
另一篇介绍的很好的博客:http://blog.jobbole.com/71431/
一、什么是PageRank
PageRank 是对搜索引擎的搜索网页进行排序的算法。
过去的排序算法是比如使用网页名字,关键词出现的次数,人工等方法,但是这种方法一方面搜索结果不准确,另一方面搜索结果容易被人为因素影响。
所以,PageRank应运而生。
PageRank算法计算每一个网页的PageRank值,然后根据这个值的大小对网页的重要性进行排序。它的思想是模拟一个悠闲的上网者,上网者首先随机选择一个网页打开,然后在这个网页上呆了几分钟后,跳转到该网页
所指向的链接,这样无所事事、漫无目的地在网页上跳来跳去,PageRank就是估计这个悠闲的上网者分布在各个网页上的概率。
PageRank背后的两个基本假设:
- 数量假设:更重要的网页更可能被更多的网页链接到。
- 质量假设:有更高的PageRank的网页将会传递更高的权重。(类似大佬转发的网页就比我转发的网页更重要)
二、PageRank模型

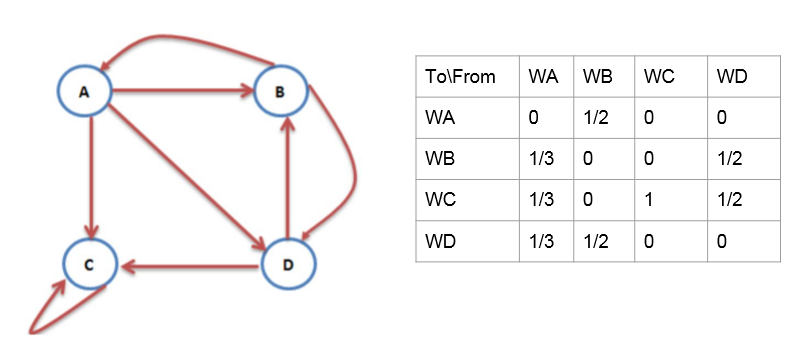
互联网中网页和网页之间的链接关系组成一个有向图,其中网页是节点,网页之间的链接为有相边。如上图所示的模型就表示四个网页,A指向B的箭头表示A中存在指向B的链接。
可以使用转移矩阵来表示这样一个有向图。上图所对应的模型即可用转移矩阵表示为:

我们看到,A网页发出三个链接,那么到任何一个网页的概率都均等,所以我们上边的矩阵A这一列对用的BCD三个网页概率都为1/3。
有了上面的转移矩阵,我们从两个角度来思考:
一方面,一个网页X如果有许多网页指向他,那么转移矩阵的X行就会有许多的非零元素,转移之后这个网页就会获得更大的PageRank,这刚好和我们上文提到的数量假设相对应。
另一方面,假设X网页具有很高的重要性,那么X所转移到的那些网页将会由于X的高重要性而获得相对更高的重要性,这刚好和我们上文提到的质量假设相对应。
那么,怎样表示一个网页的重要性呢?
我们使用PageRank Matrix来表示。上述有向图对应一个4 * 1的PageRank矩阵。

为什么初始化为均分初始化呢?我们可以这样思考,一个无聊的上网这开始想要来打开一个网页,那么他打开这一堆网页中的任何一个在最开始都是风概率的。(当然不考虑个人信息,那是个性化搜索的范畴)
好了,我们现在有了两个矩阵,转移矩阵和初始的PageRank矩阵PR0, 我们接下来就要模拟网页间的跳转。

如图,一次跳转之后,网页A的PageRank就应该由可以跳到A的网页和他们各自的PageRank相乘之后的和来表示。上图的矩阵乘法就可以表示一次跳转之后的各个网页的PageRank值。
同理,PR2 = Transition Matrix * PR1。 PRn = Transition Matrix * PR(n - 1)。可以证明,最终的PR是收敛的。(马尔科夫过程,图是强连通的)
三、Dead Ends 终止点问题
有些网页不存在指向其他网页的链接,那么多次迭代之后,导致所有网页的PageRank都变为0.

上图网页c没有指向外部的链接,最终将会导致各个网页的PageRank都变为0.

四、Spider traps 陷阱问题
陷阱问题是有些网页只存在指向自己的链接,那么多次迭代之后,这将导致这个网页的PageRank为1,而其他网页的PageRank为0.

五、解决终止点问题和陷阱问题
我们现在回到开始是所说的那个无聊的上网者,假如人类遇到这个问题的话,采取的解决办法就是关闭当前网页,重新打开一个网页。所以为了避免上述两个问题,我们呢对上边的转移公式做一个小小的修正。(有概率随机打开一个网页,这时候打开所有网页的概率均等)

回到之前的例子:

六、Map-Reduce计算PageRank
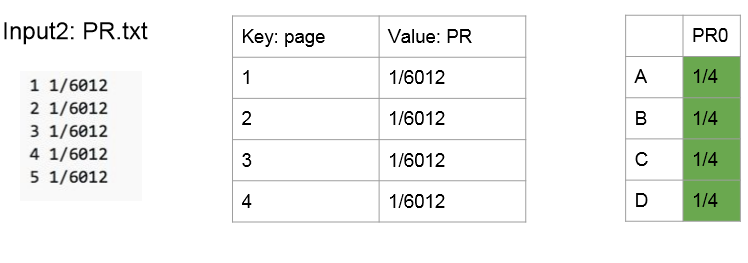
6.1输入数据
上边分析的时候数据似乎是存储在转移矩阵中,但实际不是这样的,这样一方面太浪费空间了,另一方面,插入和删除数据都很麻烦。
实际的数据输入格式如下:

我们先对数据进行预处理,类似于邻接表的存储方式,存储网页和该网页包含的链接所指向的网页。

我们使用Relations.txt来生成转移矩阵,然后在进行转移矩阵和PageRank矩阵的相乘操作。
6.2矩阵相乘
接下来就设计到Map-Reduce处理矩阵的乘法操作,我们不能直接来进行两个矩阵的乘法操作。因为如果这样做的话,我们需要转移矩阵的一行数据都来齐之后才可进行,这就需要我们 in-memory 存储整个矩阵,很容易造成out of mempry 而且速度还慢。
所以我们的处理方法是用Traverse MAtrix的每一列和PR相成,最后把所有元素相加即可。这样我们就不需要in-memery那么多东西。
其实对于一个网页A,可以思考为,你A B C D分别可以为我贡献多少,然后把ABCD的贡献全都加起来,就是A的PageRank。矩阵直接相乘和我们的相乘相加的方法的其别就是,直接相乘是计算A的PageRank 的时候,把所以对A有贡献的网页都拿来,计算出贡献加起来作为A的PageRank;相乘相加是首先计算出A可以为ABCD贡献多少,然后B可以为ABCD贡献多少,然后C..D..。最后再把这些值加起来,分别作为ABCD的PageRank。
我们的流程图如下:

容易知道,我们使用两个Map-Reduce来实现。
MR1 --- Mapper1 从Relations.txt中读取网页并计算跳转到的网页及概率

MR1 --- Mapper2 从PR.txt中读取网页并均分概率
MR1 --- Reducer 两个Mapper过来的key就代表是慨率网页key转移,输出key应该为转移到的网页,value为网页key对这个网页做了多少贡献。



MR2 --- Mapper 很简单,就是从前一个Map-Reduce生成的文件中读取数据
MR2 --- Reducer Mapper按照网页作key之后分类的sum,得到各个网页的PageRank
七、主要代码
Driver


1 public class Driver { 2 3 public static void main(String[] args) throws Exception { 4 UnitMultiplication multiplication = new UnitMultiplication(); 5 UnitSum sum = new UnitSum(); 6 7 //args0: dir of transition.txt 8 //args1: dir of PageRank.txt 9 //args2: dir of unitMultiplication result 10 //args3: times of convergence 11 String transitionMatrix = args[0]; 12 String prMatrix = args[1]; 13 String unitState = args[2]; 14 int count = Integer.parseInt(args[3]); 15 for(int i=0; i<count; i++) { 16 String[] args1 = {transitionMatrix, prMatrix+i, unitState+i}; 17 multiplication.main(args1); 18 String[] args2 = {unitState + i, prMatrix+(i+1)}; 19 sum.main(args2); 20 } 21 } 22 }
UnitMultiplication
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.InputFormat; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.chain.ChainMapper; import org.apache.hadoop.mapreduce.lib.input.MultipleInputs; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; import java.util.ArrayList; import java.util.List; public class UnitMultiplication { public static class TransitionMapper extends Mapper<Object, Text, Text, Text> { @Override public void map(Object key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString().trim(); String[] fromTo = line.split("\t"); if(fromTo.length == 1 || fromTo[1].trim().equals("")) { return; } String from = fromTo[0]; String[] tos = fromTo[1].split(","); for (String to: tos) { context.write(new Text(from), new Text(to + "=" + (double)1/tos.length)); } } } public static class PRMapper extends Mapper<Object, Text, Text, Text> { @Override public void map(Object key, Text value, Context context) throws IOException, InterruptedException { String[] pr = value.toString().trim().split("\t"); context.write(new Text(pr[0]), new Text(pr[1])); } } public static class MultiplicationReducer extends Reducer<Text, Text, Text, Text> { @Override public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { List<String> transitionUnit = new ArrayList<String>(); double prUnit = 0; for (Text value: values) { if(value.toString().contains("=")) { transitionUnit.add(value.toString()); } else { prUnit = Double.parseDouble(value.toString()); } } for (String unit: transitionUnit) { String outputKey = unit.split("=")[0]; double relation = Double.parseDouble(unit.split("=")[1]); String outputValue = String.valueOf(relation * prUnit); context.write(new Text(outputKey), new Text(outputValue)); } } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf); job.setJarByClass(UnitMultiplication.class); ChainMapper.addMapper(job, TransitionMapper.class, Object.class, Text.class, Text.class, Text.class, conf); ChainMapper.addMapper(job, PRMapper.class, Object.class, Text.class, Text.class, Text.class, conf); job.setReducerClass(MultiplicationReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); MultipleInputs.addInputPath(job, new Path(args[0]), TextInputFormat.class, TransitionMapper.class); MultipleInputs.addInputPath(job, new Path(args[1]), TextInputFormat.class, PRMapper.class); FileOutputFormat.setOutputPath(job, new Path(args[2])); job.waitForCompletion(true); } }
UnitSum
1 import org.apache.hadoop.conf.Configuration; 2 import org.apache.hadoop.fs.Path; 3 import org.apache.hadoop.io.DoubleWritable; 4 import org.apache.hadoop.io.Text; 5 import org.apache.hadoop.mapreduce.Job; 6 import org.apache.hadoop.mapreduce.Mapper; 7 import org.apache.hadoop.mapreduce.Reducer; 8 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 9 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 10 11 import java.io.IOException; 12 import java.text.DecimalFormat; 13 14 public class UnitSum { 15 public static class PassMapper extends Mapper<Object, Text, Text, DoubleWritable> { 16 17 @Override 18 public void map(Object key, Text value, Context context) throws IOException, InterruptedException { 19 String[] pageSubrank = value.toString().split("\t"); 20 double subRank = Double.parseDouble(pageSubrank[1]); 21 context.write(new Text(pageSubrank[0]), new DoubleWritable(subRank)); 22 } 23 } 24 25 public static class SumReducer extends Reducer<Text, DoubleWritable, Text, DoubleWritable> { 26 27 28 @Override 29 public void reduce(Text key, Iterable<DoubleWritable> values, Context context) 30 throws IOException, InterruptedException { 31 32 double sum = 0; 33 for (DoubleWritable value: values) { 34 sum += value.get(); 35 } 36 DecimalFormat df = new DecimalFormat("#.0000"); 37 sum = Double.valueOf(df.format(sum)); 38 context.write(key, new DoubleWritable(sum)); 39 } 40 } 41 42 public static void main(String[] args) throws Exception { 43 44 Configuration conf = new Configuration(); 45 Job job = Job.getInstance(conf); 46 job.setJarByClass(UnitSum.class); 47 job.setMapperClass(PassMapper.class); 48 job.setReducerClass(SumReducer.class); 49 job.setOutputKeyClass(Text.class); 50 job.setOutputValueClass(DoubleWritable.class); 51 FileInputFormat.addInputPath(job, new Path(args[0])); 52 FileOutputFormat.setOutputPath(job, new Path(args[1])); 53 job.waitForCompletion(true); 54 } 55 }
考虑到dead ends 和 spider traps的话,只是前边的矩阵cell相乘的时候乘以beta,后边再用一个mapper来加上beta倍的pagerank即可。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号