分布式协议理论
CAP理论
指的是在一个分布式系统中,一致性,可用性,分区容错性,三者不可兼得
一致性C:在分布式系统中,数据在多个系统之间是否能够保证一致的特性,即某个系统数据变更后,其他系统能立刻读取最新值。
可用性A:系统提供的服务必须一直处于可用的状态,即对于用户的每个请求,系统总可以在有限时间内对用户做出响应。
分区容错性P:分布式系统在遇到任何网络分区故障时,仍能够保证对外提供满足一致性和可用性的服务。
CAP定理
对于分布式系统,网络环境相对是不可控的,出现网络分区是不可避免的,因此系统必须具备分区容错性。
但其并不能同时保证一致性与可用性。CAP理论对于一个分布式系统来说,只可能满足两项,即要么CP,要么AP。
Eureka:AP zookeeper:CP
zookeeper遵循的是CP原则,即保证了一致性,但牺牲了可用性。体现在哪里呢?
当Leader宕机后,zk集群会马上进行新的Leader的选举,但选举时长在30-200毫秒间,整个选举期间zk集群是不接受客户端的读写操作的
即zk集群是处于瘫痪状态的。所以,其不满足可用性。
BASE理论
指的是基本可用,软状态,最终一致性
核心思想:即使无法做到强一致性,但每个系统都可以根据自身的业务特点,采取适当方式使系统达到最终一致性。
基本可用:当分布式系统出现不可预见的故障时,允许损失部分可用性,保障系统的基本可用,体现在时间或功能上的损失
比如:部分用户双十一高峰期淘宝页面卡顿或降级处理
软状态:允许系统延时,不影响系统可用性。
比如:2306网站卖火车票,请求会进入排队队列
最终一致性:所有的数据在经过一段时间的数据同步后,最终能够达到一个一致的状态
比如:理财产品首页充值总金额短时不一致
二阶段提交(2PC)
两阶段提交算法:当一个事务操作需要跨多个节点时,为了保证事务处理的ACID特性,需要引入一个协调者来调度所有分布式节点的执行逻辑。并最终决定这些节点是否真正进行提交,因为整个事务是分为两个阶段提交,所以叫2PC。
它本身是一致强一致性算法,所以很适合用作数据库的分布式事务。其实数据库的经常用到的TCC本身就是一种2PC。
阶段一:提交事务请求
1:事务询问
协调者向所有的参与者发送事务预处理请求,并等待回应。
2.执行事务
各参与者节点执行本地事务操作,但不会真正提交事务,而是先向协调者反馈响应
3.反馈事务询问的响应
如果 参与者 成功执行了事务操作,那么就反馈给协调者 Yes 响应,表示事务可以执行,如果没有 参与者 成功执行事务,那么就反馈给协调者 No 响应,表示事务不可以执行。
第一阶段执行完后,会有两种可能。1、所有都返回Yes. 2、有一个或者多个返回No。
第二阶段:执行事务提交
在这个阶段协调者会根据各参与者的反馈情况来决定最终是否可以进行事务提交
所以分为两种情况
1.反馈yes
如果所有的参与者反馈给协调者的信息都是Yes,那么就会执行事务提交,则协调者向所有参与者节点发出Commit请求
2.事务提交
参与者 收到Commit请求之后,就会正式执行本地事务Commit操作,并在完成提交之后释放整个事务执行期间占用的事务资源。
or
1.反馈no或超时
某个参与者向协调者反馈了No响应,或者等待超时,协调者尚未收到所有参与者的反馈响应
2.事务回滚
协调者向所有参与者节点发出RollBack请求,参与者会回滚本地事务。
缺点
1)性能问题
这俩阶段所有的参与者资源和协调者资源都是被锁住的,只有当所有节点准备完毕,事务协调者才会通知进行全局提交,参与者进行本地事务提交后才会释放资源。
这样的过程会比较漫长,对性能影响比较大。
2)单节点故障
a:如果协调者发生故障。那么所有的参与者可能还都处于锁定事务资源的状态中,而无法继续完成事务操作。
解决方案:引入协调者备份,同时协调者需记录操作日志.当检测到协调者宕机一段时间后,协调者备份取代协调者,并读取操作日志,向所有参与者询问状态。
b:参与者宕机,那么协调者无法收集到所有参与者的反馈,会陷入阻塞情况
解决方案:引入超时机制,如果协调者在超过指定的时间还没有收到参与者的反馈,事务就失败,向所有节点发送终止事务请求。
三阶段提交(3PC)
主要是为了解决2PC协调者崩溃时的阻塞问题,2PC的改进版
1、引入超时机制。同时在协调者和参与者中都引入超时机制。
2、在第一阶段和第二阶段中插入一个准备阶段。保证了在最后提交阶段之前各参与节点的状态是一致的。
- 第一阶段canCommit
确认所有的资源是否都是健康、在线的,是否可以执行事务提交操作。
这阶段主要分为2步
事务询问 协调者向参与者发送CanCommit请求。询问是否可以执行事务提交操作,然后开始等待参与者的响应。
响应反馈 参与者接到CanCommit请求之后,如果其自身认为可以顺利执行事务,则返回Yes响应,并进入预备状态,否则反馈No。 - 第二阶段PreCommit
如果所有的参与者都返回Yes的话,那么就会进入PreCommit阶段进行事务预提交。 - 第三阶段doCommit
跟2PC大同小异,不同的是,当协调者出现问题,没给资源发送commit指令时,能要求资源在一段时间超时后回默认提交做commit操作。
这样的要求就减少了前面说的单点故障,万一事务管理器出现问题,事务也回提交。
Paxos 算法
Paxos算法要解决的问题是,在分布式系统中如何就某个决议达成一致。
算法描述
(1) 三种角色
Proposer:提案者,提议者
Acceptor:表决者
Learners:学习者
(2)一致性
每个提议者在提出提案时,给提案获取一个在集群中,具有全局唯一性,递增的提案编号N。
每个表决者在收到提案后,将提案编号N记录在本地,这样表决者中,会存在一个编号最大的提案,其编号假设为maxN。表决者仅会 accept 编号大于自己本地maxN的提案。
在众多提案中最终只能有一个提案被选定,被选定后,其它服务器会主动同步(Learn)该提案到本地。
(3) 算法过程描述
Paxos 算法的执行过程划分为两个阶段:准备阶段prepare与接受阶段accept
A、prepare阶段
1)提议者提交编号N的提案时,先向所有表决者发送prepare(N)请求,用于试探集群是否支持该编号提议。
2)每个表决者都保存接收过提案中的最大编号maxN,接收其他提案请求时,会比较新提案的N和maxN的值,
a)若N小于maxN,则说明该提议已过时,当前表决者采取不回应,或回应Error的方式来拒绝该prepare请求;
b)若N大于maxN,则说明该提议可接受,当前表决者会将该N记录下来,并将其曾经已经接收的编号最大的提案反馈给提议者,
告知提议者展示自己支持的提案意愿。
B、accept 阶段
1)当提议者发送prepare(N)后,若收到超半数的表决者的反馈,那么该提议者就会将其真正的提案Proposal(myid,N,value)发送给所有的表决者。
2)当表决者接收到提议者发送的提案后,会再次拿出自己曾经记录的提议中的最大编号maxN,若N大于等于这编号,则当前表决者接受该提案,并反馈给提议者。若N小于这两个编号,则表决者采取不回应,或回应Error的方式来拒绝该提议。
3) 若提议者没有接收到超过半数的表决者的反馈,则重新进入prepare阶段,递增提案号,重新提出prepare请求。
若提议者接收到的反馈数量超过了半数,则其会向外广播两类消息
a) 向曾接收其提案的表决者发送“可执行数据同步信号”,即让它们执行其曾接收到的提案;
b) 向未曾向其发送接收反馈的表决者发送“提案 + 可执行数据同步信号”,即让它们接受到该提案后马上执行。
Zab协议
Zab协议其实就是paxos的一种简化实现,为分布式协调服务ZooKeeper专门设计的一种支持崩溃恢复的原子广播协议。
在ZooKeeper中,主要依赖ZAB协议来实现分布式数据一致性,基于该协议,ZooKeeper实现了一种主备模式的系统架构来保持集群中各个副本之间的数据一致性。
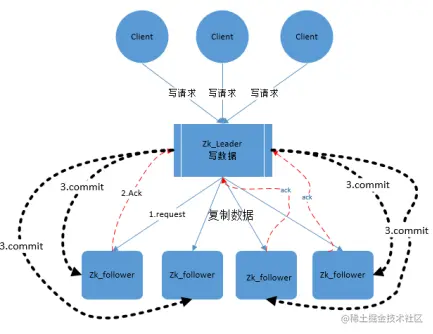
zab协议核心是在整个zookeeper集群中,leader将所有客户端的写操作转化为事务(提议proposal),leader节点再数据写完之后,将向所有的follower节点发送数据广播请求(数据复制)。
等所有的follower节点的反馈,在zab协议中,只要超过半数follower节点反馈ok,leader节点就会向所有follower服务器发送commit消息,将leader节点上的数据同步到follower节点之上。
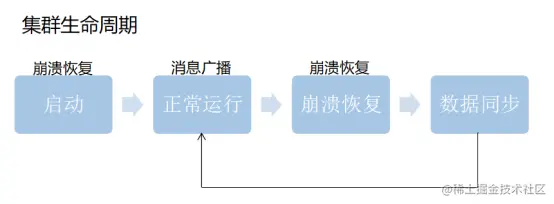
Zab模式
协议有两种模式,它们分别是恢复模式(选主)和广播模式(同步)
正常情况下当客户端对zk有写的数据请求时,leader节点会把数据同步到follower节点,这个过程其实就是消息的广播模式
在新启动的时候,或者leader节点奔溃的时候会要选举新的leader,选好新的leader之后会进行一次数据同步操作,整个过程就是奔溃恢复。
ZAB的崩溃恢复分成三个阶段:
1.选举阶段:此时集群中的节点处于Looking状态。它们会各自向其他节点发起投票,投票当中包含自己的服务器ID和最新事务ID(ZXID)。
节点会用自身的ZXID和从其他节点接收到的ZXID做比较,如果发现别人家的ZXID比自己大,也就是数据比自己新,那么就重新发起投票,投票给目前已知最大的ZXID所属节点。
每次投票后,服务器都会统计投票数量,判断是否有某个节点得到半数以上的投票。如果存在这样的节点,该节点将会成为准Leader,状态变为Leading。其他节点的状态变为Following。
2.发现阶段:用于在从节点中发现最新的ZXID和事务日志。
既然Leader被选为主节点,已经是集群里数据最新的了,为什么还要从节点中寻找最新事务呢?
为了防止某些意外情况,比如因网络原因在上一阶段产生多个Leader的情况,防止脑裂。
这一阶段,Leader集思广益,接收所有Follower发来各自的最新epoch值。Leader从中选出最大的epoch,基于此值加1,生成新的epoch分发给各个Follower。
各个Follower收到全新的epoch后,返回ACK给Leader,带上各自最大的ZXID和历史事务日志。Leader选出最大的ZXID,并更新自身历史日志。
3.同步阶段:把Leader刚才收集得到的最新历史事务日志,同步给集群中所有的Follower。只有当半数Follower同步成功,这个准Leader才能成为正式的Leader。
自此,故障恢复正式完成。
节点状态
Looking :选举状态。
Following :Follower节点(从节点)所处的状态。
Leading :Leader节点(主节点)所处状态。
消息广播模式
1.在zookeeper集群中数据副本的传递策略就是采用的广播模式
zookeeper中消息广播的具体步骤如下:
- 客户端发起一个写操作请求。
- Leader服务器将客户端的request请求转化为事物proposql提案,同时为每个提案分配一个全局唯一的ZXID。
- leader服务器与每个follower之间都有一个队列,leader将消息发送到该队列
- follower机器从队列中取出消息处理完后(写入本地事物日志中),向leader服务器发送ACK确认。
- leader服务器收到半数以上的follower的ACK后,即认为可以发送commit
- leader向所有的follower服务器发送commit消息
最大ZXID
最大ZXID也就是节点本地的最新事务编号,包含epoch和计数两部分。epoch是纪元的意思,相当于Raft算法选主时候的term。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号