

实验三
作业①
1)爬取天气网图片
https://gitee.com/see-no-green-hills/data-acquisition/tree/master/实验三/ImageSpider
import scrapy
from ImageSpider.items import ImagespiderItem
class WeatherSpider(scrapy.Spider):
name = "weather_spider"
allowed_domains = ["weather.com.cn"]
start_urls = ["http://www.weather.com.cn/"]
def __init__(self):
self.page_count = 0
self.image_count = 0
self.max_pages = 4 # 最多爬取4页
self.max_images = 144 # 最多爬取144张图片
def parse(self, response):
if self.page_count < self.max_pages:
self.page_count += 1
images = response.xpath("//img/@src").getall()
for img_url in images:
if self.image_count >= self.max_images:
break
# 检查图片格式并构建完整的URL
if img_url.endswith((".jpg", ".jpeg", ".png")):
item = ImagespiderItem()
item['image_urls'] = [response.urljoin(img_url)]
self.image_count += 1
yield item
# 跳转到下一页逻辑(假设存在“下一页”链接)
next_page = response.xpath("//a[@class='next']/@href").get()
if next_page:
yield scrapy.Request(url=response.urljoin(next_page), callback=self.parse)
2)心得体会
作业②
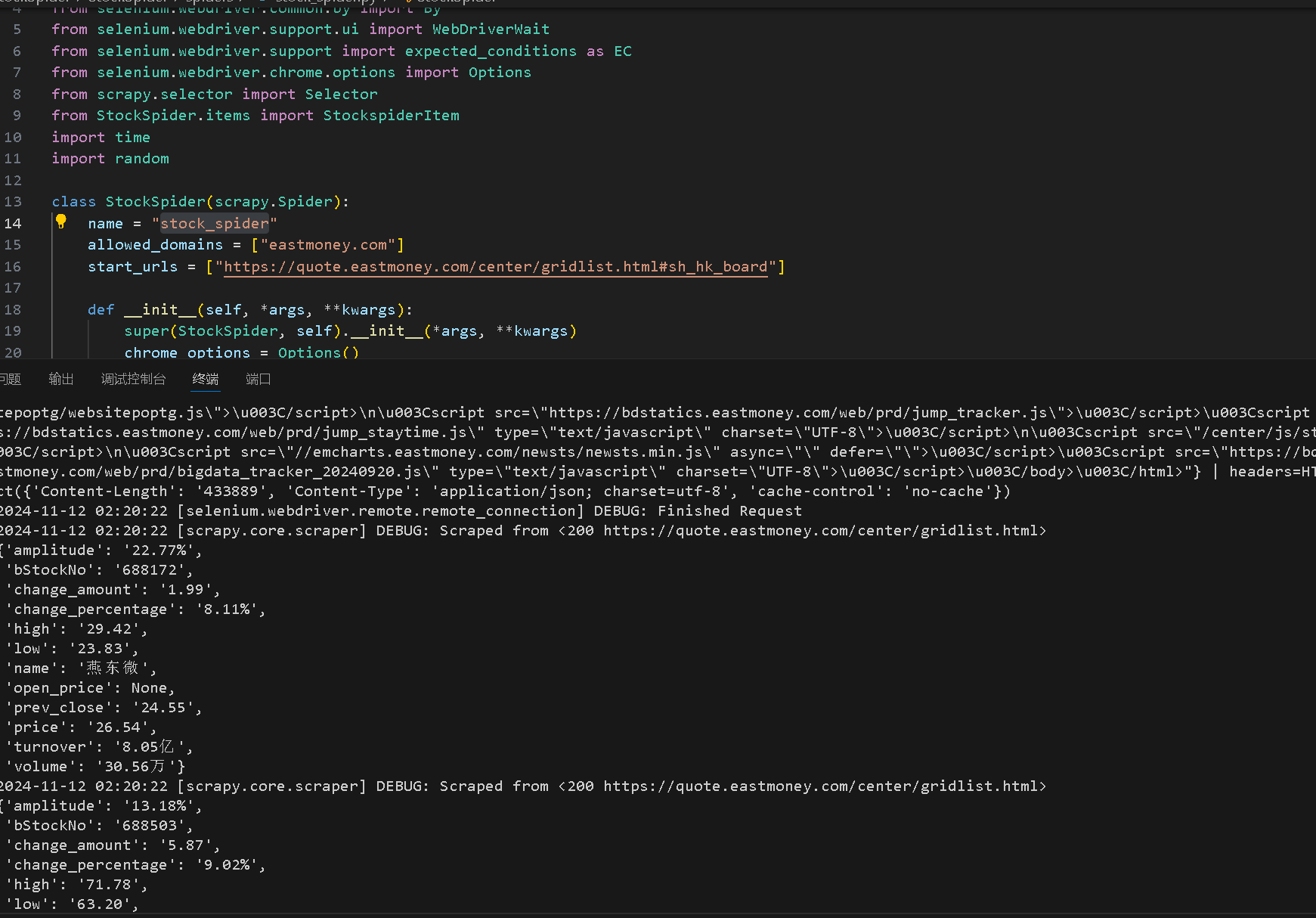
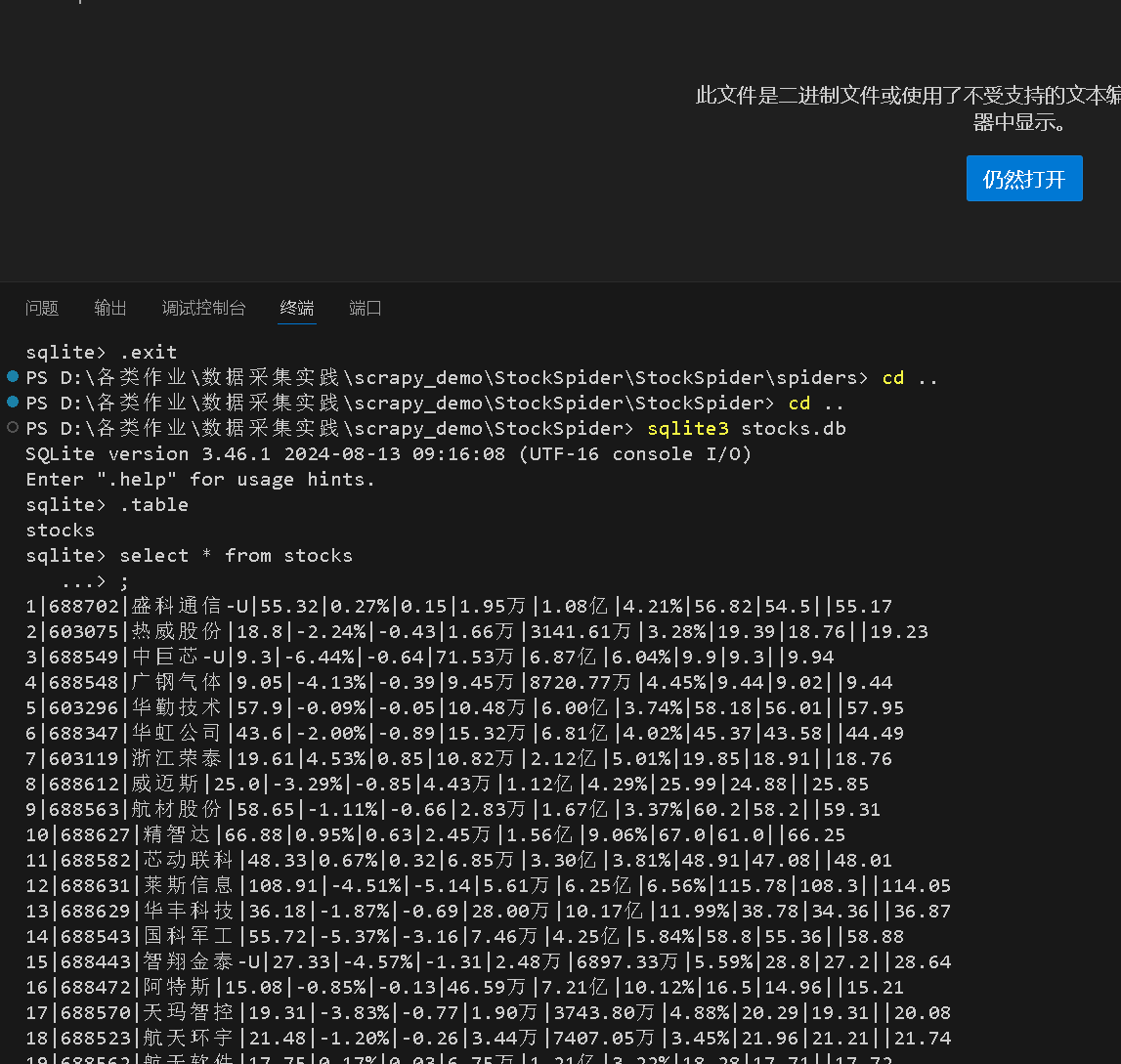
1)爬取股票信息
https://gitee.com/see-no-green-hills/data-acquisition/tree/master/实验三/StockSpider
import scrapy
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.options import Options
from scrapy.selector import Selector
from StockSpider.items import StockspiderItem
import time
import random
class StockSpider(scrapy.Spider):
name = "stock_spider"
allowed_domains = ["eastmoney.com"]
start_urls = ["https://quote.eastmoney.com/center/gridlist.html#sh_hk_board"]
def __init__(self, *args, **kwargs):
super(StockSpider, self).__init__(*args, **kwargs)
chrome_options = Options()
chrome_options.add_argument('--headless') # 使用无头模式
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-gpu')
# 设置Chrome浏览器驱动路径
self.driver = webdriver.Chrome(service=Service('D:\\ChromeDriver\\chromedriver-win64\\chromedriver.exe'), options=chrome_options)
def parse(self, response):
self.driver.get(self.start_urls[0])
# 等待页面加载完成
WebDriverWait(self.driver, 10).until(
EC.presence_of_element_located((By.XPATH, "//div[@class='listview full']"))
)
# 最大翻页数
MAX_PAGES = 4
current_page = 1
# 循环翻页直到达到最大页数
while current_page <= MAX_PAGES:
# 随机延迟以规避反爬虫
time.sleep(random.uniform(1, 3))
# 获取加载后的页面内容,并交给Scrapy的Selector解析
page_content = self.driver.page_source
sel = Selector(text=page_content)
# 提取当前页的股票数据
rows = sel.xpath("//table[@id='table_wrapper-table']/tbody/tr[@class='odd' or @class='even']")
for row in rows:
item = StockspiderItem()
item['bStockNo'] = row.xpath(".//td[2]/a/text()").get()
item['name'] = row.xpath(".//td[3]/a/text()").get()
item['price'] = row.xpath(".//td[5]/span/text()").get()
item['change_percentage'] = row.xpath(".//td[6]/span/text()").get()
item['change_amount'] = row.xpath(".//td[7]/span/text()").get()
item['volume'] = row.xpath(".//td[8]/text()").get()
item['turnover'] = row.xpath(".//td[9]/text()").get()
item['amplitude'] = row.xpath(".//td[10]/text()").get()
item['high'] = row.xpath(".//td[11]/span/text()").get()
item['low'] = row.xpath(".//td[12]/span/text()").get()
item['open_price'] = row.xpath(".//td[13]/text()").get()
item['prev_close'] = row.xpath(".//td[14]/text()").get()
yield item
# 查找并点击“下一页”按钮
try:
next_button = WebDriverWait(self.driver, 10).until(
EC.element_to_be_clickable((By.CLASS_NAME, 'next.paginate_button'))
)
next_button.click()
current_page += 1
except Exception as e:
print(f"翻页失败或到达末页: {e}")
break # 如果无法找到下一页按钮则停止翻页
def closed(self, reason):
self.driver.quit()
2)心得体会
作业③
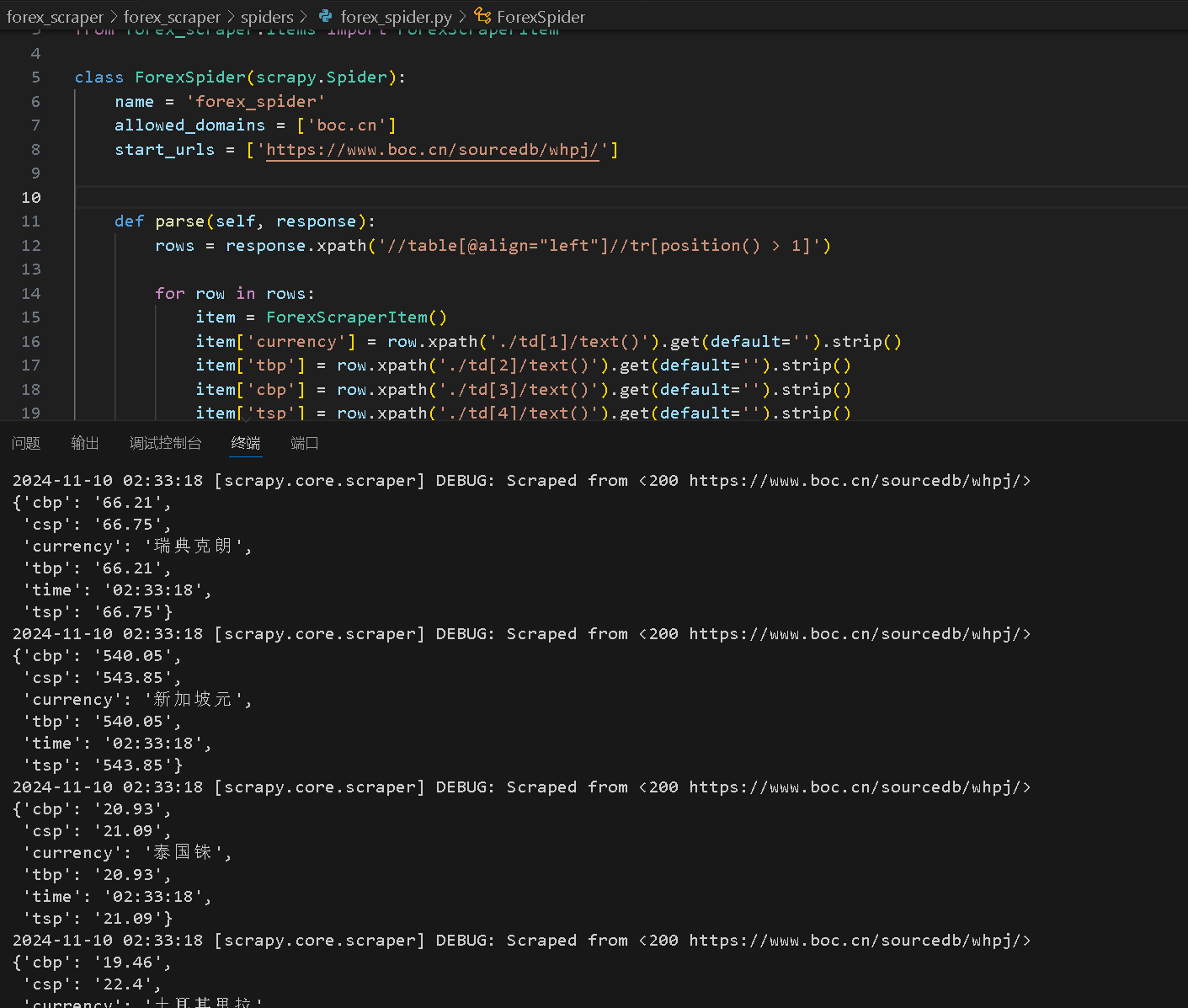
1)爬取外汇信息
https://gitee.com/see-no-green-hills/data-acquisition/tree/master/实验三/forex_scraper
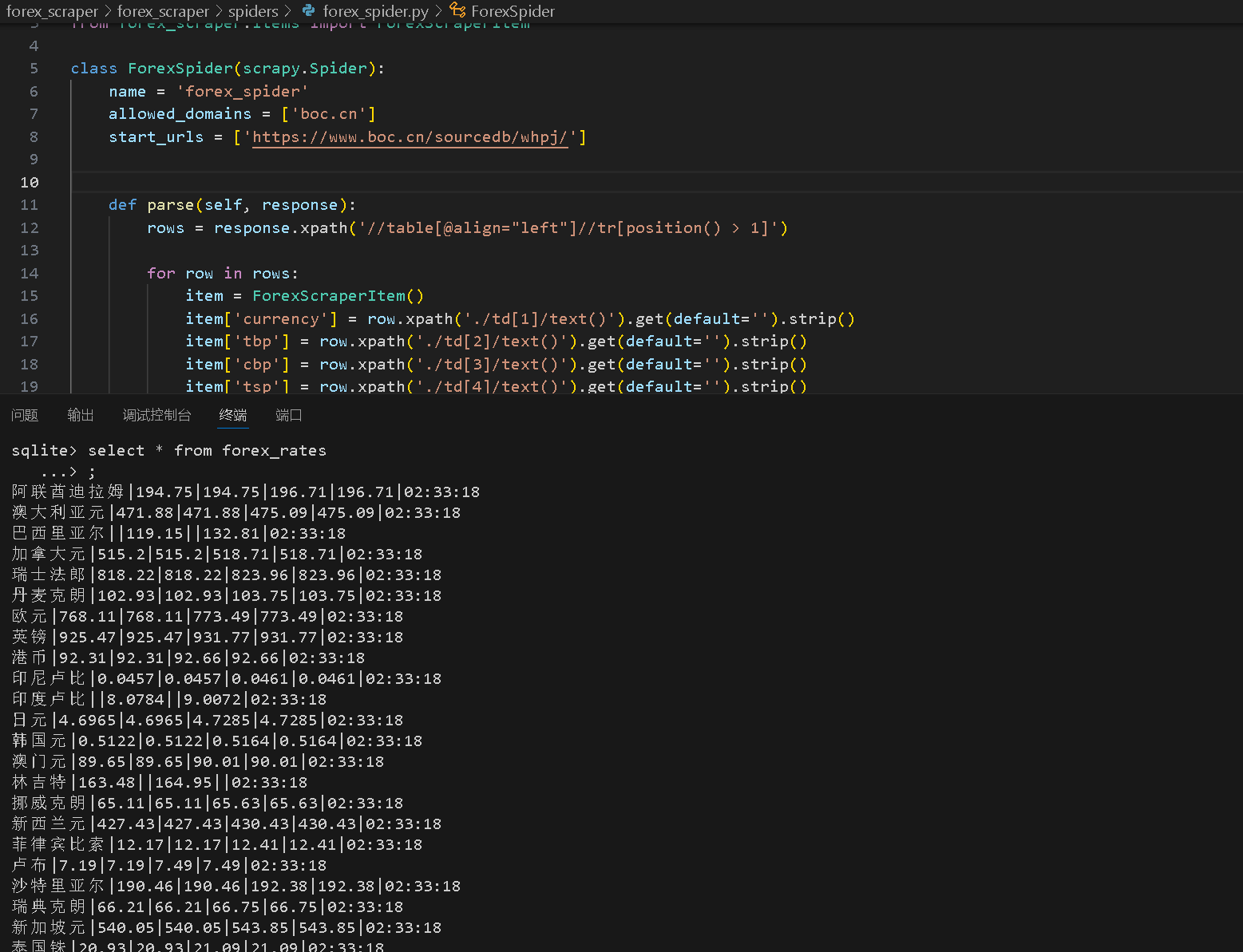
import scrapy
from datetime import datetime
from forex_scraper.items import ForexScraperItem
class ForexSpider(scrapy.Spider):
name = 'forex_spider'
allowed_domains = ['boc.cn']
start_urls = ['https://www.boc.cn/sourcedb/whpj/']
def parse(self, response):
rows = response.xpath('//table[@align="left"]//tr[position() > 1]')
for row in rows:
item = ForexScraperItem()
item['currency'] = row.xpath('./td[1]/text()').get(default='').strip()
item['tbp'] = row.xpath('./td[2]/text()').get(default='').strip()
item['cbp'] = row.xpath('./td[3]/text()').get(default='').strip()
item['tsp'] = row.xpath('./td[4]/text()').get(default='').strip()
item['csp'] = row.xpath('./td[5]/text()').get(default='').strip()
item['time'] = datetime.now().strftime("%H:%M:%S")
# 确保至少有一个字段非空,避免插入无效数据
yield item
2)心得体会

