第四次作业
业内容
作业①:
要求:
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
输出信息:MYSQL数据库存储和输出格式如下,表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头:
Gitee文件夹链接 https://gitee.com/see-no-green-hills/data-acquisition/tree/master/实验4/1
序号
import sqlite3
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import re
import time
import logging
import sys
import io
import os
# 设置 Python 输出为 UTF-8
sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='utf-8')
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[
logging.StreamHandler(sys.stdout),
logging.FileHandler("stock_scraper.log", encoding='utf-8') # 输出到文件
]
)
class StockScraper:
def __init__(self, driver_path, db_path='stock_data.db'):
self.driver_path = driver_path
self.db_path = os.path.abspath(db_path) # 使用绝对路径
self.driver = self.setup_driver()
self.board_xpaths = {
"沪深A股": '//*[@id="nav_hs_a_board"]',
"上证A股": '//*[@id="nav_sh_a_board"]',
"深证A股": '//*[@id="nav_sz_a_board"]'
}
self.initialize_database() # 初始化数据库
def setup_driver(self):
service = Service(executable_path=self.driver_path)
options = webdriver.ChromeOptions()
options.add_argument("--start-maximized")
# 可选:无头模式
# options.add_argument("--headless")
driver = webdriver.Chrome(service=service, options=options)
logging.info("WebDriver 启动成功。")
return driver
def initialize_database(self):
"""初始化数据库和表"""
try:
connection = sqlite3.connect(self.db_path)
cursor = connection.cursor()
cursor.execute("""
CREATE TABLE IF NOT EXISTS stock_info (
id INTEGER PRIMARY KEY AUTOINCREMENT,
stock_code TEXT,
stock_name TEXT,
latest_price REAL,
change_percentage TEXT,
change_amount REAL,
volume TEXT,
turnover TEXT,
amplitude REAL,
highest_price REAL,
lowest_price REAL,
opening_price REAL,
previous_close REAL
)
""")
connection.commit()
logging.info(f"数据库已初始化,数据库文件位于: {self.db_path}")
except sqlite3.Error as e:
logging.error(f"数据库初始化失败: {e}")
raise
finally:
cursor.close()
connection.close()
def navigate_to_website(self, url):
self.driver.get(url)
logging.info(f"已打开网站: {url}")
try:
WebDriverWait(self.driver, 20).until(
EC.presence_of_element_located((By.ID, "table_wrapper-table"))
)
logging.info("页面主要元素加载完成。")
except Exception as e:
logging.error(f"页面加载失败: {e}")
self.driver.quit()
raise
def clean_data(self, raw_text, field, code):
if raw_text in ['-', '--']:
return None
cleaned = re.sub(r"[^\d\.-]", "", raw_text)
try:
return float(cleaned)
except ValueError:
logging.warning(f"解析失败 - 股票代码: {code}, 字段: {field}, 原始值: {raw_text}")
return None
def extract_stock_data(self):
rows = self.driver.find_elements(By.XPATH, '//*[@id="table_wrapper-table"]/tbody/tr')
stocks = []
for idx, row in enumerate(rows, start=1):
try:
cells = row.find_elements(By.TAG_NAME, "td")
stock_code = cells[1].text.strip()
stock_name = cells[2].text.strip()
latest_price = self.clean_data(cells[4].text.strip(), "最新报价", stock_code)
change_percentage = cells[5].text.strip()
change_amount = self.clean_data(cells[6].text.strip(), "涨跌额", stock_code)
volume = cells[7].text.strip()
turnover = cells[8].text.strip()
amplitude = self.clean_data(cells[9].text.strip(), "振幅", stock_code)
highest_price = self.clean_data(cells[10].text.strip(), "最高", stock_code)
lowest_price = self.clean_data(cells[11].text.strip(), "最低", stock_code)
opening_price = self.clean_data(cells[12].text.strip(), "今开", stock_code)
previous_close = self.clean_data(cells[13].text.strip(), "昨收", stock_code)
stock = (
stock_code, stock_name, latest_price, change_percentage, change_amount,
volume, turnover, amplitude, highest_price, lowest_price, opening_price, previous_close
)
stocks.append(stock)
except Exception as e:
logging.error(f"解析第 {idx} 行数据失败: {e}")
logging.info(f"当前页面共提取到 {len(stocks)} 条股票数据。")
return stocks
def switch_board_and_scrape(self, board_name, xpath):
try:
board_element = WebDriverWait(self.driver, 10).until(
EC.element_to_be_clickable((By.XPATH, xpath))
)
board_element.click()
logging.info(f"已切换到板块: {board_name}")
time.sleep(3) # 等待数据加载
return self.extract_stock_data()
except Exception as e:
logging.error(f"切换到板块 {board_name} 失败: {e}")
return []
def scrape_all_boards(self):
all_data = []
for board, xpath in self.board_xpaths.items():
logging.info(f"开始抓取板块: {board}")
board_data = self.switch_board_and_scrape(board, xpath)
all_data.extend(board_data)
logging.info(f"板块 {board} 抓取完成,共 {len(board_data)} 条数据。")
return all_data
def save_to_database(self, data):
connection = sqlite3.connect(self.db_path)
cursor = connection.cursor()
insert_query = """
INSERT INTO stock_info (
stock_code, stock_name, latest_price, change_percentage, change_amount,
volume, turnover, amplitude, highest_price, lowest_price, opening_price, previous_close
) VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
"""
try:
cursor.executemany(insert_query, data)
connection.commit()
logging.info(f"成功插入 {cursor.rowcount} 条数据到数据库。")
except sqlite3.Error as e:
logging.error(f"数据库插入失败: {e}")
connection.rollback()
finally:
cursor.close()
connection.close()
logging.info("数据库连接已关闭。")
def verify_data_insertion(self):
"""验证数据库中是否有数据"""
try:
connection = sqlite3.connect(self.db_path)
cursor = connection.cursor()
cursor.execute("SELECT COUNT(*) FROM stock_info")
count = cursor.fetchone()[0]
logging.info(f"数据库中共有 {count} 条记录。")
except sqlite3.Error as e:
logging.error(f"数据库查询失败: {e}")
finally:
cursor.close()
connection.close()
def close(self):
self.driver.quit()
logging.info("WebDriver 已关闭。")
def main():
DRIVER_PATH = r"D:\\ChromeDriver\\chromedriver-win64\\chromedriver.exe" # 替换为实际路径
TARGET_URL = "http://quote.eastmoney.com/center/gridlist.html#hs_a_board"
scraper = StockScraper(driver_path=DRIVER_PATH)
try:
scraper.navigate_to_website(TARGET_URL)
all_stock_data = scraper.scrape_all_boards()
scraper.save_to_database(all_stock_data)
scraper.verify_data_insertion()
# 打印前5条数据进行验证
logging.info(f"总共抓取到 {len(all_stock_data)} 条数据。")
for stock in all_stock_data[:5]:
logging.info(stock)
finally:
scraper.close()
if __name__ == "__main__":
# Windows 下设置代码页为 UTF-8
if os.name == 'nt':
os.system('chcp 65001')
main()
作业②:
要求:
熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
候选网站:中国mooc网:https://www.icourse163.org
输出信息:MYSQL数据库存储和输出格式
Gitee文件夹链接 https://gitee.com/see-no-green-hills/data-acquisition/tree/master/实验4/2
import time
import random
import sqlite3
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# 设置Chrome浏览器驱动路径
driver_path = "D:\\ChromeDriver\\chromedriver-win64\\chromedriver.exe"
options = Options()
options.add_argument("--start-maximized") # 启动时最大化窗口
options.add_argument("--disable-gpu") # 禁用GPU加速
service = Service(executable_path=driver_path)
driver = webdriver.Chrome(service=service, options=options)
driver.get('https://www.icourse163.org/channel/2001.htm')
# 等待页面加载完成,查找课程列表的元素
WebDriverWait(driver, 60).until(EC.presence_of_element_located((By.XPATH, '/html/body/div[4]/div[2]/div/div/div/div[2]/div[1]/div/div[1]')))
# 模拟等待,确保页面完全加载
time.sleep(random.uniform(2, 5))
# 打开数据库连接(如果没有数据库则创建)
conn = sqlite3.connect('course_data.db')
cursor = conn.cursor()
# 创建数据库表格(如果没有表格则创建)
cursor.execute('''
CREATE TABLE IF NOT EXISTS courses (
course_name TEXT,
school_name TEXT,
teacher_name TEXT,
participants TEXT,
course_progress TEXT
)
''')
# 获取课程列表中的所有课程元素
course_data = []
# 假设每一页有20个课程,遍历每个课程
for i in range(1, 21): # 这里以 20 为示例,假设每页有 20 个课程
try:
# 根据你提供的 XPath 获取每个课程的信息
course_xpath = f'/html/body/div[4]/div[2]/div/div/div/div[2]/div[1]/div/div[2]/div/div/div/div/div[1]/ul/div[{i}]'
# 滚动页面到当前课程的位置(确保元素可见)
course_element = driver.find_element(By.XPATH, course_xpath)
driver.execute_script("arguments[0].scrollIntoView();", course_element)
time.sleep(random.uniform(1, 2)) # 等待滚动完成
# 获取课程名称
course_name_xpath = f'{course_xpath}/div/div/div[3]/div[1]/h3'
course_name = course_element.find_element(By.XPATH, course_name_xpath).text
# 获取学校名称
school_xpath = f'{course_xpath}/div/div/div[3]/div[1]/p'
school_name = course_element.find_element(By.XPATH, school_xpath).text
# 获取主讲人名称
teacher_xpath = f'{course_xpath}/div/div/div[3]/div[1]/div'
teacher_name = course_element.find_element(By.XPATH, teacher_xpath).text
# 获取参与人数
participants_xpath = f'{course_xpath}/div/div/div[3]/div[2]'
participants = course_element.find_element(By.XPATH, participants_xpath).text
# 获取课程进度
progress_xpath = f'{course_xpath}/div/div/div[3]/div[2]/div'
course_progress = course_element.find_element(By.XPATH, progress_xpath).text
# 将抓取到的数据存入 course_data 列表
course_data.append({
"course_name": course_name,
"school_name": school_name,
"teacher_name": teacher_name,
"participants": participants,
"course_progress": course_progress
})
# 将数据存入数据库
cursor.execute('''
INSERT INTO courses (course_name, school_name, teacher_name, participants, course_progress)
VALUES (?, ?, ?, ?, ?)
''', (course_name, school_name, teacher_name, participants, course_progress))
conn.commit()
except Exception as e:
print(f"Error extracting course {i}: {e}")
continue
# 打印所有课程数据
for data in course_data:
print(data)
# 关闭数据库连接
conn.close()
# 关闭浏览器
driver.quit()
作业③:
要求:
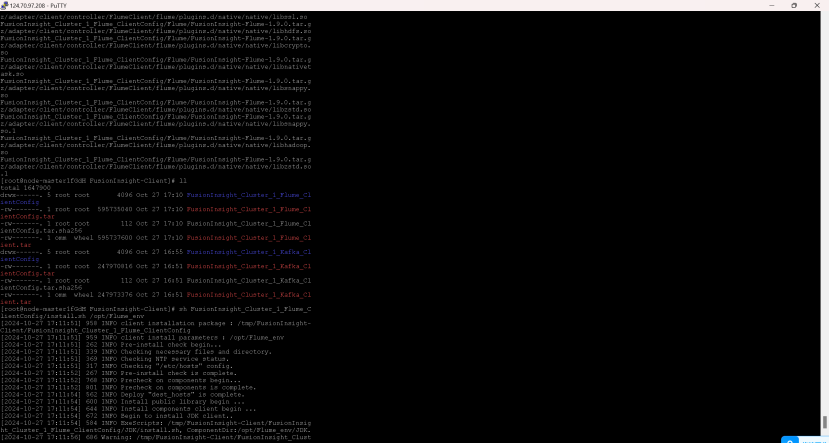
掌握大数据相关服务,熟悉Xshell的使用
完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。
环境搭建:
任务一:开通MapReduce服务
实时分析开发实战:
任务一:Python脚本生成测试数据
任务二:配置Kafka
任务三: 安装Flume客户端
任务四:配置Flume采集数据
输出:实验关键步骤或结果截图。