通过一行记录来表示,如下形势

这就是所谓的将行数据转换为列数据,即将所有的课程以列名的形势列出,来统计结果。我们先不考虑什么pivot,用我们以前所知道的知识来处理。先来分析,这里我们对每个学生都对应一条记录,而原来的表中一个学生对应多条记录所以很明显先要分组group by,然后我们再看每个属性值都被当做一列,这里我们有3个属性值(语文,数学,英语)所以select也必须要3个表达式,当然加上最后还有一个姓名,所以常规的select 表达式我们可以写成
sum(case 课程 when '语文' then 成绩 end) as 语文,
sum(case 课程 when '数学' then 成绩 end) as 数学,
sum(case 课程 when '英语' then 成绩 end) as 英语
from score group by 姓名;
下面我们用pivot来实现
select * from (select 姓名,课程,成绩 from score) as a pivot(sum(成绩) for 课程 in([语文],[数学],[英语])) as b;
代码是不是短很多呢,但是其实pivot还是会进行分组操作,因为上面两种方式对数据库引擎来说基本没区别,不信你可以看看上面两种生成的执行计划 都是一样的,所以就无所谓来的效率的比较,你别指望pivot来为你带来效率的提升,只能说微软为了我们书写方面定义了一个pivot关键字来代替原来的写法。
另一方面我们看到上面的select 我们只取了3列 姓名,课程,成绩,如果我们带上编号会怎么呢,哈哈结果是:
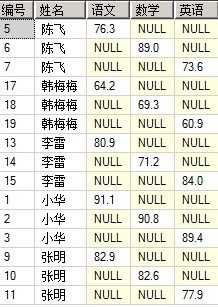
这看来应该不是我们所想要的结果吧,呼呼。
2、unpivot是一种能将列数据转换为行数据的技术
还是上面的那个例子,现在我们要将pivot的结果返回回去该怎么操作呢,即每一门课都对应与一行记录,我们也先用原始的技术来看看如何实现
假如pivot后的表为score2,我们可以这样写
when '数学' then 数学
when '英语' then 英语
end as 成绩
from score2,(select '语文' as 课程 union select '数学' union select '英语') as b order by 姓名;
如果用unpivot来实现我们写成
select 姓名,课程,成绩 from score2 unpivot(成绩 for 课程 in([语文],[数学],[英语])) as a;
是不是比原来的简单很多呢???

