
机器学习之特征提取(二)——字典类型特征提取(特征离散化)
字典类型和CountVectorizer文本类型的特征基本相同,不同的是输出的结果类型,字典直接返回的键值对。
以下代码用jupyter分块运行
运行结果含义参考上一篇:https://www.cnblogs.com/future-panda/p/16809957.html
1 from sklearn.feature_extraction import DictVectorizer 2 3 dic_data = [ 4 {'星期一': '面条', '味道':100}, 5 {'星期二': '包子', '味道':99}, 6 {'星期三': '牛奶', '味道':101}, 7 ] 8 9 dic_transfer = DictVectorizer(sparse=False) 10 new_dic_data = dic_transfer.fit_transform(dic_data) 11 12 new_dic_data 13 dic_transfer.get_feature_names_out()
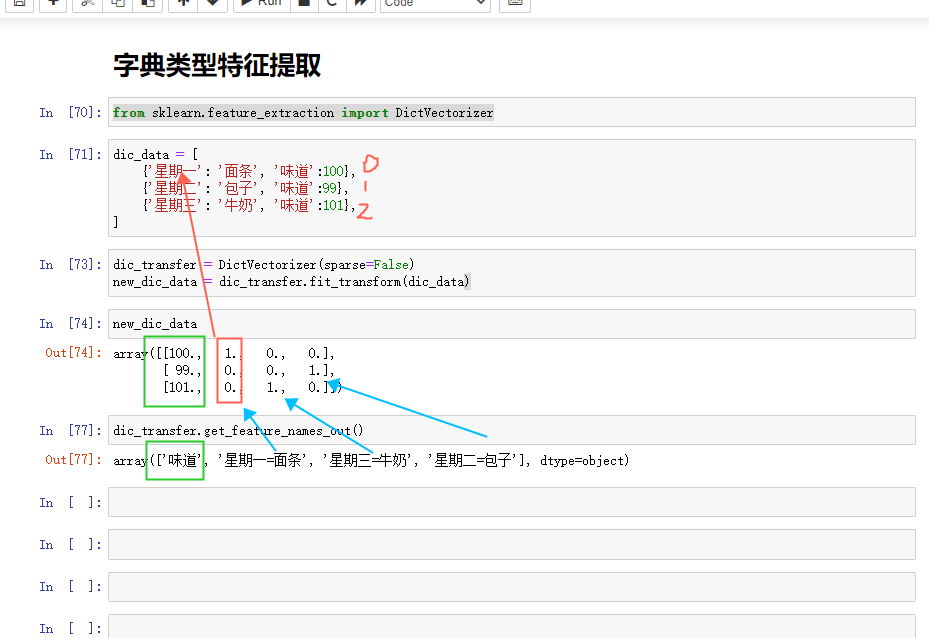
本文来自博客园,作者:许个未来—,转载请注明原文链接:https://www.cnblogs.com/future-panda/p/16810131.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号