
一、总览
攻击名称:Universal trigger(UNITrigger)是一个种有效的对抗样本攻击方法。
攻击方式:利用学习机制,生成一个固定的短语,添加到良性输入,以此降低near zero on a target class的准确率。
文章提出的防御方法:从网络安全的community中我们引入“蜜罐”内容,并提出了了DARCY。一个基于蜜罐的防御框架针对Unitrigger。
实现:DARCY贪心搜索和注入多个陷阱门在NN模型汇中,然后去"bait and catch"(诱捕)潜在的攻击。
实验:在四个公开数据集上,检测UniTRigger对抗攻击TPR提升到99%同时FPR小于2%,同时将干净输入的预测精度(在 F1 中)保持在 1% 的范围内。我们同时展示了DARCY在多个陷阱门下的鲁棒性,对各种攻击场景集合在攻击者各种知识等级和技能下。
二、背景
learning-based attacks方法的好处:
第一:从整体上利用模型的虚弱点而不是针对任何特别的输入,第二:在相似模型中有很高的转让性,为了说明这一点,UniTrigger and MALCOM攻击白盒模型的方法,对于不同结构下的不可见的黑模型也有欺骗作用。第三:由于它们对看不见的输入的泛化,基于学习的对抗生成算法可以促进大规模攻击,与基于实例的方法相比,计算成本显着降低。因此learning-base attack的防御很急迫。
为防御learning-based在nlp中的攻击,我们提出了一种创新的方法,叫做DARCY,为了防御通过uniTRigger产生的对抗样本,UNiTrigger是一种很强的表示learning-based的方法。为此我们开发了Unitrigger独有的优点,能够在一些通用的样本上成功生成一个独立的通用的对抗短语。从网路安全中引入了蜜罐的概念,去设计很多陷阱门在NN文本分类器中,并且去捕获和过滤出Unitrigger生成的恶意样本。 *** 换句话说,我们训练了一个目标神经网络模型,它为攻击者提供了极大的激励,以生成其行为是防御者预定义和意图的对抗性文本。
贡献点:
1.第一篇将蜜罐用于针对文本NN模型对抗攻击的防御方法。
2.搜索和注入多个陷阱门在文本NN中,能够检测Unitrigger攻击,超过99%TPR和少于2%的FPR。同时在大多数情况下在四个公共数据集的良性示例上保持相似的性能。
二、初步分析
2.1 Universal Trigger Attack
生成一个固定的短语S组成了K个tokens,比如一个触发器,同时增加S到良性或者x任何地方的尾部,以此去愚弄F去输出一个目标标签L。简单说就是生成短语S组成tokens,然后增加到良性数据或者任何样本位置的后面。为了搜索S,优化了以下目标函数在D attack上:
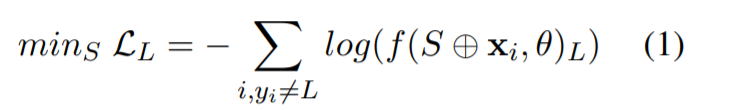
⊕是一个中token的智能链接。这个攻击首先将trigger初始化为一个中性短语,同时使用beam-search的方法通过优化公式(1)从Dattack去选择一个最好的候选tokens在随机抽样的小批量上。L收敛时,顶层的tokens将被初始化去寻找下一个最合适的触发器。最后的tokens集合被选择为Universal trigger
2.2 攻击的性能和检测
SST的数据集
使用两个token的攻击效果都高于其他模型。除了使用Unitrigger以外还使用了HotFlip,TextFooler、Textbugger、USE
Unitrigger强大又经济,攻击者有很大的动力在实践中去使用他。因此寻找一种针对这种攻击的方式的防御至关重要。
三、蜜罐和陷阱门
为了攻击F,Unitrigger依赖公式(1)去找寻在损失空间F上对应局部最优的触发器,如蜜罐,比如使用公式(1)能够快捷的让他们收敛。注入不同的陷阱门(针对熟人的预定义)到F中,使用了三个步骤:(1)找寻陷阱门(2)注入陷阱门(3)检测陷阱门,我们命名这个框架叫DARCY(Defending universAl tRigger’s attaCk with honeYpot)。图一说明了DARCY的一个例子。

3.1 DARCY框架
\(S{_L ^*}\):防御的目标标签结合
1.搜索陷阱门:为了防御在目标标签上L的攻击,选择K个陷阱门\(S^*_ {L}\)=\({W_1, W_2, W_3,..., W_K}\),它们当中的每一个都是属于从训练\({D_{train}}\)中抽取的词汇集合V。\(H(·)\)是搜索函数。:\(S^*_ {L}\)\(\leftarrow\)\(H(K,D_{train},L)\).
2.注入陷阱门:为了注入\(S^*_ {L}\)在\(F\)中同时引诱攻击者,首先填充一个陷阱门嵌入的集合样本,公式如下:
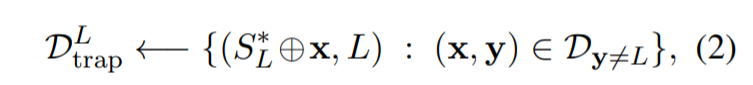
其中\(D_{y\neq L}\)表示{\(D_{train}:y\neq L\)},然后我们可以将诱饵\(S^*_ {L}\)注入到\(F\),通过训练\(F\)连同所有被注入样本的目标标签L,最小化的目标函数如下:
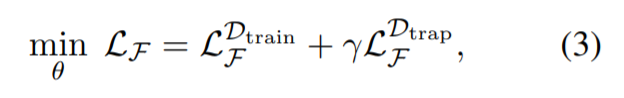
其中
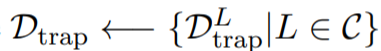
\(L{_F ^D}\)是数据集D负对数似然(NLL)损失函数,陷阱门的权重超参数\(\gamma\)是控制陷阱门嵌入样本在训练期间的贡献度。通过公式(3),我们训练\(F\)最小化NLL在观察到的和陷阱门嵌入的样本。在攻击者使用公式(1)搜索一个触发器的集合的时候,这个生成的“traps”或者是便捷的收敛点(局部最优)。然而我们可以控制陷阱门的强度。通过综合分析\(D{_{trap} ^L}\)和所有的来自公式(2)的样本\(D{_{y\neq L}}\).我们想注入"strong"陷阱门到模型中。然而这可能会导致权衡的计算超过公式(3)的权衡。所以参数的值如下:
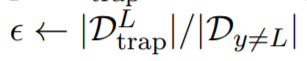
3.检测陷阱门
3.1 基本方法
一旦我们的模型被注入了陷阱门,我们就需要一个检测机制去检测潜在的攻击任务。因此我们训练了一个二分类器\(g(·)\),参数是\(\theta_g\),去预测可能性:\(x\)包含统一个统一触发器,使用输出,从\(F\)‘s的最后一层(用\(F^*(x)\)表示)因此公式如下:
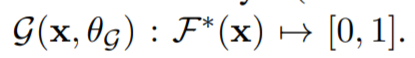
G 比简单的字符串比较更可取 因为公式(1)能够收敛不是绝对但是能够在\(S^*_ {L}\)附近,\(g(·)\)的损失函数如下:
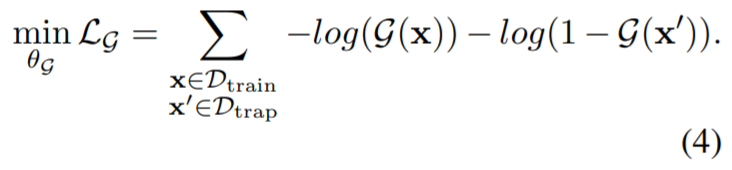
3.2 多贪婪陷阱门搜索
设计一个综合的陷阱门搜索函数\(H\)在框架中很重要。首先分析陷阱门所需的属性:
(1)保真性
(2)鲁棒性
(3)分类-意识(class-awareness)
多贪心陷阱门,搜索的标准。
保真性:
如果选择的陷阱门和语义意思的标签冲突(陷阱门选择“awful”,去防御积极的标签),优化公式(3)将变得更具挑战。因此\(H\)应该选择每一个token\(w\in S{_L ^*}\)去防御一个目标标签L,使其在附加到公式(2)中\(D{_{y\neq L}}\)样例时,根据F’s的决策边界, 尽可能远离L中的其他对比类。特别的,我们想优化的保真损失函数如下:
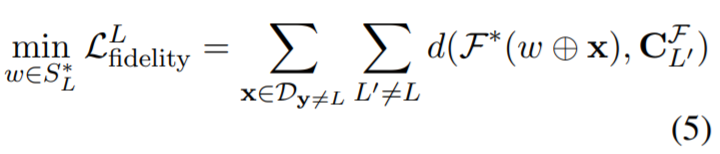
其中\(d(·)\)是相似度函数(比如余弦相似度)\(D_{y\neq L}\)和训练F的一个中心,距离越大,就更新距离。
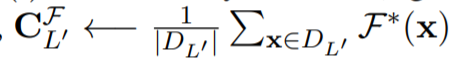
\(F^* (x)\)是在预测对比类L‘的样本时,F在最后一层的所有输出的中心。
对各种攻击的鲁棒性
即使一个强大的陷阱门,比如,一个能够显著的减少\(F\)的损失值,能够在原始UniTrigger's设置中很好的工作,但是一个高级的攻击者还是可能检测设置的陷阱门,同时找到一个可以适应的更好的办法。因此我们建议在F中搜索和嵌入多个陷阱门(K>1),为了防御每一个目标标签。
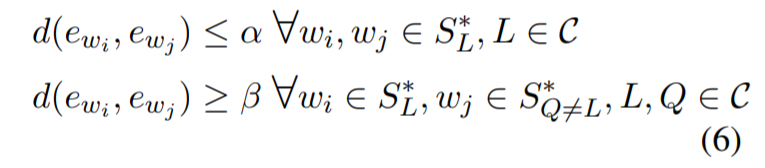
Class-Awareness
由于安装多个陷门可能会对目标模型的预测性能产生负面影响(eg:两个相似的陷阱门防御不同的目标标签),我们想通过考虑它们的防御标签来搜索陷阱门。特别的,当我们想最小化类内(intra-class)和最大化类间(inter-class)陷阱门之间的距离。类内的距离是指陷阱门和防御相同标签的距离,类间距离是指陷阱门和防御对比标签的距离。上限\(\alpha\)是类内的距离,下限\(\beta\)是类间的距离,\(e_w\)表示token\(w\)的嵌入。
对象函数和优化器
我们的目标是搜索满足保证度、鲁棒性、class-awareness性质的陷阱门,通过优化公式(5)和限制公式(6)以及K>=1.
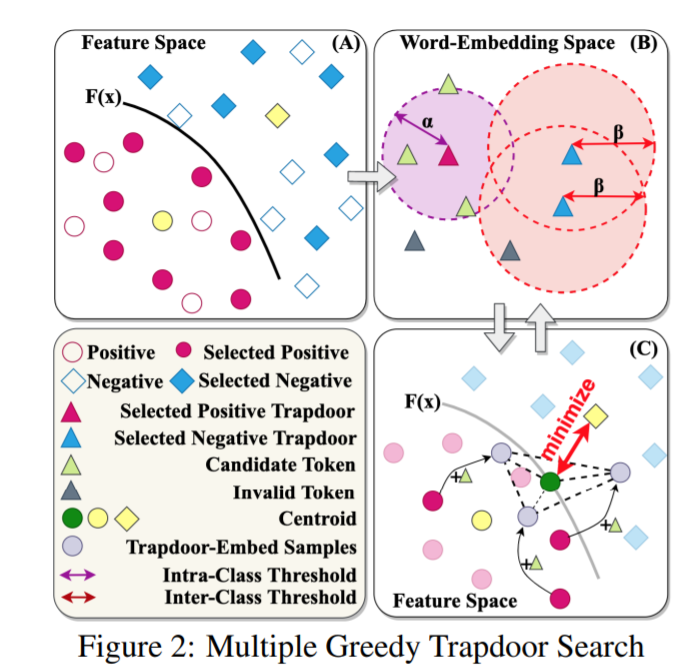
参考公式(7)为了这个全对象函数,为此,采取贪心的启发式算法的方法,主要分为三步:
- warming-up
- 候选条件选择
- 陷阱门选择

第一步(Ln.4)"warming-up"F稍后在第三步中查询,方法是在训练集 \(D_{train}\)上仅使用一个 epoch 对其进行训练。这是为了确保F的决策边界在注入陷阱门之后不会发生显著的变化。同时不会过于僵化的通过公式(3)去学习新的陷阱门样本。
第二步(Ln.10–12, Fig. 2B):搜索符合条件的陷阱门去防御每一个标签\(L \in C\),满足“class-awareness”的性质,3(Ln.14– 20, Fig. 2C)从找到的候选者中,选择最好的陷阱门token针对每一个防御的L,使其最大化\(F’s\)的保真度。从鲁棒性的方面考虑,先前的两步,重复K>=1(Ln.8-23)次.为了减少计算的消耗,我们从条件的陷阱门中随机抽取一小部分样本(\(T << |V|tokens\)),在第一步中找到这些样本,作为第二步的输入。
“计算复杂度”
复杂的算法1主要是迭代Ln.8-23的过程,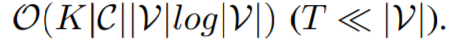 给定一个补丁数据集,\(|C||V|\)是常量,我们提出的陷门搜索算法仅随 K 线性缩放。这表明我们的防御方法的复杂性和鲁棒性之间存在权衡。
给定一个补丁数据集,\(|C||V|\)是常量,我们提出的陷门搜索算法仅随 K 线性缩放。这表明我们的防御方法的复杂性和鲁棒性之间存在权衡。
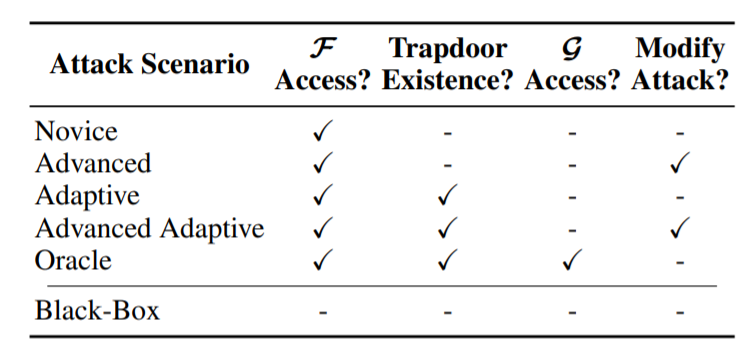
表 3:不同假设下的六种攻击场景:(i)攻击者对模型参数的可访问性(F 的访问权限?),(ii)他们是否知道嵌入式陷门(Trapdoor Existence?),(iii)他们是否有权访问 到检测网络(G 的访问?)和(iii)如果他们改进 UniTrigger 以避免嵌入式陷门(修改攻击?)。
四、总结
这篇文章将蜜罐融入到Unitrigger的检测中,可以针对UNITrigger做防御,这里做了简单的介绍,后续在不断补充心得。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号