


第二次作业
作业1:爬取天气
代码和截图
gitee仓库地址:search_weather
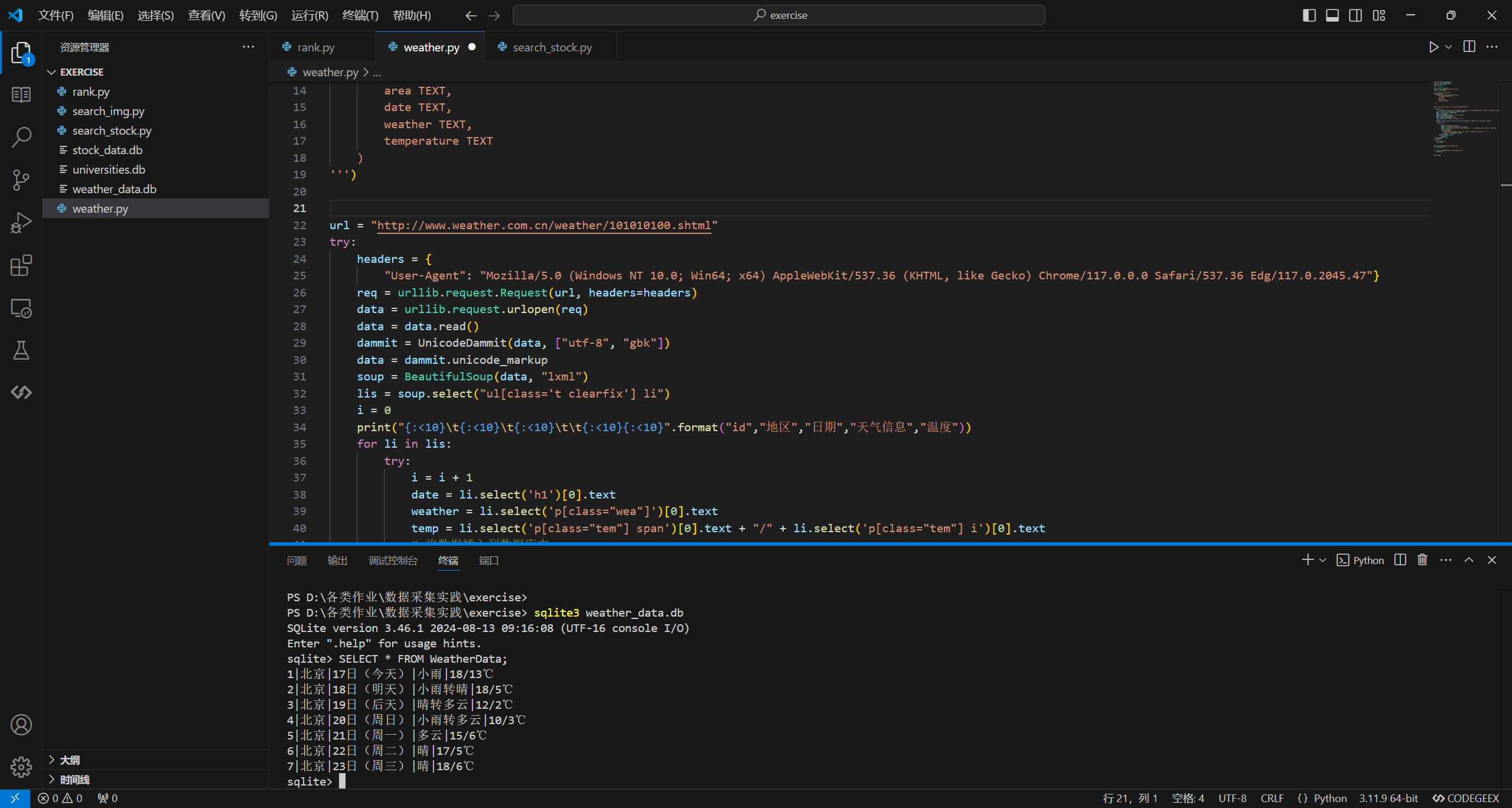
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import sqlite3
# 创建 SQLite 数据库连接
conn = sqlite3.connect('weather_data.db')
cursor = conn.cursor()
# 创建一个表用于存储天气数据
cursor.execute('''
CREATE TABLE IF NOT EXISTS WeatherData (
id INTEGER PRIMARY KEY,
area TEXT,
date TEXT,
weather TEXT,
temperature TEXT
)
''')
url = "http://www.weather.com.cn/weather/101010100.shtml"
try:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.47"}
req = urllib.request.Request(url, headers=headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
lis = soup.select("ul[class='t clearfix'] li")
i = 0
print("{:<10}\t{:<10}\t{:<10}\t\t{:<10}{:<10}".format("id","地区","日期","天气信息","温度"))
for li in lis:
try:
i = i + 1
date = li.select('h1')[0].text
weather = li.select('p[class="wea"]')[0].text
temp = li.select('p[class="tem"] span')[0].text + "/" + li.select('p[class="tem"] i')[0].text
# 将数据插入到数据库中
cursor.execute('''
INSERT INTO WeatherData (area, date, weather, temperature) VALUES (?, ?, ?, ?)
''', ("北京", date, weather, temp))
conn.commit() # 提交事务
except Exception as err:
print(err)
except Exception as err:
print(err)
finally:
# 关闭数据库连接
conn.close()
conn = sqlite3.connect('weather_data.db')
c = conn.cursor()
for row in c.execute('SELECT * FROM WeatherData'):
print(row)
conn.close()
(2)心得体会
通过中国气象网7日天气爬取项目,我学习了如何通过API请求获取动态数据,并存储到数据库中。这让我理解了数据抓取与存储的紧密联系,并加深了对网页爬虫和数据库操作的实战经验。
爬取股票信息
截图和代码
gitee仓库地址:search_stock
import requests
import json
import sqlite3
# 创建数据库连接
def create_connection(db_file):
conn = None
try:
conn = sqlite3.connect(db_file)
print(f"成功连接到数据库: {db_file}")
except sqlite3.Error as e:
print(f"数据库连接错误: {e}")
return conn
# 创建表格
def create_table(conn):
""" 创建存储股票信息的表 """
try:
cursor = conn.cursor()
cursor.execute('''CREATE TABLE IF NOT EXISTS stocks (
id INTEGER PRIMARY KEY AUTOINCREMENT,
code TEXT,
name TEXT,
latest_price REAL,
change_percent REAL,
change_amount REAL,
volume INTEGER,
turnover REAL,
amplitude REAL,
high REAL,
low REAL,
opening_price REAL,
yesterday_close REAL,
volume_ratio REAL,
turnover_rate REAL,
pe_ratio REAL,
pb_ratio REAL
)''')
print("数据库表创建成功")
except sqlite3.Error as e:
print(f"表创建错误: {e}")
# 插入股票信息数据
def insert_stock_data(conn, data):
""" 插入股票信息数据到数据库 """
try:
cursor = conn.cursor()
insert_query = '''INSERT INTO stocks (code, name, latest_price, change_percent, change_amount, volume, turnover,
amplitude, high, low, opening_price, yesterday_close, volume_ratio, turnover_rate,
pe_ratio, pb_ratio) VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)'''
cursor.executemany(insert_query, data)
conn.commit()
print(f"插入{len(data)}条股票数据成功")
except sqlite3.Error as e:
print(f"插入数据错误: {e}")
# 从API获取股票数据
def fetch_stock_data(page):
""" 从东方财富网API获取股票信息 """
url = f'http://41.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112406214897187204365_1729152484683&pn={page}&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&dect=1&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_={page}'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.47',
'cookie': 'qgqp_b_id=a7c5d47be8ad882fee56fc695bab498d'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
start = response.text.find('(') + 1
end = response.text.rfind(')')
data_json = json.loads(response.text[start:end])
return data_json['data']['diff']
else:
print(f"请求失败,状态码: {response.status_code}")
return []
# 处理原始数据
def process_stock_data(raw_data):
""" 格式化从API获取的原始股票数据,提取所需字段 """
processed_data = []
fields = ['f12', 'f14', 'f2', 'f3', 'f4', 'f5', 'f6', 'f7', 'f15', 'f16', 'f17', 'f18', 'f10', 'f8', 'f9', 'f23']
for stock in raw_data:
processed_data.append([stock.get(field) for field in fields])
return processed_data
# 主函数
def main():
database = "stock_data.db"
# 创建数据库连接
conn = create_connection(database)
if conn is not None:
create_table(conn)
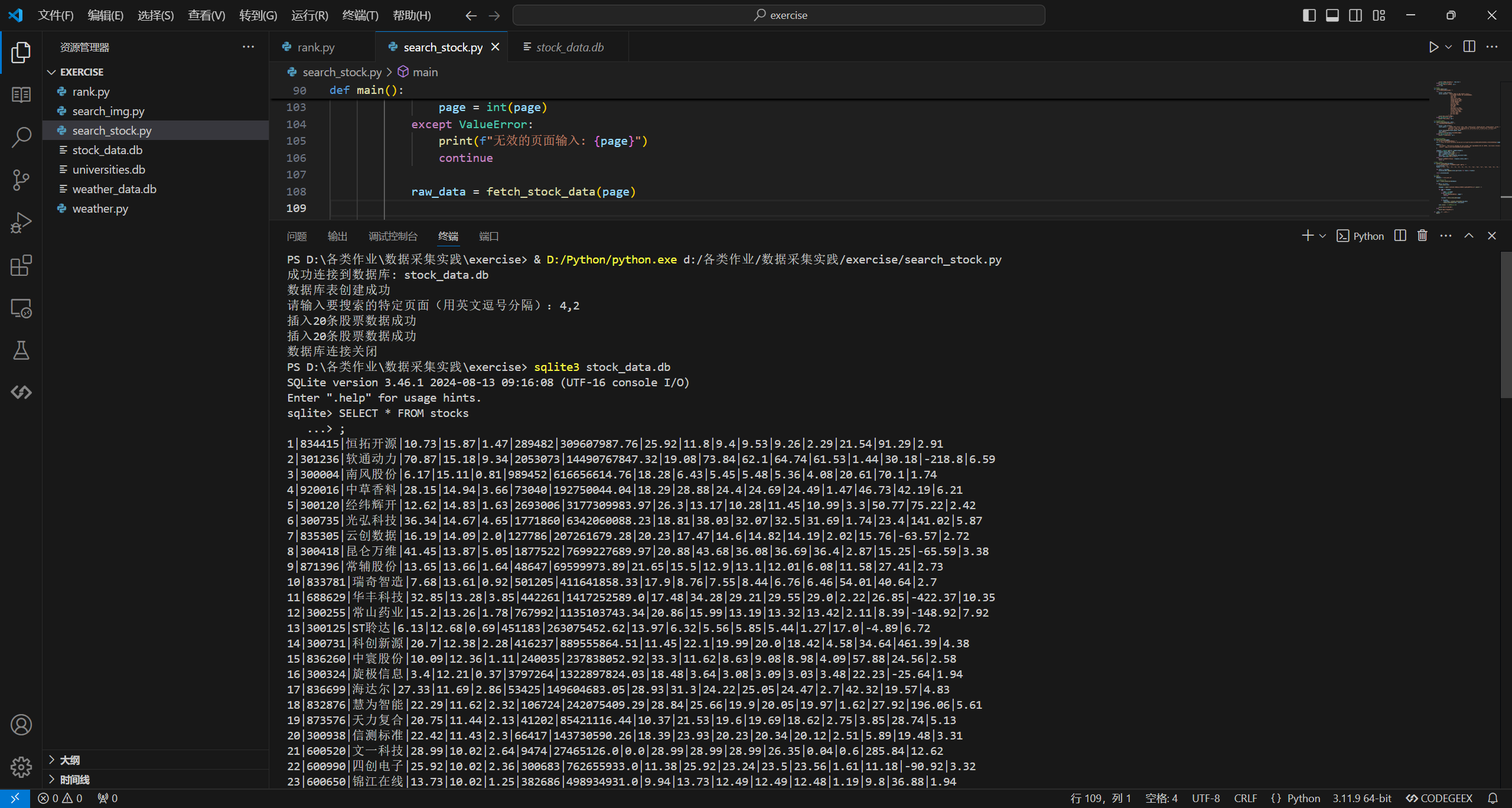
keypages = input("请输入要搜索的特定页面(用英文逗号分隔):").split(",")
for page in keypages:
try:
page = int(page)
except ValueError:
print(f"无效的页面输入: {page}")
continue
raw_data = fetch_stock_data(page)
if raw_data:
stock_data = process_stock_data(raw_data)
insert_stock_data(conn, stock_data)
conn.close() # 关闭数据库连接
print("数据库连接关闭")
else:
print("无法连接到数据库")
if __name__ == '__main__':
main()
(2)心得体会
在这个项目中,我学会了如何分析网站数据加载过程,抓取需要的信息并存储。整个过程让我对网页抓包技术有了更深的理解,也进一步提高了对数据处理的能力。
爬取大学信息
代码和截图
gitee仓库地址:search_rank
import requests
from bs4 import BeautifulSoup
import sqlite3
def get_display_length(s):
length = 0
for char in s:
if '\u4e00' <= char <= '\u9fff':
length += 2
else:
length += 1
return length
def format_str(s, target_length):
current_length = get_display_length(s)
return s + ' ' * (target_length - current_length)
def insert_into_database(data):
try:
print("正在将数据插入到数据库...")
conn = sqlite3.connect('universities.db')
cursor = conn.cursor()
# 创建表格
cursor.execute('''
CREATE TABLE IF NOT EXISTS universities (
rank TEXT,
name TEXT,
province TEXT,
school_type TEXT,
score TEXT
)
''')
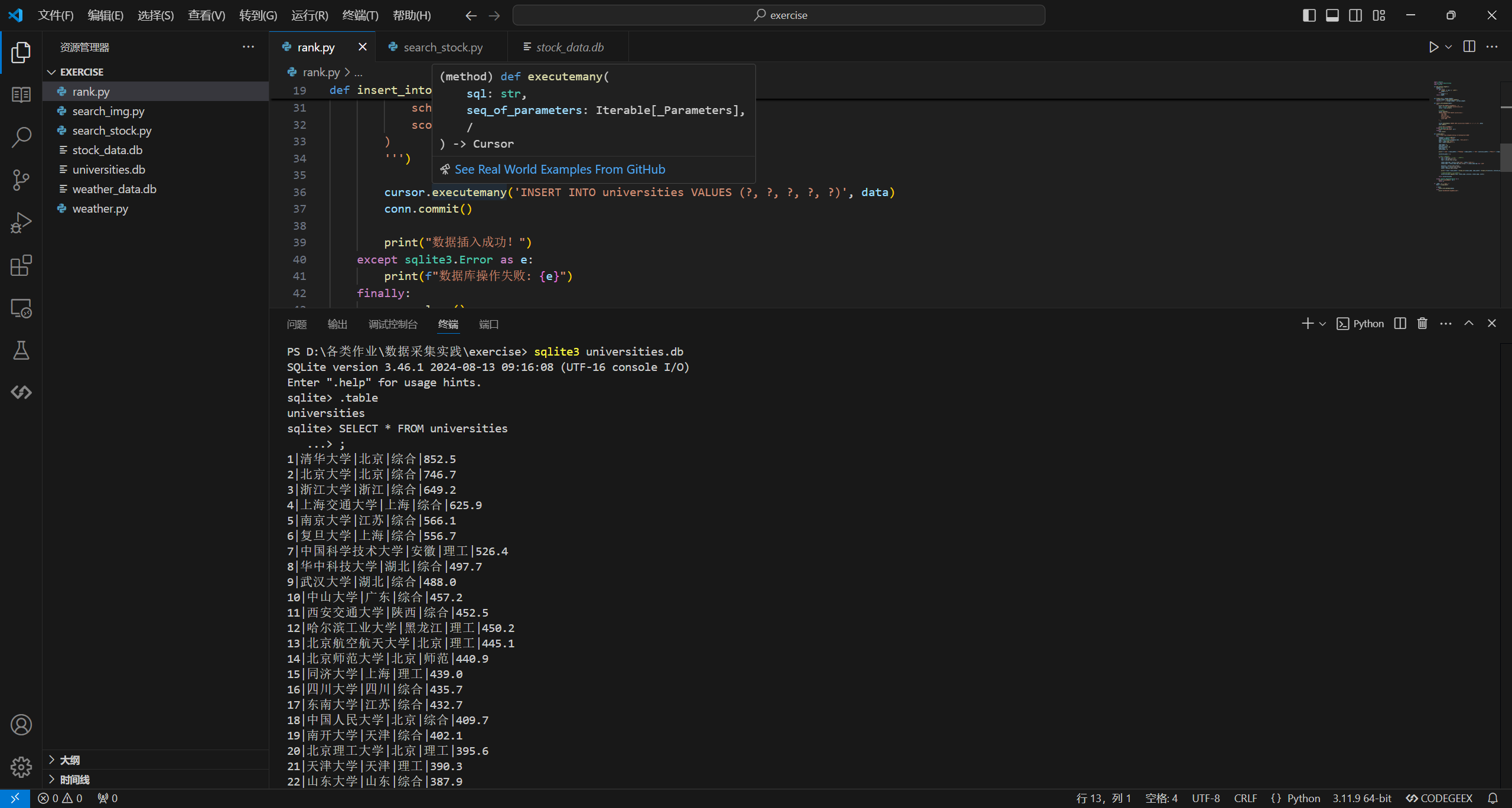
cursor.executemany('INSERT INTO universities VALUES (?, ?, ?, ?, ?)', data)
conn.commit()
print("数据插入成功!")
except sqlite3.Error as e:
print(f"数据库操作失败: {e}")
finally:
conn.close()
def scrape_data():
url = 'http://www.shanghairanking.cn/rankings/bcur/2020'
try:
response = requests.get(url)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'html.parser')
table = soup.find('table')
rows = table.find_all('tr')
rank_width = 6
name_width = 30
province_width = 10
type_width = 8
score_width = 8
print(f"{'排名':<{rank_width}} {'学校名称':<{name_width}} {'省市':<{province_width}} {'学校类型':<{type_width}} {'总分':<{score_width}}")
university_data = []
# 从表格中提取信息
for row in rows[1:]: # 忽略第一行(表头)
cols = row.find_all('td')
rank = cols[0].text.strip()
school_name_tag = cols[1].find('span', class_='name-cn')
school_name = school_name_tag.text.strip() if school_name_tag else '未知'
province = cols[2].text.strip()
school_type = cols[3].text.strip()
score = cols[4].text.strip()
print(f"{rank:<{rank_width}} {format_str(school_name, name_width)} {format_str(province, province_width)} {format_str(school_type, type_width)} {score:<{score_width}}")
# 将数据存入列表,稍后插入数据库
university_data.append((rank, school_name, province, school_type, score))
return university_data
except requests.RequestException as e:
print(f"网页请求失败: {e}")
return []
if __name__ == "__main__":
data = scrape_data()
if data:
insert_into_database(data)
else:
print("没有数据可插入到数据库。")
查找元素:
运行结果:
(2)心得体会
通过这个项目,我对如何分析网站发包情况有了新的认识,并学会了从中提取有效数据。将这些数据存入数据库的实践,让我对网页爬虫和数据存储有了更全面的理解。
