
机器学习之特征提取(三)—— TfidfVectorizer权值
1.什么是TF-IDF?
TF =(某词在文档中出现的次数/文档的总词量)
IDF= log e为底(语料库中文档总数/包含该词的文档数+1), +1的原因是避免分母为0
(也被称为逆文档频率,因为是总数除以包含文档数)
TF-IDF = TFxIDF
TF-IDF值越大表示该特征词对这个文本的重要性越大。
2.sklearn里面的TfidfVectorizer()和TfidfTransformer()的区别?
①相同点:二者都可以计算词频的权值
②不同点:
TfidfTransformer()就是将类变换成tfidf的值,通常和CountVectorizer()结合,先将文本类转化为机器所能训练识别的数字特征。再通过TfidfTransformer()来计算权值,从而得到重要性程度。
TfidfVectorizer()简单讲就是将上面两个类合并,一次性从文本类型转化,得到最后的权值。
3.TfidfVectorizer()相关常用参数?
①get_feature_names_out():得到最后的特征数组(numpy.ndarray类型)
②get_feature_names():和get_feature_names_out()结果一样,随着sklearn版本的升级,官方更加推荐使用get_feature_names_out()
③toarray():并不是TfidfVectorizer()的参数,但是因为经常转化成比较容易看的数组,会将权值数组进行矩阵转化。
④vocabulary_:返回所有特征和特征在TD-IDF中的位置对应关系
⑤stop_words:停用词集合,当为'english'时,ENGLISH_STOP_WORDS中定义的词会被忽略,如果为list,list中的单词即为要忽略的词。
⑥max_df: 设定当某个词超过一个df(document frequency)的上限时就忽略该词。当为0~1的float时表示df的比例,当为int时表示df数量
⑦idf_:输出一串权值数组,但是具体含义不清楚。该参数找了很多资料没有记录,等待后续有了解待补充。
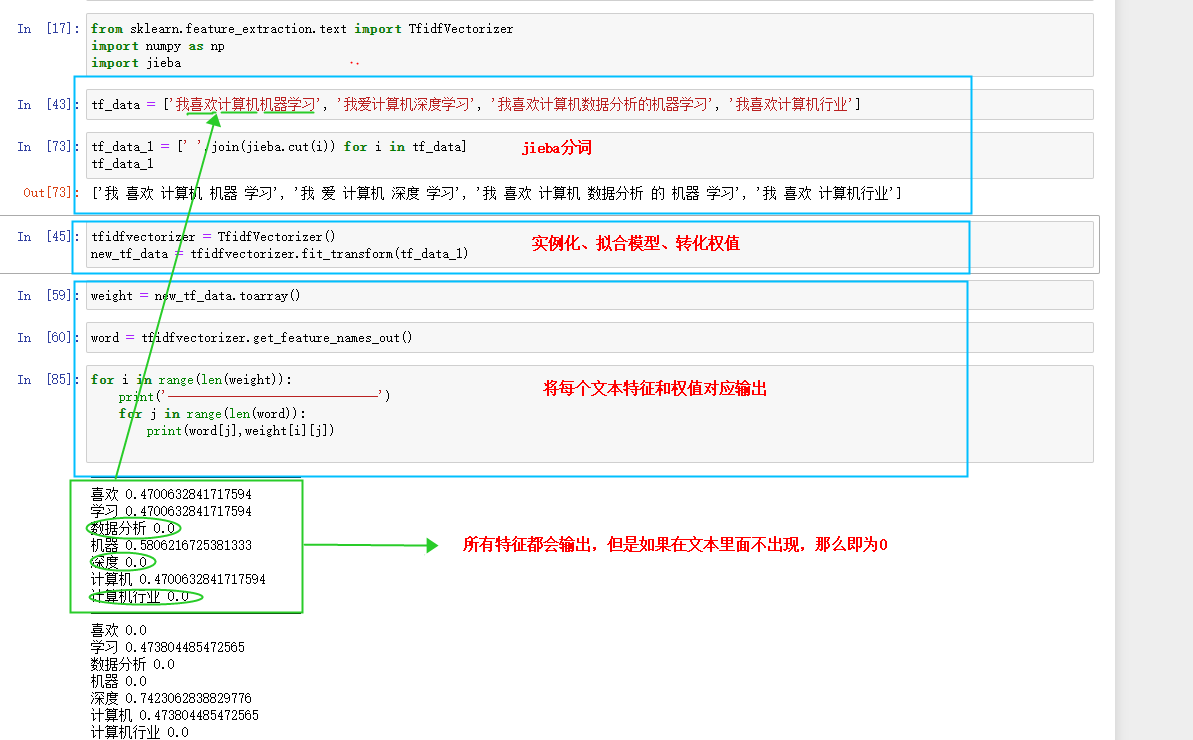
4.特征例子及含义(老样子,jupyter上逐行运行)
因为英文有空格,一般不用分词,而中文,通常使用jieba分词,jieba分词可以满足大部分的分词需求,如果用于企业或者医药等其它专业相关,jieba分词将不再适用。
在特征权值中注意:一般fit_transform()进行相关的权值转化时,是用于训练集(因为训练集需要拟合模型后进行转化),而测试不需要拟合模型,如果拟合模型会造成最后过拟合结果。
from sklearn.feature_extraction.text import TfidfVectorizer import numpy as np import jieba tf_data = ['我喜欢计算机机器学习', '我爱计算机深度学习', '我喜欢计算机数据分析的机器学习', '我喜欢计算机行业'] tf_data_1 = [' '.join(jieba.cut(i)) for i in tf_data] tf_data_1 tfidfvectorizer = TfidfVectorizer() new_tf_data = tfidfvectorizer.fit_transform(tf_data_1) weight = new_tf_data.toarray() word = tfidfvectorizer.get_feature_names_out() for i in range(len(weight)): print('------------------------------') for j in range(len(word)): print(word[j],weight[i][j]) tfidfvectorizer.vocabulary_
本文来自博客园,作者:许个未来—,转载请注明原文链接:https://www.cnblogs.com/future-panda/p/16812755.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号