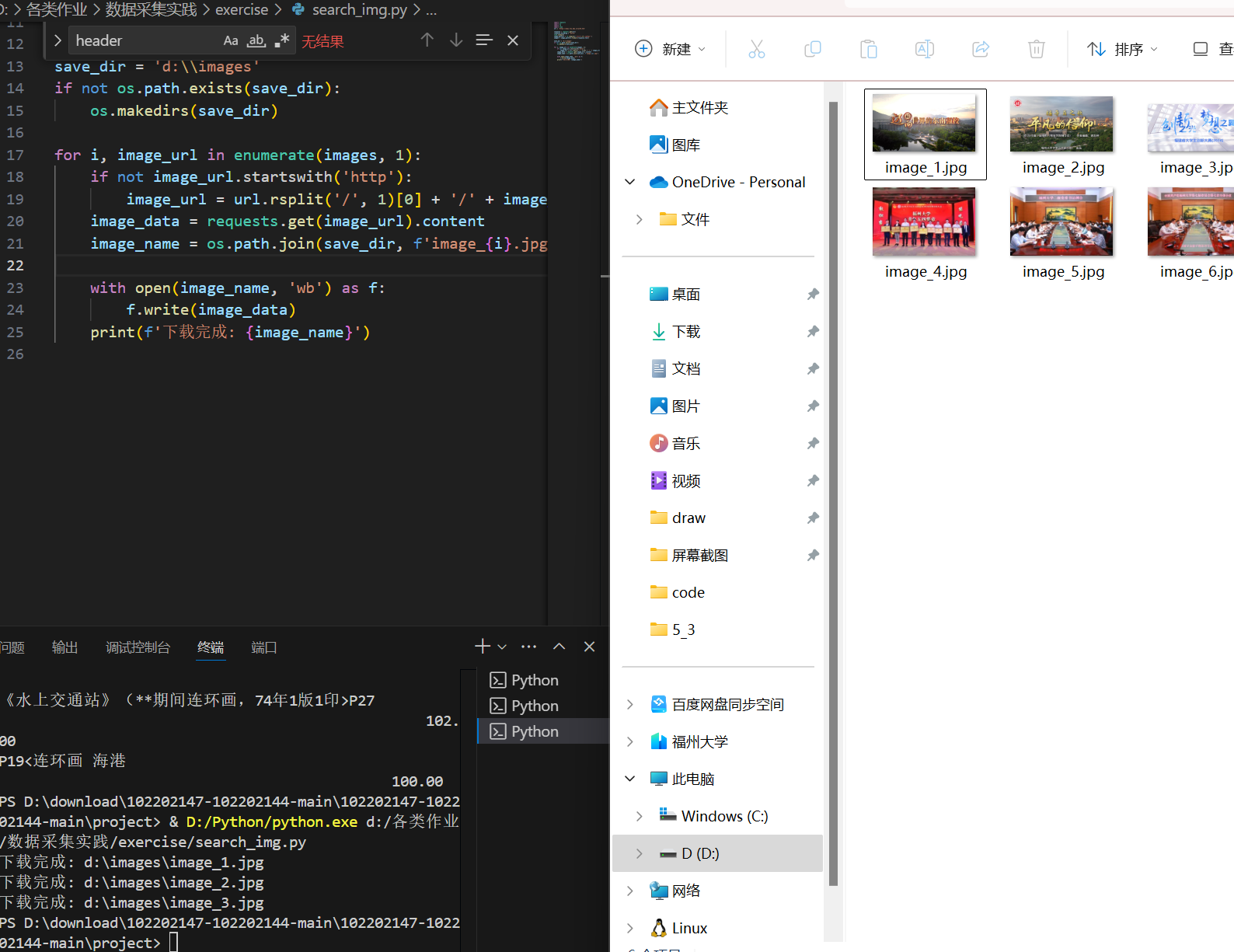
作业1:定向爬取大学排名信息
代码和结果截图
定向爬取大学信息
import requests
from bs4 import BeautifulSoup
# 目标URL
url = 'http://www.shanghairanking.cn/rankings/bcur/2020'
response = requests.get(url)
response.encoding = 'utf-8'
# 使用BeautifulSoup解析网页内er容
soup = BeautifulSoup(response.text, 'html.parser')
# 查找所有包含排名信息的表格数据
table = soup.find('table')
rows = table.find_all('tr')
# 设置列宽
rank_width = 6
name_width = 30
province_width = 10
type_width = 8
score_width = 8
# 打印表头
print(f"{'排名':<{rank_width}} {'学校名称':<{name_width}} {'省市':<{province_width}} {'学校类型':<{type_width}} {'总分':<{score_width}}")
# 解析并打印每一行的排名信息
for row in rows[1:]: # 跳过表头
cols = row.find_all('td')
rank = cols[0].text.strip()
# 学校名称在指定标签内
school_name_tag = cols[1].find('span', class_='name-cn')
school_name = school_name_tag.text.strip() if school_name_tag else '未知'
province = cols[2].text.strip()
school_type = cols[3].text.strip()
score = cols[4].text.strip()
# 格式化输出,使得中英文混合对齐
print(f"{rank:<{rank_width}} {format_str(school_name, name_width)} {format_str(province, province_width)} {format_str(school_type, type_width)} {score:<{score_width}}")
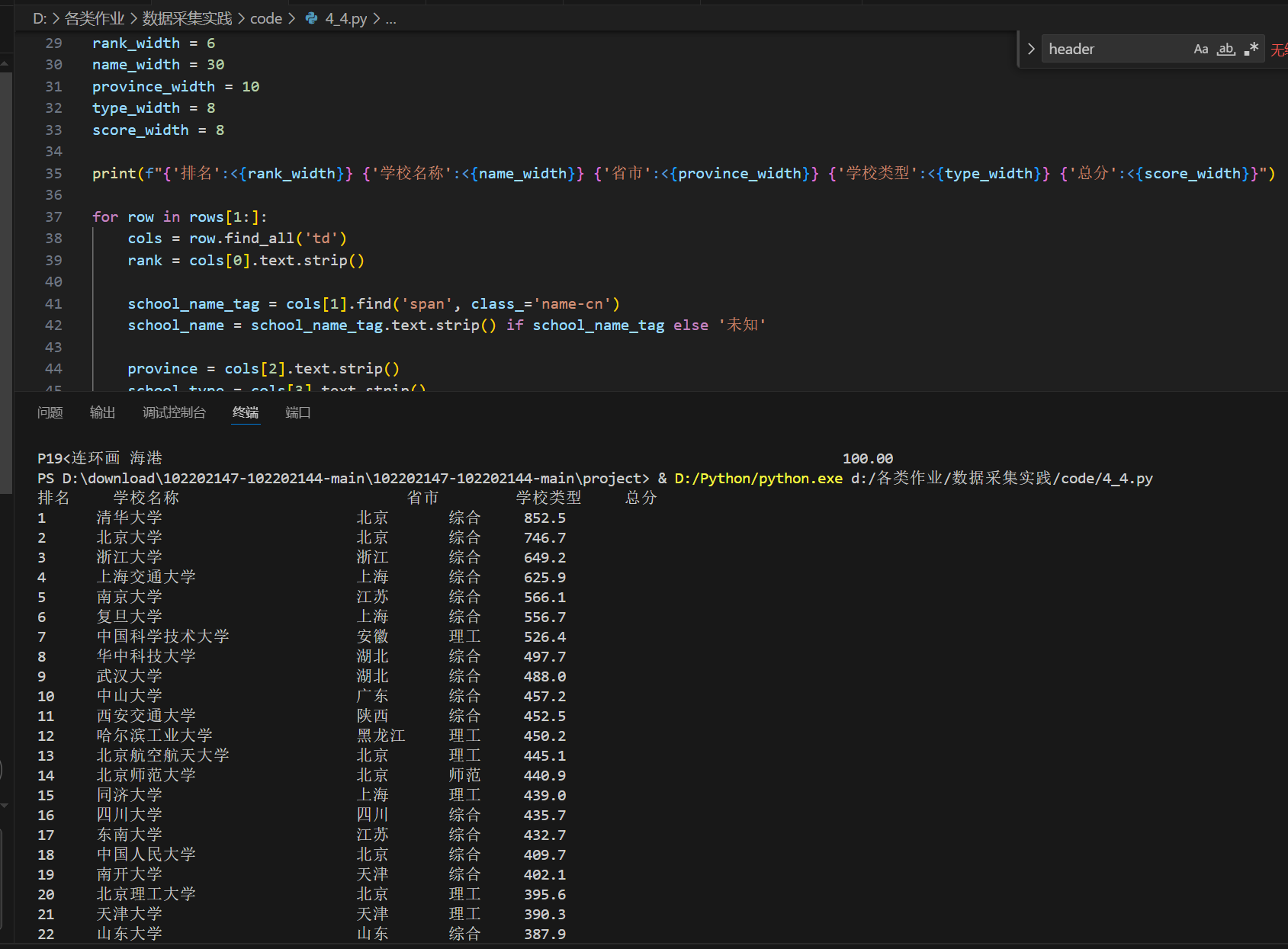
作业2:商城商品比价爬虫
代码和截图
商城商品比价爬虫
import requests
def get_display_length(s):
length = 0
for char in s:
if '\u4e00' <= char <= '\u9fff':
length += 2
else:
length += 1
return length
def format_str(s, target_length):
current_length = get_display_length(s)
return s + ' ' * (target_length - current_length)
keyword = "戴敦邦"
url = f"https://search.kongfz.com/pc-gw/search-web/client/pc/product/keyword/list?keyword={keyword}&page=1&userArea=1006000000"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36"
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
data = response.json()
if data.get('status') == 0:
print("无数据或解析失败")
else:
items = data.get('data', {}).get('itemResponse', {}).get('list', [])
print(format_str("书名", 30) + format_str("价格", 10))
print('-' * 40)
for item in items:
title = item.get('title')
price = item.get('priceText')
if title and price:
print(format_str(title, 30) + format_str(price, 10))
else:
print(f"请求失败,状态码: {response.status_code}")
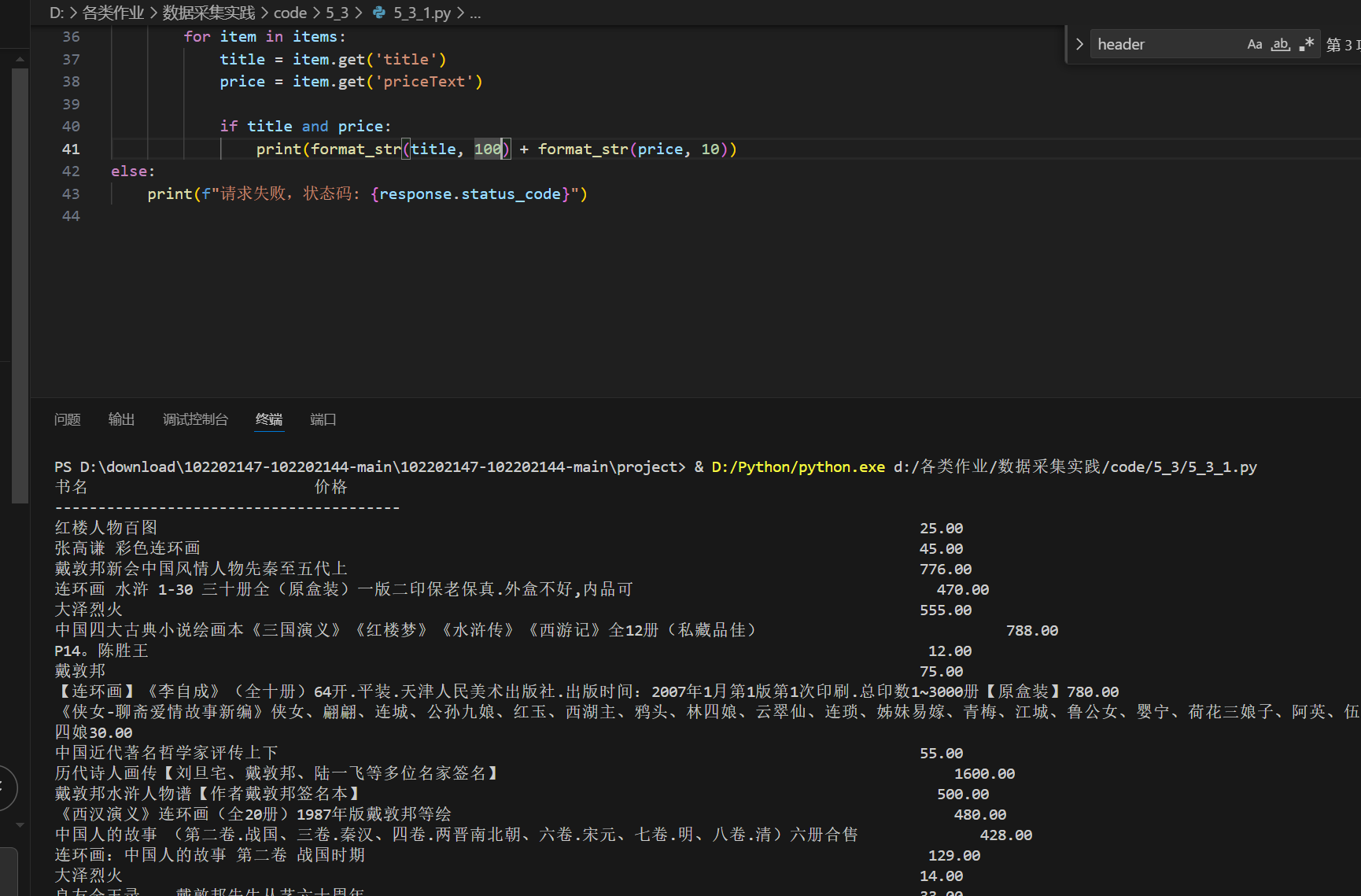
作业3:爬取网页内JPEG和JPG图片
代码和截图
爬取网页内JPEG和JPG图片
import requests
import os
import re
import time
url = 'https://news.fzu.edu.cn/yxfd.htm'
response = requests.get(url)
response.encoding = 'utf-8'
time.sleep(6)
image_pattern = re.compile(r'src="(.*?\.jpe?g)"')
images = image_pattern.findall(response.text)
save_dir = 'd:\\images'
if not os.path.exists(save_dir):
os.makedirs(save_dir)
for i, image_url in enumerate(images, 1):
if not image_url.startswith('http'):
image_url = url.rsplit('/', 1)[0] + '/' + image_url
image_data = requests.get(image_url).content
image_name = os.path.join(save_dir, f'image_{i}.jpg')
with open(image_name, 'wb') as f:
f.write(image_data)
print(f'下载完成: {image_name}')